小匠第一周期打卡笔记-Task02
一、文本预处理
预处理通常包括四个步骤:
读入文本
分词
建立字典,将每个词映射到一个唯一的索引(index)
将文本从词的序列转换为索引的序列,方便输入模型
读入文本:
import collections
import re def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines lines = read_time_machine()
print('# sentences %d' % len(lines))
分词:
将一个句子划分成若干个词(token),转换为一个词的序列
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token) tokens = tokenize(lines)
tokens[0:2]
建立字典:
将字符串转换为数字。先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx def __len__(self):
return len(self.idx_to_token) def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens] def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices] def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
'''vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[0:10])
[('', 0), ('the', 1), ('time', 2), ('machine', 3), ('by', 4), ('h', 5), ('g', 6), ('wells', 7), ('i', 8), ('traveller', 9)]'''
将词转为索引:
使用字典,将原文本中的句子从单词序列转换为索引序列
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
小结:
用现有工具进行分词:
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
- 标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
- 类似“shouldn't", "doesn't"这样的词会被错误地处理
- 类似"Mr.", "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
无论 use_special_token 参数是否为真,都会使用特殊token——<unk>,用来表示未登录词。
句子长度统计与构建字典无关
二、语言模型
作用:给定一长度为T的词的序列W1,W2, W3,....,WT,语言模型的目标是评估该序列是否合理,即计算该序列的概率:
P(W1,W2, W3,....,WT)
概率大合理,小则不合理
语言模型:
假设序列W1,W2, W3,....,WT,每个词都是依次生成的,那么:P(W1,W2, W3,....,WT) = ∏Tt=1 P(wt | w1,....,wt-1 )
语言模型的参数就是次的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,W1的概率可以计算为:

n元语法:
马尔可夫假设:
一个词的出现只与前面n个词相关,即n阶马尔可夫链(Markov chain of order n)
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。如果n=1,那么有P(w3∣w1,w2)=P(w3∣w2)。基于n−1阶马尔可夫链,我们可以将语言模型改写为P(W1,W2, W3,....,WT) = ∏Tt=1 P(wt | wt-(n-1),....,wt-1 ).也叫做n元语法,是基于n−1阶马尔可夫链的概率语言模型当n分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。当n较小时,n元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当n较大时,n元语法需要计算并存储大量的词频和多词相邻频率。
所以n元语法缺陷:参数空间过大,数据稀疏。
字符索引
时序数据的采样
列的长度为T,时间步数为n,那么一共有T−n个合法的样本,但是这些样本有大量的重合,我们通常采用更加高效的采样方式。
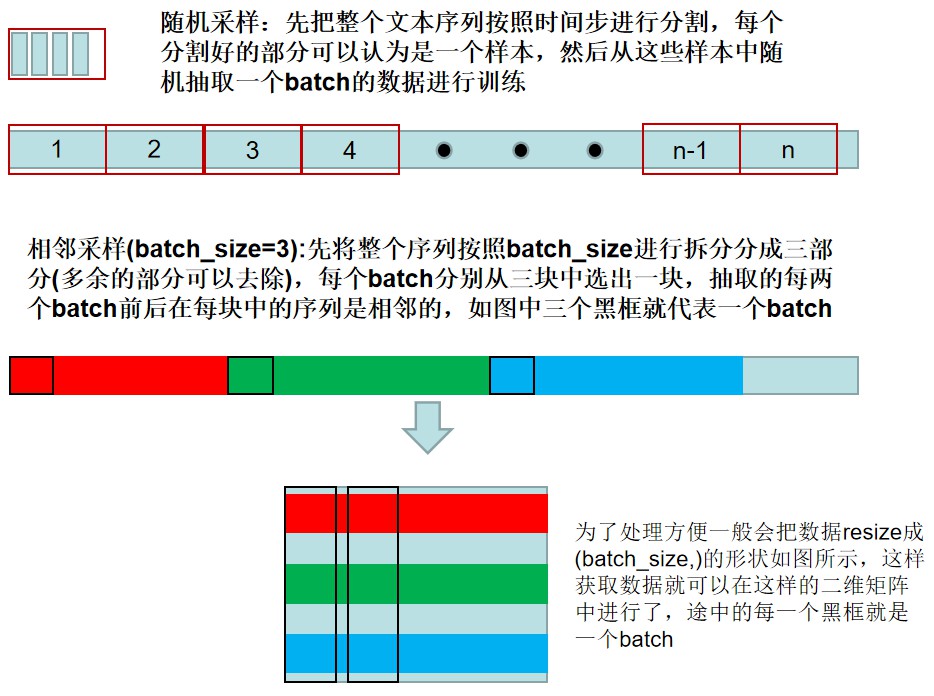
随机采样
每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。 在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
采样小结
代码实现:
建立字符索引:
idx_to_char = list(set(corpus_chars)) # 去重,得到索引到字符的映射
char_to_idx = {char: i for i, char in enumerate(idx_to_char)} # 字符到索引的映射
vocab_size = len(char_to_idx)
print(vocab_size) corpus_indices = [char_to_idx[char] for char in corpus_chars] # 将每个字符转化为索引,得到一个索引的序列
sample = corpus_indices[: 20]
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
定义函数load_data_jay_lyrics :
def load_data_jay_lyrics():
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices, char_to_idx, idx_to_char, vocab_size
随机取样:
import torch
import random
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
# 减1是因为对于长度为n的序列,X最多只有包含其中的前n - 1个字符
num_examples = (len(corpus_indices) - 1) // num_steps # 下取整,得到不重叠情况下的样本个数
example_indices = [i * num_steps for i in range(num_examples)] # 每个样本的第一个字符在corpus_indices中的下标
random.shuffle(example_indices) def _data(i):
# 返回从i开始的长为num_steps的序列
return corpus_indices[i: i + num_steps]
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') for i in range(0, num_examples, batch_size):
# 每次选出batch_size个随机样本
batch_indices = example_indices[i: i + batch_size] # 当前batch的各个样本的首字符的下标
X = [_data(j) for j in batch_indices]
Y = [_data(j + 1) for j in batch_indices]
yield torch.tensor(X, device=device), torch.tensor(Y, device=device)
测试:
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
相邻采样:
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_len = len(corpus_indices) // batch_size * batch_size # 保留下来的序列的长度
corpus_indices = corpus_indices[: corpus_len] # 仅保留前corpus_len个字符
indices = torch.tensor(corpus_indices, device=device)
indices = indices.view(batch_size, -1) # resize成(batch_size, )
batch_num = (indices.shape[1] - 1) // num_steps
for i in range(batch_num):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n'
三、循环神经网络基础
知识点记录:
循环神经网络:
目标:
基于循环神经网络实现语言模型,基于当前输入与过去输入的序列,预测序列的下一个字符。
模型设计思路:
循环神经网络引入一个隐藏变量 H,用 Ht 表示H在时间步 t 的值。Ht 的计算基于 Xt 和 Ht-1,可以认为Ht 记录了到当前字符为止的序列信息,利用 Ht 对序列的下一个字符进行预测。
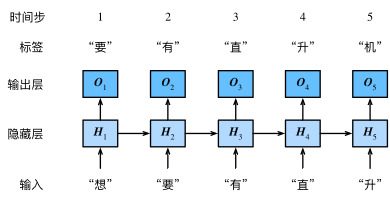
构造:
设Xt ∈ Rn×d 是时间步 t 的小批输入,Ht ∈ Rn×h 是该时间步的隐藏变量,则: Ht = Ø(XtWxh + Ht-1Whh + bh). 其中,Wxh ∈ Rd×h,Whh ∈ Rd×h ,bh ∈ R1×h, Ø 函数是非线性激活函数。因引入 Ht-1Whh ,Ht 能捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。由于Ht 的计算基于Ht-1 ,上式的计算是循环的,使用循环计算的网络即循环神经网络。 在时间步 t ,输出层的输出为: Ot = HtWhq + bq . 其中 Wh'q ∈Rh×q ,bq ∈ R1×q 。
one-hot 向量:
将字符表示成向量,假设词典大小是N,每次字符对应一个从0到N−1的唯一的索引,则该字符的向量是一个长度为N的向量,若字符的索引是i,则该向量的第i个位置为1,其他位置为0。
裁剪梯度:
循环神经网络中较容易出现梯度衰减或梯度爆炸,这会导致网络几乎无法训练。裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 g,并设裁剪的阈值是θ。裁剪后的梯度的L2范数不超过θ。 min(θ/(‖g‖),1)g
困惑度:
用于评价语言模型的好坏,困惑度是对交叉熵损失函数做指数运算后得到的值。特别地:
最佳状况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
任何一个有效模型的困惑度必须小于类别个数。
模型参数
W_xh: 状态-输入权重
W_hh: 状态-状态权重
W_hq: 状态-输出权重
b_h: 隐藏层的偏置
b_q: 输出层的偏置
一个batch的数据的表示
- 如何将一个batch的数据转换成时间步数个(批量大小,词典大小)的矩阵?
- 每个字符都是一个词典大小的向量,每个样本是时间步数个序列,每个batch是批量大小个样本
- 第一个(批量大小,词典大小)的矩阵:取出一个批量样本中每个序列的第一个字符,并将每个字符展开成词典大小的向量,就形成了第一个时间步所表示的矩阵
- 第二个(批量大小,词典大小)的矩阵:取出一个批量样本中每个序列的第二个字符,并将每个字符展开成词典大小的向量,就形成了第二个时间步所表示的矩阵
- 最后就形成了时间步个(批量大小,词典大小)的矩阵,这也就是每个batch最后的形式
隐藏状态的初始化
相邻采样:
采用相邻采样仅在每个训练周期开始的时候初始化隐藏状态是因为相邻的两个批量在原始数据上是连续的
小匠第一周期打卡笔记-Task02的更多相关文章
- 小匠第一周期打卡笔记-Task01
一.线性回归 知识点记录 线性回归输出是一个连续值,因此适用于回归问题.如预测房屋价格.气温.销售额等连续值的问题.是单层神经网络. 线性判别模型 判别模型 性质:建模预测变量和观测变量之间的关系,亦 ...
- 小匠第二周期打卡笔记-Task05
一.卷积神经网络基础 知识点记录: 神经网络的基础概念主要是:卷积层.池化层,并解释填充.步幅.输入通道和输出通道之含义. 二维卷积层: 常用于处理图像数据,将输入和卷积核做互相关运算,并加上一个标量 ...
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- 小匠第二周期打卡笔记-Task04
一.机器翻译及相关技术 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经网络翻译(NMT). 主要特征:输出是单词序列而不是单个单词.输出序列的长度可能与 ...
- 《Linux内核设计与实现》 第一二章学习笔记
<Linux内核设计与实现> 第一二章学习笔记 第一章 Linux内核简介 1.1 Unix的历史 Unix的特点 Unix很简洁,所提供的系统调用都有很明确的设计目的. Unix中一切皆 ...
- 微信小程序生命周期详解
文章出处:https://blog.csdn.net/qq_29712995/article/details/79784222 在我看来小程序的生命周期虽然简单,但是他渗透了小程序开发的整个过程,对于 ...
- 自定义View4-塔防小游戏第一篇:一个防御塔+多个野怪(简易版)*
塔防小游戏 第一篇:一个防御塔+多个野怪(简易版) 1.canvas画防御塔,妖怪大道,妖怪行走路线 2.防御塔攻击范围是按照妖怪与防御塔中心距离计算的,大于防御塔半径则不攻击,小于则攻击 ...
- 微信小程序消息通知-打卡考勤
微信小程序消息通知-打卡考勤 效果: 稍微改一下js就行,有不必要的错误,我就不改了,哈哈! index.js //index.js const app = getApp() // 填写微信小程序ap ...
- 微信小程序生命周期——小程序的生命周期及页面的生命周期。
最近在做微信小程序开发,也发现一些坑,分享一下自己踩过的坑. 生命周期是指一个小程序从创建到销毁的一系列过程. 在小程序中 ,通过App()来注册一个小程序 ,通过Page()来注册一个页面. 首先来 ...
随机推荐
- visual studio2010编译过程中出现COFF文件损坏的原因和方法总结
一.现象描述 笔者在用visual studio2010进行控制台程序进行程序编译时候,经常会遇到代码代码没有语法错误,但是编译不通过的现象.系统报错为 LINK : fatal error LNK1 ...
- 剑指offer-面试题39-数组中出现次数超过一半的数字-快速排序
/* 题目: 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字. 例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}.由于数字2在数组中出现了5次,超过数组长度的一半,因此输 ...
- mac本地安装全局包报错npm WARN checkPermissions
安装本地全局包时,本地报错 npm WARN checkPermissions Missing write access to /Users/xxx/.nvm/versions/node/v11.10 ...
- .net生成PDF文件的几种方式
以下为在.net mvc中,生成pdf的几种方式,资料都是在做项目时网上找的 1.使用Microsoft.Office.Interop.Word.dll将word转换为PDF dll可以单独下载,一般 ...
- 数据库MySQL中关于“多表关联更新”的那些事
在常见的sql中,我们经常在查询中进行多表关联查询,用的比较熟练.今天在开发中遇到一个实际业务场景是多表关联更新,一时不知所措.本着多学习的态度,没有直接写java代码去实现,终于把多表关联更新的sq ...
- 【sklearn】Toy datasets上的分类/回归问题 (XGBoost实践)
分类问题 1. 手写数字识别问题 from sklearn.datasets import load_digits digits = load_digits() # 加载手写字符识别数据集 X = d ...
- iframe在iphone手机上的问题
问题1: 通过document.addEventListener("scroll",function(){})对页面滚动监听事件进行监听,但ios下$(document).scro ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- openlayers画区域
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- 2020 CCPC Wannafly Winter Camp Day1 Div.1& F
#include<bits/stdc++.h> #define forn(i, n) for (int i = 0; i < int(n); i++) #define fore(i, ...