寻找市场中的Alpha-WorldQuant功能的实现(下)
导语:本文介绍Alpha的相关基本概念,以及寻找和检验Alpha的主要流程和方法。在上篇中我们梳理了 WorldQuant经典读本FindingAlphas的概要以及WebSim的使用。作为下篇,我们演示如何通过BigQuant平台可以复现WebSim的因子分析功能,可以只输入因子表达式以及一些相关参数,便能够获取因子分析的相关结果。
模拟步骤流程
1、 输入测试的alpha表达式:在左上方m6输入特征列表模块中输入表达式。 2、 选择市场标的范围 :
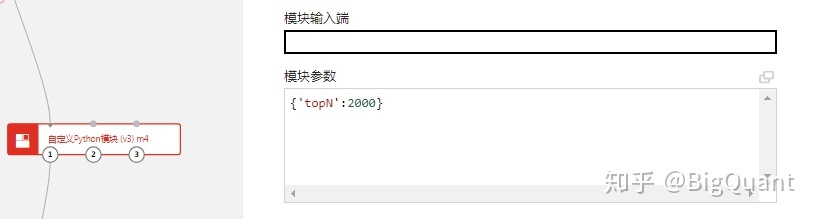
topN:代表选取流动性排名前N的股票作为证券池,在m4自定义模块中设置股票池范围,默认2000
3、 设置Delay: 延迟1(默认设置)表示alpha将使用昨天的数据(价格等)。延迟0意味着alpha将使用今天的数据。本例中默认会输出close_0/close_1和close_0/open_0两类Alpha,对应着延迟0和延迟1,因此无需设置。
4、 设置Decay: 代表因子平滑的参数,decay其实就是下面表达式中的n,默认是4 Decay_linear (x, n) = (x[date] * n x[date - 1] * (n - 1)… X[date - N - 1]) / (n (n - 1)… 1) 可以在m5模块中设置此参数:

5、 设置中性化:
neuralized_type:代表中性化的方式,分别有market和industry两种方式 可以在自定义模块m8中设置中性化方式

6 设置最大权重限制 :
max_stock_weight:代表组合中的单个股票最大权重,默认0.1 也是在自定义模块m8中设置,见上图。
7、 设置本金:
Booksize:代表本金,默认本金1千万,2倍杠杠的话就是2千万,在m16模块中设置

8、设置回测起止时间 回测起止时间通过证券代码列表m1模块设置。

评价指标介绍
Long/Short Count: 多空头寸数量
PnL: 当期头寸损益(金额)
Sharpe: 夏普比
Fitness: 定义为Sharpe * abs(Returns) / Turnover
Returns: 年化收益率
Drawdown: 最大回撤
Turnover: 换手率
Margin: 定义为PnL / 总交易额
Alpha0: 权重是当天因子值,收益率定义:close_0/open_0-1
Alpha1: 权重是前一天因子值,收益率定义:close_0/close_1-1
Alpha2:权重是前一天因子值,收益率定义:close_0/open_0-1
案例展示:
我们以市值因子作为示例,因子表达式为:-1*market_cap_0。我们在模块m6中输入因子表达式,选择默认参数,点击运行全部。可是以下链接克隆源码:
def m7_run_bigquant_run(input_1, input_2, input_3):
ins = input_1.read_pickle()['instruments']
start_date = input_1.read_pickle()['start_date']
end_date = input_1.read_pickle()['end_date']
industry_df = D.history_data(ins,start_date=start_date,end_date=end_date,fields='industry_sw_level1')
processed_industry_df = industry_df.pivot(index='date',columns='instrument',values='industry_sw_level1')\
.dropna(how='all')\
.stack()\
.apply(lambda x: 'SW'+str(int(x))+'.SHA')\
.reset_index()\
.rename(columns={0:'industry_code'})
## 过滤为0的数据异常,不过不应该被简单过滤
processed_industry_df = processed_industry_df[processed_industry_df['industry_code'].apply(lambda x:len(x)==12)]
data_1 = DataSource.write_df(processed_industry_df)
return Outputs(data_1=data_1, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m7_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m4_run_bigquant_run(input_1, input_2, input_3, topN):
# 示例代码如下。在这里编写您的代码
amount_df = input_1.read_df()
universe_dic = amount_df.groupby('date').apply(lambda df: df.sort_values('amount_0', ascending=False)[:topN].instrument.tolist()).to_dict()
return Outputs(data_1=DataSource().write_pickle(universe_dic))
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m4_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m5_run_bigquant_run(input_1, input_2, input_3, decay):
# 示例代码如下。在这里编写您的代码
df = input_1.read_df()
factor = list(set(input_2.read_pickle()).difference(['end_date', 'instruments', 'start_date']))[0]
pvt = df.pivot(index='date', columns='instrument', values=factor)
pvt = pvt.rolling(decay).apply(lambda x: sum([(i+1)*xx for i,xx in enumerate(x)])/sum(range(decay+1)))
result = pvt.unstack().reset_index().rename(columns={0:factor})
ds = DataSource().write_df(result)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m5_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m8_run_bigquant_run(input_1, input_2, input_3, max_stock_weight, neuralized_type):
# 示例代码如下。在这里编写您的代码
df = input_1.read_df()
factor = list(set(input_3.read_pickle()).difference(['end_date', 'instruments', 'start_date']))[0]
pvt = df.pivot(index='date', columns='instrument', values=factor)
universe_dic = input_2.read_pickle()
all_dates = sorted(list(universe_dic.keys()))
weights = {}
for date in all_dates:
alpha = pvt.loc[date, universe_dic[date]]
if neuralized_type == 'market':
# 市场中性化
alpha = alpha - alpha.mean()
elif neuralized_type == 'industry':
# 行业中性化
group_mean = df[df.date == date].groupby('industry_code', as_index=False).mean().rename(columns={factor:'group_mean'})
tmp = df[df.date == date].merge(group_mean, how='left', on='industry_code')
tmp[factor] = tmp[factor]- tmp['group_mean']
alpha = tmp.set_index('instrument')[factor].loc[universe_dic[date]]
alpha_weight = alpha / alpha.abs().sum()
alpha_weight = alpha_weight.clip(-max_stock_weight, max_stock_weight) # 权重截断处理
alpha_weight = alpha_weight / alpha_weight.abs().sum()
weights[date] = alpha_weight
ds = DataSource().write_pickle(weights)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m8_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m15_run_bigquant_run(input_1, input_2, input_3):
# 示例代码如下。在这里编写您的代码
alpha_weights = input_1.read_pickle()
ret_df = input_2.read_df()
ret0_df = ret_df.pivot(index='date', columns='instrument', values='close_0/close_1-1')
ret1_df = ret_df.pivot(index='date', columns='instrument', values='close_0/open_0-1')
alpha0, alpha1, alpha2 = {}, {}, {}
all_dates = sorted(alpha_weights.keys())
last_date = None
w_prev = None
for date in all_dates:
#Alpha0: 权重是当天因子值,收益:Close/Open -1
#Alpha1: 权重是前一天因子值,收益:Close/shift(Close, 1) -1
#Alpha2:权重是前一天因子值,收益:Close/Open -1
#根据统计,市场平均情况下次日低开概率较大,这个导致了alpha1的收益会更低
w = alpha_weights[date]
alpha0[date] = (ret1_df.loc[date, w.index]*w).sum()
alpha1[date] = (ret0_df.loc[date, w_prev.index]*w_prev).sum() if w_prev is not None else 0.0
alpha2[date] = (ret1_df.loc[date, w_prev.index]*w_prev).sum() if w_prev is not None else 0.0
w_prev = w
alpha0 = pd.Series(alpha0)
alpha1 = pd.Series(alpha1)
alpha2 = pd.Series(alpha2)
alpha = pd.DataFrame({'alpha0':alpha0,
'alpha1':alpha1,
'alpha2':alpha2})
ds = DataSource().write_df(alpha)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m15_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m16_run_bigquant_run(input_1, input_2, input_3, booksize):
# 示例代码如下。在这里编写您的代码
def calc_daily_turnover(alpha_weights):
all_dates = sorted(alpha_weights.keys())
last_date = None
turnover = {}
for date in all_dates:
w = alpha_weights[date]
w.name = 'w'
w_prev = alpha_weights[last_date] if last_date is not None else pd.Series(0,index=w.index)
w_prev.name = 'w_prev'
tmp = pd.concat([w,w_prev], axis=1).fillna(0)
turnover[date] = (tmp['w']-tmp['w_prev']).abs().sum()
last_date = date
turnover = pd.Series(turnover)
turnover /= 2
return turnover
import empyrical
alpha_df = m15.data_1.read_df()
alpha_weights = m8.data_1.read_pickle()
dailyPnL = alpha_df*booksize
PnL = dailyPnL.groupby(dailyPnL.index.year).sum()
IR = dailyPnL.groupby(dailyPnL.index.year).mean()/dailyPnL.groupby(dailyPnL.index.year).std()
sharpe = IR * np.sqrt(252)
returns = dailyPnL.groupby(dailyPnL.index.year).sum()/booksize
daily_turnover = calc_daily_turnover(alpha_weights)
turnover = daily_turnover.groupby(daily_turnover.index.year).mean()
fitness = sharpe * np.sqrt(returns.abs().apply(lambda x: x/turnover))
margin = PnL.apply(lambda x: x/(daily_turnover.groupby(daily_turnover.index.year).sum()*booksize)*10000)
long_short_count = pd.DataFrame({date:((w>0).sum(), (w<0).sum()) for date, w in alpha_weights.items()}).T
long_short_count = long_short_count.rename(columns={0: 'long', 1: 'short'})
long_short_count = long_short_count.groupby(long_short_count.index.year).sum()
max_drawdown = dailyPnL.apply(lambda x: empyrical.max_drawdown(x/booksize))
dataset_ds = DataSource()
output_store = dataset_ds.open_df_store()
dailyPnL.to_hdf(output_store, key='dailyPnL')
PnL.to_hdf(output_store, key='PnL')
turnover.to_hdf(output_store, key='turnover')
fitness.to_hdf(output_store, key='fitness')
margin.to_hdf(output_store, key='margin')
max_drawdown.to_hdf(output_store, key='max_drawdown')
long_short_count.to_hdf(output_store, key='long_short_count')
sharpe.to_hdf(output_store, key='sharpe')
returns.to_hdf(output_store, key='returns')
dataset_ds.close_df_store()
return Outputs(data_1=dataset_ds)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m16_post_run_bigquant_run(outputs):
return outputs
m1 = M.instruments.v2(
start_date='2010-01-01',
end_date='2018-09-30',
market='CN_STOCK_A',
instrument_list='',
max_count=0
)
m7 = M.cached.v3(
input_1=m1.data,
run=m7_run_bigquant_run,
post_run=m7_post_run_bigquant_run,
input_ports='',
params='{}',
output_ports=''
)
m2 = M.input_features.v1(
features='mean(amount_0,66)'
)
m3 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m2.data,
start_date='',
end_date='',
before_start_days=0
)
m4 = M.cached.v3(
input_1=m3.data,
run=m4_run_bigquant_run,
post_run=m4_post_run_bigquant_run,
input_ports='',
params='{\'topN\':2000}',
output_ports='',
m_cached=False
)
m6 = M.input_features.v1(
features='-1*market_cap_0',
m_cached=False
)
m10 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m6.data,
start_date='',
end_date=''
)
m11 = M.derived_feature_extractor.v3(
input_data=m10.data,
features=m6.data,
date_col='date',
instrument_col='instrument',
user_functions={}
)
m5 = M.cached.v3(
input_1=m11.data,
input_2=m6.data,
run=m5_run_bigquant_run,
post_run=m5_post_run_bigquant_run,
input_ports='',
params='{\'decay\': 4}',
output_ports='',
m_cached=False
)
m9 = M.join.v3(
data1=m7.data_1,
data2=m5.data_1,
on='date,instrument',
how='inner',
sort=False
)
m8 = M.cached.v3(
input_1=m9.data,
input_2=m4.data_1,
input_3=m6.data,
run=m8_run_bigquant_run,
post_run=m8_post_run_bigquant_run,
input_ports='',
params="""{'max_stock_weight': 0.1,
'neuralized_type': 'industry'}""",
output_ports='',
m_cached=False
)
m12 = M.input_features.v1(
features="""close_0/open_0-1
close_0/close_1-1
"""
)
m13 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m12.data,
start_date='',
end_date='',
before_start_days=0
)
m14 = M.derived_feature_extractor.v3(
input_data=m13.data,
features=m12.data,
date_col='date',
instrument_col='instrument',
user_functions={}
)
m15 = M.cached.v3(
input_1=m8.data_1,
input_2=m14.data,
run=m15_run_bigquant_run,
post_run=m15_post_run_bigquant_run,
input_ports='',
params='{}',
output_ports='',
m_cached=False
)
m16 = M.cached.v3(
input_1=m15.data_1,
run=m16_run_bigquant_run,
post_run=m16_post_run_bigquant_run,
input_ports='',
params='{\'booksize\': 20000000}',
output_ports='',
m_cached=False
)寻找市场中的Alpha-WorldQuant功能的实现(下)的更多相关文章
- (转)软件版本中的Alpha,Beta,RC,Trial是什么意思?
版本号:V(Version):即版本,通常用数字表示版本号.(如:EVEREST Ultimate v4.20.1188 Beta )Build:用数字或日期标示版本号的一种方式.(如:VeryCD ...
- 软件版本中的Alpha,Beta,RC,Trial是什么意思?
版本号: V(Version):即版本,通常用数字表示版本号.(如:EVEREST Ultimate v4.20.1188 Beta ) Build:用数字或日期标示版本号的一种方式.(如:VeryC ...
- 制作类似ThinkPHP框架中的PATHINFO模式功能(二)
距离上一次发布的<制作类似ThinkPHP框架中的PATHINFO模式功能>(文章地址:http://www.cnblogs.com/phpstudy2015-6/p/6242700.ht ...
- mixer中动态Alpha通道处理案例
本案例处理的是RGB+a,每个色彩的采样为10位位宽. 1.在Mixer IP中打开Alpha Blending Enable 和Alpha Input Stream Enable.这样在Blo ...
- Servlet中实现多个功能案例
如何实现一个Servlet中的多个功能 前言:唉,打脸了,前脚刚说过要跟Servlet正式告别,后脚这不又来了,哈哈,总结出一点东西,纠结了一下还是做个分享吧,学习知识比面子重要,对吧,下回再也不约S ...
- Python爬虫-爬取手机应用市场中APP下载量
一.首先是爬取360手机助手应用市场信息,用来爬取360应用市场,App软件信息,现阶段代码只能爬取下载量,如需爬取别的信息,请自行添加代码. 使用方法: 1.在D盘根目录新建.tet文件,命名为Ap ...
- WCF学习之旅—WCF4.0中的简化配置功能(十五)
六 WCF4.0中的简化配置功能 WCF4.0为了简化服务配置,提供了默认的终结点.绑定和服务行为.也就是说,在开发WCF服务程序的时候,即使我们不提供显示的 服务终结点,WCF框架也能为我们的服务提 ...
- Windows 10 版本 1507 中的新 AppLocker 功能
要查看 Windows 10 版本信息,使用[运行]> dxdiag 回车 下表包含 Windows 10 的初始版本(版本 1507)中包括的一些新的和更新的功能以及对版本 1511 的 W ...
- 禁用datagridview中的自动排序功能
把datagridview中的自动排序功能禁用自己收集的两种方法,看看吧①DataGridView中的Columns属性里面可以设置.进入"EditColumns"窗口后,在相应的 ...
- 【记录】尝试用android-logging-log4j去实现log输出内容到sd卡中的文件的功能
[背景] 折腾: [记录]给Android中添加log日志输出到文件 期间,已经试了: [记录]尝试用android中microlog4android实现log输出到文件的功能 但是不好用. 然后就是 ...
随机推荐
- Python条件控制和循环语句(if while for )
Python条件控制和循环语句(if while for ) 条件控制 概念:Python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块 结构 1. 顺序结构 ...
- AI测试,给出的答案还挺那么回事儿的~
今天文心一言全民开放了,所有人都可以正常下载使用了,不用像之前一样排队等号了.之前内测阶段倒也体验过,技术人员总是喜欢尝鲜,第一时间拿到邀请码后就各种调戏了TA一番,那时觉得给出的答案总有些差强人意, ...
- iOS发送探针日志到日志系统的简单实现
通过参考Testin的SDK实现方式,我们大致可以确定他们背后的实现方式: 首先,通过加载Testin的SDK,然后收集各种七七八八的数据,再通过socket发送数据到云端. 云端我们已经有了,就是h ...
- 「sdoi2019 - D2T2」移动金币
对 @command_block 没有 implementation 做法的细化.理论来说可以通过,但因为我实现得较劣无法通过.:( 把金币中的空隙看作石子,就是一个阶梯 Nim 的模型(有总共 \( ...
- FreeSWITCH容器化问题之rtp端口占用
操作系统 :CentOS 7.6_x64.debian 11 (bullseye,docker) FreeSWITCH版本 :1.10.9 Docker版本:23.0.6 FreeSWITCH容器化带 ...
- oracle问题:ORA-09817及解决办法
某天以管理员身份登录公司测试库报ORA-09817错误,查了网上的文章说是审计文件没有存储空间造成的.我的这问题也证实了这一点,现将解决步骤分享: 1.发现问题:报ORA-09817 oracle@l ...
- Apollo2.1.0+Springboot使用OpenApI
依赖管理 <!-- bootstrap最高级启动配置读取 --> <dependency> <groupId>org.springframework.cloud&l ...
- 【BUU刷题日记】--第二周
[BUU刷题日记]--第二周 一.[WUSTCTF2020]朴实无华 1 目录爆破 使用dirsearch扫描发现没有结果,因为如果dirsearch请求过快则会导致超出服务器最大请求,扫描不出本来可 ...
- Unity - UIWidgets 1. 从Hello world开始
安装参照github的README.UIWidgets相当于Flutter的一个Unity实现(后面表示UIWidgets和UGUI区别时直接称"Flutter"),是把承载的所有 ...
- meet
以后就放弃csdn了,就来这里记录自己的成长,就当成一个树洞吧,开心与难过,学习与生活,进步与成长,留下时间的痕迹!冲!冲!冲!