hdfs修复块
磁盘满了一次,导致hdfs的很多块变成一个副本
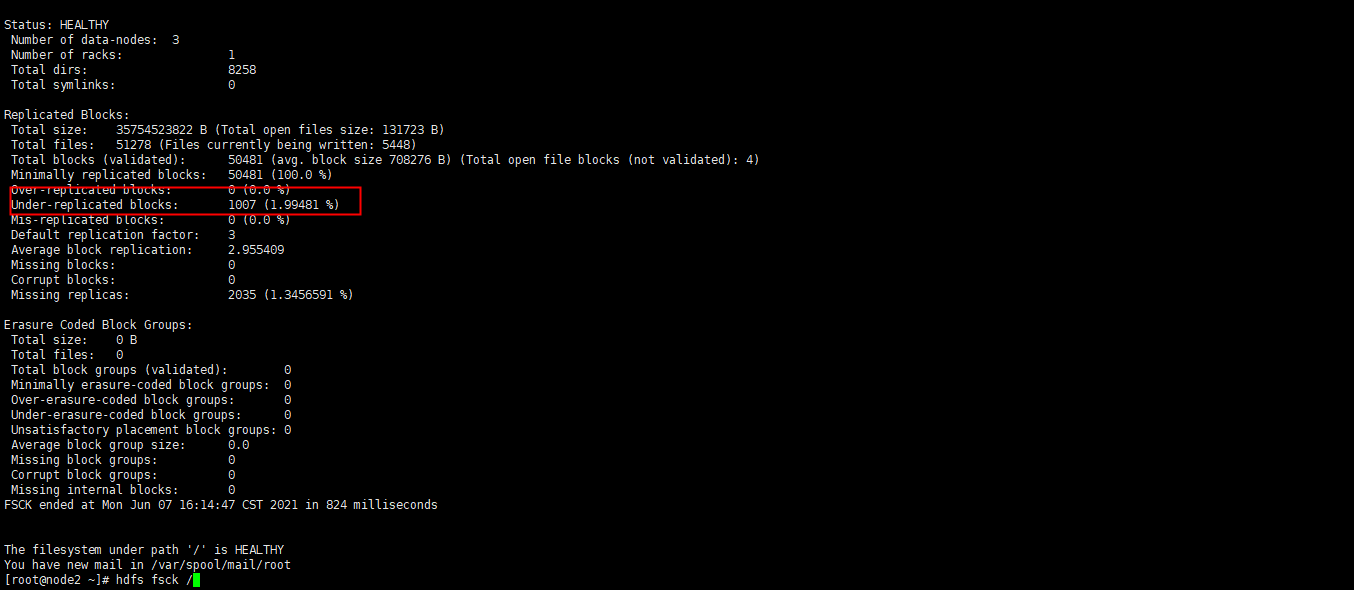
看一下副本信息
执行 hdfs fsck /
1007个块少于3个副本一下
而且 hbase的regionsever启动报错
File /apps/hbase/data/data/default/RECOMMEND.HOT_GOODS_RECOMMEND/3c3424f8a720878ebd969d90b0b376b9/recovered.edits/0000000000000027303-node1%2C16020%2C1621934159558.1622652845389.temp could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and no node(s) are excluded in this operation.
执行修复这些副本试试
先把部分不完整的的块路径写到 /tmp/under_replicated_files
hdfs fsck / | grep 'Under replicated' | awk -F':' '{print $1}' >> /tmp/under_replicated_files
写个脚本批量进行修复
#!/bin/bash
for line in `cat /tmp/under_replicated_files`
do
hdfs debug recoverLease -path $line
done
修复完成后,在执行下 hdfs fsck / 看块的情况
hdfs修复块的更多相关文章
- Hadoop hadoop 之hdfs数据块修复方法
hadoop 之hdfs数据块修复方法: .手动修复 hdfs fsck / #检查集群的健康状态 hdfs debug recoverLease -path 文件位置 -retries 重试次数 # ...
- Hadoop HDFS 文件块大小
HDFS 文件块大小 HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M ...
- hadoop 小文件 挂载 小文件对NameNode的内存消耗 HDFS小文件解决方案 客户端 自身机制 HDFS把块默认复制3次至3个不同节点。
hadoop不支持传统文件系统的挂载,使得流式数据装进hadoop变得复杂. hadoo中,文件只是目录项存在:在文件关闭前,其长度一直显示为0:如果在一段时间内将数据写到文件却没有将其关闭,则若网络 ...
- HDFS文件块
知识点补充 HDFS优缺点: 优点 (1)高容错性.节点存放的副本比较多. (2)适合处理大数据. GB.TB.PB级别的数据都可以处理. (3)可以构建在廉价的机器上,通过多副本机制来提高可靠性. ...
- hdfs 数据块重分布 sbin/start-balancer.sh -threshold
数据块重分布sbin/start-balancer.sh -threshold <percentage of disk capacity>percentage of disk capa ...
- HDFS数据块
磁盘也是由数据块组成的,一般默认大小是512字节,构建磁盘之上的文件系统一般是磁盘块的整数倍. HDFS也是采用块管理的,但是比较大,在Hadoop1.x中默认大小是64M,Hadoo ...
- Hadoop-2.4.0中HDFS文件块大小默认为128M
134217728 / 1024 = 131072 / 1024 = 128
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- HDFS 上文件块的副本数设置
一.使用 setrep 命令来设置 # 设置 /javafx-src.zip 的文件块只存三份 hadoop fs -setrep /javafx-src.zip 二.文件块在磁盘上的路径 # 设置的 ...
- 检查hdfs块的块-fsck
hadoop集群运行过程中,上下节点是常有的事情,如果下架节点,hdfs存储的块肯定会受到影响. 如何查看当前的hdfs的块的状态 hadoop1.x时候的命令,hadoop2.x也可使用: hado ...
随机推荐
- 阿里云边缘云ENS再升级 四大场景应用加速产业数字化落地
简介: 云栖大会 | 于10月21日上午举办的边缘云应用升级与技术创新论坛中,阿里云边缘云ENS产品全面升级,从边缘云产品.技术.行业应用等维度全面阐述阿里云在边缘计算领域的技术积累.产品& ...
- vue3 快速入门系列 —— 状态管理 pinia
其他章节请看: vue3 快速入门 系列 pinia vue3 状态管理这里选择 pinia. 虽然 vuex4 已支持 Vue 3 的 Composition API,但是 vue3 官网推荐新的应 ...
- To Be Vegetable
求满足下述条件的 \(n\) 阶排列 \(a\) 的数目:对每个 \(i\),要么 \(a_i-i\le a_j-j+d\) 对所有 \(j\gt i\) 成立,要么 \(a_i\ge a_j\) 对 ...
- Spark中的闭包引用和广播变量
闭包引用 概念 所有编程语言都有闭包的概念,闭包就是在一个函数中引用了函数外的变量. Spark中,普通的变量是在Driver程序中创建的,RDD的计算是在分布式集群中的task程序上进行的.因此,当 ...
- 羽夏闲谈——TeeWorlds 中文问题
不久前 削微寒 园友发布了一篇博文 误入 GitHub 游戏区,意外地收获颇丰 ,看到了一个游戏 TeeWorlds .有一说一挺好玩的,下面是那个博客的原图: 官方的下载连接:https:/ ...
- Docker 笔记汇总
一.名词说明 Dockerfile 镜像构建文件 Docker Images 镜像:生成容器 Docker Containers 容器:微型系统 Docker Volumes 卷:存放容器运行数据 D ...
- gin 单个文件函数 上传文件到本地目录里
// 单个文件 上传文件到本地目录里 // 调用方法 utils.UplaodFileToLocal(c) // author haima func UplaodFileToLocal(c *gin. ...
- MySQL优化方向
MySQL优化手段 数据库设计层面 范式设计 减少数据冗余 提高数据一致性 索引策略 选择合适的索引类型 (BTREE, HASH) 覆盖索引 索引选择性 表结构优化 使用合适的数据类型 避免使用NU ...
- 服务器电源管理(Power Management States)
目录 文章目录 目录 EIST(智能降频技术) 硬件 固件 操作系统 EIST(智能降频技术) EIST 能够根据不同的 OS(操作系统)工作量自动调节 CPU 的电压和频率,以减少耗电量和发热量.它 ...
- ansible功能实现
模糊匹配远程主机文件并拉取到本地服务器 又熬夜加班了.花很长时间研究出来.如何实现模糊匹配到的远程文件批量拉取到本地的剧本.使用copy模块的*,shll模块的* ls|grep XX都没有实现,貌似 ...