SSD-KD:天翼云&清华出品,最新无原始数据的蒸馏研究 | CVPR'24
无数据知识蒸馏能够利用大型教师网络所学到的知识,来增强较小型学生网络的训练,而无需访问原始训练数据,从而避免在实际应用中的隐私、安全和专有风险。在这方面的研究中,现有的方法通常遵循一种反演蒸馏的范式,在预训练教师网络指导下实时训练生成对抗网络来合成一个大规模的样本集用于知识蒸馏。论文重新审视了这种常见的无数据知识蒸馏范式,表明通过“小规模逆向数据进行知识蒸馏”的视角,整体训练效率有相当大的提升空间。根据三个经验观察结果,这些观察结果表明在数据逆向和蒸馏过程中平衡类别分布在合成样本多样性和难度上的重要性,论文提出了小规模无数据知识蒸馏(
SSD-KD)。在形式化上,SSD-KD引入了一个调节函数来平衡合成样本,并引入了一个优先采样函数来选择合适的样本,通过动态回放缓冲区和强化学习策略进行辅助。SSD-KD可以在极小规模的合成样本(例如,比原始训练数据规模小10 \(\times\) )条件下进行蒸馏训练,使得整体训练效率比许多主流方法快一个或两个数量级,同时保持卓越或竞争性的模型性能,这一点在流行的图像分类和语义分割基准上得到了验证。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Small Scale Data-Free Knowledge Distillation

Introduction
对于资源受限设备上的计算机视觉应用,如何学习便携的神经网络同时保持满意的预测准确性是关键问题。知识蒸馏(KD)利用预训练的大型教师网络的信息来促进在相同训练数据上的较小目标学生网络的训练,已经成为一种主流解决方案。传统的KD方法假设原始训练数据始终可用。然而,由于潜在的隐私、安全、专有或数据规模等问题,实际中通常无法访问教师网络训练时使用的源数据集。为了解决训练数据的限制,数据无关的知识蒸馏最近引起了越来越多的关注。
数据无关知识蒸馏(D-KD)的基本思想是基于预训练的教师网络构建合成样本进行知识蒸馏,这些合成样本应当匹配原始训练数据的潜在分布。现有的顶级D-KD方法通常采用对抗性反演和蒸馏范式。
- 在反演过程中,通过将预训练的教师网络作为判别器来训练生成器。
- 在随后的知识蒸馏过程中,实时学习的生成器将合成伪样本用于训练学生网络。
然而,对抗性D-KD方法通常需要生成大量的合成样本(与原始训练数据集的规模相比),以确保可信的知识蒸馏。这给训练资源消耗带来了沉重负担,抑制了其在实际应用中的使用。在最近的一项工作中,作者提出了一种有效的元学习策略,该策略寻找共同特征并将其作为初始先验以减少生成器收敛所需的迭代步骤。尽管可以实现更快的数据合成,但仍然需要生成足够多的合成样本以确保有效的知识蒸馏。这忽略了后续知识蒸馏过程的效率,成为整体训练效率的主要瓶颈。总而言之,目前尚未有研究工作通过共同考虑数据反演和知识蒸馏过程来提高D-KD的整体训练效率。
为了弥补这一关键差距,论文提出首个完全高效的D-KD方法,即小规模无数据知识蒸馏(SSD-KD)。从一种新颖的“小数据规模”视角出发,提高了对抗反演和蒸馏范式的整体训练效率。在这项工作中,“数据规模”指的是在一个训练周期内用于知识蒸馏的总反演样本数量。
SSD-KD的提出主要源于三个观察的启发。
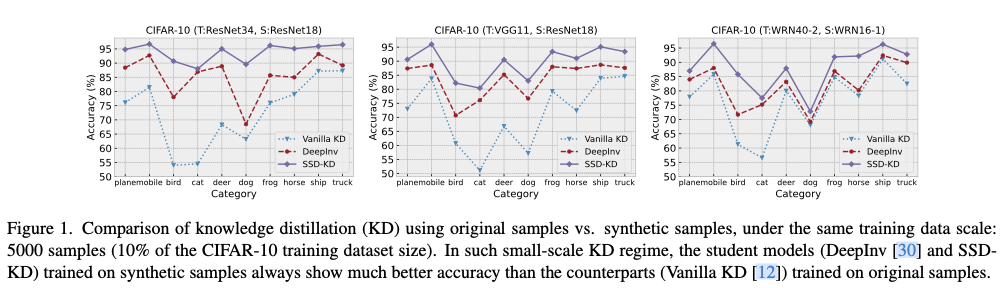
首先,论文观察到,当在不同的教师-学生网络对上将合成样本和原始样本的数据规模显著缩减到相同水平(例如,源训练数据集大小的10%)时,训练于合成样本的学生网络相比于训练于原始样本的对应网络显示出更好的性能,如图1所示。需要注意的是,合成样本是在全源数据集上预训练的教师网络的指导下生成的,这自然反映了原始数据分布的不同视角。在足够小的数据规模下,这使得合成样本在拟合整个源数据集的基础分布方面优于原始样本。这一启发性的观察表明,如果能够构建一个小规模的高质量合成样本集,将创造出一种通向完全高效D-KD的有希望的方法。从原则上讲,论文认为一个高质量的小规模合成数据集应该在合成样本的多样性和难度方面具有良好的类别分布平衡。
然而,论文其他两个观察表明,现有的D-KD方法,包括传统的和最有效的设计,都没有在小数据规模下平衡上述两个方面的类别分布的良好能力,如图2所示。需要注意的是,已经存在一些D-KD方法来增强合成样本的多样性,但合成样本在样本难度方面的多样性尚未被探讨。
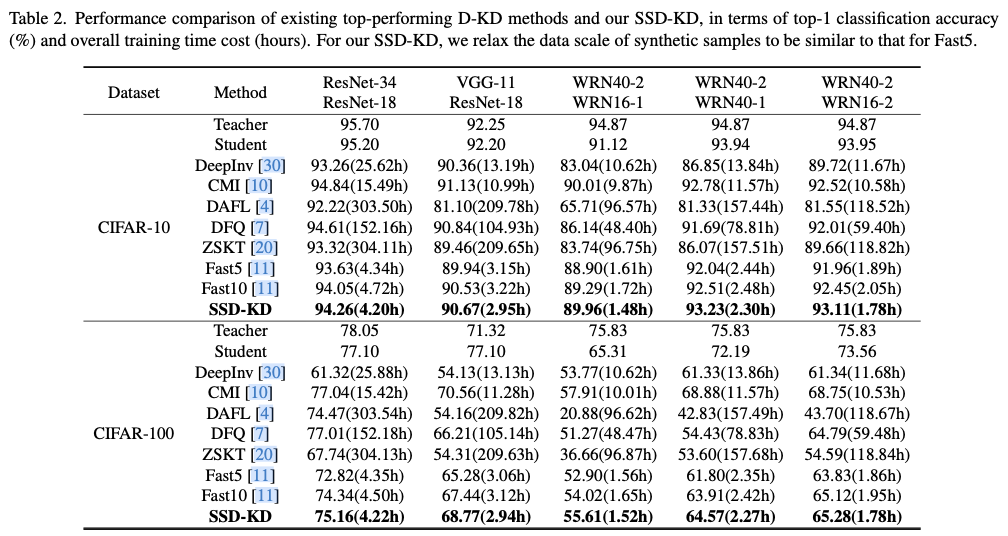
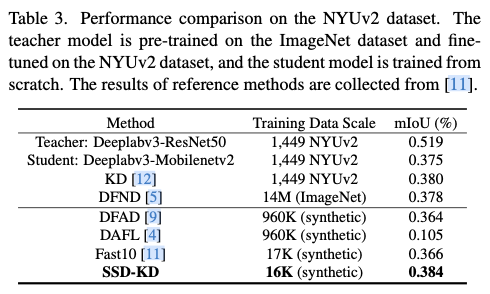
基于上述观察和分析,论文提出了SSD-KD,引入了两个相互依赖的模块以显著提高主要的对抗性反演和蒸馏范式的整体训练效率。SSD-KD的第一个模块依赖于一种新颖的调制函数,该函数定义了一个多样性感知项和一个难度感知项,以明确的方式共同平衡合成样本在数据合成和知识蒸馏过程中的类别分布。第二个模块定义了一种新颖的优先采样函数,这一函数通过强化学习策略来实现,从候选样本中选择少量适当的合成样本,这些样本存储在一个动态重放缓冲区中用于知识蒸馏,从而进一步提高端到端的训练效率。得益于这两个模块,SSD-KD具有两个吸引人的优点。一方面,SSD-KD可以在极小规模的合成样本(比原始训练数据规模小10倍)上进行蒸馏训练,使得整体训练效率比许多主流的D-KD方法快一个或两个数量级,同时保持竞争力的模型性能。另一方面,SSD-KD在学生模型准确性方面获得了大幅度的提升,并且在将合成样本的数据规模放宽到相对较大的数量时(仍然小于现有D-KD方法的规模)保持了整体训练效率。
Method
Preliminaries: D-KD
设 \({f_t(\cdot;\theta_t)}\) 为一个在原始任务数据集上预训练的教师模型,而该数据集现在已不可访问。D-KD的目标是首先通过反演教师模型学到的数据分布信息来构建一组合成训练样本 \(x\) ,然后在这些样本上训练一个目标学生模型 \({f_s(\cdot;\theta_s)}\) ,迫使学生模型模拟教师的功能。现有的D-KD方法大多使用生成对抗网络 \(g(;\theta_g)\) 来生成合成训练样本 \(x=g(z;\theta_g)\) ,其中 \(z\) 为潜在噪声输入,该生成对抗网络的训练是通过将教师模型作为鉴别器来进行的。
D-KD的优化包含一个常见的蒸馏正则化项,用于最小化教师-学生模型之间的功能差异 \(\mathcal{L}_{\text{KD}}({x})=D_\text{KD}(f_t(x; \theta_t)\| f_s(x; \theta_s))\) ,该差异基于KL散度。此外,还包含一个任务导向的正则化项 \(\mathcal{L}_{\text{Task}}({x})\) ,例如,使用教师模型的预测作为真实标签的交叉熵损失。除此之外,由于D-KD主要基于教师模型经过预训练后能够捕捉源训练数据分布的假设,近年来的D-KD方法引入了额外的损失项,以正则化数据反演过程中训练数据分布的统计量(批量归一化(BN)参数)。
\mathcal{L}_{\text{BN}}({x})= \sum_l \big\|\mu_l(x)-\mathbb{E}(\mu_l)\big\|_2+\big\| \sigma_l^2(x)-\mathbb{E}(\sigma_l^2)\big\|_2,
\end{equation}
\]
其中, \(\mu_l(\cdot)\) 和 \(\sigma_l(\cdot)\) 分别表示第 \(l\) 层特征图的批量均值和方差估计; \(\mathbb{E}(\cdot)\) 对批量归一化(BN)统计量的期望可以通过运行均值或方差进行近似替代。
D-KD的有效性在很大程度上依赖于从利用预训练教师模型知识反演得到的合成样本的质量。现行的对抗性D-KD范式包含两个过程,即数据反演和知识蒸馏。从效率和效果两个角度来看,一方面,数据反演过程在很大程度上影响学生模型的优化性能;另一方面,知识蒸馏的训练时间成本成为D-KD整体训练效率的一个重要限制因素。
Our Design: SSD-KD

SSD-KD专注于通过“用于知识蒸馏的小规模反演数据”这一视角来改进对抗性D-KD范式,着重于利用预训练教师模型和知识蒸馏过程的反馈来指导数据反演过程,从而显著加快整体训练效率。根据前述中的符号,SSD-KD的优化目标定义为
\min\limits_{f_s} \max\limits_{g} \mathbb{E}_{x = \delta \circ g\left(z\right)}\big(\mathcal{L}_{\text{BN}}({x})+\mathcal{L}_{\text{KD}}({x})+\phi(x)\mathcal{L}_{\text{Task}}({x})\big),
\label{eq:loss}
\end{align}
\]
其中,
采用了一种多样性感知的调制函数 \(\phi(x)\) ,该函数根据教师模型对每个合成样本的预测类别分配不同的优先级。
在
BN估计的约束下,通过 \(\phi(x)\) 鼓励生成器尽可能探索对教师模型来说更具挑战性的合成样本。不采用随机采样策略来选择样本进行知识蒸馏,而是采用重加权策略来控制采样过程。符号 \(\circ\) 来表示应用基于优先级采样函数 \(\delta\) 。
每个合成样本不仅由其调制函数 \(\phi(x)\) 进行优先级排序,而且在采样阶段还会重新加权,该阶段重用了与 \(\phi(x)\) 相同的中间值。
虽然D-KD流水线允许合成训练样本并用于在同一任务上训练学生模型,但存在大量数据冗余,这妨碍了D-KD方法的训练效率。SSD-KD是一种完全高效的D-KD方法,能够使用极小规模的合成数据,同时与现有的D-KD方法相比,达到具有竞争力的性能。
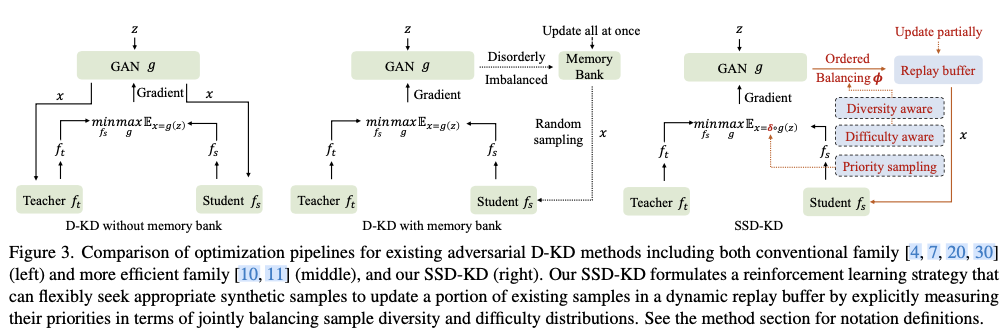
SSD-KD的流程总结在算法1中,现有对抗性D-KD方法的优化流程(包括传统家族和更高效家族)与我们的SSD-KD的比较如图3所示。
Data Inversion with Distribution Balancing
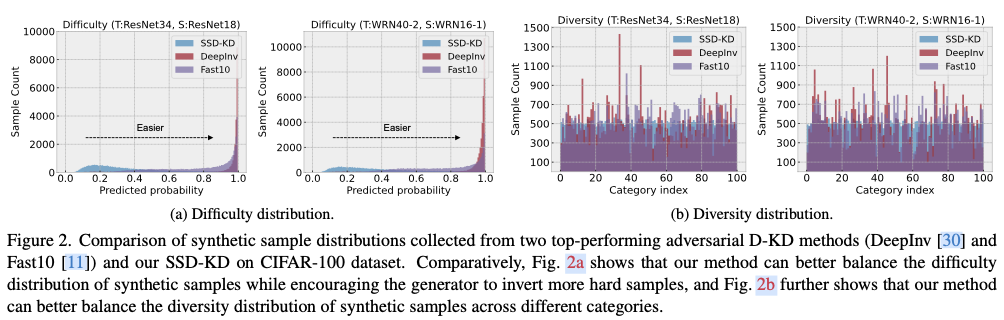
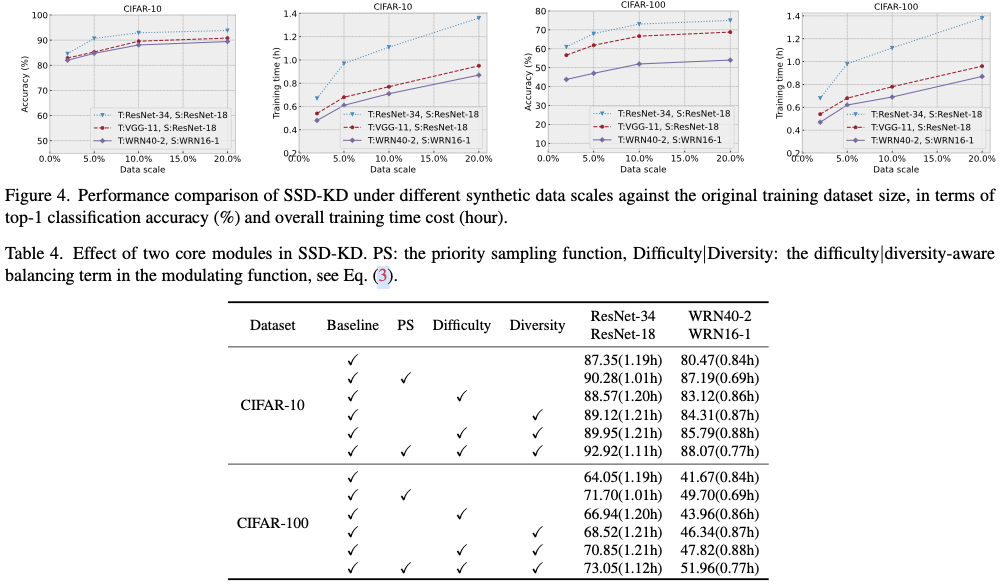
图2展示了D-KD中由于合成数据的大量不平衡导致的数据冗余。右侧两个子图描绘了教师模型预测的类别分布,显示了数据类别的显著不平衡,而左侧两个子图展示了不同预测难度下的样本数量(难度通过教师模型预测的概率来衡量)。对于D-KD来说,这表明仅仅根据教师-学生差异来生成样本会导致样本难度分布非常不均,并倾向于获得容易预测的数据样本。对于数据样本全部合成的D-KD任务,数据生成过程需要同时考虑教师-学生差异和教师自身的预训练知识,基于此,SSD-KD提出了考虑多样性和难度的数据合成方法。
Diversity-aware balancing
首先在数据反演过程中解决样本难度不平衡的问题。具体来说,维护一个回放缓冲区 \(\mathcal{B}\) ,它存储一定数量(记作 \(|\mathcal{B}|\) )的合成数据样本。对于 \(\mathcal{B}\) 中的每个数据样本 \(x\) ,惩罚与 \(x\) 共享相同预测类别(由教师模型预测)的样本总量。为实现这一点,采用了一个考虑多样性的平衡项,该项鼓励生成器合成具有不常见类别的样本。
Difficulty-aware balancing
借鉴在对象检测领域中使用焦点损失来处理高度不平衡样本的经验,进一步对每个样本 \(x\) 引入了一个基于预测概率 \(p_T(x)\) 的难度感知平衡项。在这里,困难的合成样本被认为是那些由教师模型预测信心较低的样本,这些样本会受到难度感知平衡项的鼓励。
总之,论文引入了一个调节函数 \(\phi(x)\) 来根据来自预训练教师模型的预测反馈调整生成器的优化。 \(\phi(x)\) 旨在平衡类别分布,并动态地区分容易和困难的合成样本,从而使容易的样本不会过度主导蒸馏过程。形式上,对于合成数据样本 \(x\in\mathcal{B}\) ,其调节函数 \(\phi(x)\) 的计算公式为
\phi (x) = \underbrace {\Big(1 - \frac{1}{|\mathcal{B}|}\sum_{x'\in\mathcal{B}}\mathbb{I}_{c_T(x')=c_T(x)}\Big)}_{\text{diversity-aware balancing}} \underbrace{{\Big(1 - p_T(x)\Big)}^\gamma }_{\text{difficulty-aware balancing}}
\label{eq:phi}
\end{equation}
\]
其中, \(c_T(x)\) 和 \(p_T(x)\) 分别指代预训练教师模型预测的类别索引和概率(或置信度); \(\mathbb{I}_{c_T(x')=c_T(x)}\) 表示一个指示函数,如果 \(x'\) 的预测类别与 \(x\) 相同,则该函数等于 \(1\) ,否则为 \(0\) ; \(\gamma\) 是一个超参数。
强调调节函数 \(\phi(x)\) 的两个特性:
- 对于在教师模型中预测置信度较高的数据样本 \(x\) (即被视为容易样本), \(\phi(x)\) 接近于低值,从而对任务相关损失 \(\mathcal{L}_{\text{Task}}({x})\) 在公式 (`ref`{eq:loss}) 中的影响较小。
- 当教师网络预测的合成数据样本在 \(\mathcal{B}\) 中的类别分布严重不平衡时,与 \(\mathcal{B}\) 中更多样本共享类别的样本 \(x\) 会受到惩罚,从而 \(\phi(x)\) 会削弱相应的 \(\mathcal{L}_{\text{Task}}({x})\) 。
尽管公式表明调节函数 \(\phi(x)\) 的值部分由当前的重放缓冲区 \(\mathcal{B}\) 决定,但需要注意的是, \(\mathcal{B}\) 是动态变化的,并且也受到 \(\phi(x)\) 的影响。这是因为公式中的项 \(\phi(x)\mathcal{L}_{\text{Task}}({x})\) 直接优化了生成器,该生成器合成数据样本以组成 \(\mathcal{B}\) 。从这个意义上说,考虑到 \(\mathcal{B}\) 和 \(\phi(x)\) 的相互影响,在训练过程中保持了类别多样性的平衡。在数据逆向过程中,平衡数据样本的类别尤为重要。
如图2所示,借助这两个平衡项,SSD-KD在样本类别和难度方面生成了温和的样本分布。
Distillation with Priority Sampling
原始的优先经验重放方法更频繁地重用重要知识的转移,从而提高学习效率。与此不同的是,论文的优先采样方法并不从环境中获得奖励,而是设计为适应无数据的知识蒸馏并从框架自身获取反馈。换句话说,优先采样方法在无数据知识蒸馏方法中扮演了相反的角色:它专注于训练一小部分高度优先的样本,而不是均匀采样,从而加速训练过程。
从当前的重放缓冲区 \(\mathcal{B}\) 中采样合成数据 \(x\) ,论文提出了一种名为优先采样(Priority Sampling, PS)的采样策略来调节采样概率,而不是均匀采样。PS的基本功能是衡量 \(\mathcal{B}\) 中每个样本 \(x\) 的重要性,因此引入了优先采样函数 \(\delta_{i}(x)\) 。
\delta_{i}(x) = w_{i-1}(x) KL(f_t(x;\theta_t)||f_s(x;\theta_s)),
\end{equation}
\]
\(KL\) 表示softmax输出 \(f_t(x;\theta_t)\) 和 \(f_s(x;\theta_s)\) 之间的KL散度; \(\theta_t\) 和 \(\theta_s\) 依赖于训练步骤 \(i\) ; \(w_{i}(x)\) 是用于归一化 \(\mathcal{B}\) 中样本的校准项,如下面的公式所形式化,特别地,当 \(i=0\) 时, \(w_{-1}(x)=1\) 。
使用随机更新进行知识蒸馏的训练,依赖于这些更新与其期望值具有相同的分布。优先采样数据会引入偏差,因为它可能会改变数据分布,从而影响估计值所收敛的解。因此,通过引入一个重要性采样(Importance Sampling, IS)权重 \(w_i(x)\) 来校正这种偏差,用于数据样本 \(x\) :
\label{eq_wi}
w_{i}(x)=(N \cdot P_{i}(x))^{-\beta},
\end{equation}
\]
其中 \(\beta\) 是一个超参数; \(P_{i}(x)\) 是定义为的采样过渡概率
\label{pi}
P_{i}(x)=\frac{\big(\left|\delta_{i}(x)\right|+\epsilon\big)^\alpha}{\sum_{x'\in\mathcal{B}}\big(\left|\delta_{i}(x')\right|+\epsilon\big)^\alpha},
\end{equation}
\]
其中 \(\epsilon\) 是一个小的正数,用于防止在优先级为零时转移不被选择的极端情况。
优先采样函数 \(\delta(x)\) 具有两个显著特性:
- 随着
delta值的增加, \(\delta(x)\) 反映了当前 \(\mathcal{B}\) 中合成样本的教师模型与学生模型之间的更大信息差异。因此,学生模型应从信息差异更大的样本中进行优化,这有助于更快地获取教师模型。 - \(\delta(x)\) 会随着学生模型和生成模型的每次更新迭代而动态变化。因此,当学生模型在某些样本上获得了教师模型的能力时,它会继续从相对于教师模型差异更大的样本中学习,基于新的样本分布。这进一步提升了学生模型的性能。
Experiment

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

SSD-KD:天翼云&清华出品,最新无原始数据的蒸馏研究 | CVPR'24的更多相关文章
- 天翼云 RDS数据库操作
1.RDS数据库创建好之后点击RDS实例管理找到已下信息 官方文档 -1:http://www.ctyun.cn/help/qslist/567 官方文档 -2:http://www.ctyun.cn ...
- 天翼云安装jdk(注意有坑)
1.下载jdk8 查看Linux位数,到oracle官网下载对应的jdk ① sudo uname --m 确认32位还是64位 ② https://www.oracle.com/technetwo ...
- 天翼云上新增IP备案具体操作步骤
0.点击右上角的备案,进入到备案中心 1.已备案信息管理 点击左侧的已备案信息管理,右侧出现的页面中找到已备案网站信息,网站负责人后面的操作里有5个图标,点击第三个(变更接入),提交订单,进入到下一步 ...
- 玩转云端 | 算力基础设施升级,看天翼云紫金DPU显身手!
数字时代下,算力成为新的核心生产力,传统以CPU为核心的架构难以满足新场景下快速增长的算力需求,具备软硬加速能力的DPU得以出现并快速发展.天翼云凭借领先的技术和丰富的应用实践自研紫金DPU,打造为云 ...
- “洞察千里”,华为云HiLens如何让无人车智行天下
作者:华为云 Rosie 随着人工智能的普及和渗透,"无人"的场景越来越丰富,无人超市.无人车.无人机等已经融入我们的生活. 乘着这股热浪,华为云携手上海交通大学学生创新中心举办了 ...
- 阿里云k8s应用最新日志采集不到的问题
问题描述: 阿里云k8s应用日志之前一直都是可以正常的采集, 先出现一问题, 通过kibana 和阿里云的日志服务都没法展示最新的k8s应用的日志, 部分应用的最新日志有被采集到,但大部分应用日志没有 ...
- azure 云上MySQL最新版本 MySQL5.7.11 批量自动化一键式安装 (转)
--背景云端 以前都喜欢了源码安装mysql,总觉得源码是高大上的事情,不过源码也需要时间,特别是make的时候,如果磁盘和cpu差的话,时间很长很长,在虚拟机上安装mysql尤其甚慢了. 现在业务发 ...
- 专访阿里云 Serverless 负责人:无服务器不会让后端失业
2012 年,云基础设施服务提供商 Iron.io 的副总裁 Ken 谈到软件开发行业的未来,首次提出了 Serverless 的概念,为云中运行的应用程序描述了一种全新的系统体系架构.此后,以 AW ...
- 【大数据-课程】高途-天翼云侯圣文-Day3-实时计算原理解析
〇.老师及课程介绍 一.今日内容 二.实时计算理论解析 1.什么是实时计算 微批处理.流式处理.实时计算 水流和车流的例子 spark streaming就是一种微批处理,水满了才处理,进入下一个地方 ...
- 阿里云ECS安装最新版本Node.js
原文 http://www.w3ctech.com/topic/1610 主题 Node.js操作系统服务器 我的ECS实例是Ubuntu操作系统,直接使用 apt-get install node ...
随机推荐
- oeasy 教您玩转linux 010304 图形界面 xfce
我们来回顾一下 上一部分我们都讲了什么? 讲了文件管理器和命令行终端互相交互 用命令nautilus在文件管理器打开某路径 这次我们来看看 图形用户界面(GUI)的情况 图形界面和发行版的关系 一个发 ...
- CF858C 题解
洛谷链接&CF 链接 本篇题解为此题较简单做法及较少码量,并且码风优良,请放心阅读. 题目简述 给你一个均为小写字母的字符串,如果它的子串同时满足: 三个连着的辅音字母. 这一段连着的辅音字母 ...
- Langchain 与 LlamaIndex:LLM 应用开发框架的比较与使用建议
Langchain 和 Llamaindex 是两种广泛使用的主流 LLM 应用开发框架.两者有什么不同?我们该如何使用?以下我根据各类资料和相关文档做了初步选型. 一.Langchain 1. 适用 ...
- 解密prompt系列34. RLHF之训练另辟蹊径:循序渐进 & 青出于蓝
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM So ...
- 英伟达又向开源迈了一步「GitHub 热点速览」
大家是否还记得 2012 年,Linux 之父 Linus Torvalds 在一次活动中"愤怒"地表达了对英伟达闭源 Linux GPU 驱动的不满?这个场景曾是热门表情包,程序 ...
- 搭建lnmp环境-mysql(第五步)
版本mysql 5.7 先删除系统自带的db 新建文件夹/data/download 进入后下载 wget http://repo.mysql.com/mysql57-community-releas ...
- wireshark抓包分析数据
wireshark抓包分析数据 https://www.cnblogs.com/moonbaby/p/10528401.html https://blog.csdn.net/wangyiyungw/a ...
- 【转载】 ImportError: libGL.so.1: cannot open shared object file: No such file or directory——docker容器内问题报错
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_35516745/article/de ...
- centos7系统 通过编译安装gcc7.5.0
背景: 现有的centos7 gcc的最高版本为4.8.5 项目需要升级到7.1.0以上 正常方式可以通过以下命令即可完成升级: $ sudo yum install centos-release-s ...
- 知攻善防Web1应急靶机笔记--详解
知攻善防Web1应急靶机笔记 概述 这是一台知攻善防实验室的应急响应靶机,方便大家练习一下应急响应的流程和操作. 靶机的前景概述: 前景需要: 小李在值守的过程中,发现有CPU占用飙升,出于胆子小,就 ...