每日一个机器学习算法——adaboost
在网上找到一篇好文,直接粘贴过来,加上一些补充和自己的理解,算作此文。
My education in the fundamentals of machine learning has mainly come from Andrew Ng’s excellent Coursera course on the topic. One thing that wasn’t covered in that course, though, was the topic of “boosting” which I’ve come across in a number of different contexts now. Fortunately, it’s a relatively straightforward topic if you’re already familiar with machine learning classification.
Whenever I’ve read about something that uses boosting, it’s always been with the “AdaBoost” algorithm, so that’s what this post covers.
AdaBoost is a popular boosting technique which helps you combine multiple “weak classifiers” into a single “strong classifier”. A weak classifier is simply a classifier that performs poorly, but performs better than random guessing. A simple example might be classifying a person as male or female based on their height. You could say anyone over 5′ 9″ is a male and anyone under that is a female. You’ll misclassify a lot of people that way, but your accuracy will still be greater than 50%.
AdaBoost can be applied to any classification algorithm, so it’s really a technique that builds on top of other classifiers as opposed to being a classifier itself.
You could just train a bunch of weak classifiers on your own and combine the results, so what does AdaBoost do for you? There’s really two things it figures out for you:
1. It helps you choose the training set for each new classifier that you train based on the results of the previous classifier.
2. It determines how much weight should be given to each classifier’s proposed answer when combining the results.
Training Set Selection
Each weak classifier should be trained on a random subset of the total training set. The subsets can overlap–it’s not the same as, for example, dividing the training set into ten portions. AdaBoost assigns a “weight” to each training example, which determines the probability that each example should appear in the training set. Examples with higher weights are more likely to be included in the training set, and vice versa. After training a classifier, AdaBoost increases the weight on the misclassified examples so that these examples will make up a larger part of the next classifiers training set, and hopefully the next classifier trained will perform better on them.
The equation for this weight update step is detailed later on.
adaboost只会训练整个训练集的一个子集,而不是全部。子集从训练集中随机挑选而来,而训练集的每个样本有一个权值,不是每个样本都能被选入子集,adaboost通过权值来决定该样本能进入子集的可能性。
Classifier Output Weights
After each classifier is trained, the classifier’s weight is calculated based on its accuracy. More accurate classifiers are given more weight. A classifier with 50% accuracy is given a weight of zero, and a classifier with less than 50% accuracy (kind of a funny concept) is given negative weight.
根据测试结果计算错误率,从而计算该弱分类器的权值。(不是样本权值)
Formal Definition
To learn about AdaBoost, I read through a tutorial written by one of the original authors of the algorithm, Robert Schapire. The tutorial is available here.
Below, I’ve tried to offer some intuition into the relevant equations.
Let’s look first at the equation for the final classifier.
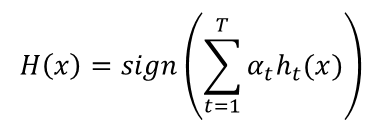
The final classifier consists of ‘T’ weak classifiers. h_t(x) is the output of weak classifier ‘t’ (in this paper, the outputs are limited to -1 or +1). Alpha_t is the weight applied to classifier ‘t’ as determined by AdaBoost. So the final output is just a linear combination of all of the weak classifiers, and then we make our final decision simply by looking at the sign of this sum.
The classifiers are trained one at a time. After each classifier is trained, we update the probabilities of each of the training examples appearing in the training set for the next classifier.
The first classifier (t = 1) is trained with equal probability given to all training examples. After it’s trained, we compute the output weight (alpha) for that classifier.
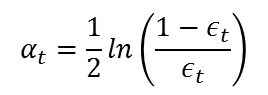
The output weight, alpha_t, is fairly straightforward. It’s based on the classifier’s error rate, ‘e_t’. e_t is just the number of misclassifications over the training set divided by the training set size.
Here’s a plot of what alpha_t will look like for classifiers with different error rates.
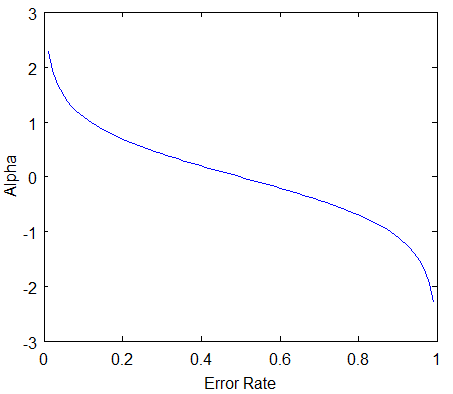
There are three bits of intuition to take from this graph:
- The classifier weight grows exponentially as the error approaches 0. Better classifiers are given exponentially more weight.
- The classifier weight is zero if the error rate is 0.5. A classifier with 50% accuracy is no better than random guessing, so we ignore it.
- The classifier weight grows exponentially negative as the error approaches 1. We give a negative weight to classifiers with worse worse than 50% accuracy. “Whatever that classifier says, do the opposite!”.
After computing the alpha for the first classifier, we update the training example weights using the following formula.
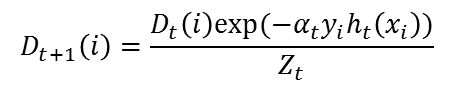
The variable D_t is a vector of weights, with one weight for each training example in the training set. ‘i’ is the training example number. This equation shows you how to update the weight for the ith training example.
The paper describes D_t as a distribution. This just means that each weight D(i) represents the probability that training example i will be selected as part of the training set.
To make it a distribution, all of these probabilities should add up to 1. To ensure this, we normalize the weights by dividing each of them by the sum of all the weights, Z_t. So, for example, if all of the calculated weights added up to 12.2, then we would divide each of the weights by 12.2 so that they sum up to 1.0 instead.
This vector is updated for each new weak classifier that’s trained. D_t refers to the weight vector used when training classifier ‘t’.
This equation needs to be evaluated for each of the training samples ‘i’ (x_i, y_i). Each weight from the previous training round is going to be scaled up or down by this exponential term.
To understand how this exponential term behaves, let’s look first at how exp(x) behaves.
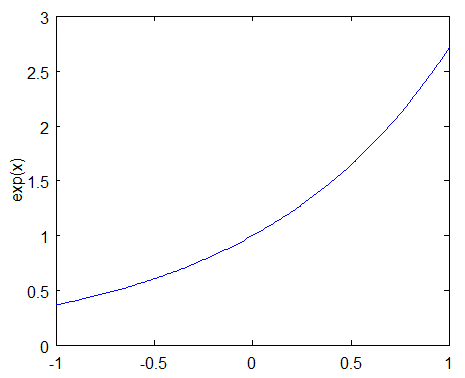
The function exp(x) will return a fraction for negative values of x, and a value greater than one for positive values of x. So the weight for training sample i will be either increased or decreased depending on the final sign of the term “-alpha * y * h(x)”. For binary classifiers whose output is constrained to either -1 or +1, the terms y and h(x) only contribute to the sign and not the magnitude.
y_i is the correct output for training example ‘i’, and h_t(x_i) is the predicted output by classifier t on this training example. If the predicted and actual output agree, y * h(x) will always be +1 (either 1 * 1 or -1 * -1). If they disagree, y * h(x) will be negative.
Ultimately, misclassifications by a classifier with a positive alpha will cause this training example to be given a larger weight. And vice versa.
Note that by including alpha in this term, we are also incorporating the classifier’s effectiveness into consideration when updating the weights. If a weak classifier misclassifies an input, we don’t take that as seriously as a strong classifier’s mistake.
概括的说,-h*y的结果可能为1或者-1,而alpha则是一个可正可负的数,和错误率的变化是相反的,错误率越小,alpha越大。若错误率小于1/2,则alpha>0,此刻,对于正确分类的样本,样本权值减小,对于误分类的样本,权值加大。如果错误率大于1/2,则alpha<0,此刻,对于正确分类的样本,权值加大,对于误分类的样本,权值减小。
可以这样理解,错误率较低的分类器,ok,对于被正确分类的样本而言表现不错,我们应该更关注那些被错分的样本。也就是说当前分类器对正确分类的样本辨识度较高。错误率较高的分类器,对于被正确分类的样本而言表现都很差,也就是说,当前分类器对正确分类的样本的辨识度都不高,那么就不应该急着去分类那些被错分的样本,还是规规矩矩把当前的样本分好再说。
Practical Application
One of the biggest applications of AdaBoost that I’ve encountered is the Viola-Jones face detector, which seems to be the standard algorithm for detecting faces in an image. The Viola-Jones face detector uses a “rejection cascade” consisting of many layers of classifiers. If at any layer the detection window is not recognized as a face, it’s rejected and we move on to the next window. The first classifier in the cascade is designed to discard as many negative windows as possible with minimal computational cost.
In this context, AdaBoost actually has two roles. Each layer of the cascade is a strong classifier built out of a combination of weaker classifiers, as discussed here. However, the principles of AdaBoost are also used to find the best features to use in each layer of the cascade.
The rejection cascade concept seems to be an important one; in addition to the Viola-Jones face detector, I’ve seen it used in a couple of highly-cited person detector algorithms (here and here). If you’re interested in learning more about the rejection cascade technique, I recommend reading the original paper, which I think is very clear and well written. (Note that the topics of Haar wavelet features and integral images are not essential to the concept of rejection cascades).
adaboost官方算法流程图:

每日一个机器学习算法——adaboost的更多相关文章
- 每日一个机器学习算法——k近邻分类
K近邻很简单. 简而言之,对于未知类的样本,按照某种计算距离找出它在训练集中的k个最近邻,如果k个近邻中多数样本属于哪个类别,就将它判决为那一个类别. 由于采用k投票机制,所以能够减小噪声的影响. 由 ...
- 每日一个机器学习算法——LR(逻辑回归)
本系列文章用于汇集知识点,查漏补缺,面试找工作之用.数学公式较多,解释较少. 1.假设 2.sigmoid函数: 3.假设的含义: 4.性质: 5.找一个凸损失函数 6.可由最大似然估计推导出 单个样 ...
- 机器学习算法-Adaboost
本章内容 组合类似的分类器来提高分类性能 应用AdaBoost算法 处理非均衡分类问题 主题:利用AdaBoost元算法提高分类性能 1.基于数据集多重抽样的分类器 - AdaBoost 长处 泛化错 ...
- ML(6)——改进机器学习算法
现在我们要预测的是未来的房价,假设选择了回归模型,使用的损失函数是: 通过梯度下降或其它方法训练出了模型函数hθ(x),当使用hθ(x)预测新数据时,发现准确率非常低,此时如何处理? 在前面的章节中我 ...
- 机器学习算法的Python实现 (1):logistics回归 与 线性判别分析(LDA)
先收藏............ 本文为笔者在学习周志华老师的机器学习教材后,写的课后习题的的编程题.之前放在答案的博文中,现在重新进行整理,将需要实现代码的部分单独拿出来,慢慢积累.希望能写一个机器学 ...
- 机器学习之Adaboost (自适应增强)算法
注:本篇博文是根据其他优秀博文编写的,我只是对其改变了知识的排序,另外代码是<机器学习实战>中的.转载请标明出处及参考资料. 1 Adaboost 算法实现过程 1.1 什么是 Adabo ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
随机推荐
- 【hdoj_2124】RepairTheWall
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2124 思路:贪心法.由于要求所需的块儿(block)的最小数目,先把所有的块儿加起来,看看大小是否> ...
- api接口思路介绍
现在很流行api了,但各种api做法不一样,下面我整理了一些自己的想法,也是看了各大门户网站开放的api应用想到的,与大家分享分享,高手跳过. API(Application Programmin ...
- HDU 6273.Master of GCD-差分数组 (2017中国大学生程序设计竞赛-杭州站-重现赛(感谢浙江理工))
Super-palindrome 题面地址:http://acm.hdu.edu.cn/downloads/CCPC2018-Hangzhou-ProblemSet.pdf 这道题是差分数组的题目,线 ...
- HDU 2700 Parity(字符串,奇偶性)
Parity Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- 利用PyPDF2删除PDF文件首页
前话:有个朋友让我给他编辑他们公司的PDF文件,签名的日期时间不对,需要进(nong)行(xu)优(zuo)化(jia).而我手上只有两个管理pdf的软件,一个福晰阅读器,还有一个福晰编辑器.但是阅读 ...
- NGUI_Sprites
一.UI Sprites 控件: Sprites控件是NGUI的基础控件,几乎可以这么说所有的控件都可以基于Sprites控件添加 Box Collider然后进行附加相关的脚本组件来达到想要的插件效 ...
- 简单工厂模式(Factory)
设计模式序言:这是开始学习设计模式的第一步,也是相对简单的一个设计模式,简单工厂设计模式. 简单工厂就是将业务进行封装,减少代码之间的耦合度,使代码更易于扩展和维护. 以下是简单工厂设计模式的图解: ...
- luogu P1623 [CEOI2007]树的匹配Treasury
题目链接 luogu P1623 [CEOI2007]树的匹配Treasury 题解 f[i][0/1]表示当前位置没用/用了 转移暴力就可以了 code // luogu-judger-enable ...
- [CSAcademy]Connected Tree Subgraphs
题目大意: 给你一棵n个结点的树,求有多少种染色方案,使得染色过程中染过色的结点始终连成一块. 思路: 树形DP. 设f[x]表示先放x时,x的子树中的染色方案数,y为x的子结点. 则f[x]=pro ...
- acitivity 和fragment 通信,使用广播来传递信息的问题
使用广播来传递信息时 如果 acitivity 给 太快给 fragment 发送广播,fragment 收不到 使用回调的方式来解决