hackerrank Similar Pair
Problem Statement
You are given a tree where each node is labeled from 1 to n. How many similar pairs(S) are there in this tree?
A pair (A,B) is a similar pair if the following are true:
- node A is the ancestor of node B
- abs(A−B)≤T
Input format:
The first line of the input contains two integers, n and T. This is followed by n−1 lines, each containing two integers si and ei where node si is a parent to node ei.
Output format:
Output a single integer which denotes the number of similar pairs in the tree.
Constraints:
1≤n≤100000
0≤T≤n
1≤si, ei ≤n
Sample Input:
5 2
3 2
3 1
1 4
1 5
Sample Output:
4
Explanation:
The similar pairs are: (3, 2) (3, 1) (3, 4) (3, 5).
You can have a look at the tree image here
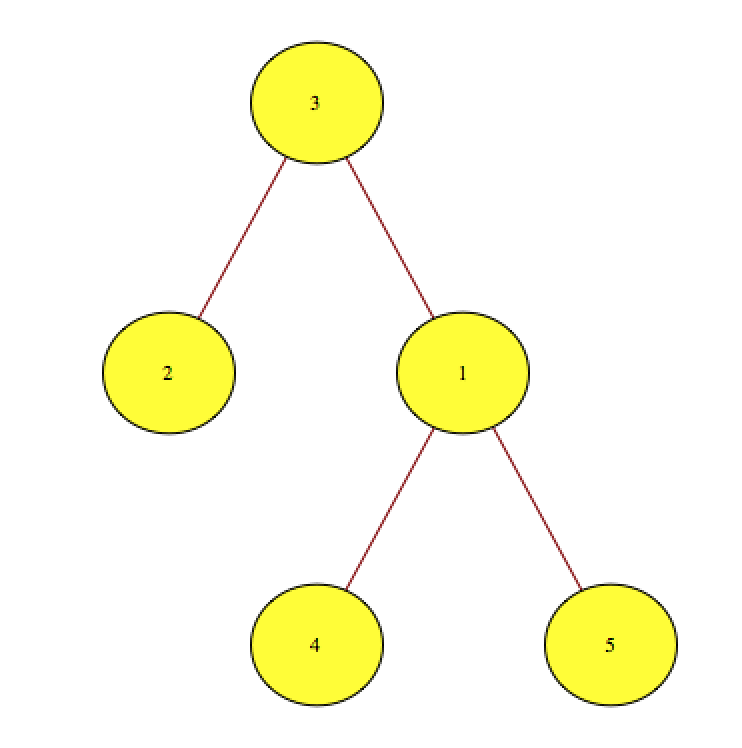{kind=link}
#include <bits/stdc++.h>
using namespace std;
int T, n;
const int N(1e5+);
int bit[N];
int sum(int x){
int s=;
while(x){
s+=bit[x];
x-=x&-x;
}
return s; //error-prone
}
void add(int x){
while(x<=n){
bit[x]++;
x+=x&-x;
}
}
int get_ans(int x){
int l=max(x-T-, );
int r=min(n, x+T);
return sum(r)-sum(l);
}
int par[N];
vector<int> g[N];
long long ans;
void dfs(int u){
int tmp=get_ans(u);
for(int i=; i<g[u].size(); i++){
int &v=g[u][i];
dfs(v);
}
ans+=get_ans(u)-tmp;
add(u);
}
int main(){
//freopen("in", "r", stdin);
cin>>n>>T;
for(int i=, u, v; i<n; i++){
cin>>u>>v;
par[v]=u;
g[u].push_back(v);
}
int root=;
while(par[root])
root=par[root];
dfs(root);
cout<<ans<<endl;
}
--------------------------------------------
我们在考虑能否用C++ STL中的 set实现这个集合
显然我们需要支持3种操作
1. 插入,set OK
2.查询集合中大于x的数有多少个
3.查询集合中小于x的数有多少个
下面的资料摘自C++ Primer (5th. edition)
P. 330
Table 9.2 Contianer Operations
Type Aliases
difference_type Signed integral type big enough to hold the distance between two iterators
set<int> s;
int f(int l, int r){
return s.upper_bound(r)-s.lower_bound(l);
}
但这是行不通的,编译时报错:
:no match for ‘operator-’ (operand types are ‘std::set<int>: :iterator {aka std::_Rb_tree_const_iterator<int>}’ and ‘std::set<int>::iterator {aka std::_Rb_tree_const_iterator<int>}’)
因为set<int>::iterator不支持-(减法)
------------------------------------------------
只能写成
set<int> s;
int f(int l, int r){
auto b=s.lower_bound(l), e=s.upper_bound(r);
int res=;
while(b!=e){ //use != rather than <
++b;
++res;
}
return res;
}
但这样写复杂度是O(n),不能承受。
Bjarne Stroustrup TC++PL (4th. edition) P.954
The reason to use != rather than < for testing whether we have reached the end is partially because that is
the more precise statement of what we testing for and partially because only random-access iterators support <.
----------------------------------------------------------
hackerrank Similar Pair的更多相关文章
- R语言-混合型数据聚类
利用聚类分析,我们可以很容易地看清数据集中样本的分布情况.以往介绍聚类分析的文章中通常只介绍如何处理连续型变量,这些文字并没有过多地介绍如何处理混合型数据(如同时包含连续型变量.名义型变量和顺序型变量 ...
- 【LeetCode】734. Sentence Similarity 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 只修改区间起终点 日期 题目地址:https://le ...
- RFID Exploration and Spoofer a bipolar transistor, a pair of FETs, and a rectifying full-bridge followed by a loading FET
RFID Exploration Louis Yi, Mary Ruthven, Kevin O'Toole, & Jay Patterson What did you do? We made ...
- *[hackerrank]Algorithmic Crush
https://www.hackerrank.com/contests/w4/challenges/crush 第一眼觉得要用线段树,但据说会超时.其实这个可以通过生成pair排序来做. #inclu ...
- 【HackerRank】How Many Substrings?
https://www.hackerrank.com/challenges/how-many-substrings/problem 题解 似乎是被毒瘤澜澜放弃做T3的一道题(因为ASDFZ有很多人做过 ...
- [Functional Programming] mapReduce over Async operations and fanout results in Pair(rejected, resolved) (fanout, flip, mapReduce)
This post is similar to previous post. The difference is in this post, we are going to see how to ha ...
- Code Signal_练习题_Are Similar?
Two arrays are called similar if one can be obtained from another by swapping at most one pair of el ...
- MOSFET pair makes simple SPDT switch
With an n- and p-channel MOSFET, you can easily implement a single-pole double-throw (SPDT) switch t ...
- 2017-5-14 湘潭市赛 Similar Subsequence 分析+四维dp+一些简单优化
Similar Subsequence Accepted : Submit : Time Limit : MS Memory Limit : KB Similar Subsequence For gi ...
随机推荐
- 常用API——字符串String型函数
上图: 声明 var myString = new String(“Every good boy does fine.”); var myString = “Every good boy does f ...
- js中A包含B的写法与分割字符串的方法
在java中A包含B的写法 if(A.contains(B)){ ... } 在js中没有contains方法,应该使用下面这种方法: var an = "传染性.潜伏性.破坏性" ...
- CLR via C# 读书笔记---常量、字段、方法和参数
常量 常量是值从不变化的符号.定义常量符号时,它的值必须能在编译时确定.确定后,编译器将唱两只保存在程序集元数据中.使用const关键字声明常量.由于常量值从不变化,所以常量总是被视为类型定义的一部分 ...
- 从零自学Hadoop(03):Linux准备上
阅读目录 序 检查列表 常用Linux命令 搭建环境 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sou ...
- Linux 下编译升级 Python
一.Centos下升级python3.4.3 1.下载安装 wget http://www.python.org/ftp/python/3.4.3/Python-3.4.3.tgz wget http ...
- MySQL的loose index scan
众所周知,InnoDB采用IOT(index organization table)即所谓的索引组织表,而叶子节点也就存放了所有的数据,这就意味着,数据总是按照某种顺序存储的.所以问题来了,如果是这样 ...
- openstack-swift云存储部署(一)
最近因为工作的需要搭建了一套swift云存储架构 我们先来解读一下里面的技术知识点:swift服务是属于openstack中的一种组件服务,openstack中的组件服务还有keystone.Nova ...
- Eclipse Kelper 设置代理服务器无效解决方案
Open Network Connection Settings. Select Active Provider to "Manual". Set HTTP/HTTPS proxy ...
- [很郁闷]python2.7连接mysql5.5配置
前言:今天在公司电脑上python版本跟自己家里电脑上的一样,不一样的是mysql公司版本5.6,结果花了两天的时间都没配置好python和mysql 简单说就是python连接mysql一直报200 ...
- UrlEncode 和 HtmlEncode
UrlEncode 是将指定的字符串按URL编码规则,包括转义字符进行编码.