一种轻量分表方案-MyBatis拦截器分表实践
背景
部门内有一些亿级别核心业务表增速非常快,增量日均100W,但线上业务只依赖近一周的数据。随着数据量的迅速增长,慢SQL频发,数据库性能下降,系统稳定性受到严重影响。本篇文章,将分享如何使用MyBatis拦截器低成本的提升数据库稳定性。
业界常见方案
针对冷数据多的大表,常用的策略有以2种:
1. 删除/归档旧数据。
2. 分表。
归档/删除旧数据
定期将冷数据移动到归档表或者冷存储中,或定期对表进行删除,以减少表的大小。此策略逻辑简单,只需要编写一个JOB定期执行SQL删除数据。我们开始也是用这种方案,但此方案也有一些副作用:
综上,此方案有一定风险,为了规避这种风险,我们决定采用另一种方案:分表。
分表
我们决定按日期对表进行横向拆分,实现让系统每周生成一张周期表,表内只存近一周的数据,规避单表过大带来的风险。
分表方案选型
经调研,考虑2种分表方案:Sharding-JDBC、利用Mybatis自带的拦截器特性。
经过对比后,决定采用Mybatis拦截器来实现分表,原因如下:
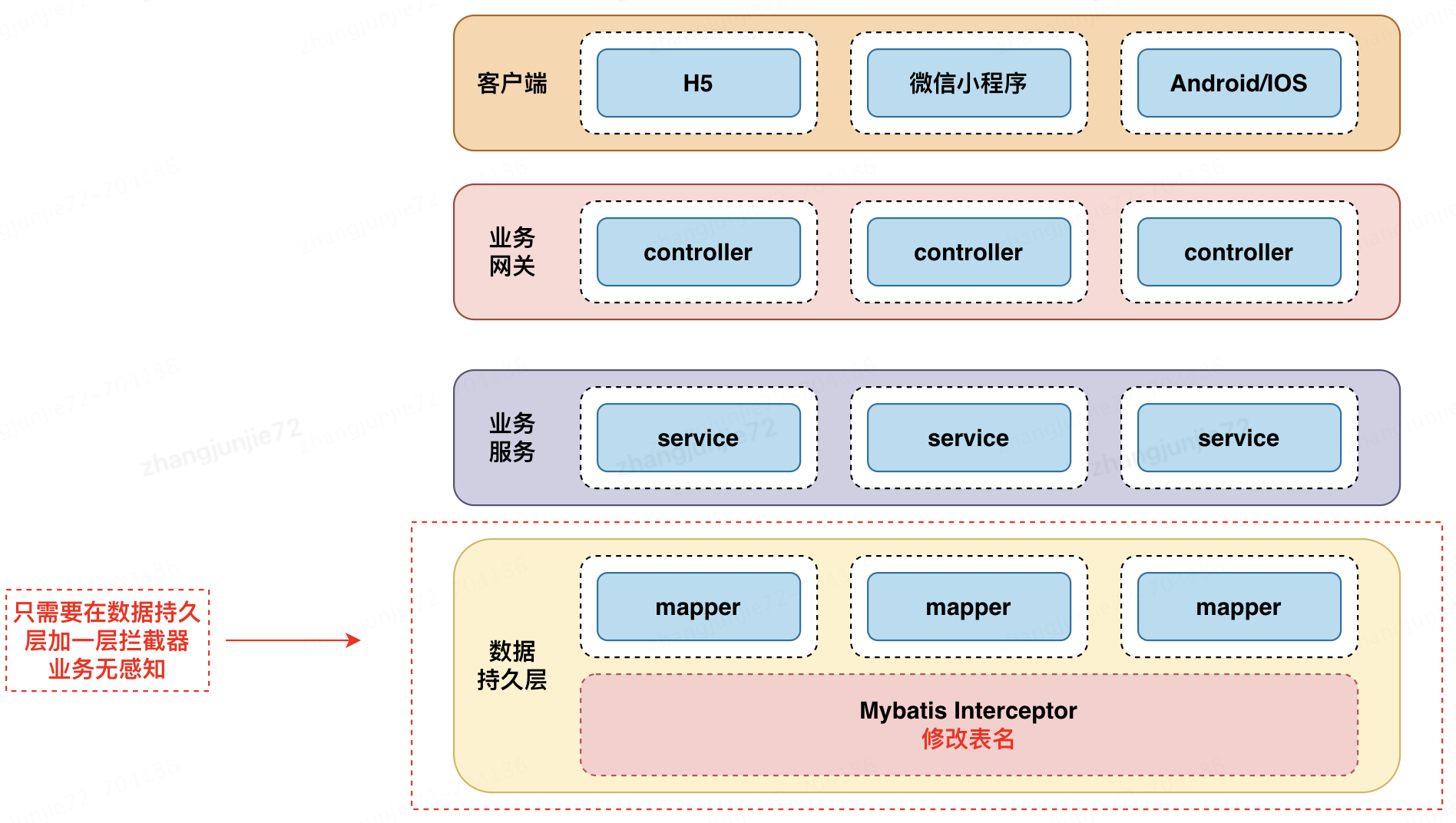
分表具体实现代码
分表配置对象
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ShardingProperty {
// 分表周期天数,配置7,就是一周一分
private Integer days;
// 分表开始日期,需要用这个日期计算周期表名
private Date beginDate;
// 需要分表的表名
private String tableName;
}
分表配置类
import java.util.concurrent.ConcurrentHashMap;
public class ShardingPropertyConfig {
public static final ConcurrentHashMap<String, ShardingProperty> SHARDING_TABLE ();
static {
ShardingProperty orderInfoShardingConfig = new ShardingProperty(15, DateUtils.string2Date("20231117"), "order_info");
ShardingProperty userInfoShardingConfig = new ShardingProperty(7, DateUtils.string2Date("20231117"), "user_info");
SHARDING_TABLE.put(orderInfoShardingConfig.getTableName(), orderInfoShardingConfig);
SHARDING_TABLE.put(userInfoShardingConfig.getTableName(), userInfoShardingConfig);
}
}
拦截器
import lombok.extern.slf4j.Slf4j;
import o2o.aspect.platform.function.template.service.TemplateMatchService;
import org.apache.commons.lang3.StringUtils;
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.reflection.DefaultReflectorFactory;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.ReflectorFactory;
import org.apache.ibatis.reflection.factory.DefaultObjectFactory;
import org.apache.ibatis.reflection.factory.ObjectFactory;
import org.apache.ibatis.reflection.wrapper.DefaultObjectWrapperFactory;
import org.apache.ibatis.reflection.wrapper.ObjectWrapperFactory;
import org.springframework.stereotype.Component;
import java.sql.Connection;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Date;
import java.util.Properties;
@Slf4j
@Component
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})
public class ShardingTableInterceptor implements Interceptor {
private static final ObjectFactory DEFAULT_OBJECT_FACTORY = new DefaultObjectFactory();
private static final ObjectWrapperFactory DEFAULT_OBJECT_WRAPPER_FACTORY = new DefaultObjectWrapperFactory();
private static final ReflectorFactory DEFAULT_REFLECTOR_FACTORY = new DefaultReflectorFactory();
private static final String MAPPED_STATEMENT = "delegate.mappedStatement";
private static final String BOUND_SQL = "delegate.boundSql";
private static final String ORIGIN_BOUND_SQL = "delegate.boundSql.sql";
private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyyMMdd");
private static final String SHARDING_MAPPER = "com.jd.o2o.inviter.promote.mapper.ShardingMapper";
private ConfigUtils configUtils = SpringContextHolder.getBean(ConfigUtils.class);
@Override
public Object intercept(Invocation invocation) throws Throwable {
boolean shardingSwitch = configUtils.getBool("sharding_switch", false);
// 没开启分表 直接返回老数据
if (!shardingSwitch) {
return invocation.proceed();
}
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaStatementHandler = MetaObject.forObject(statementHandler, DEFAULT_OBJECT_FACTORY, DEFAULT_OBJECT_WRAPPER_FACTORY, DEFAULT_REFLECTOR_FACTORY);
MappedStatement mappedStatement = (MappedStatement) metaStatementHandler.getValue(MAPPED_STATEMENT);
BoundSql boundSql = (BoundSql) metaStatementHandler.getValue(BOUND_SQL);
String originSql = (String) metaStatementHandler.getValue(ORIGIN_BOUND_SQL);
if (StringUtils.isBlank(originSql)) {
return invocation.proceed();
}
// 获取表名
String tableName = TemplateMatchService.matchTableName(boundSql.getSql().trim());
ShardingProperty shardingProperty = ShardingPropertyConfig.SHARDING_TABLE.get(tableName);
if (shardingProperty == null) {
return invocation.proceed();
}
// 新表
String shardingTable = getCurrentShardingTable(shardingProperty, new Date());
String rebuildSql = boundSql.getSql().replace(shardingProperty.getTableName(), shardingTable);
metaStatementHandler.setValue(ORIGIN_BOUND_SQL, rebuildSql);
if (log.isDebugEnabled()) {
log.info("rebuildSQL -> {}", rebuildSql);
}
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
if (target instanceof StatementHandler) {
return Plugin.wrap(target, this);
}
return target;
}
@Override
public void setProperties(Properties properties) {}
public static String getCurrentShardingTable(ShardingProperty shardingProperty, Date createTime) {
String tableName = shardingProperty.getTableName();
Integer days = shardingProperty.getDays();
Date beginDate = shardingProperty.getBeginDate();
Date date;
if (createTime == null) {
date = new Date();
} else {
date = createTime;
}
if (date.before(beginDate)) {
return null;
}
LocalDateTime targetDate = SimpleDateFormatUtils.convertDateToLocalDateTime(date);
LocalDateTime startDate = SimpleDateFormatUtils.convertDateToLocalDateTime(beginDate);
LocalDateTime intervalStartDate = DateIntervalChecker.getIntervalStartDate(targetDate, startDate, days);
LocalDateTime intervalEndDate = intervalStartDate.plusDays(days - 1);
return tableName + "_" + intervalStartDate.format(FORMATTER) + "_" + intervalEndDate.format(FORMATTER);
}
}
临界点数据不连续问题
分表方案有1个难点需要解决:周期临界点数据不连续。举例:假设要对operate_log(操作日志表)大表进行横向分表,每周一张表,分表明细可看下面表格。
| 第一周(operate_log_20240107_20240108) | 第二周(operate_log_20240108_20240114) | 第三周(operate_log_20240115_20240121) |
| 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 | 1月15号 ~ 1月21号的数据 |
1月8号就是分表临界点,8号需要切换到第二周的表,但8号0点刚切换的时候,表内没有任何数据,这时如果业务需要查近一周的操作日志是查不到的,这样就会引发线上问题。
我决定采用数据冗余的方式来解决这个痛点。每个周期表都冗余一份上个周期的数据,用双倍数据量实现数据滑动的效果,效果见下面表格。
| 第一周(operate_log_20240107_20240108) | 第二周(operate_log_20240108_20240114) | 第三周(operate_log_20240115_20240121) |
| 12月25号 ~ 12月31号的数据 | 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 |
| 1月1号 ~ 1月7号的数据 | 1月8号 ~ 1月14号的数据 | 1月15号 ~ 1月21号的数据 |
注:表格内第一行数据就是冗余的上个周期表的数据。
思路有了,接下来就要考虑怎么实现双写(数据冗余到下个周期表),有2种方案:
方案对比后,选择了对业务性能损耗小的方案二。
监听binlog并双写流程图
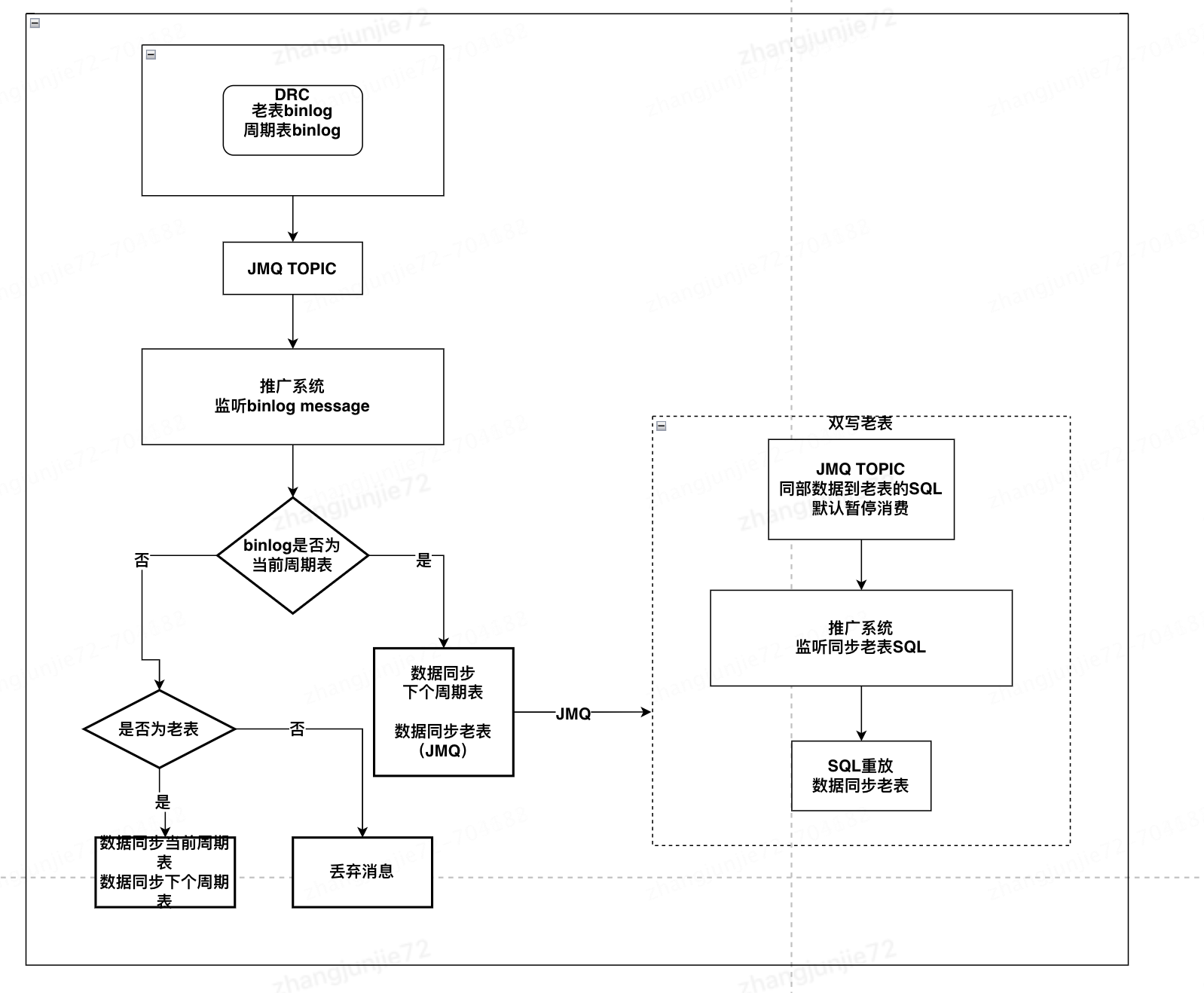
监听binlog数据双写注意点
监听binlog数据双写代码
注:下面代码不能直接用,只提供基本思路
/**
* 监听binlog ,分表双写,解决数据临界问题
*/
@Slf4j
@Component
public class BinLogConsumer implements MessageListener {
private MessageDeserialize deserialize = new JMQMessageDeserialize();
private static final String TABLE_PLACEHOLDER = "%TABLE%";
@Value("${mq.doubleWriteTopic.topic}")
private String doubleWriteTopic;
@Autowired
private JmqProducerService jmqProducerService;
@Override
public void onMessage(List<Message> messages) throws Exception {
if (messages == null || messages.isEmpty()) {
return;
}
List<EntryMessage> entryMessages = deserialize.deserialize(messages);
for (EntryMessage entryMessage : entryMessages) {
try {
syncData(entryMessage);
} catch (Exception e) {
log.error("sharding sync data error", e);
throw e;
}
}
}
private void syncData(EntryMessage entryMessage) throws JMQException {
// 根据binlog内的表名,获取需要同步的表
// 3种情况:
// 1、老表:需要同步当前周期表,和下个周期表。
// 2、当前周期表:需要同步下个周期表,和老表。
// 3、下个周期表:不需要同步。
List<String> syncTables = getSyncTables(entryMessage.tableName, entryMessage.createTime);
if (CollectionUtils.isEmpty(syncTables)) {
log.info("table {} is not need sync", tableName);
return;
}
if (entryMessage.getHeader().getEventType() == WaveEntry.EventType.INSERT) {
String insertTableSqlTemplate = parseSqlForInsert(rowData);
for (String syncTable : syncTables) {
String insertSql = insertTableSqlTemplate.replaceAll(TABLE_PLACEHOLDER, syncTable);
// 双写老表发Q,为了避免出现同步死循环问题
if (ShardingPropertyConfig.SHARDING_TABLE.containsKey(syncTable)) {
Long primaryKey = getPrimaryKey(rowData.getAfterColumnsList());
sendDoubleWriteMsg(insertSql, primaryKey);
continue;
}
mysqlConnection.executeSql(insertSql);
}
continue;
}
}
数据对比
为了保证新表和老表数据一致,需要编写对比程序,在上线前进行数据对比,保证binlog同步无问题。
具体实现代码不做展示,思路:新表查询一定量级数据,老表查询相同量级数据,都转换成JSON,equals对比。
作者:京东零售 张均杰
来源:京东云开发者社区 转载请注明来源
一种轻量分表方案-MyBatis拦截器分表实践的更多相关文章
- 基于mybatis拦截器分表实现
1.拦截器简介 MyBatis提供了一种插件(plugin)的功能,但其实这是拦截器功能.基于这个拦截器我们可以选择在这些被拦截的方法执行前后加上某些逻辑或者在执行这些被拦截的方法时执行自己的逻辑. ...
- 玩转SpringBoot之整合Mybatis拦截器对数据库水平分表
利用Mybatis拦截器对数据库水平分表 需求描述 当数据量比较多时,放在一个表中的时候会影响查询效率:或者数据的时效性只是当月有效的时候:这时我们就会涉及到数据库的分表操作了.当然,你也可以使用比较 ...
- PintJS – 轻量,并发的 GruntJS 运行器
PintJS 是一个小型.异步的 GruntJS 运行器,试图解决大规模构建流程中的一些问题. 典型的Gruntfile 会包括 jsHint,jasmine,LESS,handlebars, ugl ...
- Mybatis拦截器介绍
拦截器的一个作用就是我们可以拦截某些方法的调用,我们可以选择在这些被拦截的方法执行前后加上某些逻辑,也可以在执行这些被拦截的方法时执行自己的逻辑而不再执行被拦截的方法.Mybatis拦截器设计的一个初 ...
- Mybatis拦截器介绍及分页插件
1.1 目录 1.1 目录 1.2 前言 1.3 Interceptor接口 1.4 注册拦截器 1.5 Mybatis可拦截的方法 1.6 利用拦截器进行分页 1.2 前言 拦截器的一 ...
- Mybatis拦截器执行过程解析
上一篇文章 Mybatis拦截器之数据加密解密 介绍了 Mybatis 拦截器的简单使用,这篇文章将透彻的分析 Mybatis 是怎样发现拦截器以及调用拦截器的 intercept 方法的 小伙伴先按 ...
- "犯罪心理"解读Mybatis拦截器
原文链接:"犯罪心理"解读Mybatis拦截器 Mybatis拦截器执行过程解析 文章写过之后,我觉得 "Mybatis 拦截器案件"背后一定还隐藏着某种设计动 ...
- 关于mybatis拦截器,对结果集进行拦截
因业务需要,需将结果集序列化为json返回,于是,网上找了好久资料,都是关于拦截参数的处理,拦截Sql语法构建的处理,就是很少关于对拦截结果集的处理,于是自己简单的写了一个对结果集的处理, 记录下. ...
- 详解Mybatis拦截器(从使用到源码)
详解Mybatis拦截器(从使用到源码) MyBatis提供了一种插件(plugin)的功能,虽然叫做插件,但其实这是拦截器功能. 本文从配置到源码进行分析. 一.拦截器介绍 MyBatis 允许你在 ...
- Mybatis拦截器,修改Date类型数据。设置毫秒为0
1:背景 Mysql自动将datetime类型的毫秒数四舍五入,比如代码中传入的Date类型的数据值为 2021.03.31 23:59:59.700 到数据库 2021.04.01 0 ...
随机推荐
- web自动化测试(1):再谈UI发展史与UI、功能自动化测试
前言(废话) 行文前,安利下文章:<图形界面操作系统发展史--计算机界面发展历史回顾>.<再谈MV*(MVVM MVP MVC)模式的设计原理-封装与解耦> 1973年4月,X ...
- centos8 测地卸载php5.6 与卸载php7
centos8 yum php 默认安装 php7.1.2 我想卸载php7 ,安装php5.6 yum remove php 无法彻底卸载干净.必须强制删除,使用下面命令查看全部php软件包 rpm ...
- Flutter App混淆加固、保护与优化原理
引言 在移动应用程序开发中,保护应用程序的代码和数据安全至关重要.本文将探讨如何对Flutter应用程序进行混淆.优化和保护,以提高应用程序的安全性和隐私. 一.混淆原理 混淆是一种代码保护技术, ...
- 总结MySQL 的一些知识点:MySQL 连接的使用
MySQL 连接的使用 在前几章节中,我们已经学会了如何在一张表中读取数据,这是相对简单的,但是在真正的应用中经常需要从多个数据表中读取数据. 本章节我们将向大家介绍如何使用 MySQL 的 JOIN ...
- 实用指南:手把手搭建坚若磐石的DevSecOps框架
长期以来,安全问题一直被当作软件开发流程中的最后一步.开发者贡献可以实现软件特性的代码,但只在开发生命周期的测试和部署阶段考虑安全问题.随着盗版.恶意软件及网络犯罪事件飙升,开发流程需要做出改变. 开 ...
- 【django-vue】课程表数据录入 课程分类接口 所有课程接口 课程详情接口 所有章节接口 课程列表前端 课程详情前端
目录 上节回顾 APSchudler 双写一致性 今日内容 1 课程表数据录入 2 课程分类接口 2.1 路由 2.2 序列化类 2.3 视图类 3 所有课程接口(过滤,排序) 3.1 表模型 3.2 ...
- vivo 互联网业务就近路由技术实战
一.问题背景 在vivo互联网业务高速发展的同时,支撑的服务实例规模也越来越大,然而单个机房能承载的机器容量是有限的,于是同城多机房甚至多地域部署就成为了业务在实际部署过程中不得不面临的场景. 一般情 ...
- P4913【橙】
蕾姆了,上一道题做的好烦,结果直接把上一题的代码稍微改改就直接五分钟做出了另一道题,就是这道橙题.虽然只是一道橙题,但上一题代码得以复用显得自己没浪费那么多时间,显得自己还是有不少收获的.心里平摊多了 ...
- 扒一扒ProcessOn 新功能——一键编号、图形组合、左侧导航、画布水印、表格组件
思维导图.一键编号 思维导图新增 多种全新主题风格,让您的创作赏心悦目 思维导图新增 一键编号 功能 流程图.图形组合 自定义组合图形功能:新增流程图 我的图形 功能,用户可以设置或者上传自己的图形 ...
- poj 3268 最短路
***题意:在x这个点有个聚会,其他的点要到x这个点,然后再会自己原始的点,求一来一回最大的那个距离 做法:两边dijstra算法,因为是单向图,要注意更新顺序*** #include<iost ...