数据结构7——BFS
一、重拾关键
宽度优先搜索,也有称为广度优先搜索,简称BFS。类似于树的按层次遍历的过程。
初始状态:图G所有顶点均未被访问过,任选一点v。
遍历过程:假设从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程中以v为起始点,由近至远,依次访问和v有路径相通且路径长度为1,2,…的顶点。
二、算法过程
以如下图的无向图G4为例,进行图的宽度优先搜索:
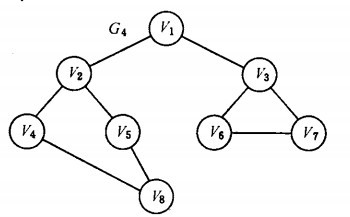
假设从顶点v1出发进行搜索,首先访问v1和v1的邻接点v2和v3,然后依次访问v2的邻接点v4和v5及v3的邻接点v6和v7,最后访问v4的邻接点v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由些完成了图的遍历。得到的顶点访问序列为: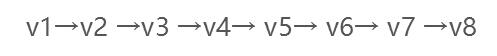 。
。
和深度优先搜索类似,在遍历的过程中也需要一个访问标志数组。并且,为了顺次访问路径长度为2、3、…的顶点,需附设队列以存储已被访问的路径长度为1、2、… 的顶点。
三、代码实现
邻接矩阵做存储结构时,广度优先搜索的代码如下。
/* 图的BFS遍历 */
//邻接矩阵形式实现
//顶点从1开始
#include<iostream>
#include<cstdio>
#include<queue>
using namespace std;
const int maxn = 105; //最大顶点数
typedef int VertexType; //顶点类型
bool vis[maxn]; struct Graph{ //邻接矩阵表示的图结构
VertexType vex[maxn]; //存储顶点
int arc[maxn][maxn]; //邻接矩阵
int vexnum,arcnum; //图的当前顶点数和弧数
}; void createGraph(Graph &g) //构建有向网g
{
cout<<"请输入顶点数和边数:";
cin>>g.vexnum>>g.arcnum; //构造顶点向量
cout<<"请依次输入各顶点:\n";
for(int i=1;i<=g.vexnum;i++){
scanf("%d",&g.vex[i]);
} //初始化邻接矩阵
for(int i=1;i<=g.vexnum;i++){
for(int j=1;j<=g.vexnum;j++){
g.arc[i][j] = 0;
}
} //构造邻接矩阵
VertexType u,v; //分别是一条弧的弧尾(起点)和弧头(终点)
printf("每一行输入一条弧依附的顶点(空格分开):\n");
for(int i=1;i<=g.arcnum;i++){
cin>>u>>v;
g.arc[u][v] = g.arc[v][u] = 1;
}
} //邻接矩阵的宽度遍历操作
void BFSTraverse(Graph g)
{
queue<int> q; //声明队列q
for(int i=1;i<=g.vexnum;i++){
vis[i] = false;
}
for(int i=1;i<=g.vexnum;i++){ //对每个顶点做循环
if(!vis[i]){
vis[i] = true;
printf("%d\t",g.vex[i]);
q.push(i); //将此节点入队列
while(!q.empty()){
int m = q.front();
q.pop(); //出队列,值已赋给m
for(int j=1;j<=g.vexnum;j++){
if(g.arc[m][j]==1 && !vis[j]){ //如果顶点j是顶点i的未访问的邻接点
vis[j] = true;
printf("%d\t",g.vex[j]);
q.push(j); //将顶点j入队列
}
} }
}
} } int main()
{
Graph g;
createGraph(g);
BFSTraverse(g);
return 0;
}
我的代码2:
int n, m;
int graph[][];
bool vis[];
queue<int> q; void init()
{
memset(map,,sizeof(map));
memset(vis,,sizeof(vis));
while(!q.empty()) q.pop();
} void BFS(int u)
{
vis[u] = ;
cout<<u<<"\t";
q.push(u);
while(!q.empty()){
int p = q.front();
q.pop();
for(int i=;i<=n;i++){
if(!vis[i] && graph[p][i]==){
q.push(i);
cout<<i<<"\t";
vis[i] = ;
}
}
}
} void read()
{
init();
cin>>n>>m;
for(int i=;i<=m;i++){
int u, v;
cin>>u>>v;
graph[u][v] = graph[v][u] = ;
}
for(int i=;i<=n;i++){
if(!vis[i])
BFS(i);
}
cout<<endl;
} int main()
{
read();
return ;
}

对于邻接表的广度优先遍历,代码与邻接矩阵差异不大, 代码如下。
//邻接表的广度遍历算法
void BFSTraverse(GraphList g)
{
int i;
EdgeNode *p;
Queue q;
for(i = 0; i < g.numVertexes; i++)
{
visited[i] = FALSE;
}
InitQueue(&q);
for(i = 0; i < g.numVertexes; i++)
{
if(!visited[i])
{
visited[i] = TRUE;
printf("%c ", g.adjList[i].data); //打印顶点,也可以其他操作
EnQueue(&q, i);
while(!QueueEmpty(q))
{
int m;
DeQueue(&q, &m);
p = g.adjList[m].firstedge; 找到当前顶点边表链表头指针
while(p)
{
if(!visited[p->adjvex])
{
visited[p->adjvex] = TRUE;
printf("%c ", g.adjList[p->adjvex].data);
EnQueue(&q, p->adjvex);
}
p = p->next;
}
}
}
}
}
分析上述算法,每个顶点至多进一次队列。遍历图的过程实质是通过边或弧找邻接点的过程,因此广度优先搜索遍历图的时间复杂度和深度优先搜索遍历相同,两者不同之处仅仅在于对顶点访问的顺序不同。
四、沙场练兵
题目一、迷宫问题
数据结构7——BFS的更多相关文章
- 【暑假】[基本数据结构]根据BFS与DFS确定树
UVa10410 Tree Reconstruction 算法:根据BFS构造pos数组以区分关系,在此基础上对DFS序列操作.注:栈中存父结点,栈顶是最优先的父结点. 代码如下: #include& ...
- 用js来实现那些数据结构16(图02-图的遍历)
上一篇文章我们简单介绍了一下什么是图,以及用JS来实现一个可以添加顶点和边的图.按照惯例,任何数据结构都不可或缺的一个point就是遍历.也就是获取到数据结构中的所有元素.那么图当然也不例外.这篇文章 ...
- Uva 1599 最佳路径
题目链接:https://uva.onlinejudge.org/external/15/1599.pdf 题意: 保证在最短路的时候,输出字典序最小的路径. 方法: 路径上有了权值,可以利用图论的数 ...
- Codeforces 605D - Board Game(树状数组套 set)
Codeforces 题目传送门 & 洛谷题目传送门 事实上是一道非常容易的题 很容易想到如果 \(c_i\geq a_j\) 且 \(d_i\geq b_j\) 就连一条 \(i\to j\ ...
- 数据结构 《2》----基于邻接表表示的图的实现 DFS(递归和非递归), BFS
图通常有两种表示方法: 邻接矩阵 和 邻接表 对于稀疏的图,邻接表表示能够极大地节省空间. 以下是图的数据结构的主要部分: struct Vertex{ ElementType element; // ...
- 数据结构学习笔记05图 (邻接矩阵 邻接表-->BFS DFS、最短路径)
数据结构之图 图(Graph) 包含 一组顶点:通常用V (Vertex) 表示顶点集合 一组边:通常用E (Edge) 表示边的集合 边是顶点对:(v, w) ∈E ,其中v, w ∈ V 有向边& ...
- 数据结构和算法总结(一):广度优先搜索BFS和深度优先搜索DFS
前言 这几天复习图论算法,觉得BFS和DFS挺重要的,而且应用比较多,故记录一下. 广度优先搜索 有一个有向图如图a 图a 广度优先搜索的策略是: 从起始点开始遍历其邻接的节点,由此向外不断扩散. 1 ...
- 数据结构与算法之PHP用邻接表、邻接矩阵实现图的广度优先遍历(BFS)
一.基本思想 1)从图中的某个顶点V出发访问并记录: 2)依次访问V的所有邻接顶点: 3)分别从这些邻接点出发,依次访问它们的未被访问过的邻接点,直到图中所有已被访问过的顶点的邻接点都被访问到. 4) ...
- [数据结构]图的DFS和BFS的两种实现方式
深度优先搜索 深度优先搜索,我们以无向图为例. 图的深度优先搜索(Depth First Search),和树的先序遍历比较类似. 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发, ...
随机推荐
- vue-resource+iview上传文件取消上传
vue-resource+iview上传文件取消上传 子组件: <template> <div class="upload-area-div"> <U ...
- mycat常用的分片规则
一.枚举法<tableRule name="sharding-by-intfile"> <rule> <columns>user ...
- SpringBoot非官方教程 | 第十篇: 用spring Restdocs创建API文档
转载请标明出处: 原文首发于:https://www.fangzhipeng.com/springboot/2017/07/11/springboot10-springrestdocs/ 本文出自方志 ...
- 菜鸟笔记 -- Chapter 6.2.1 权限修饰符
6.2.1 权限修饰符 面向对象的三大特性就有封装,封装隐藏了对象的属性和实现细节,仅对外提供公共访问方式,而这个访问方式就是由权限修饰符控制的.Java中的权限修饰符主要包括private.pub ...
- Java实现双向冒泡排序
public class BubbleSort_Two { public static void bubbleSort_Two(int[] list){ //j在最外层定义 boolean needN ...
- SAP ABAP 日期,时间 相关函数
获的两个日期之间的分钟数 data min TYPE i. CALL FUNCTION 'DELTA_TIME_DAY_HOUR' EXPORTING T1 = ' T2 = ' D1 = ' D2 ...
- 小程序swiper不显示图片
按照文档上的代码运行后,发现图片不显示 解决办法: app.wxss文件 align-items: center;这句话删除了,运行 OK!
- JavaScript实现图片切换
页面内容:一个按钮标签 一个Img标签 实现原理:通过修改Img标签的src属性,实现图片的切换 备注:代码中flag变量仅仅用作标记,也可以直接用Img标签的src属性进行判断,不过在判断时候不能 ...
- React学习(1)—— 基础项目搭建以及环境配置
首先,我们需要安装node.js,直接搜索并在官网下载安装包. node.js官网:https://nodejs.org/en/ 现在我们成功安装了node和npm,然后我们来用npm创建新的项目,首 ...
- docker化安装grafana
继续进行docker改造. 1. 找镜像.拉取镜像 [root@devlop ~]# docker search grafana INDEX NAME DESCRIPTION STARS OFFICI ...