Elasticsearch编程操作
1.创建工程导入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-to-slf4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.13.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
2.创建索引
@Test
//创建索引
public void createIndex() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//创建名称为blog1的索引
client.admin().indices().prepareCreate("blog1").get();
//释放资源
client.close();
}

注意:此时创建的索引是没有mapping映射的
3.创建映射mapping
@Test
//创建映射mapping
public void createMapping() throws Exception {
// 创建Client连接
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));
// 添加映射
/**
格式:
"mappings" : {
"article" : {
"dynamic" : "false",
"properties" : {
"id" : { "type" : "string" },
"content" : { "type" : "string" },
"author" : { "type" : "string" }
}
}
}
*/
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "integer").field("store", "yes")
.endObject()
.startObject("title")
.field("type", "string").field("store", "yes").field("analyzer", "ik_smart")
.endObject()
.startObject("content")
.field("type", "string").field("store", "yes").field("analyzer", "ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
// 创建映射
PutMappingRequest mapping = Requests.putMappingRequest("blog1")
.type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
//释放资源
client.close();
}

4.建立文档document
4.1 建立文档(通过XContentBuilder)
@Test
//创建文档(通过XContentBuilder)
public void createXContentBuilder() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
//创建文档信息
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("id", 1)
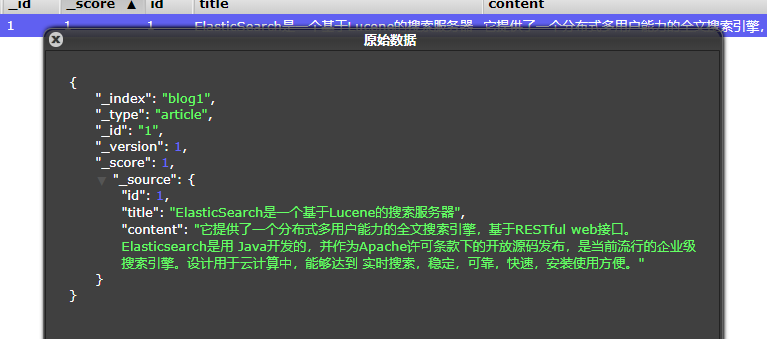
.field("title", "ElasticSearch是一个基于Lucene的搜索服务器")
.field("content",
"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用\n" +
"Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到\n" +
"实时搜索,稳定,可靠,快速,安装使用方便。")
.endObject();
// 建立文档对象
/**
* 参数一blog1:表示索引对象
* 参数二article:类型
* 参数三1:建立id
* */
client.prepareIndex("blog1", "article", "1").setSource(builder).get();
//释放资源
client.close();
}
4.2 建立文档(使用Jackson转换实体)
1)创建Article实体
package com.wish.elasticSear;
public class Article {
private Integer id;
private String title;
private String content;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
2)导入Jackson的依赖
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
3)代码实现
@Test
//创建文档(通过实体转json)
public void createJson() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
// 描述json 数据
//{id:xxx, title:xxx, content:xxx}
Article article = new Article();
article.setId(2);
article.setTitle("搜索工作其实很快乐");
article.setContent("我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,\n" +
" 我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩\n" +
" 展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这\n" +
" 些问题和更多的问题。"); ObjectMapper objectMapper=new ObjectMapper();
client.prepareIndex(
"blog1","article",article.getId().toString()
).setSource(
objectMapper.writeValueAsString(article).getBytes(),XContentType.JSON
).get();
client.close();
}


5.查询文档操作
5.1关键词查询
@Test
//关键词查询
public void testTermQuery() throws Exception {
//1、创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
//2、设置搜索条件
SearchResponse searchResponse = client.prepareSearch("blog1")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "搜索")).get();
//3、遍历搜索结果数据
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
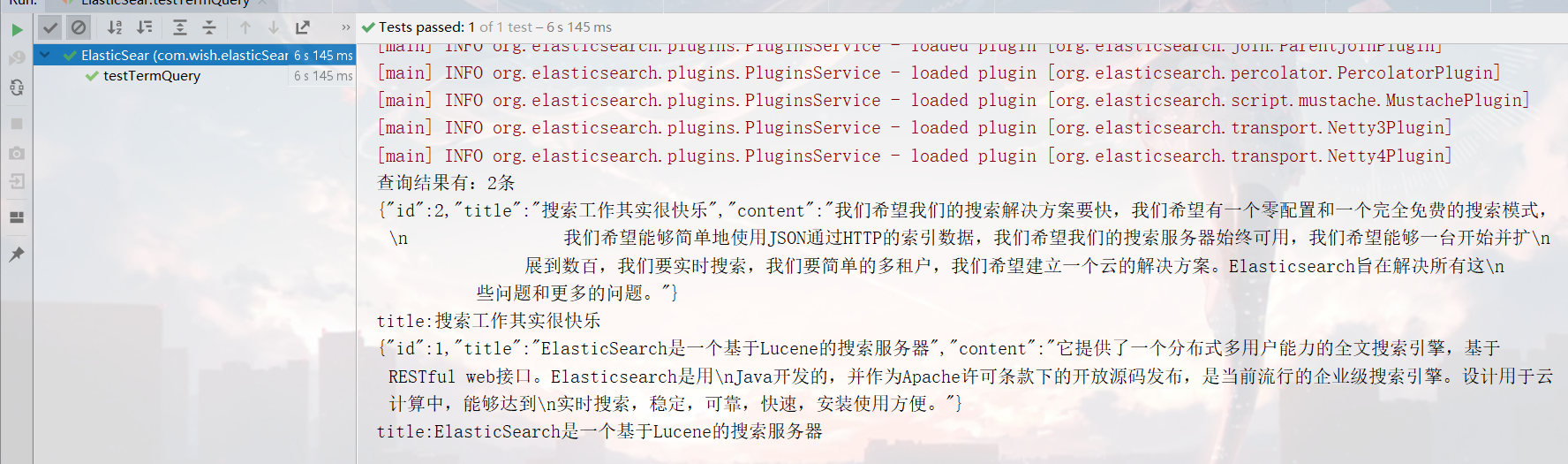
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
System.out.println("title:" + searchHit.getSource().get("title"));
}
//4、释放资源
client.close();
}
5.2 字符串查询
@Test
//字符串查询
public void testStringQuery() throws Exception {
//1、创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
//2、设置搜索条件
SearchResponse searchResponse = client.prepareSearch("blog1")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("搜索")).get();
//3、遍历搜索结果数据
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
System.out.println("title:" + searchHit.getSource().get("title"));
}
//4、释放资源
client.close(); }

5.3 使用文档ID查询文档
@Test
//使用文档ID查询文档
public void testIdQuery() throws Exception {
//1、创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
//client对象为TransportClient对象
SearchResponse response = client.prepareSearch("blog1")
.setTypes("article")
//设置要查询的id
.setQuery(QueryBuilders.idsQuery().addIds("1"))
//执行查询
.get();
//取查询结果
SearchHits searchHits = response.getHits();
//取查询结果总记录数
System.out.println(searchHits.getTotalHits());
Iterator<SearchHit> hitIterator = searchHits.iterator();
while(hitIterator.hasNext()) {
SearchHit searchHit = hitIterator.next();
//打印整行数据
System.out.println(searchHit.getSourceAsString());
}
}

6 .查询文档分页操作
1)批量插入数据
@Test
//批量插入50条数据
public void continuousInsertion() throws Exception {
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new
InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 1; i <= 50; i++) {
// 描述json 数据
Article article = new Article();
article.setId(i);
article.setTitle(i + "搜索工作其实很快乐");
article.setContent(i
+ "我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我\n" +
" 们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展\n" +
" 到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些\n" +
" 问题和更多的问题。");
// 建立文档
client.prepareIndex("blog1", "article", article.getId().toString())
//.setSource(objectMapper.writeValueAsString(article)).get();
.setSource(objectMapper.writeValueAsString(article).getBytes(), XContentType.JSON).get(); }
//释放资源
client.close();
}


2)分页查询
@Test
//分页查询
public void pagingQuery() throws Exception {
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 搜索数据
SearchRequestBuilder searchRequestBuilder =
client.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.matchAllQuery());//默认每页10条记录
// 查询第2页数据,每页20条
//setFrom():从第几条开始检索,默认是0。
//setSize():每页最多显示的记录数。
searchRequestBuilder.setFrom(0).setSize(5);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
System.out.println("id:" + searchHit.getSource().get("id"));
System.out.println("title:" + searchHit.getSource().get("title"));
System.out.println("content:" + searchHit.getSource().get("content"));
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
}
//释放资源
client.close();
}



7.查询结果高亮操作
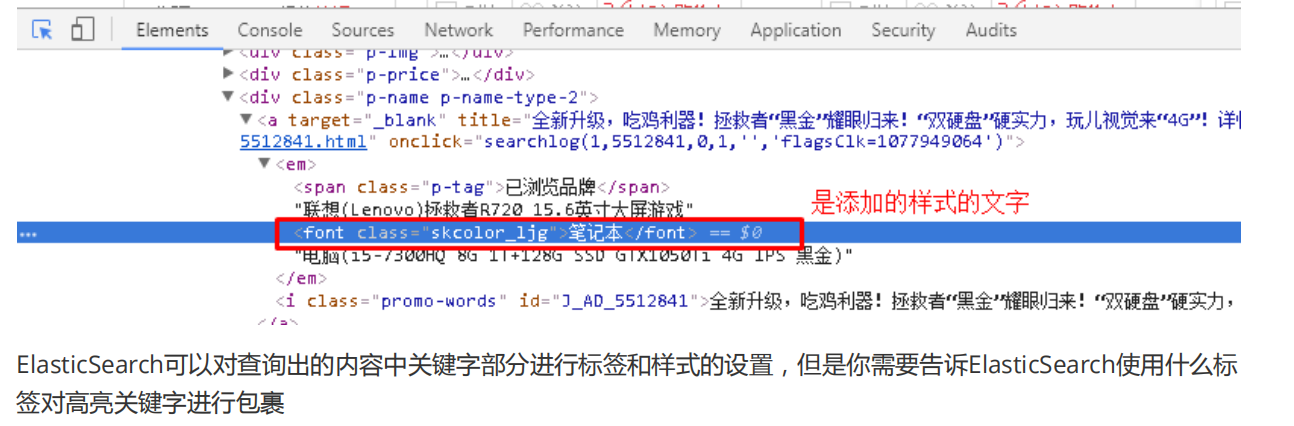
1).什么是高亮显示
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮
2).高亮显示的html分析
3).高亮显示代码实现
@Test
//高亮查询
public void highlightQuery() throws Exception {
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my‐elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),
9300));
// 搜索数据
SearchRequestBuilder searchRequestBuilder = client
.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "搜索"));
//设置高亮数据
HighlightBuilder hiBuilder = new HighlightBuilder();
hiBuilder.preTags("<font style='color:red'>");
hiBuilder.postTags("</font>");
hiBuilder.field("title");
searchRequestBuilder.highlighter(hiBuilder);
//获得查询结果数据
SearchResponse searchResponse = searchRequestBuilder.get();
//获取查询结果集
SearchHits searchHits = searchResponse.getHits();
System.out.println("共搜到:" + searchHits.getTotalHits() + "条结果!");
//遍历结果
for (SearchHit hit : searchHits) {
System.out.println("String方式打印文档搜索内容:");
System.out.println(hit.getSourceAsString());
System.out.println("Map方式打印高亮内容");
System.out.println(hit.getHighlightFields());
System.out.println("遍历高亮集合,打印高亮片段:");
Text[] text = hit.getHighlightFields().get("title").getFragments();
for (Text str : text) {
System.out.println(str);
}
}
//释放资源
client.close();
}

Elasticsearch编程操作的更多相关文章
- KEIL的混合编程操作
http://hi.baidu.com/txz01/item/21ad9d75913a7b28d7a89c12 这一篇来讲讲混合编程的问题,在网上找了一下,讲混合编程的文件章也有不少,但进行实例操作讲 ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- SpringBoot使用WebFlux响应式编程操作数据库
这一篇文章介绍SpringBoot使用WebFlux响应式编程操作MongoDb数据库. 前言 在之前一篇简单介绍了WebFlux响应式编程的操作,我们在来看一下下图,可以看到,在目前的Spring ...
- 使用Spring Data ElasticSearch+Jsoup操作集群数据存储
使用Spring Data ElasticSearch+Jsoup操作集群数据存储 1.使用Jsoup爬取京东商城的商品数据 1)获取商品名称.价格以及商品地址,并封装为一个Product对象,代码截 ...
- elasticsearch使用操作部分
本片文章记录了elasticsearch概念.特点.集群.插件.API使用方法. 1.elasticsearch的概念及特点.概念:elasticsearch是一个基于lucene的搜索服务器.luc ...
- Elasticsearch批处理操作——bulk API
Elasticsearch提供的批量处理功能,是通过使用_bulk API实现的.这个功能之所以重要,在于它提供了非常高效的机制来尽可能快的完成多个操作,与此同时使用尽可能少的网络往返. 1.批量索引 ...
- Elasticsearch 编程API入门系列---说在前面的话
前提,是 Eclipse下Maven新建项目.自动打依赖jar包(包含普通项目和Web项目) setting.xml配置文件 如何在Maven官网下载历史版本 HBase 开发环境搭建(Eclipse ...
- elasticsearch简单操作
现在,启动一个节点和kibana,接下来的一切操作都在kibana中Dev Tools下的Console里完成 创建一篇文档 将小黑的小姨妈的个人信息录入elasticsearch.我们只要输入 PU ...
- JestClient 使用教程,教你完成大部分ElasticSearch的操作。
本篇文章代码实现不多,主要是教你如何用JestClient去实现ElasticSearch上的操作. 授人以鱼不如授人以渔. 一.说明 1.elasticsearch版本:6.2.4 . jdk版本: ...
随机推荐
- mysq5.7l的下载与配置
---恢复内容开始--- mysql是一个开源免费的数据库,它属于oracle公司 下载地址:www.oracle.com 页面移动到下面可以找到这几个选项 还是移动到下面 如果你要下载的不是那四样中 ...
- tf.keras遇见的坑:Output tensors to a Model must be the output of a TensorFlow `Layer`
经过网上查找,找到了问题所在:在使用keras编程模式是,中间插入了tf.reshape()方法便遇到此问题. 解决办法:对于遇到相同问题的任何人,可以使用keras的Lambda层来包装张量流操作, ...
- HDS协议介绍
一.什么是HTTP Dynamic Streaming 使用传统的HTTP协议进行在线播放叫做“渐进下载”,所有的视频内容从头到尾必须从服务器传输到客户端,用户只能在传输完的视频长度中选择播放点,而不 ...
- qq机器人 python实现 自动回复
我以前写的代码我现在贴在了下面,下面的连接是我自己的博客,有问题希望大家提出来,一起进步...我以前试过,没啥问题.可以实现聊天. https://realwuxiong.github.io/blog ...
- springboot中使用Caffeine本地缓存
Caffeine是使用Java8对Guava缓存的重写版本性能有很大提升 一 依赖 <dependency> <groupId>org.springframework.boot ...
- ROS可视化工具RViz的简单使用教程
1.安装rviz sudo apt-get install ros-melodic-rviz 环境检测.安装 rosdep install rviz rosmake rviz startup(开两个 ...
- linux中rz、rs命令无法执行的情况
执行如下安装命令: yum install -y lrzsz
- VUE 开发报表,非编码方式
官网:http://doc.sougn.com 下载地址:https://pan.baidu.com/share/init?surl=P0O9sjfzC8nuQxirDfjW1A 密码:4oev 先 ...
- Android: Fragment编程指南
本文来自于www.lanttor.org Fragment代表了Activity里的一个行为,或者Activity UI的一部分.你可以在一个activity里构造多个Fragment,也可以在多个a ...
- VS生成垃圾文件清理
@echo Off del /s /a *.txt *.exe *.suo *.ncb *.user *.dll *.pdb *.netmodule *.aps *.ilk 2>nul FOR ...