数值优化算法-BFGS
参考:
https://www.cnblogs.com/Leo_wl/p/3367323.html
牛顿法:
使用牛顿法优化函数 f(θ) 最小值时,每次计算获得新的\(θ\)值,即\(θ_{k+1}\)为\(θ_k\)的基础上计算所得。
\(g_k\)为\(f(\theta)\)在\(θ_k\)时雅可比向量,\(H_k\)为\(θ_k\)时Hession矩阵,整体的计算式为:
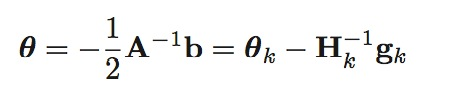
牛顿方法的步骤为:

BFGS算法
Newton算法在计算时需要用到Hessian矩阵H, 计算Hessian矩阵非常费时, 所以研究者提出了很多使用方法来近似Hessian矩阵, 这些方法都称作准牛顿算法, BFGS就是其中的一种, 以其发明者Broyden, Fletcher, Goldfarb和Shanno命名.
BFGS算法使用以下方法来近似Hessian矩阵, Bk≈Hk:
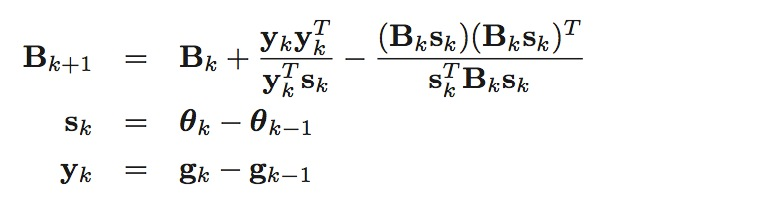
初始时可以取\(B_0=I\)
因为Hessian矩阵的大小为O(D2), 其中D为参数的个数, 所以有时Hessian矩阵会比较大, 可以使用L-BFGS(Limited-memory BFGS)算法来进行优化。
参考文献:
[1]. Machine Learning: A Probabilistic Perspective. p249-p252.
[2]. Wekipedia: L-BFGS
给出python版本调用scipy库进行bfgs的计算:
import scipy
def f(arg):
x1, x2 = arg
y = x1**2 + x2**2
return y, [2*x1, 2*x2]
ans = scipy.optimize.fmin_l_bfgs_b(f, (1000, 1000), maxiter=25)
# ans = scipy.optimize.fmin_l_bfgs_b(f, (1000, 1000), maxiter=2)
print(ans)
运行结果:

本文参考:
出处1:
源作者:Leo_wl
出处:http://www.cnblogs.com/Leo_wl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
数值优化算法-BFGS的更多相关文章
- 优化算法-BFGS
优化算法-BFGS BGFS是一种准牛顿算法, 所谓的"准"是指牛顿算法会使用Hessian矩阵来进行优化, 但是直接计算Hessian矩阵比较麻烦, 所以很多算法会使用近似的He ...
- paper 8:支持向量机系列五:Numerical Optimization —— 简要介绍求解求解 SVM 的数值优化算法。
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
- 数值最优化:一阶和二阶优化算法(Pytorch实现)
1 最优化概论 (1) 最优化的目标 最优化问题指的是找出实数函数的极大值或极小值,该函数称为目标函数.由于定位\(f(x)\)的极大值与找出\(-f(x)\)的极小值等价,在推导计算方式时仅考虑最小 ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- SMO优化算法(Sequential minimal optimization)
原文:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html SMO算法由Microsoft Research的John C. ...
- deeplearning.ai 改善深层神经网络 week2 优化算法 听课笔记
这一周的主题是优化算法. 1. Mini-batch: 上一门课讨论的向量化的目的是去掉for循环加速优化计算,X = [x(1) x(2) x(3) ... x(m)],X的每一个列向量x(i)是 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
随机推荐
- xv6 的锁机制
LOCK 公众号:Rand_cs 锁,大家应该很熟悉了,用来避免竞争,实现同步.本文以 xv6 为例来讲解锁本身是怎么实现的,废话不多说,先来看一些需要了解的概念: 一些概念 公共资源:顾名思义就是被 ...
- Vue学习:10.v标签综合-进阶版
再来一节v标签综合... 实例:水果购物车 实现功能: 显示水果列表:展示可供选择的水果列表,包括名称.价格等信息. 修改水果数量:允许用户在购物车中增加或减少水果的数量. 删除水果:允许用户从购物车 ...
- js金额格式化
function fmoney(s, n) //s:传入的float数字 ,n:希望返回小数点几位 { n = n > 0 && n <= 20 ? n : 2; s = ...
- Javascript高级程序设计第三章 | ch3 | 阅读笔记
语言基础 语法 标识符 注释 // /* */ 严格模式 // 也可以单独指定在一个函数中进行 'use strict' 语句 语句末尾分号不是必须的,但是最好加上 加上分号方便开发者删除空行压缩代码 ...
- BC5-牛牛学说话之-字符
题目描述 会说浮点数之后,牛牛开始尝试字符.输入一个字符,输出这个字符. 输入描述 输入一个字符,范围在 ascii 范围内 输出描述 输出这个字符 示例 1 输入:a 输出:a 解题思路 方案一 字 ...
- 燕千云 YQCloud 数智化业务服务管理平台发布1.11版本
2022年3月25日,燕千云 YQCloud 数智化业务服务管理平台发布1.11版本.新增客户服务管理模块.优化IT服务管理功能.增强燕千云与其他平台的集成能力.支持更多的业务服务场景.全面提升企业数 ...
- 认真学习css3-2-css的选择器
关于有哪些选择器,具体可以查看w3school. 本文写了一个考卷的例子,带有部分js,jquery.不会针对每个选择器做示例,只练习了一些常用的,有意思的. 先看html/js代码: <!DO ...
- Java开发者的神经网络进阶指南:深入探讨交叉熵损失函数
前言 今天来讲一下损失函数--交叉熵函数,什么是损失函数呢?大体就是真实与预测之间的差异,这个交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异 ...
- 大模型重塑软件开发,华为云AI原生应用架构设计与实践分享
在ArchSummit全球架构师峰会2024上,华为云aPaaS平台首席架构师马会彬受邀出席,和技术爱好者分享AI原生应用引擎的架构与实践. AI大模型与AI重塑软件的大趋势下,软件会发生哪些本质的变 ...
- Nginx配置文件nginx.conf中location的匹配原则
一.空格:默认匹配.普通匹配 location / { root /home; } 二.= :精确匹配(表示匹配到 /home/resources/img/face.png 这张图片) locati ...