python 基础篇 16 递归和二分数查找与编码补充回顾
编码回顾补充:
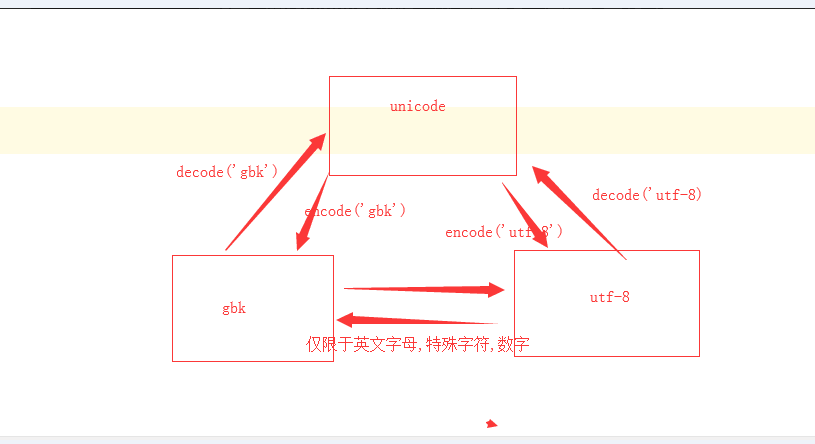
回顾编码问题:
编码相当于密码本,关系到二进制与看懂的文字的的对应关系.
最早期的密码本:
ascii码:只包含英文字母,数字,特殊字符.
0000 0001:
'fjdskal 我发'
字符:组成你看到的内容的最小单位就是字符.
位:二进制中占有的位置,就是位.
字节:8位表示一个字节.
对于ascii码,一个字符是用8位一个字节去表示.
A: 01000001
unicode 万国码:将全世界所有的文字都给我汇总到一起.
起初:unicode:
一个字符用16位表示.
A: 0000 0000 0000 0010
中:0000 0000 1000 0010
最终unicode:
一个字符用32位表示.
A: 0000 0000 0000 0010 0000 0000 0000 0010
中:0000 0000 1000 0010 0000 0000 1000 0010
浪费,占用资源.
utf-8: 最少用8位表示一个字符.对unicode升级,
A: 01000001
欧洲文字: 0000 0000 1000 0010
亚洲文字: 0000 0010 0000 0000 1000 0010
gbk: 国标
英文字母:一个字节表示.中文两个字节表示.
A: 01000001
中:0000 0000 1000 0010
前提:
文件的存储和传输 不能用unicode编码
除了unicode 剩下的编码方式不能直接识别.
python3x版本.
int
str ----> 在内存中用的unicode
bytes类型
list
bool
dict
set
tuple
英文:
str:
表现形式: s = 'oldboy'
内部编码: unicode
bytes:
表现形式: b1 = b'oldboy'
内部编码: 非unicode
中文:
str:
表现形式: s = '中国'
内部编码: unicode
bytes:
表现形式: b1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
内部编码: 非unicode
# s1 = '中国'
# b1 = s1.encode('gbk')
# print(b1)
# b2 = b1.decode('gbk').encode('utf-8')
# print(b2)
# s1 = 'zhong'
# b1 = s1.encode('utf-8')
# print(b1)
# print(b1.decode('gbk'))
------------->>>>>>>>>>>>>递归函数<<<<<<<<<<<<<<--------------------------
递归函数:在一个函数里在调用这个函数本身。
递归的最大深度:998
正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去。但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997(只要997!你买不了吃亏,买不了上当...).
拿什么来证明这个“998理论”呢?这里我们可以做一个实验:
def foo(n):
print(n)
n +=
foo(n)
foo()
由此我们可以看出,未报错之前能看到的最大数字就是998.当然了,997是python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
import sys
print(sys.setrecursionlimit())
我们可以通过这种方式来修改递归的最大深度,刚刚我们将python允许的递归深度设置为了10w,至于实际可以达到的深度就取决于计算机的性能了。不过我们还是不推荐修改这个默认的递归深度,因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决要么是你代码写的太烂了~~~
示例讲解------------->>>>>>>>>>>
例一:
现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。
你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。
你又问武sir,武sir也不告诉你,他说他比太白大两岁。
那你问太白,太白告诉你,他18了。
这个时候你是不是就知道了?alex多大?

递归实例:
def age(n):
if n == :
return
else:
return age(n-)+ print(age())
----------------------->>>>>>>>>>>>>>>>>>二分数查找<<<<<<<<<<<<<<<<<-----------------------------
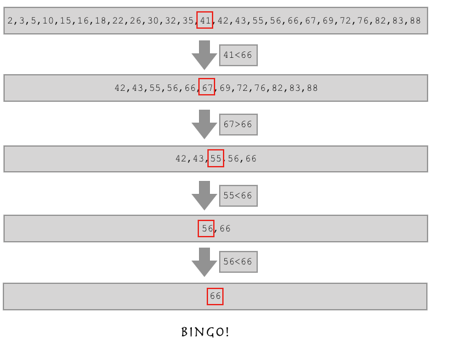
如果有这样一个列表,让你从这个列表中找到66的位置,你要怎么做?
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你说,so easy!
l.index(66)...
我们之所以用index方法可以找到,是因为python帮我们实现了查找方法。如果,index方法不给你用了。。。你还能找到这个66么?
l = [,,,,,,,,,,,,,,,,,,,,,,,,] i =
for num in l:
if num == :
print(i)
i+=
上面这个方法就实现了从一个列表中找到66所在的位置了。
但我们现在是怎么找到这个数的呀?是不是循环这个列表,一个一个的找的呀?假如我们这个列表特别长,里面好好几十万个数,那我们找一个数如果运气不好的话是不是要对比十几万次?这样效率太低了,我们得想一个新办法。
二分查找算法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你观察这个列表,这是不是一个从小到大排序的有序列表呀?
如果这样,假如我要找的数比列表中间的数还大,是不是我直接在列表的后半边找就行了?
注意:列表必须是有序的,
我们知道2**16等于65536,也就是说,如果一个列表里有六万个数字,我们用二分数查找,最多16次就可 以找到目标值.
这就是二分查找算法!
那么落实到代码上我们应该怎么实现呢?
简单版二分法
l = [,,,,,,,,,,,,,,,,,,,,,,,,] def func(l,aim):
mid = (len(l)-)//
if l:
if aim > l[mid]:
func(l[mid+:],aim)
elif aim < l[mid]:
func(l[:mid],aim)
elif aim == l[mid]:
print("bingo",mid)
else:
print('找不到')
func(l,)
func(l,)
升级版二分法
l1 = [, , , , , ]
def two_search(l,aim,start=,end=None):
end = len(l)- if end is None else end
mid_index = (end - start) // 2 + start
if end >= start:
if aim > l[mid_index]:
return two_search(l,aim,start=mid_index+,end=end) elif aim < l[mid_index]:
return two_search(l,aim,start=start,end=mid_index-) elif aim == l[mid_index]:
return mid_index
else:
return '没有此值'
else:
return '没有此值'
print(two_search(l1,))
人理解函数,神理解递归!可以用下边的方法多跑几次程序,慢慢理解!!!
python 基础篇 16 递归和二分数查找与编码补充回顾的更多相关文章
- Python基础篇_实例练习(二)
问题1:假设有同学A,A每周在工作日进步,周末退步,问一年(365天)后A同学是一年前的几倍? 工作日进步由用户输入,周末下降0.01即1% deyup = eval(input()) deyfact ...
- python基础篇(二)
PYTHON基础篇(二) if:else,缩进 A:if的基础格式和缩进 B:循环判断 C:range()函数和len()函数 D:break,contiue和pass语句 for,while循环 函 ...
- Python基础篇(二)_基本数据类型
Python基础篇——基本数据类型 数字类型:整数类型.浮点数类型.复数类型 整数类型:4种进制表示形式:十进制.二进制.八进制.十六进制,默认采用十进制,其他进制需要增加引导符号 进制种类 引导符号 ...
- python基础篇(六)
PYTHON基础篇(六) 正则模块re A:正则表达式和re模块案例 B:re模块的内置方法 时间模块time A:时间模块的三种表示方式 B:时间模块的相互转换 随机数模块random A:随机数模 ...
- python基础篇(四)
PYTHON基础篇(四) 内置函数 A:基础数据相关(38) B:作用域相关(2) C:迭代器,生成器相关(3) D:反射相关(4) E:面向对象相关(9) F:其他(12) 匿名函数 A:匿名函数基 ...
- python基础篇(五)
PYTHON基础篇(五) 算法初识 什么是算法 二分查找算法 ♣一:算法初识 A:什么是算法 根据人们长时间接触以来,发现计算机在计算某些一些简单的数据的时候会表现的比较笨拙,而这些数据的计算会消耗大 ...
- python基础篇(三)
PYTHON基础篇(三) 装饰器 A:初识装饰器 B:装饰器的原则 C:装饰器语法糖 D:装饰带参数函数的装饰器 E:装饰器的固定模式 装饰器的进阶 A:装饰器的wraps方法 B:带参数的装饰器 C ...
- 面试题之第一部分(Python基础篇) 80题
第一部分(python基础篇)80题 为什么学习Python?==*== # 1. python应用于很多领域,比如后端,前端,爬虫,机器学习(人工智能)等方面,几乎能涵盖各个开发语言的领域,同时它相 ...
- python基础篇-day1
python基础篇 python是由C语言写的: pass 占位符: del,python中全局的功能,删除内存中的数据: 变量赋值的方法: user,pass = 'freddy','freddy1 ...
随机推荐
- 10474 - Where is the Marble?(模拟)
传送门: UVa10474 - Where is the Marble? Raju and Meena love to play with Marbles. They have got a lot o ...
- 前端DOM知识点
DOM即文档对象模型(Document Object Model,DOM)是一种用于HTML和XML文档的编程接口.它给文档提供了一种结构化的表示方法,可以改变文档的内容和呈现方式.DOM把网页和脚本 ...
- LinkedList---链表各种方法的实现
public class ListExer2 { public static void main(String[] args) { LinkList list = new LinkList(); li ...
- Struts2 第四讲 -- Struts2的基本配置
5.struts2的基本配置 5.1 struts2的访问连接url 在struts1中,通过<action path=“/primer/helloWorldAction.action”> ...
- Java 基础标识符
标识符: 程序员为自己定义的类,方法或者变量等起的名称. 标识符由大写字母,数字,下划线(_)和美元符号组成,但不能以数字开头.Java 语言中严格区分大小写. 包名: 使用小写字母. 类名和接口名: ...
- git简单配置
1.安装完git查看版本 git --version 2.配置用户名邮箱 git config --global user.name "chencheng" git config ...
- atan和atan2反正切计算
typedef struct point { double x, y; }point; //给定两个点 point a(x1,y1),b(x2,y2); 使用反三角函数atan求斜率,原型如下 flo ...
- 思维导图 XMind 8 Update 8 Pro for Mac 中文破解版
破解包下载地址 在官网下载8版本就可以了
- struts2的token interceptor
关于struts2的token拦截器的说明 原理:struts2的token interceptor是关于重复提交的拦截器,其实现是:在form表单中加入token标签,如下: <form ac ...
- 初次了解MVC框架模式
MVC框架:即Model.View.Controller即模型.视图.控制器. View层是界面,Model层是业务逻辑,Controller层用来调度View层和Model层,将显示界面和业务逻辑合 ...