hadoop3自学入门笔记(2)—— HDFS分布式搭建
一些介绍
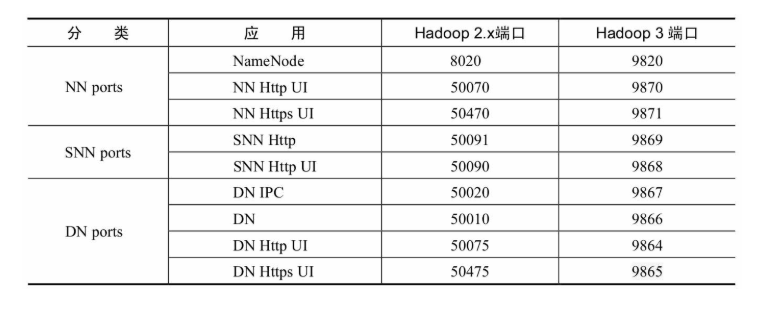
Hadoop 2和Hadoop 3的端口区别
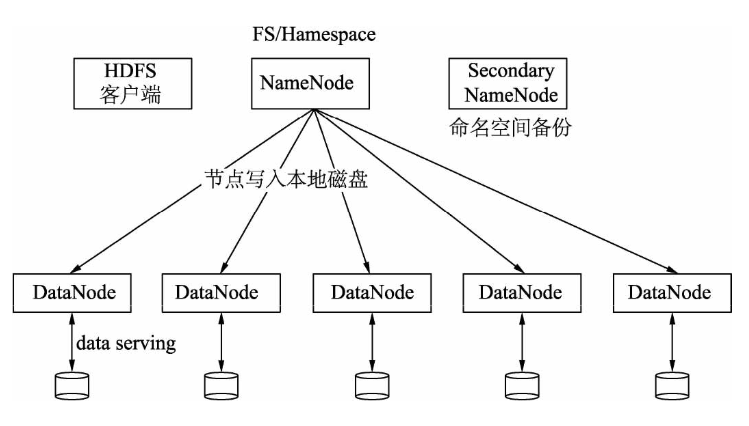
Hadoop 3 HDFS集群架构
我的集群规划
| name | ip | role |
|---|---|---|
| 61 | 192.168.3.61 | namenode, datanode |
| 62 | 192.168.3.62 | datanode |
| 63 | 192.168.3.63 | secondnamenode |
| 64 | 192.168.3.64 | datanode |
1.安装JDK
利用FileZilla sftp功能进行上传到指定文件夹下/root/software,下图是配置sftp.
解压使用命令tar -xvzf jdk-8u241-linux-x64.tar.gz 解压到当前文件夹下。
配置环境变量,输入命令vim /etc/profile,添加
JAVA_HOME=/root/software/jdk1.8.0_241
PATH=$JAVA_HOME/bin:$PATH
最后退出vi,输入source /etc/profile
测试输入命令java -version,如果展示
root@localhost ~]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
[root@localhost ~]#
安装成功!
ssh免密配置请查看
2.配置Hadoop
sftp://root@192.168.3.62/root/software/hadoop-3.2.1.tar.gz
解压。
2.1部署及配置
Hadoop的配置涉及以下几个文件,分别是:hadoop-env.sh、core-site.xml、hdfs-site.xml和workers。其中,hadoop-env.sh是Hadoop运行环境变量配置;core-site.xml是Hadoop公共属性的配置;hdfs-site.xml是关于HDFS的属性配置;workers是DataNode分布配置。下面我们分别配置这几个文件。
以61为中心配置,最后复制到其他服务器
- hadoop-env.sh文件
在/etc/hadoop/hadoop-env.sh中配置运行环境变量,在默认情况下,这个文件是没有任何配置的。我们需要配置JAVA_HOME、HDFS_NAMENODE_USER和HDFS_DATANODE_USER等,HDFS_SECONDARYNAMENODE_USER配置代码如下:
在尾部加入
export JAVA_HOME=/root/software/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
其中,JAVA_HOME=/root/software/jdk1.8.0_241是指定JDK的位置,HDFS_NAMENODE_USER=root是指定操作NameNode进程的用户是root。同理,HDFS_DATANODE_USER和HDFS_SECONDARYNAMENODE_USER分别指定了操作DataNode和Secondary NameNode的用户,在这里我们设置为root用户,具体应用时,读者根据情况进行设置即可。在这里需要注意的是,HDFS_NAMENODE_USER、HDFS_DATANODE_USER和HDFS_SECONDARYNAMENODE_USER是Hadoop 3.x为了提升安全性而引入的。
- core-site.xml文件
core-site.xml中主要配置Hadoop的公共属性,配置代码如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.3.61:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata</value>
</property>
</configuration>
其中,fs.defaultFS是指定NameNode所在的节点,在这里配置为node1;9820是默认端口;hdfs:是协议;hadoop.tmp.dir是配置元数据所存放的配置,这里配置为/opt/hadoopdata,后续如果需要查看fsiamge和edits文件,可以到这个目录下查找。
- hdfs-site.xml文件
hdfs-site.xml文件中主要是HDFS属性配置,配置代码如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.3.63:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
其中,dfs.namenode.secondary.http-address属性是配置Secondary NameNode的节点,在这里配置为node2。端口为9868。
关于这些配置,读者可以从官网上查找,网址为https://hadoop.apache.org/docs/stable/index.html,其中的左下角有个Configuration项,其中包括core-default.xml等配置文件。
- workers文件
在workers中配DataNode节点,在其中写入:
192.168.3.61
192.168.3.62
192.168.3.64
2.2 将配置复制到其他服务器
进入 /root/software/hadoop-3.2.1/etc 目录
输入命令
scp -r ./hadoop 192.168.3.62:/root/software/hadoop-3.2.1/etc/
scp -r ./hadoop 192.168.3.63:/root/software/hadoop-3.2.1/etc/
scp -r ./hadoop 192.168.3.64:/root/software/hadoop-3.2.1/etc/
2.3配置下hadoop的环境变量,方便输入命令
export JAVA_HOME=/root/software/jdk1.8.0_241
export HADOOP_HOME=/root/software/hadoop-3.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.4格式化
第一次安装Hadoop需要进行格式化,以后就不需要了。格式化命令在hadoop/bin下面,执行如下命令:
hdfs namenode -formate
格式化后会创建一个空白的fsimage文件,可以在opt/hadoopdata/dfs/name/current中找到fsimage文件,注意此时没有edits文件。
3.启动
进入hadoop/sbin下面运行start-dfs.sh,启动HDFS集群,启动命令如下:
./start-dfs.sh
这时,可以在不同节点中通过jps命令查看不同的进程。
61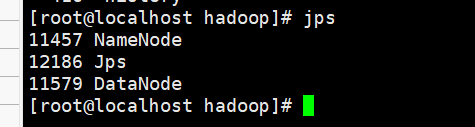
62
63
64
表示都已经启动。
4.打开浏览器查看HDFS监听页面
在浏览器中输入http://ip:9870,比如这里输入http://192.168.30.61:9870/,出现以下界面则表示Hadoop完全分布式搭建成功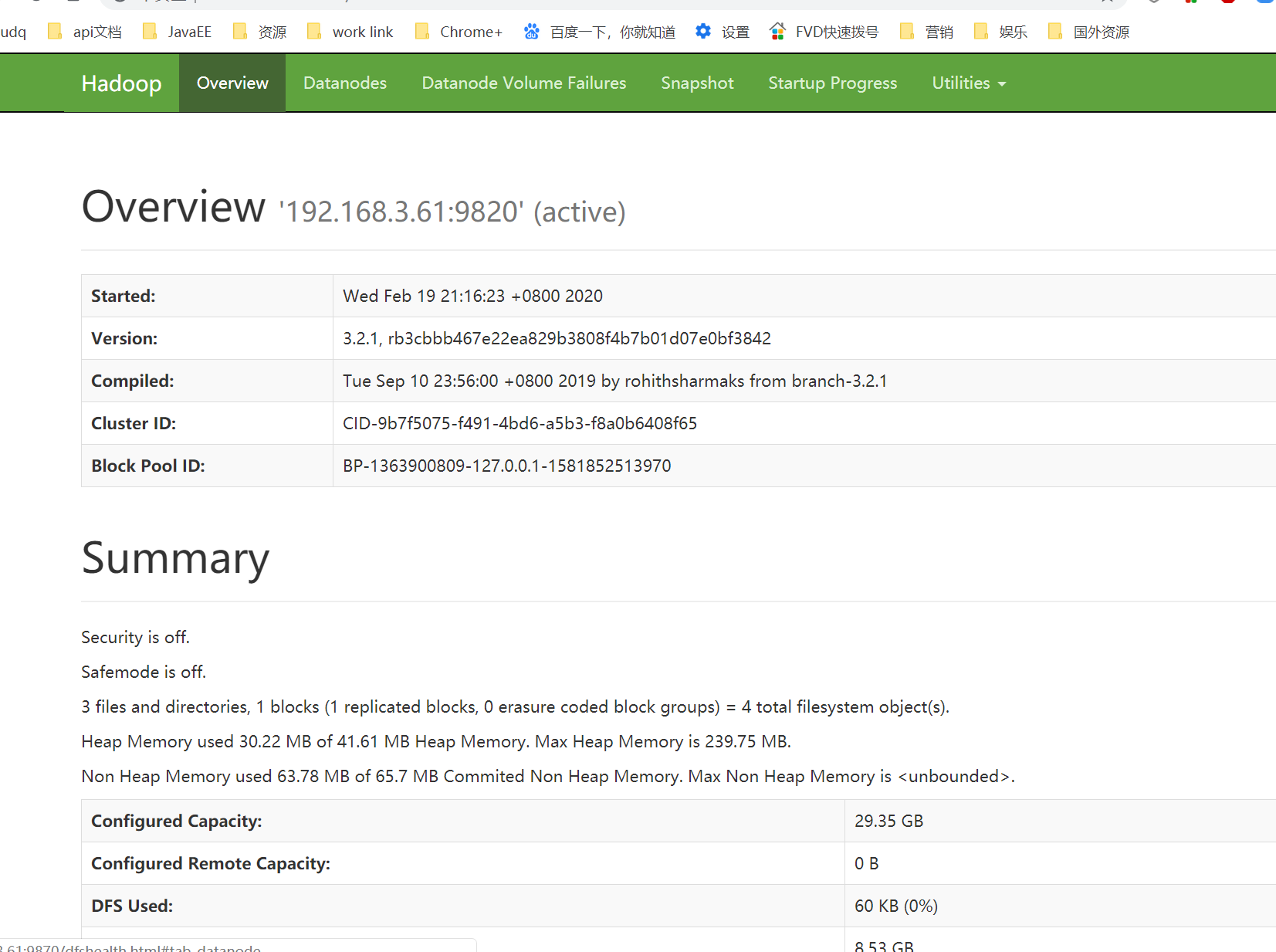

选择Datanodes选项,可以看到DataNode的利用率和DataNode的节点状态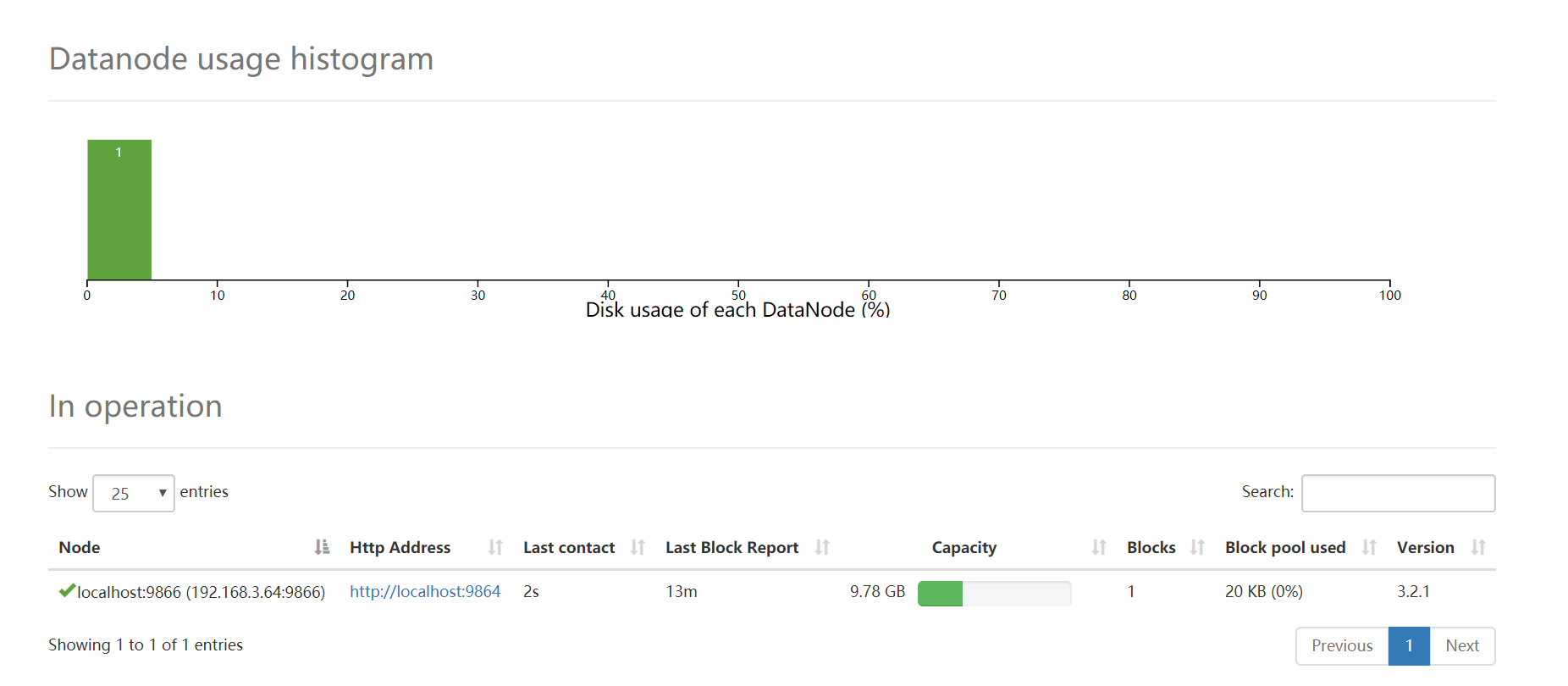
这里只显示了一个比较奇怪,以后再研究。
更多精彩请关注公众号【lovepythoncn】
hadoop3自学入门笔记(2)—— HDFS分布式搭建的更多相关文章
- hadoop3自学入门笔记(3)-java 操作hdfs
1.core-site.xml <configuration> <property> <name>fs.defaultFS</name> <val ...
- hadoop3自学入门笔记(1)——虚拟机安装和网络配置
前言 年过30惶惶不安,又逢疫情,还是不断学习,强化自己的能力.hadoop的视频和书籍在15年的时候就看过,但是一直没动手实践过,要知道技术不经过实战,一点提升也没有.因此下定决心边学边做,希望能有 ...
- Hadoop 笔记1 (原理和HDFS分布式搭建)
1. hadoop 是什么 以及解决的问题 (自行百度) 2.基本概念的讲解 1. NodeName master 节点(NN) 主节点 保存了metaData(元数据信息) 包括文件的owener ...
- vue自学入门-1(Windows下搭建vue环境)
本人是一个喜欢动手的程序员,先跑起来个HelloWorld,增加感性认识,这三篇入门文章,花了不到一个小时,从网上找资料,程序跑通后,整理出来的,有的新人可能去哪找资料,运行代码都不知道,分享出来,大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs分布式文件系统安装
实验目的 复习安装jdk 学习免密码登录 掌握安装配置hdfs集群的方法 掌握hdfs集群的简单使用和检查其工作状态 实验原理 1.hdfs是什么 hadoop安装的第一部分是安装hdfs,hdfs是 ...
- vue自学入门-6(vue jsx)
目录: vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5( ...
- vue自学入门-4(vue slot)
vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5(vuex ...
- vue自学入门-5(vuex state)
vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5(vuex ...
- vue自学入门-7(vue style scope)
vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5(vuex ...
随机推荐
- latex之在windows环境下能够在latex中使用中文
今天要把前段时间的实验用英语先记录下来,自己就想根据原来会议的模版弄一个简易的页面(英语),突然想到之前用英文模板时是不能输入中文的,于是想着怎么在latex中输入中文,折腾了许久,终于成功了,现在分 ...
- windows上apache配置php5
windows上apache配置php5 重点:1.php5里的php.ini的extension_dir要改为绝对目录(带'/'斜杠),如果只是写个ext,在apache+mod_php里面是不会加 ...
- C语言—期末小黄衫获奖感言
小黄衫获奖感言 一,感谢环节 非常感谢邹欣,周筠老师给提供的小黄衫,我非常荣幸的能够获得这个奖项,我感到无比自豪.感谢两位老师对教学事业的大力支持,对我们学生的亲切关怀.同时感谢我的C语言老师彭琛(琛 ...
- [CF 487C Prefix Product Sequence]
题意 将1~n的正整数重排列,使得它的前缀积在模n下形成0~n-1的排列,构造解或说明无解.n≤1E5. 思考 小范围内搜索解,发现n=1,n=4和n为质数时有解. 不难发现,n一定会放在最后,否则会 ...
- mysql--->MySQL错误日志
MySQL错误日志 简介 MySQL错误日志是记录MySQL 运行过程中较为严重的警告和错误信息,以及MySQL每次启动和关闭的详细信息.错误日志的命名通常为hostname.err.其中,hostn ...
- springBoot 整合 dubbo 遇到的坑
一.注意springBoot 和 dubbo 之间版本的问题 <?xml version="1.0" encoding="UTF-8"?> < ...
- django登录页面优化
环境准备 1.python3.6 2.django2.0+ 3.bootstrap3 后台代码 #创建login_check视图函数,用来处理登录 def login_action(request): ...
- Redis系列(三):Redis的持久化机制(RDB、AOF)
本篇博客是Redis系列的第3篇,主要讲解下Redis的2种持久化机制:RDB和AOF. 本系列的前2篇可以点击以下链接查看: Redis系列(一):Redis简介及环境安装. Redis系列(二): ...
- MSVC下快速Unicode I/O
http://blog.kingsamchen.com/archives/863 如果需要往console输出包含非ASCII字符的宽字符串,一个比较快速的方法是使用WriteConsoleW这个AP ...
- Codeforces Round #600 (Div. 2) E. Antenna Coverage
Codeforces Round #600 (Div. 2) E. Antenna Coverage(dp) 题目链接 题意: m个Antenna,每个Antenna的位置是\(x_i\),分数是\( ...