堆之*bin理解
在程序运行中,使用bins结构对释放的堆块进行管理,以减少向系统申请内存的开销,提高效率。
chunk数据结构
从内存申请的所有堆块,都使用相同的数据结构——malloc_chunk,但在inuse和free状态,表现形式上略有差别。
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
以上为malloc所得到的chunk的结构,前两个size_t为chunk_header,分别保存前一个(物理相邻)chunk的size(如果前一个chunk为空闲,则保存其size;若为使用状态则归前一个chunk作为usrdata区域使用) 和本chunk的size。因分配的空间会向2*size_t进行对齐,所以后3bit没有意义,因而将其作为三个标记位
- A : NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1表示不属于,0表示属于
- M : 记录当前 chunk 是否是由 mmap 分配的
- P : 记录前一个 chunk 块是否被分配。
chunk被free之后,其usrdata区域被复用,作为bin中的链表指针,其结构如下
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| fd |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| bk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (fd_nextsize) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (bk_nextsize) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- fd和bk指针分别指向bin中在其之前和之后的chunkfd指向先进入bin者;bk指向后来者。
- fastbin中只有fd指针,使用单向链表进行维护。
- fd_nextsize和bk_nextsize只存在与large bin中(chunk的size不大时不需要这两个变量,也可能没有他们的空间),指向前/后一个更大size的chunk。
fastbin
对于size较小(小于max_fast)的chunk,在释放之后进行单独处理,将其放入fastbin中。
max_fast:
在32位系统中,fastbin里chunk的大小范围从16到64;
在64位系统中,fastbin里chunk的大小范围从32到128。
fastbin是main_arena中的一个数组,每个元素作为特定size的空闲堆块的链表头,指向被释放并加入fastbin的chunk。
fastbin链表采用单向链表进行连接
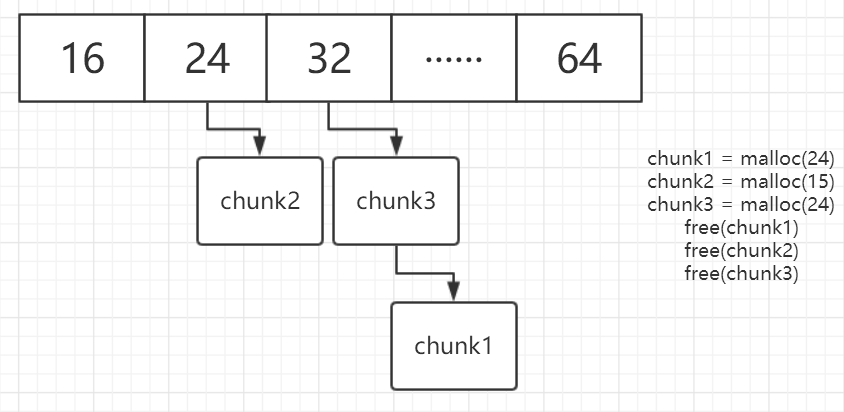
如图所示,在free之后,会将被free掉指向的地址“挂”在fastbin相应大小的条目下,以便于下次分配时节省时间 (曾经为了节省free指针的时间而不free,原来浪费了这么多时间,心疼我的无数个TLE)
在分配空间时,首先检查fastbin数组对应大小的条目下是否有“空闲”的空间,有则直接取下进行分配,同时修改fd指针,维护单向链表。
- 在fastbin条目下,无论是free掉的空间地址加进来,还是将空闲的空间地址分配出去,都是在根部操作
- 加入free的空间时,新加入的连在根部,(如新加入chunk3,插入链表根部,chunk3->fd指向原来最靠近bin的chunk1),类似蛋白质的翻译过程
- 分配空间时,若在对应大小的条目下有空闲的空间,则按蛋白质翻译的逆顺序进行操作(上图中取出chunk3,将chunk3->fd = chunk1链在bin上)
- malloc(n)时,实际申请的空间sizeof(chunk) = (n + 4) align to 8 (x86)
- 实际申请的空间从chunk开始,当堆中物理相邻的前一个chunk为free时,Size of previous chunk标记前一个chunk的大小,否则可以存储前一个chunk的数据。之后是本chunk的大小,由于分配的必定是24bytes(64位为28bytes)的整数倍,最后三位没有影响用作三个标记位。
- malloc函数范围的指针是从mem开始的用户可用空间。
unsorted bin
unsorted bin 可以作为chunk 被释放和分配的缓冲区。在malloc&free剖析中解释了malloc和free活动中对unsorted bin的使用。这里从更微观的角度解释unsorted bin如何工作。
main_arena
main_arena,主分配区,是一个静态全局变量,其中存储着进行堆块管理的各种变量和指针。
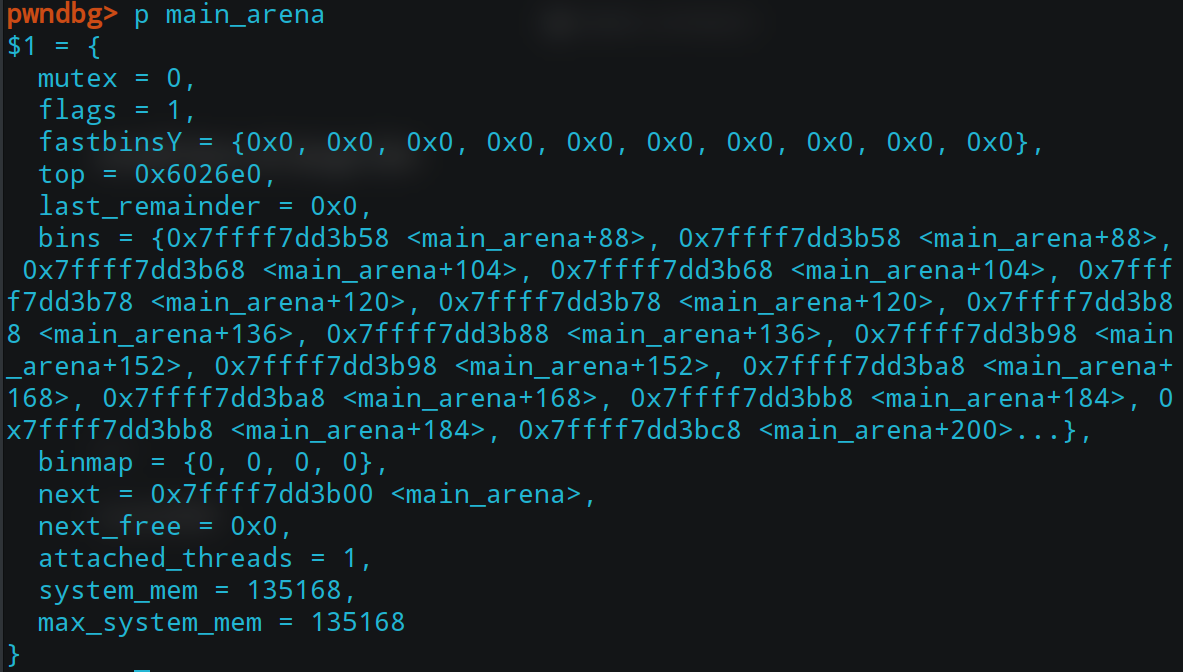
fastbin各项指针、topchunk、和bins指针都存在于这个变量当中。
unsorted bin指针就是bins指针的前两项,ptmalloc共维护128个bin,都存放于bins数组中。
- 前两项为unsorted bin的指针
- bins[2] - bins[65]的64个元素为small bin指针
- bins[66] - bins[127]为large bin
unsorted bin
下面通过这段代码分析在释放和分配chunk时unsorted bin中各指针的工作细节:
# include <stdio.h>
# include <stdlib.h>
int main()
{
void *a, *b, *c, *d, *e;
a = malloc(128);
b = malloc(128);
c = malloc(128);
d = malloc(128);
e = malloc(128);
printf("a >> %p\nb >> %p\nc >> %p\nd >> %p\ne >> %p\n",a,b,c,d,e);
puts("free d and b, remember the bins");
free(d);
free(b);
//puts("free c,look at the unsorted bin");
//free(c);
puts("malloc(128) again, what will happen?");
void * newd = malloc(128);
printf("new d -> %p\n", newd);
return 0;
}
//make file(x64):
//gcc -o unsortedbin ./test_unosrted -no-pie
运行后得到分配的五个chunk的地址,由于直接输出了返回给用户的指针,所以指向的都是usrdata,指向实际chunk头的地址应该减去0x10。
a >> 0x602010
b >> 0x6020a0
c >> 0x602130
d >> 0x6021c0
e >> 0x602250
没有发生free之前

bins数组的前两个可以看做unsorted bin的fd和bk指针,在unsorted bin为空的时候都指向top (main_arena+88)
CTFwiki对这个过程具体流程和背后原理的示意图不太准确:unsorted bin链表头并不是malloc_chunk结构体,而是main_arena变量中bins列表的前两项分别做fd和bk指针,指向的位置也不是pre_size,而是main_arena中的top,top指向top chunk。我的理解是这样的,如有错误,还请指出。
free(d)
pwndbg> unsortedbin
unsortedbin
all: 0x6021b0 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x6021b0 ◂— 0x7ffff7dd3b58
pwndbg> p main_arena
$2 = {
mutex = 0,
flags = 1,
fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0},
top = 0x6026e0,
last_remainder = 0x0,
bins = {0x6021b0, 0x6021b0, 0x7ffff7dd3b68 <main_arena+104>, 0x7ffff7dd3b68 <main_arena+104>...
pwndbg> telescope 0x6021b0
00:0000│ 0x6021b0 ◂— 0x0
01:0008│ 0x6021b8 ◂— 0x91
02:0010│ 0x6021c0 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x6026e0 ◂— 0x0
... ↓
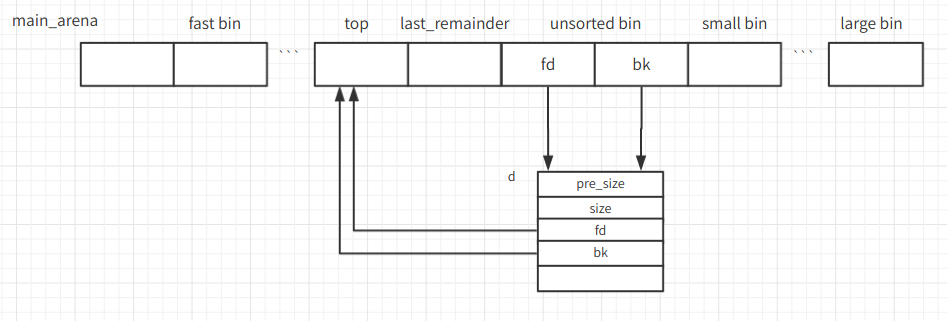
此时unsorted bin的两个指针均指向被释放的d,d的fd、bk指针指向top
free(b)
pwndbg> p main_arena
$3 = {
mutex = 0,
flags = 1,
fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0},
top = 0x6026e0,
last_remainder = 0x0,
bins = {0x602090, 0x6021b0, 0x7ffff7dd3b68 <main_arena+104>,...
pwndbg> unsortedbin
unsortedbin
all: 0x602090 —▸ 0x6021b0 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x602090 ◂— 0x6021b0
pwndbg> telescope 0x602090
00:0000│ 0x602090 ◂— 0x0
01:0008│ 0x602098 ◂— 0x91
02:0010│ 0x6020a0 —▸ 0x6021b0 ◂— 0x0
03:0018│ 0x6020a8 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x6026e0 ◂— 0x0
04:0020│ 0x6020b0 ◂— 0x0
... ↓
pwndbg> telescope 0x6021b0
00:0000│ 0x6021b0 ◂— 0x0
01:0008│ 0x6021b8 ◂— 0x91
02:0010│ 0x6021c0 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x6026e0 ◂— 0x0
03:0018│ 0x6021c8 —▸ 0x602090 ◂— 0x0
04:0020│ 0x6021d0 ◂— 0x0
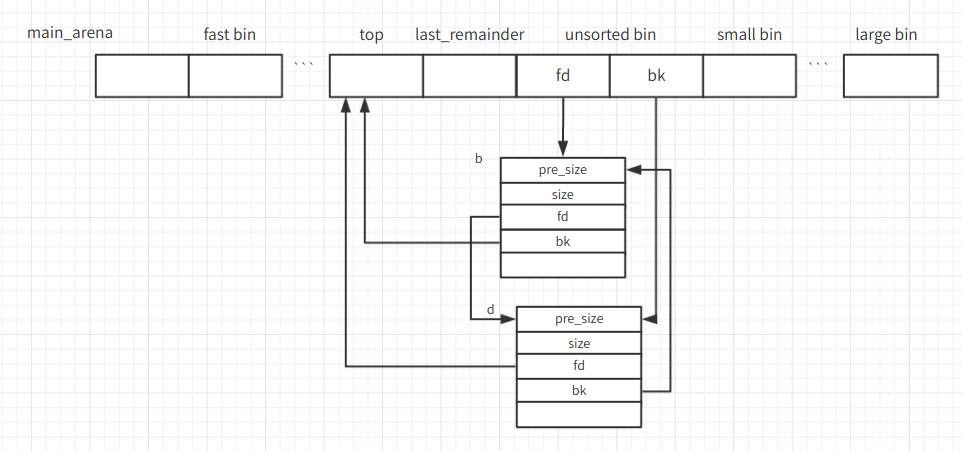
新释放的b会连载unsortedbin的根部,各指针的关系如图。
malloc(128)
pwndbg> p main_arena
$4 = {
mutex = 0,
flags = 1,
fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0},
top = 0x6026e0,
last_remainder = 0x0,
bins = {0x602090, 0x602090, 0x7ffff7dd3b68 <main_arena+104>, ...
pwndbg> unsortedbin
unsortedbin
all: 0x602090 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x602090 ◂— 0x7ffff7dd3b58
pwndbg> telescope 0x602090
00:0000│ 0x602090 ◂— 0x0
01:0008│ 0x602098 ◂— 0x91
02:0010│ 0x6020a0 —▸ 0x7ffff7dd3b58 (main_arena+88) —▸ 0x6026e0 ◂— 0x0
... ↓
04:0020│ 0x6020b0 ◂— 0x0
此时unsorted bin又只有一个chunk,指针关系与刚刚free(d)时相同,但在bin中的是b,先进入的d被再次分配,由此得到,unsorted bin中遵循FIFO原则,先进入的chunk在size合适的情况下会被优先分配。
unlink
在unsorted bin中进行分配的时候,size不合适的chunk会被放入small bin或large bin,这个unlink的过程没有对chunk进行检查,所以被篡改过的chunk也能通过unlink,破坏掉链表中的fd、bk指针,即unsorted bin attack。
small bins & large bin
chunk进入small bin和large bin的唯一机会是在分配chunk时,在unsorted bin中进行遍历,size不合适的chunk会被unlink过来。
small bin和large bin都是采用双向链表进行维护,遵循FIFO原则。
其中large bin中的chunk有fd_nextsize和bk_nextsize,分别指向之前/之后更大的chunk,加快寻找速度。
在分配chunk的时候,如果前面的步骤都没有找到合适的chunk,则在small bin和large bin中找到最小的large enough的chunk,进行分割,unlink,分配完成。
Ref:
作者:辣鸡小谱尼
出处:http://www.cnblogs.com/ZHijack/
如有转载,荣幸之至!请随手标明出处;
堆之*bin理解的更多相关文章
- 堆&栈的理解(转)
(摘自:http://www.cnblogs.com/likwo/archive/2010/12/20/1911026.html) C++中堆和栈的理解 内存分配方面: 堆: 操作系统有一个记录空闲内 ...
- [原创]C#中的堆和栈理解
引言:程序运行时,它的数据必须存在内存中,一个数据需要多大内存.存储在什么地方以及如何存储都依赖于该数据的数据类型. 1.什么是栈 栈是一个内存数组,是一个LIFO(Last-In-First-Out ...
- Pwnable.kr
Dragon —— 堆之 uaf 开始堆的学习之旅. uaf漏洞利用到了堆的管理中fastbin的特性,关于堆的各种分配方式参见堆之*bin理解 在SecretLevel函数中,发现了隐藏的syste ...
- c#中栈和堆的理解
之前对栈(stack)和堆(heap)的认识很模糊,今天看了一篇关于堆栈的文章<译文---C#堆VS栈>后,仿佛有种拨开云雾见青天的感觉,当然只是一些浅显的理论的认识,这里做一些简单的记录 ...
- 堆溢出---glibc malloc
成功从来没有捷径.如果你只关注CVE/NVD的动态以及google专家泄露的POC,那你只是一个脚本小子.能够自己写有效POC,那就证明你已经是一名安全专家了.今天我需要复习一下glibc中内存的相关 ...
- [20180822]session_cached_cursors与子游标堆0.txt
[20180822]session_cached_cursors与子游标堆0.txt --//前几天测试刷新共享池与父子游标的问题,--//链接: http://blog.itpub.net/2672 ...
- 内存栈与堆的区别C#
C# 堆与栈 理解堆与栈对于理解.NET中的内存管理.垃圾回收.错误和异常.调试与日志有很大的帮助.垃圾回收的机制使程序员从复杂的内存管理中解脱出来,虽然绝大多数的C#程序并不需要程序员手动管理内存, ...
- 深入理解JVM(一)——JVM内存模型
JVM内存模型 Java虚拟机(Java Virtual Machine=JVM)的内存空间分为五个部分,分别是: 1. 程序计数器 2. Java虚拟机栈 3. 本地方法栈 4. 堆 5. 方法区. ...
- solr 5.0.0 bin/start脚本详细解析
参考文档:https://cwiki.apache.org/confluence/display/solr/Solr+Start+Script+Reference#SolrStartScriptRef ...
随机推荐
- Java中类锁和对象锁
类锁 类锁 锁的其实是类的Class对象,类锁的代码写法是对类方法加synchronize,或者 synchronize(xx.class){} 对象锁 对象锁 锁的是类的实例对象,对象锁的形式有 对 ...
- 前端开发:这10个Chrome扩展你不得不知
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文出处:https://blog.bitsrc.io/10-top-chrome-extensions-f ...
- leetcode--js--Two Sum
问题描述: 给定一个整数数列,找出其中和为特定值的那两个数. 你可以假设每个输入都只会有一种答案,同样的元素不能被重用. 示例: 给定 nums = [2, 7, 11, 15], target = ...
- 【STM32H7教程】第62章 STM32H7的MDMA,DMA2D和通用DMA性能比较
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第62章 STM32H7的MDMA,DMA2D和通 ...
- Redis-位图
关于位图,可能大家不太熟悉, 那么位图能干啥呢?位图的内容其实就是普通的字符串,也就是byte数组,我们都知道 byte 8 位无符号整数 0 到 255 说个场景.比如你处理一些业务时候,往往会存在 ...
- idea如何做到多模块开发项目 收藏整理
idea如何做到多模块开发项目 <packaging>pom</packaging>是什么意思? idea 快捷键汇总
- SDI011 读卡器自动发送00A4选择指令 解决方法
如标题,SDI读卡器会自动发送 004A的应用选择指令 解决方法: 是Certificate Propagation 服务 弄的, 关闭就好了
- libmodbus库linux 嵌入式设备中的使用
libmodbus库的交叉编译:1]到libmodbus官网https://libmodbus.org/download/下载安装包,内部自带configure文件,官网推荐v3.1.6稳定版.另外注 ...
- BUUCTF 部分wp
目录 Buuctf crypto 0x01传感器 提示是曼联,猜测为曼彻斯特密码 wp:https://www.xmsec.cc/manchester-encode/ cipher: 55555555 ...
- Centos7下安装包方式安装MySQL
安装包下载地址:https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar 第一步:在 /h ...