[转帖]linux系统上free命令看到的buff/cache到底是什么
https://zhuanlan.zhihu.com/p/645904515
上周二一大早,小智准备早点去公司肝一篇技术文分享给大家的,哪成想,一到公司就被测试部的“卷王”拉去看问题,哎,也是够够的了。问题是这样的,这个测试同事看到我们产品的页面上,显示的内存占用率很高,已经超过80%告警了,就用free命令在后台查了一下,发现buffer/cache占用很高,她就怀疑是我们的程序有问题。
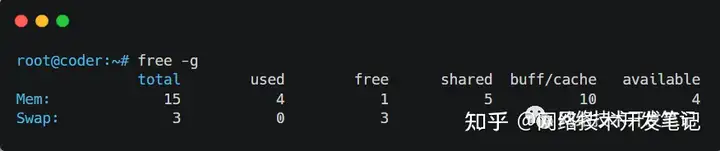
我一看,确实,buff/cache一栏显示占去了内存的大部分,当时也没心思去细查,就甩了下面几个命令给她清理完事了:

不过后来想一想,这种态度,不是咱技术人的风格,不搞清楚,心里还是虚得慌啊,于是利用周末时间,把这里面的细节,好好的给扒拉了一下。
1、buff/cache是什么
buff/cache是free命令查看到的,我们来追根溯源一下。free命令出自 procps util 包,源码可以在https://gitlab.com/procps-ng/procps/-/tree/master看到,我们可以去查看它的源码,当然比较快的方式,还是通过man free看一下它的说明:
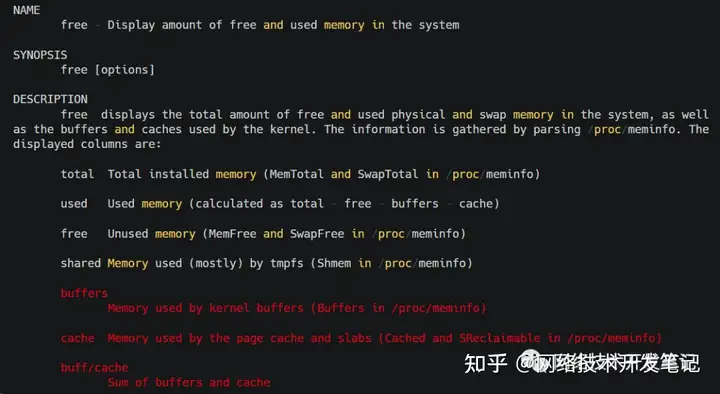
从 free 的手册中,可以看到 buff/cache的说明:
- buff/cache是buffers和cache之和
- buffers是内核缓冲区用到的内存,对应的是/proc/meminfo 中的 Buffers 值
- cache是内核页缓存和Slab用到的内存,对应的是/proc/meminfo中的Cached与SReclaimable之和
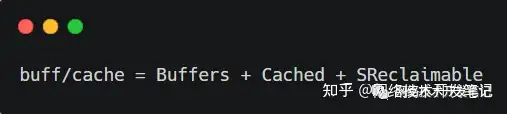
所以我们可以得出下面的计算公式:
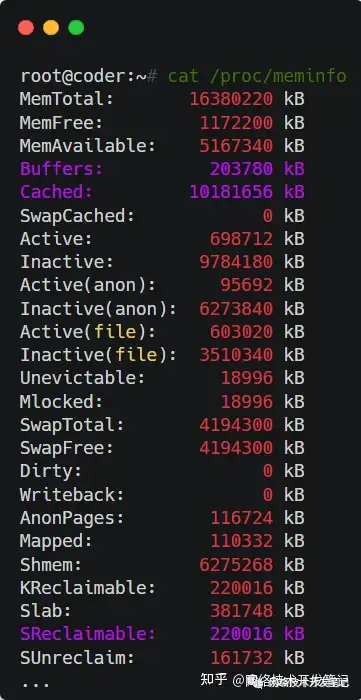
那么,问题又来了,/proc/meminfo看到的Buffers、Cached和SReclaimable,又是什么呢?不着急,咱们继续,嘿嘿。
在linux中,一切皆文件。/proc是Linux内核提供的一种特殊文件系统,是用户跟内核交互的接口。比方说,用户可以从 /proc 中查询内核的运行状态和配置选项,查询进程的运行状态、统计数据等,当然,我们也可以通过 /proc 来修改内核的配置。
执行man proc,我们看一下对Buffers、Cached、SReclaimable三项的描述:
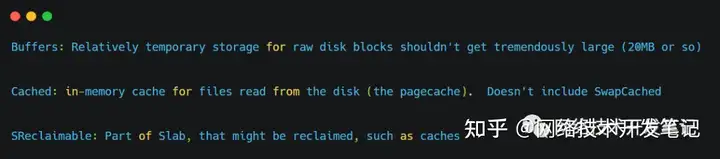
翻译一下上面的描述:
- Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,一般不会特别大(20MB 左右)
- Cached 是从磁盘读取文件的内存页缓存(pagecache),但是不包括SwapCached,也就是用来缓存从文件读取的数据
- SReclaimable 是 Slab 的一部分,是可以被回收的,例如缓存
上面的描述太多简单,小智通过查阅相关资料,在这里再深入说明一下:
- Buffers 既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
- Cached 既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
- Buffer 是对磁盘数据的缓存,而 Cached 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
- linux内核使用 Slab 机制,管理文件系统的目录项和索引节点的缓存。Slab 包括两部分,其中的可回收部分,是指可以被回收的内核内存,包括目录项(dentry) 和索引节点( inode )的缓存等,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
以我们常规的读写文件为例,通过下面这两张图,我们可以看到Cache在读写文件中作用。
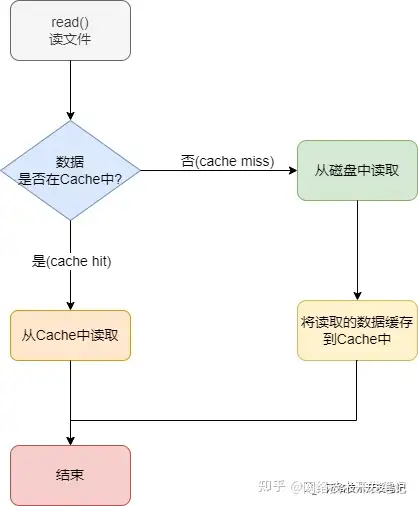
读文件时,先看要读取的数据是否在Cache中,如果在,则直接可以从内存中读取;如果不在,则从磁盘中读取数据缓存到Cache中。

写文件时,先把文件写到cache中,标记cache为脏页(dirty),再由内核将cache中的脏页刷新到磁盘上。所谓脏页就是cache中的数据还没有同步到磁盘上,如果cache中的数据已经同步到磁盘上,我们就叫它干净页。
为什么linux系统设计如此复杂的流程去支持Buffers和Cached,还是因为内存和磁盘读取速度的不匹配导致的。
内存价格贵,容量小,读取数据速度快,断电后数据丢失;而磁盘价格便宜,容量大,读取数据慢,断电后数据依然可以保存。
计算机在启动工作时,会一直存在把数据在内存和磁盘之间搬运的过程,而这个过程中,显然从磁盘读取数据会大大影响计算机CPU的工作效率,所以只能在内存中开辟缓存空间,提前把要用到的一些数据放到内存中,以此来提高计算机的工作效率。
其实,CPU的寄存器和三级Cache跟这个类似,也是因为寄存器和Cache与内存之间的读取速度不匹配造成的。
2、Buffer和Cache的区别和联系
free 命令中的 buff/cache 是由 Buffers、Cached 和 SReclaimable 这三项组成的,free命令是一个工具,是逻辑上人为去统计三个值的和,它强调的是内存的可回收性,也就是说,可以被回收的内存会统计在这一项。
通过下面这张图,我们可以看到 Buffers、Cached 和 SReclaimable在linux内核中的位置:
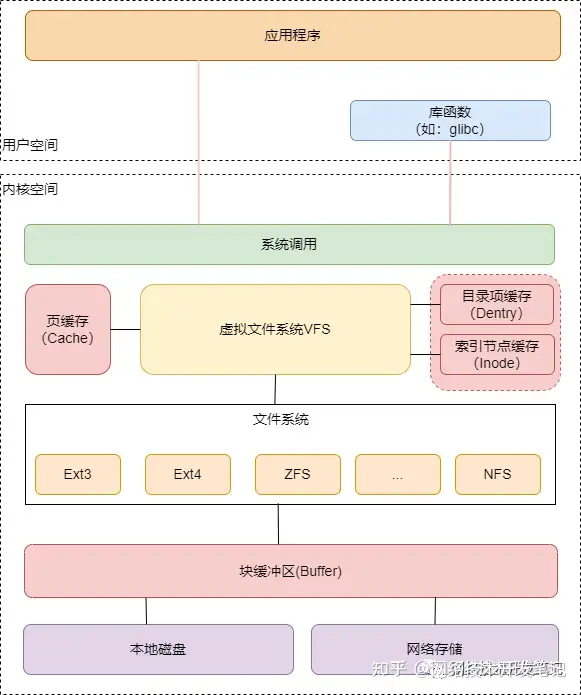
我们可以看到,Cached 是与文件系统同级的;块是物理上的概念,因此 Buffers 是与块设备驱动程序同级的。
在读写普通文件时,会经过文件系统,由文件系统负责与磁盘交互;而读写磁盘或者分区时,就会跳过文件系统,也就是所谓的“裸I/O“。这两种读写方式所使用的缓存是不同的,也就是文中所讲的 Cached 和 Buffers 区别。
一个文件放在磁盘上,读首先会缓存到Buffers, 然后到Cached。有了文件系统才有了Cached,在 Linux 2.4 版本的内核之前,Cached 与 buffers 是完全分离的。那这样对于文件数据,会被缓存两次。这种方案虽然简单,但是低效,浪费内存空间。
后期,Linux把这两块缓存统一了。如果一个文件的页加载到了 Cached,那么同时Buffers 只需要维护块指向页的指针就可以了。只有那些没有文件表示的块,或者绕过了文件系统直接操作(如dd命令)的块,才会真正放到 Buffers 里。
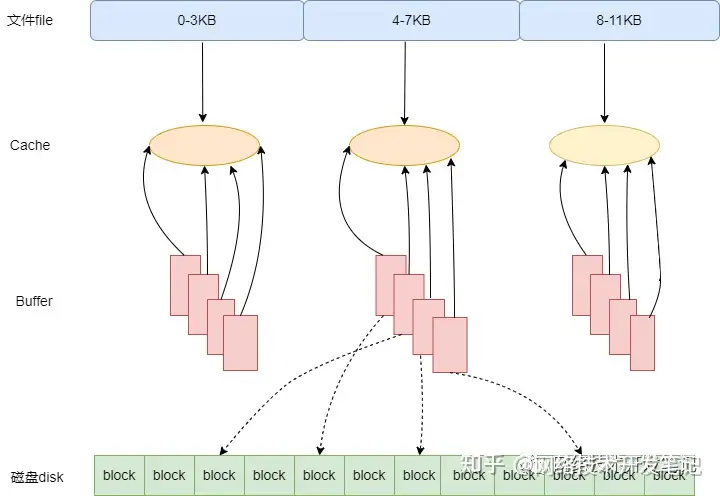
下图近似地示出 32位 Linux 系统中可能的一种 Buffers/Cached结构,其中 block size 大小为 1KB,page size 大小为 4KB。
3、SReclaimable是什么
在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。
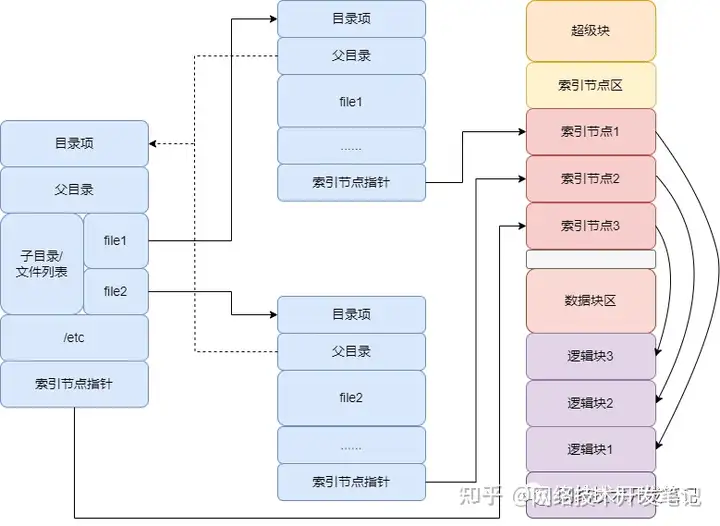
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以,它们的索引节点相同。
目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的 Buffers 和 Cached 原理中,我们提到过,为了协调慢速磁盘与快速内存和 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中。其实,这些索引节点也会缓存到内存中,加速文件的访问。
可以通过下面这张图,理解一下目录项、索引节点以及文件数据的关系:
4、Buffer和Cache带来的影响
通过上面的内容,我们已经知道了buff/cache的含义以及运行机制。使用Buffer和Cache的好处是显而易见的:
- 从读的角度来说,如果要获取的数据在buffer/cache中,就可以直接从内存中获取,由于内存访问比磁盘访问快很多,可以大大加快数据的访问效率
- 从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作
- buffer/cache在缓存时,会进行缓存预取,利用局部性原理,可以通过一次 I/O 将多个 page 页装入 buffer/Cache ,减少磁盘 I/O 次数, 进而提高系统磁盘 I/O 吞吐量
但是使用buffer/cache也会存在一些问题:
- 需要占用额外物理内存空间,物理内存在比较紧俏的时候可能会导致频繁的 swap 操作,最终导致系统的磁盘 I/O 负载的上升
- 对应用层并没有提供很好的管理 API,几乎是透明管理。应用层即使想优化 Page Cache 的使用策略也很难进行。因此一些应用选择在用户空间实现自己的 page 管理,而不使用 page cache,例如 MySQL InnoDB 存储引擎以 16KB 的页进行管理
- 在某些应用场景下会比 Direct I/O 多一次磁盘读 I/O 以及磁盘写 I/O
5、Buffer/Cache是怎样回收的
Buffers/Cache占用的是系统的内存空间,如果一直在长时间读写文件并进行缓存,cache肯定会占用大量的内存的,那么,系统是怎样进行Buffer和Cache的回收的呢?
Linux 内核会在内存将要耗尽的时候,会触发内存回收的工作,以便释放出内存给急需内存的进程使用。
一般情况下,这个操作中主要的内存释放都来自于对 buffer/cache 的释放。尤其是被使用更多的 cache 空间。
既然它主要用来做缓存,只是在内存够用的时候加快进程对文件的读写速度,那么在内存压力较大的情况下,当然有必要清空释放 cache,作为 free 空间分给相关进程使用。
在系统中除了内存将被耗尽的时候可以清缓存以外,我们还可以使用/proc/sys/vm/drop_caches这个文件来人工触发缓存清除的操作。
linux系统的内存回收流程如下图:
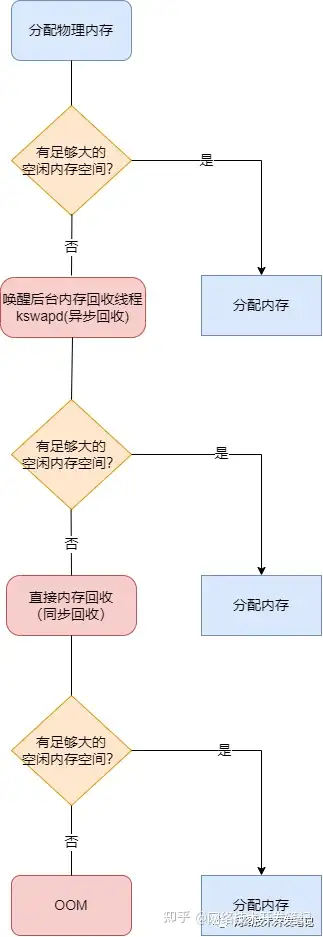
可以看到,这个过程中,主要是先触发内核线程进行后台异步回收,如果还不够,就会在申请内存的过程中,直接进行回收,如果还是不够,就只能使用最后的杀手锏,触发OOM(Out of Memory)机制,直接杀掉占用大量内存的进程。
上面可被回收的内存类型,可以分为两类:
- cache缓存页的回收:对于干净页,是直接释放内存,这个操作不会影响性能,而对于脏页(还没有同步数据到磁盘)会先写回到磁盘,再释放内存,这个操作会发生磁盘 I/O 的,是会影响系统性能的。
- 匿名页的回收:匿名页通常通过系统调用(如mmap()或sbrk())或C库函数(如malloc())进行动态分配,因为这部分内存可能还会使用到,因此不能直接释放。如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个过程会发生IO操作,也是会影响系统性能的。
6、Buffer/Cache在编程中的说明
虽然,linux提供了Buffers和Cache这种读写文件或者磁盘块的缓存,但是对于程序员写代码来说,其实我们是可以控制的。这里就涉及到几个IO操作的概念:
- Raw IO: 裸 I/O,不经过文件系统,直接写磁盘
- Direct IO: 直接 I/O,读写文件不经过Cache,也就是跳过前面的Cache机制
- Bufferd IO: 也叫非直接 I/O,读写文件经过Cache,也就是正常使用Cache机制
需要注意的是,Direct IO和Bufferd IO本质上还是和文件系统交互。如果是在数据库等场景中,我们会看到跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
对于只读写一遍,后续再不会用到的文件,可以使用Direct IO,特别是对于超大文件,读入到内存Cache,也会影响其他进程对内存的使用。
还有的应用程序会维护自己的 Cache ,做更加细粒度的控制,比如 MySQL 就是这样做的,可以参考MySQL Buffer Pool。
在编程中,使用open函数,可以指定是使用Direct IO 或者 Bufferd IO,想要实现Direct IO,需要你在open函数中,指定 O_DIRECT 标志。如果没有设置过,默认的是 Bufferd IO。
另外,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。
7、Buffer和Cache占用高怎么办
Linux服务器运行一段时间后,由于其内存管理机制,会将暂时不用的内存转为buff/cache,这样在程序使用到这一部分数据时,能够很快的取出,从而提高系统的运行效率。
所以这也正是linux内存管理中非常出色的一点,但是我们会看到buff/cache越来越大,乍一看,内存剩余的非常少,但是在程序真正需要内存空间时,linux会将缓存让出给程序使用,这样达到对内存的最充分利用,所以真正剩余的内存是free+buff/cache。
但是有些时候,大量的缓存占据空间,这时候应用程序会去使用swap交换空间,从而使系统变慢,这时候需要手动去释放内存。
说到清理内存,那么不得不提到/proc这一个虚拟文件系统,这里面的数据和文件都是内存中的实时数据,很多参数的获取都可以从下面相应的文件中得到,比如查看某一进程占用的内存大小和各项参数,cpu和主板的详细信息,显卡的参数等等;
相应的关于内存的管理方式是在/proc/sys/vm/drop_chches文件中,一定要注意这个文件中,存放的并不是具体的内存内容,而是0-3这几个数字,通过文件大小只有1B也可以知道,而这些代号分别告诉系统代表不同的含义如下:
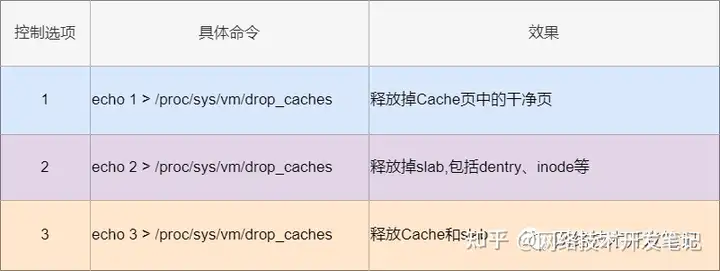
drop Cache不会清理脏页,只会清理干净的页,所以如果你想清理所有的页的话,是需要在drop前先sync的,执行sync会将脏页同步到磁盘,从而都变为干净页被drop Cache操作给释放。
这里需要说明的是,Linux系统内存中的Cache并不是在所有情况下,都能被释放当做空闲空间用的。并且,即使可以释放Cache,也并不是对系统来说没有成本的。总结一下要点,我们应该记得这样几点:
- 当cache作为文件缓存被释放的时候,会引发IO变高,这是cache加快文件访问速度所要付出的成本。
- 临时文件系统tmpfs中存储的文件会占用cache空间,除非文件删除,否则这个cache不会被自动释放。
- 使用shmget方式申请的共享内存会占用cache空间,除非共享内存被ipcrm,或者使用shmctl去IPC_RMID,否则相关的cache空间都不会被自动释放。
- 使用mmap方法申请的MAP_SHARED标志的内存,会占用cache空间,除非进程将这段内存munmap,否则相关的cache空间都不会被自动释放。
- 实际上shmget、mmap的共享内存,在内核层都是通过tmpfs实现的,tmpfs实现的存储用的都是cache。
8、总结
一个free命令看到的buff/cache,竟然扯出了这么多的内容,信息量有点多,看起来可能有点头大。不过学习的过程就是这样,每个知识点都是互相关联的,看一个点,可能会涉及到多个点的内容,然后还可能是一堆专业名词。不过不要紧,我们可以由点及面,先抓住这篇文章的主要内容:
- buff/cache表示的是文件缓存cache、块缓存buffer以及文件系统目录项和索引节点的缓存SReclaimable之和,强调的是可以被系统回收的内容
- 读写文件时,会把文件内容缓存到内存cache中,提高读写效率
- 读写磁盘时,会把内容缓存到内存buffer中,提高读写效率
- 当内存不够时,buff和cache是可以被系统回收的,当然我们也可以使用drop cache的命令手动回收,不过可能会导致脏页同步到磁盘带来的磁盘IO变高
至于其它的细节点,咱们现在能看懂多少是多少,先有个印象就行,后面文章肯定会再提到的,就是这样在这个反复的过程中,我们会加深印象,然后就会慢慢理解的。
怎么样,看了上面的分析,小伙伴们有没有什么想法?是不是没想到,就是这样一个简单的命令,很小很小的一个细节,竟然暗藏有这么深的玄机。小伙伴们对这种类型的文章感不感兴趣呢?要不要小智再给大家多扒一扒?要的话,大家点个分享、在看和点赞,我就知道了,哈哈~~
[转帖]linux系统上free命令看到的buff/cache到底是什么的更多相关文章
- Linux系统上的命令使用方法
许多windows非常熟悉ipconfig命令行工具,它被用来获取网络接口配置信息并对此进行修改.Linux系统拥有一个类似的工具,也就是ifconfig(interfaces config).通常需 ...
- 在Linux系统上获取命令帮助信息和划分man文档
使用历史命令history 打完以后前面会有顺序号的比如1 cd2 ls3 pwd如果需要重新执行cd命令则可以执行 !3 命令 命令补全功能 比如你要执行history命令 可以打上histo+键 ...
- linux系统上传下载命令rz和sz的教程
(一)安装方法汇总(注意:一下命令如果没有权限的需要在每个命令前面加一个sudo) 1.安装方法(推荐) sudo yum install lrzsz 2.在安装Linux系统时选中“DialupNe ...
- VM下的linux系统上不了网?? 使用putty远程登录不上linux的解决方法?
背景:昨晚想尝试一下用putty远程登录我的linux系统,悲剧的是,我竟然连接不上,显示 connection refused ,连接被拒绝.于是我就想看看能不能在linux下看看能不能访问百度 ...
- Linux系统上使用php获取apk信息
最近在做一个apk商城,需要在用户上传了apk之后系统自动读取apk信息(包名,版本号等),后台语言使用的是php,需要php去调用系统的aapt命令去读取apk信息,在Linux系统上安装aapt的 ...
- [r]Ubuntu Linux系统下apt-get命令详解
Ubuntu Linux系统下apt-get命令详解(via|via) 常用的APT命令参数: apt-cache search package 搜索包 apt-cache show package ...
- 在VMware的Linux系统上安装Redis
在VMware的Linux系统上安装Redis 具体过程如下: 下载,解压和编译: 在执行make的时候报错,具体报错信息如下: zmalloc.o: In function `zmalloc_use ...
- Linux系统采用netstat命令查看DDOS攻击的方法
Linux系统采用netstat命令查看DDOS攻击的方法 来源:互联网 作者:佚名 时间:07-05 15:10:21 [大 中 小] 这篇文章主要为大家介绍了Linux系统采用netstat命令查 ...
- Redis进阶实践之二如何在Linux系统上安装安装Redis
一.引言 上一篇文章写了"如何安装VMware Pro虚拟机"和在虚拟机上安装Linux操作系统.那是第一步,有了Linux操作系统,我们才可以在该系统上安装Redis. ...
- Redis进阶实践之六Redis Desktop Manager连接Windows和Linux系统上的Redis服务
一.引言 今天本来没有打算写这篇文章,当初我感觉使用这个工具应该很简单,下载的过程也不复杂,也没有打算记录下来.但是在使用的过程中还是出现了一些问题,为了给第一次使用Redis Desktop Man ...
随机推荐
- aspnetcore使用websocket实时更新商品信息
先演示一下效果,再展示代码逻辑. 中间几次调用过程省略... 暂时只用到了下面四个项目 1.产品展示页面中第一次通过接口去获取数据库的列表数据 /// <summary> /// 获取指定 ...
- 创建傀儡进程svchost.exe并注入DLL文件(Shellcode)
本文主要利用 SetThreadContext 修改进程中的线程上下文来实现Dll注入(ShellCode). 实现原理 首先,使用 CreateProcess 函数创建svchost.exe进程,并 ...
- 2023-06-01:讲一讲Redis常见数据结构以及使用场景。
2023-06-01:讲一讲Redis常见数据结构以及使用场景. 答案2023-06-01: 字符串(String) 适合场景 缓存功能 Redis 作为缓存层,MySQL 作为存储层,在大部分请求中 ...
- CodeForces 1141F2 贪心 离散化
CodeForces 1141F2 贪心 离散化 题意 给定一个序列,要求我们找出最多数量的不相交区间,每个区间和都相等. 思路 一开始没有头绪,不过看到 \(n \le 1500\) 后想到可以把所 ...
- 华为云PB级数据库GaussDB(for Redis)介绍第四期:高斯 Geo的介绍与应用
摘要:高斯Redis的大规模地理位置信息存储的解决方案. 1.背景 LBS(Location Based Service,基于位置的服务)有非常广泛的应用场景,最常见的应用就是POI(Point of ...
- 什么是 A/B 实验,为什么要开 A/B 实验?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 1.什么是 A/B 实验 A/B 实验也被称为 A/B 测试,实验的基本思路是在线上流量中取出一小部分(较低风险) ...
- Axure 自定义元件库
点击文件 -> 新建元件库 可以添加多个元件,并将期重命名 保存元件库 新建页面 添加元件,选择自建的元件库 导入后就会发现我的原件库 这样就可以使用我们自定义的元件库了
- matplotlib 图表生成
条形颜色演示 import matplotlib.pyplot as plt ''' 将plt.subplots()函数的返回值赋值给fig和ax俩个变量 plt.subplots()是一个函数,返回 ...
- 愉快的了解Charles
charles是PC端常用的网络封包截取工具,在做移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析.除了在做移动开发中调式端口外,charles也可以用于分析第三方应用的通 ...
- ADB移动端及Monkey常用命令
ADB ADB全程Android Debug Bridge,是android sdk里的一个工具,用这个工具可以直接操作管理android模拟器或者真实的android设备 它的主要功能: 运行设备的 ...