关于点赞业务对MySQL和Redis和MongoDB的思考
点赞
在我个人理解中,点赞业务比较频繁,很多人业务可能都会有这个,比如:博客,视频,文章,动态,评论等,但是不应该是核心业务,不应该大量地请求MySQL数据库,给数据库造成大量的资源消耗,MySQL的数据库是非常宝贵的.
以某音为例,当我去搜索的时候,全抖音比较高的点赞数目应该是在1200w - 2000w,我们自己的业务肯定答不到这么高的,但是假设有10个100w的点赞的博客,user_id为用户ID,publication_id为博客的id
第一种方式是直接操作数据库.每次有点赞或者取消点赞操作时,就更新MySQL数据库的点赞数.同时,插入或者更新一个user_id和publication_id的数据行,如果点赞操作非常频繁,会对数据库产生很大的压力.如果有大量的点赞记录,会对数据库产生很大的数据量,一篇文章,100w+的点赞的记录,对于MySQL来说,是非常恐怖的.
第二种方式是通过MySQL + Redis的Set来实现,具体代码如下,以下的代码为B站Redis黑马点评项目:
@Override
public Result likeBlog(Long id){
// 1. 获取登录用户
Long userId = UserHolder.getUser().getId(); // 2. 判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); if(BooleanUtil.isFalse(isMember)){
// 3. 如果未点赞,可以点赞
// 3.1 数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update(); // 3.2 保存用户到Redis的set集合
if(isSuccess){
stringRedisTemplate.opsForSet().add(key, userId.toString());
}
} else {
// 4. 如果已点赞,取消点赞
// 4.1 数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update(); // 4.2 把用户从Redis的set集合移除
if(isSuccess){
stringRedisTemplate.opsForSet().remove(key, userId.toString());
}
}
}这样造成的问题是,Redis是内存数据库,点赞信息存储在内存中。当点赞数量非常大时,会占用大量内存。
下面测试一下,一个key为"userId:114514:publication_id:738836",value为100000-1100000的数据
数据量
scard userId:114514:publication_id:738836

判断一个value是否存在这个set中-----(对应的业务为"判断当前登录用户是否已经点赞")
@Test
public void selectBigKey() {
String key = "userId:114514:publication_id:738836";
String value1 = "100000";
String value2 = "5000000";
// 记录开始时间
long startTime = System.nanoTime(); boolean cacheSet1 = RedisUtils.containsInCacheSet(key, value1);
if (cacheSet1) {
System.out.println("代码2:" + "存在这个value");
} else {
System.out.println("代码2:" + "不存在这个value");
}
// 记录结束时间
long endTime = System.nanoTime(); // 计算执行时间(以毫秒为单位)
long executionTime = (endTime - startTime) / 1_000_000; // 将纳秒转换为毫秒 System.out.println("代码执行时间1: " + executionTime + " 毫秒"); // 记录开始时间
long startTime2 = System.nanoTime(); boolean cacheSet2 = RedisUtils.containsInCacheSet(key, value2);
if (cacheSet2) {
System.out.println("代码2:" + "存在这个value");
} else {
System.out.println("代码2:" + "不存在这个value");
} // 记录结束时间
long endTime2 = System.nanoTime(); // 计算执行时间(以毫秒为单位)
long executionTime2 = (endTime2 - startTime2) / 1_000_000; // 将纳秒转换为毫秒 System.out.println("代码执行时间2: " + executionTime2 + " 毫秒"); }
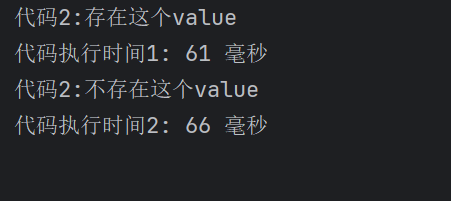
可以看到,其实对于时间来说,61毫秒和66毫秒可以说时间非常短了,不愧是redis,即使数据量很大,但是查询一个value是否在比较大的set的效率是非常短的.
往一个key中添加一个value,或者删除一个value--->(对应一个点赞,和取消点赞)
@Test
public void addAndRemoveElementFromBigKey() {
String key = "userId:114514:publication_id:738836";
String value1 = "10000000";
String value2 = "200000"; // 记录开始时间
long startTime = System.nanoTime(); boolean cacheSet1 = RedisUtils.addToCacheSet(key, value1); // 记录结束时间
long endTime = System.nanoTime(); // 计算执行时间(以毫秒为单位)
long executionTime = (endTime - startTime) / 1_000_000; // 将纳秒转换为毫秒 System.out.println("添加一个元素的执行时间: " + executionTime + " 毫秒"); // 记录开始时间
long startTime2 = System.nanoTime(); boolean cacheSet2 = RedisUtils.removeFromCacheSet(key, value2); // 记录结束时间
long endTime2 = System.nanoTime(); // 计算执行时间(以毫秒为单位)
long executionTime2 = (endTime2 - startTime2) / 1_000_000; // 将纳秒转换为毫秒 System.out.println("删除一个元素的代码执行时间: " + executionTime2 + " 毫秒"); }
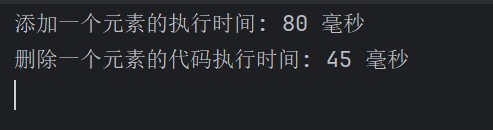
但从时间来讲,只有一个字:快
查询占用的内存的空间
MEMORY USAGE userId:114514:publication_id:738836

其实可以看到,大概是占用66mb,如果用户的id为雪花算法的id,那可能占用的内存100mb
以上来说,主要还是一个bigkey的问题,如果点赞的数量过大,占用的内存过大,宝贵的内存不应该给这种业务.
自然而然,我们想到用非关系型数据库,但是不要是基于内存的,我想到的是用MongoDB的方案
我们可以往MongoDB中插入一条这样的数据:
db.collectionName.insertOne({
"id": "yourIdValue",
"userId": yourUserIdValue,
"type": yourTypeValue,
"likedItemId": yourLikedItemIdValue,
"createTime": new Date("yourCreateTimeValue")
});id 主键id,userId为用户的ID,type为文章或者动态或者其他的类型,likedItemId为文章或者动态或者其他的类型的主键ID,createTime为点赞时间
在MongoDB中,可以使用
createIndex方法来创建唯一索引。为userId,type和likedItemId字段创建一个唯一索引。db.collectionName.createIndex(
{ "userId": 1, "type": 1, "likedItemId": 1 },
{ unique: true, name: "unique_index_name" }
);
详细解释:
collectionName:集合名称。unique_index_name:你想要给索引起的名字,可以根据你的需求替换为其他名称。
这个命令将在
collectionName集合上创建一个名为unique_index_name的唯一索引,涵盖了userId、type和likedItemId字段。1表示升序,如果需要降序索引,可以使用-1。unique: true选项确保索引是唯一的。执行这个命令后,如果有重复的组合出现在这三个字段上,MongoDB将会阻止插入并抛出错误。
即如果里面有记录为已经点过赞,点赞就是往里面加记录,取消点赞就是删除记录
详细代码如下:
@Service
public class LikeServiceImpl implements LikeService {
@Autowired
private MongoTemplate mongoTemplate; @Autowired
private PublicationService publicationService; /**
* 为动态或者文章点赞
*
* @param publicationId 动态或者文章的ID
* @param userId 用户的ID
* @param type 类型,区分是文章还是动态
* @return 点赞总数
*/
@Override
public Integer likePublication(Long publicationId, Long userId, Integer type) {
// 构建查询条件
Criteria criteria = Criteria.where("userId").is(userId)
.and("type").is(type)
.and("likedItemId").is(publicationId);
// 创建查询对象并应用查询条件
Query query = new Query(criteria);
boolean isExists = mongoTemplate.exists(query, PublicationLike.class); if (isExists) {
Asserts.fail("重复点赞");
}
//将点赞记录保存到mongodb
PublicationLike publicationLike = new PublicationLike();
publicationLike.setType(type);
publicationLike.setCreateTime(DateUtil.date());
publicationLike.setLikedItemId(publicationId);
publicationLike.setUserId(userId);
PublicationLike savedLike = mongoTemplate.save(publicationLike);
//点赞数统计 String redisLikeCountKey = String.format(RedisConstant.PUBLICATION_LIKE_COUNT, publicationId, userId, type);
Long likeCount = RedisUtils.getAtomicValueWithDefault(redisLikeCountKey);
//如果没有缓存过点赞数,则查询数据库
if (likeCount.equals(-1L)) {
Publication publication = publicationService.getById(publicationId);
RedisUtils.setAtomicValue(redisLikeCountKey, publication.getLikeCount());
return publication.getLikeCount();
} else {
//返回点赞数+1
return Math.toIntExact(RedisUtils.incrAtomicValue(redisLikeCountKey));
} } @Override
public Integer unlikePublication(Long publicationId, Long userId, Integer type) {
// 构建查询条件
Criteria criteria = Criteria.where("userId").is(userId)
.and("type").is(type)
.and("likedItemId").is(publicationId);
// 创建查询对象并应用查询条件
Query query = new Query(criteria);
boolean isExists = mongoTemplate.exists(query, PublicationLike.class); if (!isExists) {
Asserts.fail("未点赞过该内容,无法取消点赞");
} // 从MongoDB中删除点赞记录
mongoTemplate.remove(query, PublicationLike.class); // 更新点赞数统计
String redisLikeCountKey = String.format(RedisConstant.PUBLICATION_LIKE_COUNT, publicationId, userId, type);
Long likeCount = RedisUtils.getAtomicValueWithDefault(redisLikeCountKey); // 如果点赞数存在于缓存中,减少点赞数并返回
if (!likeCount.equals(-1L)) {
long newLikeCount = RedisUtils.decrAtomicValue(redisLikeCountKey);
return Math.toIntExact(newLikeCount);
} else {
// 如果点赞数没有缓存,查询数据库并更新缓存
Publication publication = publicationService.getById(publicationId);
if (publication != null) {
RedisUtils.setAtomicValue(redisLikeCountKey, publication.getLikeCount());
return publication.getLikeCount();
} else {
Asserts.fail("无法获取点赞数");
return 0;
}
}
} }
关于点赞业务对MySQL和Redis和MongoDB的思考的更多相关文章
- MySQL、Redis、MongoDB网络抓包工具
简介 go-sniffer 可以抓包截取项目(MySQL.Redis.MongoDB)中的请求并解析成相应的语句,并格式化输出.类似于在之前的文章 MySQL抓包工具:MySQL Sniffer[转] ...
- spring boot多数据源配置(mysql,redis,mongodb)实战
使用Spring Boot Starter提升效率 虽然不同的starter实现起来各有差异,但是他们基本上都会使用到两个相同的内容:ConfigurationProperties和AutoConfi ...
- 浅谈 Redis 与 MySQL 的耦合性以及利用管道完成 MySQL 到 Redis 的高效迁移
http://blog.csdn.net/dba_waterbin/article/details/8996872 ㈠ Redis 与 MySQL 的耦合性 在业务架构早期.我们 ...
- laravel集成workerman,使用异步mysql,redis组件时,报错EventBaseConfig::FEATURE_FDS not supported on Windows
由于laravel项目中集成了workerman,因业务需要,需要使用异步的mysql和redis组件. composer require react/mysql composer require c ...
- 【Docker】 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二)
系列目录: [Docker] CentOS7 安装 Docker 及其使用方法 ( 一 ) [Docker] 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二) [D ...
- Mysql和Redis数据如何保持一致
先阐明一下Mysql和Redis的关系:Mysql是数据库,用来持久化数据,一定程度上保证数据的可靠性:Redis是用来当缓存,用来提升数据访问的性能. 关于如何保证Mysql和Redis中的数据一致 ...
- linux安装和配置 mysql、redis 过程中遇到的问题记录
linux下部署mysql和redis网上的教程很多,这里记录一下我部署.配置的过程中遇到的一些问题和解决办法. mysql ①安装完成后启动的时候报错 Starting MySQL.The serv ...
- Mysql与Redis的同步实践
一.测试环境在Ubuntu kylin 14.04 64bit 已经安装Mysql.Redis.php.lib_mysqludf_json.so.Gearman. 点击这里查看测试数据库及表参考 本文 ...
- 通过Gearman实现MySQL到Redis的数据同步
对于变化频率非常快的数据来说,如果还选择传统的静态缓存方式(Memocached.File System等)展示数据,可能在缓存的存取上会有很大的开销,并不能很好的满足需要,而Redis这样基于内存的 ...
- 一步完成 MySQL 向 Redis 迁移
从mysql搬一个大表到redis中,你会发现在提取.转换或是载入一行数据时,速度慢的让你难以忍受.这里我就要告诉一个让你解脱的小技巧.使用“管道输出”的方式把mysql命令行产生的内容直接传递给re ...
随机推荐
- rest-apiV2.0.0升级为simplest-api开源框架生态之simplest-jpa发布
什么是 simplest simplest 追求存粹简单和极致. 旨在为项目快速开发提供一系列的基础能力,方便用户根据项目需求快速进行功能拓展 不在去关心一些繁琐.重复工作,而是把重点聚焦到业务. 前 ...
- .Net Web API 004 Controller获取对象列表,传入数据以及对象
1.返回UserEntityList 这个服务接口的目的是分为用户列表,代码如下所示. /// <summary> /// 得到用户列表 /// </summary> /// ...
- [论文阅读] 颜色迁移-Illuminant Aware Gamut-Based
[论文阅读] 颜色迁移-Illuminant Aware Gamut-Based 文章: [Illuminant Aware Gamut-Based Color Transfer], [python代 ...
- Ehcache的Maven依赖及其配置文件
Ehcache的Maven依赖 <!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache --> ...
- 文心一言 VS 讯飞星火 VS chatgpt (72)-- 算法导论7.1 3题
三.请简要地证明:在规模为 n 的子数组上,PARTITION 的时间复杂度为 Θ(n). 文心一言: 首先,我们需要明确PARTITION函数的具体定义.PARTITION函数通常用于快速排序算法中 ...
- Hybrid App 技术路径带动性能的提升
说到 Hybrid App(混合应用)大家都不陌生,因为这种开发模式大行其道发展的这些年取代了很多原生和 Web 应用,为什么大家对这种「Native + HTML5」的开发模式额外偏爱呢? 因为一方 ...
- 每日一库:fsnotify简介
fsnotify是一个用Go编写的文件系统通知库.它提供了一种观察文件系统变化的机制,例如文件的创建.修改.删除.重命名和权限修改.它使用特定平台的事件通知API,例如Linux上的inotify,m ...
- 魔术方法__getitem__
Python中的魔术方法_getitem_ python中有许多的魔术方法,下文主要对_getitem_()进行介绍.__ 在python中_getitem_(self, key):方法被称为魔法方法 ...
- 在Windows下用VScode构造shell脚本的IDE
在linux系统中,大家可以很轻松的开发.调试shell脚本.但是,对于不熟悉linux系统 的小白或者想在Windows下开发shell脚本的人来说,这就有点不友好了.本篇文章就 教大家,在Wind ...
- 纯分享:将MySql的建表DDL转为PostgreSql的DDL
背景 现在信创是搞得如火如荼,在这个浪潮下,数据库也是从之前熟悉的Mysql换到了某国产数据库. 该数据库我倒是想吐槽吐槽,它是基于Postgre 9.x的基础上改的,至于改了啥,我也没去详细了解,当 ...