前沿分享|阿里云资深技术专家 魏闯先:AnalyticDB PostgreSQL年度新版本发布
简介: 本篇内容为2021云栖大会-云原生数据仓库AnalyticDB技术与实践峰会分论坛中,阿里云资深技术专家 魏闯先关于“AnalyticDB PostgreSQL年度新版本发布”的分享。

本篇内容将通过三个部分来介绍AnalyticDB PG年度新版本发布。
一、AnalyticDB PG云原生架构
二、云原生架构核心技术剖析
三、演进路标

一、AnalyticDB PG云原生架构
阿里云自研高性能、海量扩展数据仓库服务、兼容部分Oracle/Teradata语法生态,大量应用于阿里巴巴集团内部电商,物流,文娱,广告等业务部门,服务于阿里云的金融、政企、互联网等各行业用户,支持快速构建新一代云化数据仓库服务。

它具有以下四个特点:第一,PB级数据秒级响应。采用向量化计算以及列存储和智能索引,领先传统数据库引擎性能3x倍。新一代SQL优化器,实现复杂分析语句免调优。第二,稳定可靠简化运维。飞天平台基于阿里多年大规模集群系统构筑经验打造,智能硬件管理,故障监控诊断自恢复,支持MPP数据库实现复杂集群系统高可靠,自运维。第三,高SQL兼容性。支持SQL 2003,部分兼容0racle语法,支持PL/SQL存储过程, OLAP窗口函数,视图等,具有完备功能和生态,可实现应用快速适配和迁移。第四,数据多模分析。通过PostGIS插件支持地理信息数据分析,内置100+机器学习算法库,实现数据智能探索。支持高维向量检索算法,实现视频/图像检索以图搜图功能。

我们为什么要升级云原生架构?从80年代开始,数据库逐步由单机向云原生架构逐步演进。80年代,数据库采用存储计算耦合的单点数据库服务架构。90年代开始,通过共享存储的能力做到了一份存储多份计算。随着计算节点线性增加,它的存储逐渐成为瓶颈。到2000年以后,随着大数据的发展,数据水平切成多个分片,每一个节点负责一个分片数据的计算和存储。2010年开始,随着云计算的迅速发展,数据库开始向云原生方向演变。

对于数据仓库的业务来说,它天生适合存算分离架构并支持弹性伸缩。第一,数据量本身存在波峰波谷,数据量在某些天出现激增,数仓需要做到快速扩容。第二,实时分析。我们需要数据做到实时反馈,刚刚产生的数据,能够立刻分析。第三,数据仓库既要提供历史数据分析,又要提供实时分析,这就要求数仓必须具有好的资源隔离能力。第四,现在的部门数据越来越复杂,跨部门之间需要数据共享。我们的数据仓库需要做到一份存储,多部门共享,减少部门之间数据扭转带来的业务复杂。

二、云原生架构核心技术剖析
我们的当前ADB是两层结构,上层是master节点,底层的是计算节点,通过云盘的弹性能力去解决存储弹性的问题。这种架构的主要痛点问题是,计算节点有状态,一旦有状态,在扩容等过程中,就会面临着数据搬迁慢的问题,所以我们在新的云原生架构把计算节点从有状态变成无状态或者弱状态。状态包括真实数据和元数据两个层面,真实数据放在共享存储中,元数据放在分布式KV中,存储和计算完全解耦,做到无状态,这样就可以快速地实现秒级的弹性能力。在开发测试过程中,发现了很多性能问题。第一个问题是,原来的云盘或者是本地盘换成了共享存储后,共享存储响应性能比本地盘差一个数量级或两个数量级,我们采用分布式的多层缓存来解决共享存储的性能问题。第二个,共享存储具有非常好的吞吐能力,但需要存储引擎适应这个特性,因此我们设计了行列缓存的架构,并做了大量的面向高吞吐的性能优化。

对普通客户来说,最重要的事情就是做到成本的降低。由于采用的共享存储的价格比原先使用本地盘或云盘的成本有一个数量级的下降,所以整个原生版本在成本上会有个大幅下降。

云原生架构有四个特色:第一个特色是弹性,可以实现计算和存储独立的伸缩。第二个是实时,保留实时能力,支持高并发的实时写入。第三个是高吞吐,具有好的多维分析性能,并可线性扩展。第四个是数据共享,可以实现数据跨实例的实时共享。

首先我们介绍一下扩容的过程。假设开始只有两个计算节点,数据有八个分片。扩容前,每个计算节点负责四个分片数据,映射关系保存在元数据库中,所有的数据都放在共享存储上面。扩容过程就是将映射关系从原来的一个节点对四个分片改成一个节点对两个分片,扩容过程无需数据迁移,只需要修改元数据,整个过程可以做到秒级弹性。

高吞吐实时写入是实时数仓的一个重要特性。主要通过以下三种方式:一、Batch和并行化提高吞吐。二、本地行存表实现事务ACID。三、分布式缓存加速。

另一个重要技术点是离在线一体行列混存。我们设计一个面向吞吐的行列混存的存储引擎,充分发挥共享存储高吞吐的特色。行列混存利用数据的有序性,支持计算下推,得到了10倍以上的性能提升。同时针对多维分析任意列查询的场景,设计了多维排序功能,可以保证多个维度的任意查询都能达到毫秒级的响应。
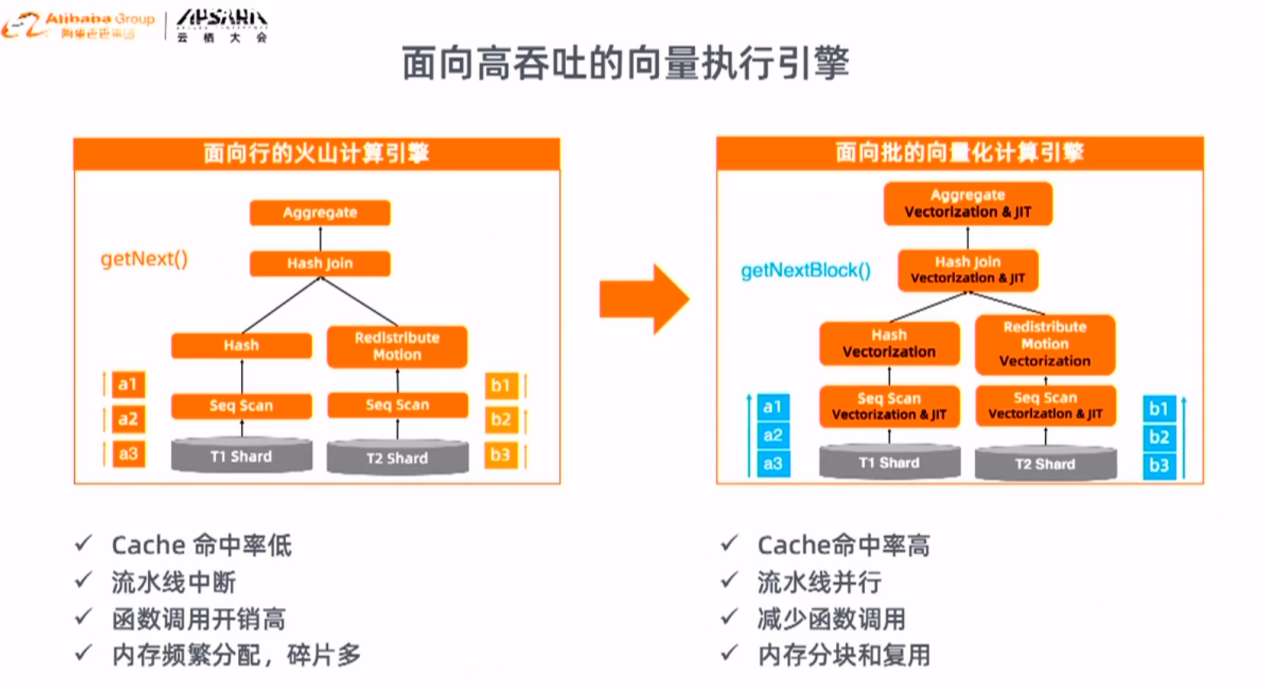
ADBPG原先采用火山计算模型,在云原生版本中将火山模型升级为向量化模型。向量化引擎的本质是将原来的一条条计算,改成批计算,每批数据采用列式向量化计算。相对于火山模型,向量化引擎具有CPU Cache命中率高、流水线并行、低函数调用开销、减少内存碎片等优势。测试结果显示,向量化计算引擎相对原来的火山模型有三倍以上的性能提升。

计算存储分离架构的第一个演进特性是数据共享。元数据可分成系统表和可见性表,存储在KV系统中。被共享的实例将元数据同步到KV系统中,共享实例实时查KV系统,拿到最新表的元数据和可见性信息,再根据元数据访问共享存储中的数据,从而实现数据的实时共享。

下一个演进特性是细粒度弹性。通过前面介绍的计算存储分离架构,已经实现了计算节点的无状态化。下一步的工作就是把节点再细拆为存储服务化节点和计算节点。存储服务化节点主要负责数据实时写入和缓存,计算节点实现完全无状态,从而实现极致弹性能力。

三、演进路标
未来一年的演进路径。10月份云原生架构升级,支持极速扩缩容。12月份,上线跨实例数据共享功能,并支持分时弹性功能。明年6月份,上线存储服务化和计算无状态。22年10月份,支持算子级弹性和自动挂起/启动功能。
原文链接
本文为阿里云原创内容,未经允许不得转载。
前沿分享|阿里云资深技术专家 魏闯先:AnalyticDB PostgreSQL年度新版本发布的更多相关文章
- 阿里云资深技术专家黄省江:让天下没有难做的SaaS
导语:本文中,阿里云资深技术专家黄省江(花名禅笑)将聚焦“SaaS加速器——让天下没有难做的SaaS”,对伙伴来说,SaaS加速器帮助他们做好SaaS,卖好SaaS:对企业来说,SaaS加速器帮助他们 ...
- 专访阿里云资深技术专家黄省江:中国SaaS公司的成功之路
笔者采访中国SaaS厂商10多年,深感面对获客成本巨大.产品技术与功能成熟度不足.项目经营模式难以大规模复制.客户观念有待转变等诸多挑战,很多中国SaaS公司的经营状况都不容乐观. 7月26日,阿里云 ...
- 洞见数据库前沿 集结阿里云数据库最强阵容 DTCC 2019 八大亮点抢先看
摘要: 作为DTCC的老朋友和全球领先的云计算厂商,阿里云数据库团队受邀参加本次技术盛会,不仅将派出重量级嘉宾阵容,还会为广大数据库业内人士和行业用户奉上8场精彩议题.下面小编就为大家提前梳理了8大亮 ...
- 阿里云资深DBA专家罗龙九:云数据库十大经典案例分析【转载】
阿里云资深DBA专家罗龙九:云数据库十大经典案例分析 2016-07-21 06:33 本文已获阿里云授权发布,转载具体要求见文末 摘要:本文根据阿里云资深DBA专家罗龙九在首届阿里巴巴在线峰会的&l ...
- 分享阿里云推荐码 IC1L2A,购买服务器可以直接打9折,另附阿里云服务器部署ASP.NET MVC5关键教程
阿里云推荐码为:IC1L2A 阿里云还是不错滴. 以windows server 2008 R2为例,介绍如何从全新的服务器部署MVC5 站点. 新购买的阿里云服务器是没有IIS的,要安装IIS: 控 ...
- 分享阿里云SLB-负载均衡的实现基本原理架构
负载均衡技术原理浅析 https://help.aliyun.com/knowledge_detail/39444.html?spm=5176.7839438.2.6.XBbX5l 阿里定制版的LVC ...
- 云栖神侠传—阿里云数据库专家德歌告诉你PostgreSQL的那些事
什么是云栖神侠传: 云栖社区(http://yq.aliyun.com/?utm_source=yqdg),是阿里云面向开发者群体的开放型社区.在云栖社区中,活跃着许多阿里技术大牛,他们在自己的技术领 ...
- 干货来了!2019阿里云合作伙伴峰会SaaS加速器专场回顾合集:嘉宾分享、深度解读
2019年7月26日,在上海举办的阿里云合作伙伴峰会上,阿里云正式发布SaaS生态战略,计划用阿里云的品牌.渠道.资本.方法论.技术加持伙伴,成就亿级营收独角兽. 该生态战略计划招募10家一级SaaS ...
- 阿里云在云栖大会发布SaaS加速器3.0版最新成果,让天下没有难做的SaaS
2019年杭州·云栖大会顺利落幕,超过6万人次观展,200余位顶尖科学家分享了前沿技术.作为“阿里云不做SaaS”,坚持“被集成”战略的落地体现,阿里云SaaS加速器在云栖大会现场发布了SaaS加速器 ...
- 共享商业&技术红利,阿里云SaaS加速器让天下没有难做的SaaS
9月26日,阿里云在2019杭州云栖大会上发布了SaaS加速器3.0版“一云多端”多个应用平台,展示了阿里云给伙伴带来的多种商业和技术红利.阿里云SaaS加速器将帮助伙伴做好SaaS,卖好SaaS:帮 ...
随机推荐
- Ubuntu 16.04 LAMP(PHP7.0) 环境搭建并测试
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- python基础三(数据类型)
一 引子 1 什么是数据? x=10,10是我们要存储的数据 2 为何数据要分不同的类型 数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示 3 数据类型 数字(整形,长整形,浮点型,复数 ...
- AntSK 0.2.3 版本更新:轻松集成 AI 本地离线模型
大家好,今天和大家分享 AntSK 知识库/智能体项目的最新进展. AntSK 是一个基于 .Net 8.Blazor 及 SemanticKernel 开发的 AI 项目,旨在为开发者提供一个强大的 ...
- 无人不识又无人不迷糊的this
本文分享自华为云社区<3月阅读周·你不知道的JavaScript | 无人不识又无人不迷糊的this>,作者: 叶一一. 关于this this关键字是JavaScript中最复杂的机制之 ...
- 【Docker】Dockerfile基础知识,相信你一定有所收获
Dockerfile常用命令 FROM: 继承基础镜像 MAINTAINER:镜像制作作者信息 RUN: 用来执行shell命令 EXPOSE: 暴露端口号 CMD: 启动容器默认执行的命令,会被覆盖 ...
- Linux服务器部署Web版VSCode,在window下使用浏览器在linux环境下编写代码
最近尝试了一下在Linux服务器上部署VSCode,也就是code-server,然后在windows电脑上通过浏览器访问打开在线编辑器编写代码,以下记录一下部署过程. 1.在linux服务器上安装c ...
- KingbaseES 表级设置autovacuum有关参数和触发机制
前言 在表级别设置autovacuum有关参数清理表的死亡元祖可以有效规避autovacuum触发全局默认阈值的高峰.例如,如果想让表的autovacuum任务更频繁,可以在表级设置更小的触发auto ...
- KingbaseES V8R6集群运维案例之---同一主机节点部署多个集群
案例说明: 在同一主机环境,由于生产需要,需要部署两个集群:本案例详细描述了两个集群的部署过程. 注意:同一主机部署多个集群需要先部署securecmdd服务,节点之间通过securecmdd服务通讯 ...
- KingbaseES sys_restore 恢复表时默认不包括表上的索引
前言 最近碰到一个案例,在使用sys_restore恢复指定表时,默认不恢复表上的索引,如果想恢复需要单独指定. 测试过程 [](javascript:void(0) 查看表的有关属性:test=# ...
- debian12安装arch到chroot环境
纯属瞎玩,可能有风险 1.安装工具 sudo apt install pacman-package-manager arch-install-scripts archlinux-keyring 2.创 ...