ByteBuffer 字节缓冲区
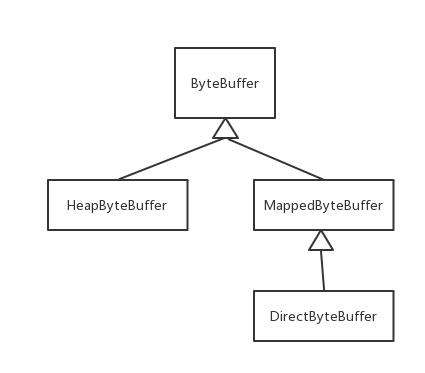
| HeapByteBuffer | 在jvm堆上面的一个buffer,底层的本质是一个数组 | 由于内容维护在jvm里,所以把内容写进buffer里速度会快些;并且,可以更容易回收 |
| DirectByteBuffer | 底层的数据其实是维护在操作系统的内存中,而不是jvm里,DirectByteBuffer里维护了一个引用address指向了数据,从而操作数据 | 跟外设(IO设备)打交道时会快很多,因为外设读取jvm堆里的数据时,不是直接读取的,而是把jvm里的数据读到一个内存块里,再在这个块里读取的,如果使用DirectByteBuffer,则可以省去这一步,实现zero copy |
ByteBuffer的属性
byte[] buff //buff即内部用于缓存的数组。
position //当前读取的位置。
mark //为某一读过的位置做标记,便于某些时候回退到该位置。
capacity //初始化时候的容量。是它所包含的元素的数量,缓冲区的容量不能为负并且不能更改
limit //当写数据到buffer中时,limit一般和capacity相等,当读数据时,limit代表buffer中有效数据的长度。
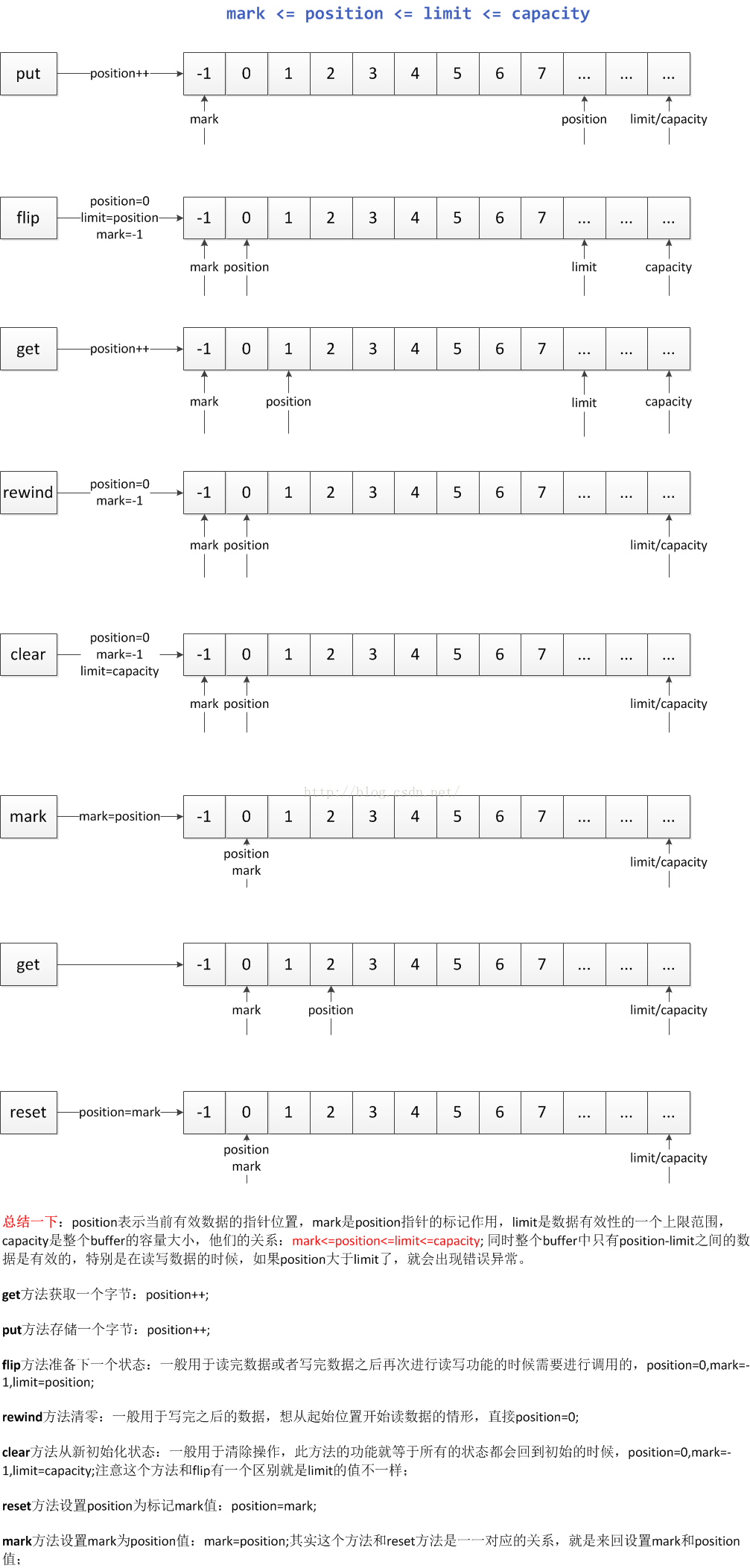
这些属性总是满足以下条件: 0 <= mark <= position <= limit <= capacity
ByteBuffer的常规方法
ByteBuffer allocate(int capacity) //创建一个指定capacity的ByteBuffer。
ByteBuffer allocateDirect(int capacity) //创建一个direct的ByteBuffer,这样的ByteBuffer在参与IO操作时性能会更好
ByteBuffer wrap(byte [] array)
ByteBuffer wrap(byte [] array, int offset, int length) //把一个byte数组或byte数组的一部分包装成ByteBuffer。
//get put方法不多说
byte get(int index)
ByteBuffer put(byte b)
int getInt() //从ByteBuffer中读出一个int值。
ByteBuffer putInt(int value) // 写入一个int值到ByteBuffer中。
ByteBuffer的特殊方法
Buffer clear() //把position设为0,把limit设为capacity,一般在把数据写入Buffer前调用。
Buffer flip() //把limit设为当前position,把position设为0,一般在从Buffer读出数据前调用。
Buffer rewind() //把position设为0,limit不变,一般在把数据重写入Buffer前调用。和 clear() 类似,只是不改动限制
compact() //将 position 与 limit之间的数据复制到buffer的开始位置,复制后 position = limit -position,limit = capacity, 但如 果position 与limit 之间没有数据的话发,就不会进行复制。
mark() & reset() //通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。
put
写模式下,往buffer里写一个字节,并把postion移动一位。写模式下,一般limit与capacity相等。
flip
写完数据,需要开始读的时候,将postion复位到0,并将limit设为当前postion。
get
从buffer里读一个字节,并把postion移动一位。上限是limit,即写入数据的最后位置。
clear
将position置为0,并不清除buffer内容。
mark & reset
mark相关的方法主要是mark()(标记)和reset()(回到标记).
/**
* 1.txt => VipSoftAAA
*
* @throws Exception
*/
@Test
public void readFile() throws Exception {
FileChannel channel = FileChannel.open(Paths.get("D:\\temp\\1.txt"), StandardOpenOption.READ);
ByteBuffer buf = ByteBuffer.allocate(7);
while (channel.read(buf) != -1) {
buf.flip();
String ss = new String(buf.array());
System.out.println(ss); // 这种方式的读取,不会产生 position 的变化 int idx = 0;
while (buf.hasRemaining()) {
/**
* get() 后 position 会往后+1
* 如果执行完成后,没有 clear(),则新的文件内容不会被读出来。因为 position 已经到了 capacity 值了,没地方放新内容了
*/
System.out.print((char) buf.get());
if (idx == 2) {
/**
* 将 position 与 limit之间的数据复制到buffer的开始位置
* 复制后,position = (pos <= lim ? lim - pos : 0) 接着往后读
* 所以第二次取出AAA时,重置后,position =0 ,这时候会就把buf里面的数据重新再打印一遍变成 AAAAAAtoft
*/
buf.compact(); String compactStr = new String(buf.array());
System.out.println("\r\nCompact => " + compactStr); // compact后一次性读出来看变化,发现Soft被复制到了前面
}
idx++;
}
//第二次读出4个字节,但输出还是AAASoft,说明 clear 只是把 position 设为0, 并没有清除数据
buf.clear();
System.out.println();
}
channel.close();
System.out.println();
}
//输出结果:
//VipSoft //buf.array() 一次性打印全部,无偏移
//Vipoft //compact=7-3=4,所以跳过第三位的S,从第4位开始取值
//AAAtoft //一次性打印全部,因为 compact 将后position~limit的数据复制到了开始位置,所以AAA后面多了个 t
//AAAAAAtoft //第二次 pos>lim 所以 pos=0 把第一次的内容又打了一遍

1.分配内存大小为10的缓存区。索引10的空间是我虚设出来,实际不存在,为了能明显表示capacity。IntBuffer的容量为10,所以capacity为10,在这里指向索引为10的空间。Buffer初始化的时候,limit和capacity指向同一索引。position指向0。
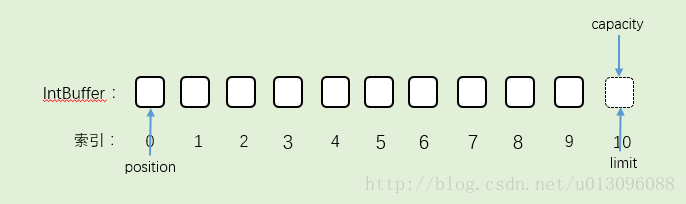
2.往Buffer里加一个数据。position位置移动,capacity不变,limit不变。
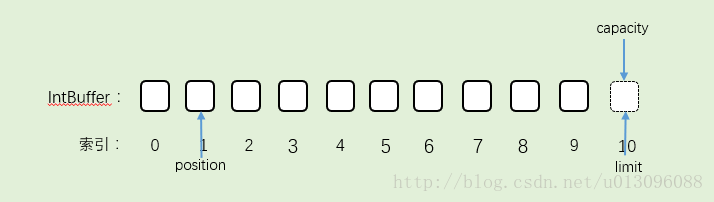
3.Buffer读完之后,往bufer里写了5个数据,position指向索引为5的第6个数据,capacity不变,limit不变。
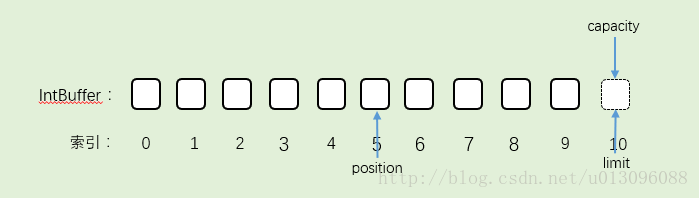
4.执行flip()。这时候对照着,之前flip源码去看。把position的值赋给limit,所以limit=5,然后position=0。capacity不变。结果就是:
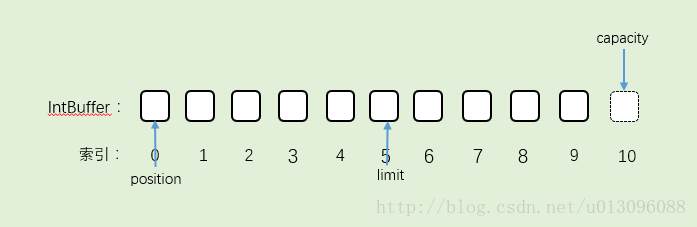
5.Buffer开始往外写数据。每写一个,position就下移一个位置,一直移到limit的位置,结束。
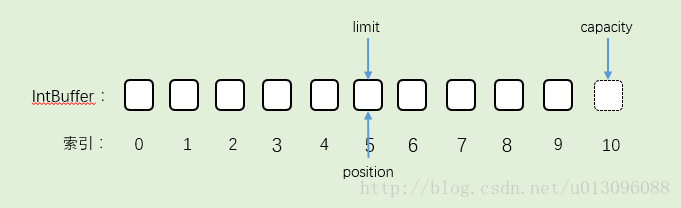
上图的顺序就是代码中的IntBuffer从初始化,到读数据,再写数据三个状态下,capacity,position,limit三个属性的变化和关系。
大家可以发现:
1. 0 <= position <= limit <= capacity
2. capacity始终不变
@Test
public void nioTest() {
// 分配内存大小为10的缓存区
IntBuffer buffer = IntBuffer.allocate(10);
System.out.println("capacity:" + buffer.capacity());
for (int i = 0; i < 5; ++i) {
System.out.println("put data position:" + buffer.position());
buffer.put(i+1);
}
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>>>>> position:" + buffer.position());
System.out.println(">>>>>>>> limit:" + buffer.limit());
System.out.println(">>>>>>>> capacity:" + buffer.capacity());
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>> flip() 使缓冲区为一系列新的通道写入或相对获取 操作做好准备<<<<<");
buffer.flip();
System.out.println("after flip limit:" + buffer.limit());
System.out.println("enter while loop");
while (buffer.hasRemaining()) {
System.out.println(">>>>>>>> position:" + buffer.position());
System.out.println(">>>>>>>> limit:" + buffer.limit());
System.out.println(">>>>>>>> capacity:" + buffer.capacity());
System.out.println(">>>>>>>> 元素:" + buffer.get());
}
System.out.println(">>>>> rewind() 将位置 position = 0 也就是相当于选取当前缓冲区总的全部有效数据 和clear()类似,只是不改动限制 <<<<<");
buffer.rewind();
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>>>>> position:" + buffer.position());
System.out.println(">>>>>>>> limit:" + buffer.limit());
System.out.println(">>>>>>>> capacity:" + buffer.capacity());
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>> clear() 用来初始化缓存空间,例如读取文件时将文件内容置入缓存时要先执行此方法 <<<<<");
buffer.clear();
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>>>>> position:" + buffer.position());
System.out.println(">>>>>>>> limit:" + buffer.limit());
System.out.println(">>>>>>>> capacity:" + buffer.capacity());
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
}
ByteBuffer 字节缓冲区的更多相关文章
- Java基础知识强化之IO流笔记28:BufferedOutputStream / BufferedInputStream(字节缓冲区流) 之BufferedOutputStream写出数据
1. BufferedOutputStream / BufferedInputStream(字节缓冲区流)的概述 通过定义数组的方式确实比以前一次读取一个字节的方式快很多,所以,看来有一个缓冲区还是非 ...
- 【转】Socket接收字节缓冲区
原创本拉灯 2014年04月16日 10:06:55 标签: socket / 数据包 4448 我们接收Socket字节流数据一般都会定义一个数据包协议( 协议号,长度,内容),由于Socket接收 ...
- Java中的字节流,字符流,字节缓冲区,字符缓冲区复制文件
一:创建方式 1.建立输入(读)对象,并绑定数据源 2.建立输出(写)对象,并绑定目的地 3.将读到的内容遍历出来,然后在通过字符或者字节写入 4.资源访问过后关闭,先创建的后关闭,后创建的先关闭 ...
- Java基础-虚拟内存之映射字节缓冲区(MappedByteBuffer)
Java基础-虚拟内存之映射字节缓冲区(MappedByteBuffer) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.映射字节缓冲区 1>.什么是虚拟内存 答:虚拟内 ...
- Java SocketChannel 读取ByteBuffer字节的处理模型
在JAVA中的流分为字节流或字符流,一般来说采用字符流处理起来更加方便.字节流处理起来相对麻烦,SocketChannel中将数据读取到ByteBuffer中,如何取出完整的一行数据(使用CRLF分隔 ...
- 牛客网Java刷题知识点之字节缓冲区练习之从A处复制文本文件到B处(BufferedReader、BufferedWriter)、复制文本文件的原理图解
不多说,直接上干货! CopyTextByBufTest.java package zhouls.bigdata.DataFeatureSelection.test; import java.io.B ...
- NIO之缓冲区
NIO引入了三个概念: Buffer 缓冲区 Channel 通道 selector 选择器 1.java.io优化建议 操作系统与Java基于流的I/O模型有些不匹配.操作系统要移动的是大块数据(缓 ...
- NIO基础学习——缓冲区
NIO是对I/O处理的进一步抽象,包含了I/O的基础概念.我是基于网上博友的博客和Ron Hitchens写的<JAVA NIO>来学习的. NIO的三大核心内容:缓冲区,通道,选择器. ...
- Java NIO之套接字通道
1.简介 前面一篇文章讲了文件通道,本文继续来说说另一种类型的通道 -- 套接字通道.在展开说明之前,咱们先来聊聊套接字的由来.套接字即 socket,最早由伯克利大学的研究人员开发,所以经常被称为B ...
- java网络编程学习之NIO模型
网上对NIO的解释有很多,但自己一直没有理解,根据自己的理解画出下面这个图,有什么不对的地方,欢迎留言指出. 理解是,客户端先与通过通道Channel与连接(注册到服务器端),然后再传送数据,服务器端 ...
随机推荐
- 【Vue3响应式原理#02】Proxy and Reflect
专栏分享:vue2源码专栏,vue3源码专栏,vue router源码专栏,玩具项目专栏,硬核推荐 欢迎各位ITer关注点赞收藏 背景 以下是柏成根据Vue3官方课程整理的响应式书面文档 - 第二节, ...
- 你还在为SFTP连接超时而困惑么?
1. 前言 在最近的项目联调过程中,发现在连接上游侧SFTP时总是需要等待大约10s+的时间才会出现密码输入界面,这种长时间的等待直接导致的调用文件接口时连接sftp超时问题.于是决定自己针对该问题进 ...
- Codeforces Round #698 (Div. 2) A~C题解
写在前边 链接:Codeforces Round #698 (Div. 2) 又是自闭的一场比赛,\(C\)题补了一天终于明白了一些,真的好自闭好自闭. 今晚还有一场,加油喽. A. Nezzar a ...
- 微信小程序敏感内容检测
获取access_token access_token是公众号的全局唯一接口调用凭据,公众号调用各接口时都需使用access_token.开发者需要进行妥善保存.access_token的存储至少要保 ...
- Jayway JsonPath-提取JSON文档内容的Java DSL
介绍 JsonPath是一种能够提取部分JSON文档属性.对象.数组的语法,支持条件过滤.数学运算.字符串处理等功能.JsonPath与JSON文档就像 XPath 表达式与 XML 文档结合使用一样 ...
- .net下优秀的MQTT框架MQTTnet使用方法,物联网通讯必备
MQTTnet 是一个高性能的MQTT类库,支持.NET Core和.NET Framework. MQTTnet 原理: MQTTnet 是一个用于.NET的高性能MQTT类库,实现了MQTT协议的 ...
- 【已解决】nrm -g安装成功后不是全局应用(command not found: nrm)
本机情况: 服务器系统:CentOS 8.1 nodejs版本:20 问题描述: 在命令行执行命令,npm install -g nrm,全局安装nrm. 安装之后,执行nrm ls 报command ...
- 终结篇:==和equals有什么区别?
== 和 equals 有什么区别?这个问题本身不难,但是被问到的频率很高,且大部分人的回答都不够全面,让人听了有种"恨铁不成钢"的感觉,所以今天咱们就来好好聊聊这个问题. 1.典 ...
- 云端开炉,线上训练,Bert-vits2-v2.2云端线上训练和推理实践(基于GoogleColab)
假如我们一定要说深度学习入门会有一定的门槛,那么设备成本是一个无法避开的话题.深度学习模型通常需要大量的计算资源来进行训练和推理.较大规模的深度学习模型和复杂的数据集需要更高的计算能力才能进行有效的训 ...
- 什么是革命性技术eBPF?为什么可观测性领域都得用它
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 如果有一种技术可以监控和采集任何应用信息,支持任何语言,并且应用完全无感知,零侵入,想想是不是很激动,那么这个技术是什么呢 ...