baselines算法库common/vec_env/dummy_vec_env.py模块分析
baselines算法库设计可以和多个并行环境进行交互,也就是并行采样,实现多进程并行采样的模块为subproc_vec_env.py,与此相对的只实现单个进程下多环境交互的模块即为本文所要讲的dummy_vec_env.py模块。
我们可以认为dummy_vec_env.py模块是属于对照或调试模块来看。
dummy_vec_env.py模块代码:
import numpy as np
from .vec_env import VecEnv
from .util import copy_obs_dict, dict_to_obs, obs_space_info class DummyVecEnv(VecEnv):
"""
VecEnv that does runs multiple environments sequentially, that is,
the step and reset commands are send to one environment at a time.
Useful when debugging and when num_env == 1 (in the latter case,
avoids communication overhead)
"""
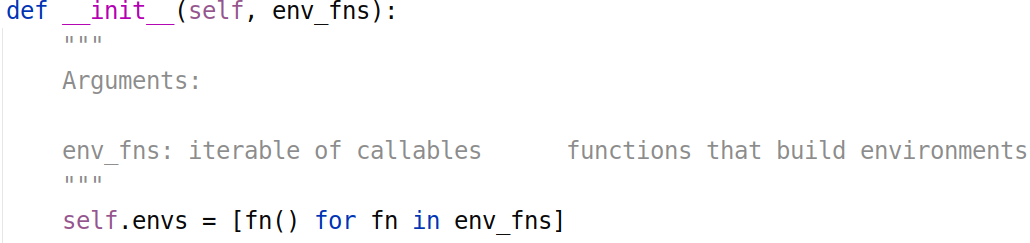
def __init__(self, env_fns):
"""
Arguments: env_fns: iterable of callables functions that build environments
"""
self.envs = [fn() for fn in env_fns]
env = self.envs[0]
VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
obs_space = env.observation_space
self.keys, shapes, dtypes = obs_space_info(obs_space) self.buf_obs = { k: np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k]) for k in self.keys }
self.buf_dones = np.zeros((self.num_envs,), dtype=np.bool)
self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
self.buf_infos = [{} for _ in range(self.num_envs)]
self.actions = None
self.spec = self.envs[0].spec def step_async(self, actions):
listify = True
try:
if len(actions) == self.num_envs:
listify = False
except TypeError:
pass if not listify:
self.actions = actions
else:
assert self.num_envs == 1, "actions {} is either not a list or has a wrong size - cannot match to {} environments".format(actions, self.num_envs)
self.actions = [actions] def step_wait(self):
for e in range(self.num_envs):
action = self.actions[e]
# if isinstance(self.envs[e].action_space, spaces.Discrete):
# action = int(action) obs, self.buf_rews[e], self.buf_dones[e], self.buf_infos[e] = self.envs[e].step(action)
if self.buf_dones[e]:
obs = self.envs[e].reset()
self._save_obs(e, obs)
return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones),
self.buf_infos.copy()) def reset(self):
for e in range(self.num_envs):
obs = self.envs[e].reset()
self._save_obs(e, obs)
return self._obs_from_buf() def _save_obs(self, e, obs):
for k in self.keys:
if k is None:
self.buf_obs[k][e] = obs
else:
self.buf_obs[k][e] = obs[k] def _obs_from_buf(self):
return dict_to_obs(copy_obs_dict(self.buf_obs)) def get_images(self):
return [env.render(mode='rgb_array') for env in self.envs] def render(self, mode='human'):
if self.num_envs == 1:
return self.envs[0].render(mode=mode)
else:
return super().render(mode=mode)
如类注释所说:
class DummyVecEnv(VecEnv):
"""
VecEnv that does runs multiple environments sequentially, that is,
the step and reset commands are send to one environment at a time.
Useful when debugging and when num_env == 1 (in the latter case,
avoids communication overhead)
"""
这个模块,或者说类作用主要就是调试之用。
envs_fns可以看做是可以生成gym环境的函数的一个集合列表,fn则为生成gym环境的函数,fn()函数返回一个gym类型的环境。
调用util.py模块,获得内部env环境的key值集合,以及各个value的shapes和dtypes。

如果env.observation_space不属于gym.spaces.Dict和gym.spaces.Tuple,那么env.observation_space.spaces属于np.array类,env.observation也为np.array类,此时返回的self.keys为[None]。
另外:
env为gym环境,env.observation_space为observation的space类对象,而env的具体的observation的space的存储对象为env.observation_space.spaces。
这里如果env.observation_space属于gym.spaces.Dict类的话,env.observation_space.spaces属于python内部类Dict。
如果env.observation_space属于gym.spaces.Tuple类的话,env.observation_space.spaces属于python内部类Tuple。
如果env.observation_space属于gym.spaces类的话并且不属于gym.spaces.Dict和gym.spaces.Tuple,那么env.observation_space.spaces属于numpy类的np.array。
由
self.buf_obs = { k: np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k]) for k in self.keys }
self.buf_dones = np.zeros((self.num_envs,), dtype=np.bool)
self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
self.buf_infos = [{} for _ in range(self.num_envs)]
由于,observation_space经过obs_space_info函数可以获得作为gym.spaces.Dict类型的key值,这里就把observation转为了Dict类型,其中obs_space_info函数参见util.py模块。
该步操作将不同env的observation、done、reward使用np.array进行拼接,由于observation需要转为Dict类型,因此相同key下的不同环境的observation使用np.array进行拼接。
上面的代码只对拼接变量进行置0初始化。
对于info变量,各个环境的info都是Dict类型,这里的拼接方法是将各个环境的info用列表拼接。
从父类vec_env.py模块中的vec_env类可以知道:

这个环境类的包装类实现真正的环境交互是需要调用step_async和step_wait函数的。
由于dummy_vec_env.py只实现单进程的设计,因此在self.step_async中只是在做输入动作actions的检查工作:
def step_async(self, actions):
listify = True
try:
if len(actions) == self.num_envs:
listify = False
except TypeError:
pass if not listify:
self.actions = actions
else:
assert self.num_envs == 1, "actions {} is either not a list or has a wrong size - cannot match to {} environments".format(actions, self.num_envs)
self.actions = [actions]
返回的actions为列表类型,列表中的每个原始则为要传给的每个env的action。
def step_wait(self):
for e in range(self.num_envs):
action = self.actions[e]
# if isinstance(self.envs[e].action_space, spaces.Discrete):
# action = int(action) obs, self.buf_rews[e], self.buf_dones[e], self.buf_infos[e] = self.envs[e].step(action)
if self.buf_dones[e]:
obs = self.envs[e].reset()
self._save_obs(e, obs)
return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones),
self.buf_infos.copy())
将每个环境的action传给对应的env,将获得的reward,done,info分别存储给对应环境。
需要注意的是和多个环境交互和单个环境的交互在这里是有区别的,传统和单个环境交互不论是否done=True都是直接把observation进行返回的,而是否reset也是交给外部函数来处理的,而这里由于是和多个环境进行交互,也就是说如果一个环境done=True时其他环境可能还没有结束,此时如果交给外部函数处理需要较多操作,因此在这里对单个环境是否done=True进行了单独处理,如果单个环境done=True则直接对其单独进行reset操作。
需要注意的是在多环境的设置下reset操作是对所有环境进行reset,而单独环境如果结束了done=True的话需要单独进行env.reset,与单独环境不同的是单独环境done=True后返回的observation不是当下的而是env.reset后,这种设置是一种十分巧妙的trick,
在强化学习中一个episode结束的时候的observation其实是没有意义的,因为这个observation是不参与任何计算的, 在多个环境交互的情况下单个环境done=True后返回的observation是什么并不重要,并且由于在dummy_vec_env中对单个done=True的环境进行reset后是不像上层反馈的,也就是说上层是不知道单个环境的reset操作的,这样返回reset后的observation方便下一步step计算时的observation确定,可以方便下一个episode开始时的计算。
其中对于obs变量进行了两步操作,即,
self._save_obs(e, obs)
self._obs_from_buf()
def _save_obs(self, e, obs):
for k in self.keys:
if k is None:
self.buf_obs[k][e] = obs
else:
self.buf_obs[k][e] = obs[k] def _obs_from_buf(self):
return dict_to_obs(copy_obs_dict(self.buf_obs))
其中,_save_obs将obs按照环境索引号存储在buf_obs中,如果key为None说明obs为np.array类型否则为Dict类型,如果obs为Dict类型则按照key值进行对应存储。

copy_obs_dict对转为Dict类型的observation进行copy。

对copy后的Dict类型的observation进行处理,如果observation的key只有一个为None,那么直接返回value,否则直接将observation进行返回。
dummy_vec_env.py中对绘图函数的设计:

get_images函数调用gym的env下的render函数,使用'rgb_array'模式,得到每个环境env的图片的np.array数据。
在dummy_vec_env.py的render函数中,如果只有一个环境env则直接调用gym的env的rendr函数,如果env个数不为1则调用父类vec_env的render函数。
vec_env.py中render函数:
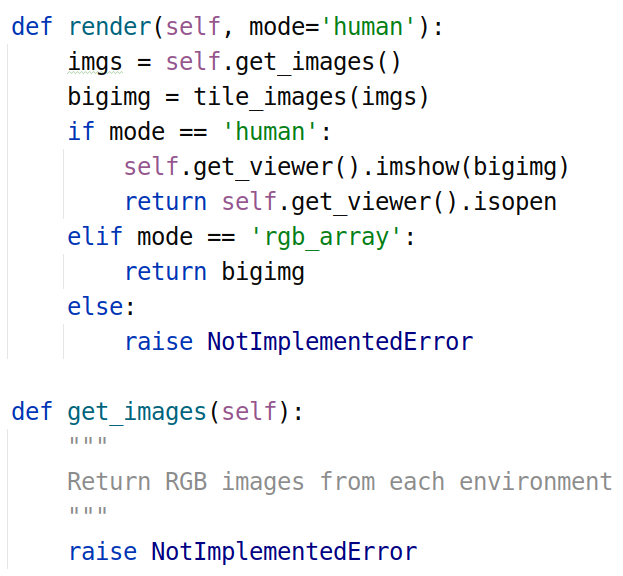
可以看到父类的render函数调用get_images函数,而父类的get_images函数没有实现因此调用的是自身类的get_images,也就是获得所有环境的'rgb_array'模式下的图片集合列表,然后使用tile_images函数将所有环境的图片进行拼接形成一个大的图片,如果上层函数调用render使用的是'rgb_array'模式则直接将拼接后图片的np.array数据返回,要是'human'模式则将调用gym的render绘图函数进行绘制。
================================================
需要注意的是dummy_vec_env.py模块虽然也实现了与多个环境的同时交互,但是并没有使用多进程并发的方式而是使用了单进程并行的方式,或者说只是一种伪并行的方式。
================================================
baselines算法库common/vec_env/dummy_vec_env.py模块分析的更多相关文章
- 图像滤镜艺术---ZPhotoEngine超级算法库
原文:图像滤镜艺术---ZPhotoEngine超级算法库 一直以来,都有个想法,想要做一个属于自己的图像算法库,这个想法,在经过了几个月的努力之后,终于诞生了,这就是ZPhotoEngine算法库. ...
- scikit-learn 支持向量机算法库使用小结
之前通过一个系列对支持向量机(以下简称SVM)算法的原理做了一个总结,本文从实践的角度对scikit-learn SVM算法库的使用做一个小结.scikit-learn SVM算法库封装了libsvm ...
- 【Python】【Web.py】详细解读Python的web.py框架下的application.py模块
详细解读Python的web.py框架下的application.py模块 这篇文章主要介绍了Python的web.py框架下的application.py模块,作者深入分析了web.py的源码, ...
- 第三百零六节,Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- 使用织梦开源的分词算法库编写的YII获取分词扩展
在编辑文章中,很多时候都需要自动根据文章内容获取关键字的功能,因此,本文主要是说明如何在yii中使用织梦开源的分词算法编写一个独立的扩展,可以在不同的模块中使用,步骤如下: 1 到这里下载其他朋友整理 ...
- 四 Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- mahout算法库(四)
mahout算法库 分为三大块 1.聚类算法 2.协同过滤算法(一般用于推荐) 协同过滤算法也可以称为推荐算法!!! 3.分类算法 算法类 算法名 中文名 分类算法 Log ...
- 操作MySQL-数据库的安装及Pycharm模块的导入
操作MySQL-数据库的安装及Pycharm模块的导入 1.基于pyCharm开发环境,在CMD控制台输入依次输入以下步骤: (1)pip3 install PyMySQL < 安装 PyMy ...
- 痞子衡嵌入式:对比MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异. 近期有 i.MXRT 客户在集成 OTA SBL ...
- snowland-smx密码算法库
snowland-smx密码算法库 一.snowland-smx密码算法库的介绍 snowland-smx是python实现的国密套件,对标python实现的gmssl,包含国密SM2,SM3,SM4 ...
随机推荐
- Kafka多维度调优
优化金字塔 应用程序层面 框架层面(Broker层面) JVM层面 操作系统层面 应用程序层面:应当优化业务代码合理使用kafka,合理规划主题,合理规划分区,合理设计数据结构: 框架层面:在不改动源 ...
- window10 yapi安装 swagger配置 及 Error: getaddrinfo ENOTFOUND yapi.demo.qunar.com解决
node下载https://nodejs.org/download/release/v12.18.3/mongodb下载https://www.mongodb.com/try/download/ent ...
- Asp.net Core Flurl.Http 结合IHttpClientFactory管理HttpClient生命周期
Asp.net Core, 在我用过的多种Http REST 客户端: RestSharp WebApiClient Refit Flurl 中,Flurl可以说是最符合我口味的,用起来那可真的顺滑无 ...
- ecnuoj 5039 摇钱树
5039. 摇钱树 题目链接:5039. 摇钱树 感觉在赛中的时候,完全没有考虑分数规划这种做法.同时也没有想到怎么拆这两个交和并的式子.有点难受-- 当出现分数使其尽量大或者小,并且如果修改其中直接 ...
- mysql子查询不支持limit问题解决
如果sql语句中的子查询包含limit 例如: select * from table where id in (select id from table limit 3) 会报错: This ver ...
- MFC基于对话框工程笔记->新建MFC对话框
一.前言 最近用MFC做了一个对话框小工具,学到了很多知识,现在做一下总结,以作备忘.(如有不足,后期添加修改) 二.MFC使用->新建MFC对话框 操作环境:VS2010 主要使用语言:C.C ...
- Linux安装Redis教程
举例版本 Redis版本 5.0.4 服务器版本 Linux CentOS 7.6 64位 下载Redis 进入官网找到下载地址 https://redis.io/download 右键Downloa ...
- koa web框架入门
1.在hello-koa这个目录下创建一个package.json,这个文件描述了我们的hello-koa工程会用到哪些包.完整的文件内容如下: { "name": "h ...
- SpringBoot排查自动装配、Bean、Component、Configuration配置类
排除自动装配AutoConfiguration @SpringBootApplication( exclude = { DataSourceAutoConfiguration.class, Mybat ...
- Oracle 日期减年数、两日期相减
-- 日期减年数 SELECT add_months(DEF_DATE,12*USEFUL_LIFE) FROM S_USER --两日期相减 SELECT round(sysdate-PEI.STA ...