Python爬虫连载3-Post解析、Request类
一、访问网络的两种方法
1.get:利用参数给服务器传递信息;参数为dict,然后parse解码
2.post:一般向服务器传递参数使用;post是把信息自动加密处理;如果想要使用post信息,需要使用到data参数
3.Content-Type:application/x-www.form-urlencode
4.Content-Length:数据长度
5.简而言之,一旦更改请求方法,请注意其他请求头信息相适应
6.urllib.parse.urlencode可以将字符串自动转换为上面的信息。
案例:利用parse模块模拟post请求分析百度翻译:分析步骤:
(1)打开谷歌浏览器,F12
(2)尝试输入单词girl,发想每敲击一个字母后都会有一个请求
(3)请求地址是:http://fanyi.baidu.com/sug
(4)打开network-XHR-sug
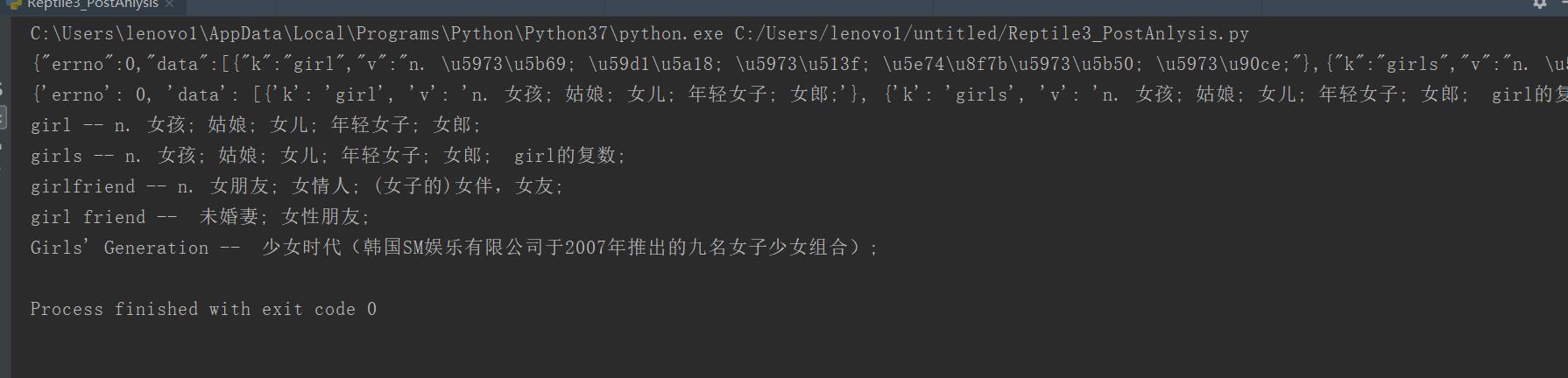
from urllib import request,parse
#负责处理json格式的模块
import json
"""
大致流程:
(1)利用data构造内容,然后urlopen打开
(2)返回一个json格式的结果
(3)结果就应该是girl的释义
"""
baseurl = "https://fanyi.baidu.com/sug"
#存放迎来模拟form的数据一定是dict格式
data = {
#girl是翻译输入的英文内容,应该是由用户输入,此处使用的是硬编码
"kw":"girl"
}
#需要使用parse模块对data进行编码
data = parse.urlencode(data).encode("utf-8")
#我们需要构造一个请求头,请求头应该至少包含传入的数据的长度
#request要求传入的请求头是一个dict格式
headers = {
#因为使用了post,至少应该包含content-length字段
"Content-length":len(data)
}
#有了headers,data,url就可以尝试发出请求了
rsp = request.urlopen(baseurl,data=data)#,headers=headers
json_data = rsp.read().decode()
print(json_data)
#把json字符串转化为字典
json_data = json.loads(json_data)
print(json_data)
for item in json_data["data"]:
print(item["k"],"--",item["v"])
二、为了更多的设置请求信息,单纯的通过urlopen函数已经不太好用了;需要利用request.Request类
这里只修改一部分代码,其他的代码都不变,依然可以得到相同的结果。
#构造一个Request的实例,就是借用这个类,来把能够传入的头信息进行封装扩展 req = request.Request(url=baseurl,data=data,headers=headers) #有了headers,data,url就可以尝试发出请求了 rsp = request.urlopen(req)#,headers=headers
三、源码
Reptile3_PostAnlysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile3_PostAnlysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

Python爬虫连载3-Post解析、Request类的更多相关文章
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- Python爬虫连载1-urllib.request和chardet包使用方式
一.参考资料 1.<Python网络数据采集>图灵工业出版社 2.<精通Python爬虫框架Scrapy>人民邮电出版社 3.[Scrapy官方教程](http://scrap ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
随机推荐
- Spring注解开发系列Ⅴ --- 自动装配&Profile
自动装配: spring利用依赖注入和DI完成对IOC容器中各个组件的依赖关系赋值.自动装配的优点有: 自动装配可以大大地减少属性和构造器参数的指派. 自动装配也可以在解析对象时更新配置. 自动装配的 ...
- 连接redis出现错误:Cannot get Jedis connection
错误信息: 错误描述:由于我的redis数据库没有设置密码,配置连接的时候我配置了密码为空,导致连接失败
- springIOC源码接口分析(十一):ConfigurableApplicationContext
一 实现接口 关系图: ConfigurableApplicationContext接口实现了三个接口,ApplicationContext, Lifecycle, Closeable, Applic ...
- 在python3 encode和decode 的使用
说这个问题之前必须的介绍关于编码的在我们这的发展: 首先电脑能识别的最初的语言是二进制 ---010101这种 然后在是我们知道的ASSIC码 再过了就是 gb2312----------->g ...
- Idea | Load error: undefined path variables
Load error: undefined path variables 案例 今天打开idea项目,突然间出现如下异常: Load error: undefined path variables 类 ...
- 一文教你一次性完成Helm 3迁移
2019年,Kubernetes软件包管理器--Helm发布了最新版本Helm 3,并且该版本已经stable.Helm 3中的一些关键特性我们在之前的文章中已经介绍过,其中一些功能吸引了许多开发人员 ...
- 如何在OpenStack中对云主机类型进行重新配置
目标:很多用户在OpenStack启动一个虚拟机,选择了一个云主机配置类型,例如2CPU 4GB内存,使用了一段时间,感觉这个配置并不能满足需求,所以希望能够提高配置,那么OpeNStack的管理界面 ...
- LR中解决接口请求中包含中文字符,服务器不识别的问题
在LR中,直接写的接口请求,如果请求字段包含中文字段,服务器会不识别,这个时候就要用到lr_convert_string_encoding这个函数: 具体用法: lr_convert_string_e ...
- Linq扩展方法获取单个元素
在使用Linq 提供的扩展方法时,First(OrDefault), Single(OrDefault), Last(OrDefault)都具有返回单个元素的功能.MSDN对这些方法的描述只有功能说明 ...
- 【Java并发工具类】Semaphore
前言 1965年,荷兰计算机科学家Dijkstra提出的信号量机制成为一种高效的进程同步机制.这之后的15年,信号量一直都是并发编程领域的终结者.1980年,管程被提出,成为继信号量之后的在并发编程领 ...