玩转内核链表list_head,3个超级哇塞的的例子
在Linux内核中,提供了一个用来创建双向循环链表的结构 list_head。虽然linux内核是用C语言写的,但是list_head的引入,使得内核数据结构也可以拥有面向对象的特性,通过使用操作list_head 的通用接口很容易实现代码的重用,有点类似于C++的继承机制(希望有机会写篇文章研究一下C语言的面向对象机制)。
首先找到list_head结构体定义,kernel/inclue/linux/types.h 如下:
1 struct list_head {
2 struct list_head *next, *prev;
3 };
4 #define LIST_HEAD_INIT(name) { &(name), &(name) }
需要注意的一点是,头结点head是不使用的,这点需要注意。
使用list_head组织的链表的结构如下图所示:
然后就开始围绕这个结构开始构建链表,然后插入、删除节点 ,遍历整个链表等等,其实内核已经提供好了现成的接口,接下来就让我们进入 kernel/include/linux/list.h中:
一. 创建链表
内核提供了下面的这些接口来初始化链表:
1 #define LIST_HEAD_INIT(name) { &(name), &(name) }
2
3 #define LIST_HEAD(name) \
4 struct list_head name = LIST_HEAD_INIT(name)
5
6 static inline void INIT_LIST_HEAD(struct list_head *list)
7 {
8 WRITE_ONCE(list->next, list);
9 list->prev = list;
10 }
如: 可以通过 LIST_HEAD(mylist) 进行初始化一个链表,mylist的prev 和 next 指针都是指向自己。
1 structlist_head mylist = {&mylist, &mylist} ;
但是如果只是利用mylist这样的结构体实现链表就没有什么实际意义了,因为正常的链表都是为了遍历结构体中的其它有意义的字段而创建的,而我们mylist中只有 prev和next指针,却没有实际有意义的字段数据,所以毫无意义。
综上,我们可以创建一个宿主结构,然后在此结构中再嵌套mylist字段,宿主结构又有其它的字段(进程描述符 task_struct,页面管理的page结构,等就是采用这种方法创建链表的)。为简便理解,定义如下:
1 struct mylist{
2 int type;
3 char name[MAX_NAME_LEN];
4 struct list_head list;
5 }
创建链表,并初始化
1 structlist_head myhead;
2 INIT_LIST_HEAD(&myhead);
这样我们的链表就初始化完毕,链表头的myhead就prev 和 next指针分别指向myhead自己了,如下图:
二. 添加节点
内核已经提供了添加节点的接口了
1. list_add
如下所示。根据注释可知,是在链表头head后方插入一个新节点new。
1 /**
2 * list_add - add a new entry
3 * @new: new entry to be added
4 * @head: list head to add it after
5 *
6 * Insert a new entry after the specified head.
7 * This is good for implementing stacks.
8 */
9 static inline void list_add(struct list_head *new, struct list_head *head)
10 {
11 __list_add(new, head, head->next);
12 }
list_add再调用__list_add接口
1 /*
2 * Insert a new entry between two known consecutive entries.
3 *
4 * This is only for internal list manipulation where we know
5 * the prev/next entries already!
6 */
7 static inline void __list_add(struct list_head *new,
8 struct list_head *prev,
9 struct list_head *next)
10 {
11 if (!__list_add_valid(new, prev, next))
12 return;
13
14 next->prev = new;
15 new->next = next;
16 new->prev = prev;
17 WRITE_ONCE(prev->next, new);
18 }
其实就是在myhead链表头后和链表头后第一个节点之间插入一个新节点。然后这个新的节点就变成了链表头后的第一个节点了。
接着上面步骤创建1个节点然后插入到myhead之后
1 struct mylist node1;
2 node1.type = I2C_TYPE;
3 strcpy(node1.name,"yikoulinux");
4 list_add(&node1.list,&myhead);
然后在创建第二个节点,同样把它插入到header_task之后
1 struct mylist node2;
2 node2.type = I2C_TYPE;
3 strcpy(node2.name,"yikoupeng");
4 list_add(&node2.list,&myhead);
以此类推,每次插入一个新节点,都是紧靠着header节点,而之前插入的节点依次排序靠后,那最后一个节点则是第一次插入header后的那个节点。最终可得出:先来的节点靠后,而后来的节点靠前,“先进后出,后进先出”。所以此种结构类似于 stack“堆栈”, 而header_task就类似于内核stack中的栈顶指针esp,它都是紧靠着最后push到栈的元素。
2. list_add_tail 接口
上面所讲的list_add接口是从链表头header后添加的节点。同样,内核也提供了从链表尾处向前添加节点的接口list_add_tail.让我们来看一下它的具体实现。
1 /**
2 * list_add_tail - add a new entry
3 * @new: new entry to be added
4 * @head: list head to add it before
5 *
6 * Insert a new entry before the specified head.
7 * This is useful for implementing queues.
8 */
9 static inline void list_add_tail(struct list_head *new, struct list_head *head)
10 {
11 __list_add(new, head->prev, head);
12 }
从注释可得出:
(1)在一个特定的链表头前面插入一个节点
(2)这个方法很适用于队列的实现(why?)
进一步把__list_add()展开如下:
1 /*
2 * Insert a new entry between two known consecutive entries.
3 *
4 * This is only for internal list manipulation where we know
5 * the prev/next entries already!
6 */
7 static inline void __list_add(struct list_head *new,
8 struct list_head *prev,
9 struct list_head *next)
10 {
11 if (!__list_add_valid(new, prev, next))
12 return;
13
14 next->prev = new;
15 new->next = next;
16 new->prev = prev;
17 WRITE_ONCE(prev->next, new);
18 }
所以,很清楚明了, list_add_tail就相当于在链表头前方依次插入新的节点(也可理解为在链表尾部开始插入节点,此时,header节点既是为节点,保持不变)
利用上面分析list_add接口的方法可画出数据结构图形如下。
(1)创建一个链表头(实际上应该是表尾)代码参考第一节;
(2)插入第一个节点 node1.list , 调用
1 struct mylist node1;
2 node1.type = I2C_TYPE;
3 strcpy(node1.name,"yikoulinux");
4 list_add_tail(&node1.list,&myhead);
(3) 插入第二个节点node2.list,调用
1 struct mylist node2;
2 node2.type = I2C_TYPE;
3 strcpy(node2.name,"yikoupeng");
4 list_add_tail(&node2.list,&myhead);
依此类推,每次插入的新节点都是紧挨着
header_task表尾,而插入的第一个节点my_first_task排在了第一位,my_second_task排在了第二位,可得出:先插入的节点排在前面,后插入的节点排在后面,“先进先出,后进后出”,这不正是队列的特点吗(First
in First out)!
三. 删除节点
内核同样在list.h文件中提供了删除节点的接口 list_del(), 让我们看一下它的实现流程
1 static inline void list_del(struct list_head *entry)
2 {
3 __list_del_entry(entry);
4 entry->next = LIST_POISON1;
5 entry->prev = LIST_POISON2;
6 }
7 /*
8 * Delete a list entry by making the prev/next entries
9 * point to each other.
10 *
11 * This is only for internal list manipulation where we know
12 * the prev/next entries already!
13 */
14 static inline void __list_del(struct list_head * prev, struct list_head * next)
15 {
16 next->prev = prev;
17 WRITE_ONCE(prev->next, next);
18 }
19
20 /**
21 * list_del - deletes entry from list.
22 * @entry: the element to delete from the list.
23 * Note: list_empty() on entry does not return true after this, the entry is
24 * in an undefined state.
25 */
26 static inline void __list_del_entry(struct list_head *entry)
27 {
28 if (!__list_del_entry_valid(entry))
29 return;
30
31 __list_del(entry->prev, entry->next);
32 }
利用list_del(struct list_head *entry) 接口就可以删除链表中的任意节点了,但需注意,前提条件是这个节点是已知的,既在链表中真实存在,切prev,next指针都不为NULL。
四. 链表遍历
内核是同过下面这个宏定义来完成对list_head链表进行遍历的,如下 :
1 /**
2 * list_for_each - iterate over a list
3 * @pos: the &struct list_head to use as a loop cursor.
4 * @head: the head for your list.
5 */
6 #define list_for_each(pos, head) \
7 for (pos = (head)->next; pos != (head); pos = pos->next)
上面这种方式是从前向后遍历的,同样也可以使用下面的宏反向遍历:
1 /**
2 * list_for_each_prev - iterate over a list backwards
3 * @pos: the &struct list_head to use as a loop cursor.
4 * @head: the head for your list.
5 */
6 #define list_for_each_prev(pos, head) \
7 for (pos = (head)->prev; pos != (head); pos = pos->prev)
而且,list.h 中也提供了list_replace(节点替换) list_move(节点移位) ,翻转,查找等接口,这里就不在一一分析了。
五. 宿主结构
1.找出宿主结构 list_entry(ptr, type, member)
上面的所有操作都是基于list_head这个链表进行的,涉及的结构体也都是:
1 struct list_head {
2 struct list_head *next, *prev;
3 };
其实,正如文章一开始所说,我们真正更关心的是包含list_head这个结构体字段的宿主结构体,因为只有定位到了宿主结构体的起始地址,我们才能对对宿主结构体中的其它有意义的字段进行操作。
1 struct mylist
2 {
3 int type;
4 char name[MAX_NAME_LEN];
5 struct list_head list;
6 };
那我们如何根据list这个字段的地址而找到宿主结构node1的位置呢?list.h中定义如下:
1 /**
2 * list_entry - get the struct for this entry
3 * @ptr: the &struct list_head pointer.
4 * @type: the type of the struct this is embedded in.
5 * @member: the name of the list_head within the struct.
6 */
7 #define list_entry(ptr, type, member) \
8 container_of(ptr, type, member)
list.h中提供了list_entry宏来实现对应地址的转换,但最终还是调用了container_of宏,所以container_of宏的伟大之处不言而喻。
2 container_of
做linux驱动开发的同学是不是想到了LDD3这本书中经常使用的一个非常经典的宏定义!
1 container_of(ptr, type, member)
在LDD3这本书中的第三章字符设备驱动,以及第十四章驱动设备模型中多次提到,我觉得这个宏应该是内核最经典的宏之一。那接下来让我们揭开她的面纱:
此宏在内核代码 kernel/include/linux/kernel.h中定义(此处kernel版本为3.10;新版本4.13之后此宏定义改变,但实现思想保持一致)
而offsetof定义在 kernel/include/linux/stddef.h ,如下:
举个例子,来简单分析一下container_of内部实现机制。
例如:
1 struct test
2 {
3 int a;
4 short b;
5 char c;
6 };
7 struct test *p = (struct test *)malloc(sizeof(struct test));
8 test_function(&(p->b));
9
10 int test_function(short *addr_b)
11 {
12 //获取struct test结构体空间的首地址
13 struct test *addr;
14 addr = container_of(addr_b,struct test,b);
15 }
展开container_of宏,探究内部的实现:
1 typeof ( ( (struct test *)0 )->b ) ; (1)
2 typeof ( ( (struct test *)0 )->b ) *__mptr = addr_b ; (2)
3 (struct test *)( (char *)__mptr - offsetof(struct test,b)) (3)
(1) 获取成员变量b的类型 ,这里获取的就是short 类型。这是GNU_C的扩展语法。
(2) 用获取的变量类型,定义了一个指针变量 __mptr ,并且将成员变量 b的首地址赋值给它
(3) 这里的offsetof(struct test,b)是用来计算成员b在这个struct test 结构体的偏移。__mptr
是成员b的首地址, 现在 减去成员b在结构体里面的偏移值,算出来的是不是这个结构体的
首地址呀 。
3. 宿主结构的遍历
我们可以根据结构体中成员变量的地址找到宿主结构的地址,并且我们可以对成员变量所建立的链表进行遍历,那我们是不是也可以通过某种方法对宿主结构进行遍历呢?
答案肯定是可以的,内核在list.h中提供了下面的宏:
1 /**
2 * list_for_each_entry - iterate over list of given type
3 * @pos: the type * to use as a loop cursor.
4 * @head: the head for your list.
5 * @member: the name of the list_head within the struct.
6 */
7 #define list_for_each_entry(pos, head, member) \
8 for (pos = list_first_entry(head, typeof(*pos), member); \
9 &pos->member != (head); \
10 pos = list_next_entry(pos, member))
其中,list_first_entry 和 list_next_entry宏都定义在list.h中,分别代表:获取第一个真正的宿主结构的地址;获取下一个宿主结构的地址。它们的实现都是利用list_entry宏。
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member) /**
* list_next_entry - get the next element in list
* @pos: the type * to cursor
* @member: the name of the list_head within the struct.
*/
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
最终实现了宿主结构的遍历
1 #define list_for_each_entry(pos, head, member) \
2 for (pos = list_first_entry(head, typeof(*pos), member); \
3 &pos->member != (head); \
4 pos = list_next_entry(pos, member))
首先pos定位到第一个宿主结构地址,然后循环获取下一个宿主结构地址,如果查到宿主结构中的member成员变量(宿主结构中struct list_head定义的字段)地址为head,则退出,从而实现了宿主结构的遍历。如果要循环对宿主结构中的其它成员变量进行操作,这个遍历操作就显得特别有意义了。
我们用上面的 nod结构举个例子:
1 struct my_list *pos_ptr = NULL ;
2 list_for_each_entry (pos_ptr, &myhead, list )
3 {
4 printk ("val = %d\n" , pos_ptr->val);
5 }
实例1 一个简单的链表的实现
为方便起见,本例把内核的list.h文件单独拷贝出来,这样就可以独立于内核来编译测试。
功能描述:
本例比较简单,仅仅实现了单链表节点的创建、删除、遍历。
1 #include "list.h"
2 #include <stdio.h>
3 #include <string.h>
4
5 #define MAX_NAME_LEN 32
6 #define MAX_ID_LEN 10
7
8 struct list_head myhead;
9
10 #define I2C_TYPE 1
11 #define SPI_TYPE 2
12
13 char *dev_name[]={
14 "none",
15 "I2C",
16 "SPI"
17 };
18
19 struct mylist
20 {
21 int type;
22 char name[MAX_NAME_LEN];
23 struct list_head list;
24 };
25
26 void display_list(struct list_head *list_head)
27 {
28 int i=0;
29 struct list_head *p;
30 struct mylist *entry;
31 printf("-------list---------\n");
32 list_for_each(p,list_head)
33 {
34 printf("node[%d]\n",i++);
35 entry=list_entry(p,struct mylist,list);
36 printf("\ttype: %s\n",dev_name[entry->type]);
37 printf("\tname: %s\n",entry->name);
38 }
39 printf("-------end----------\n");
40 }
41
42 int main(void)
43 {
44
45 struct mylist node1;
46 struct mylist node2;
47
48 INIT_LIST_HEAD(&myhead);
49
50 node1.type = I2C_TYPE;
51 strcpy(node1.name,"yikoulinux");
52
53 node2.type = I2C_TYPE;
54 strcpy(node2.name,"yikoupeng");
55
56 list_add(&node1.list,&myhead);
57 list_add(&node2.list,&myhead);
58
59 display_list(&myhead);
60
61 list_del(&node1.list);
62
63 display_list(&myhead);
64 return 0;
65 }
运行结果
实例2 如何在一个链表上管理不同类型的节点
功能描述:
本实例主要实现在同一个链表上管理两个不同类型的节点,实现增删改查的操作。
结构体定义
一个链表要想区分节点的不同类型,那么节点中必须要有信息能够区分该节点类型,为了方便节点扩展,我们参考Linux内核,定义一个统一类型的结构体:
1 struct device
2 {
3 int type;
4 char name[MAX_NAME_LEN];
5 struct list_head list;
6 };
其中成员type表示该节点的类型:
1 #defineI2C_TYPE 1
2 #define SPI_TYPE 2
有了该结构体,我们要定义其他类型的结构体只需要包含该结构体即可,这个思想有点像面向对象语言的基类,后续派生出新的属性叫子类,说到这,一口君又忍不住想挖个坑,写一篇如何用C语言实现面向对象思想的继承、多态、interface。
下面我们定义2种类型的结构体:
i2c这种类型设备的专用结构体:
1 struct i2c_node
2 {
3 int data;
4 unsigned int reg;
5 struct device dev;
6 };
spi这种类型设备的专用结构体:
1 struct spi_node
2 {
3 unsigned int reg;
4 struct device dev;
5 };
我特意让两个结构体大小类型不一致。
结构类型
链表头结点定义
1 structlist_head device_list;
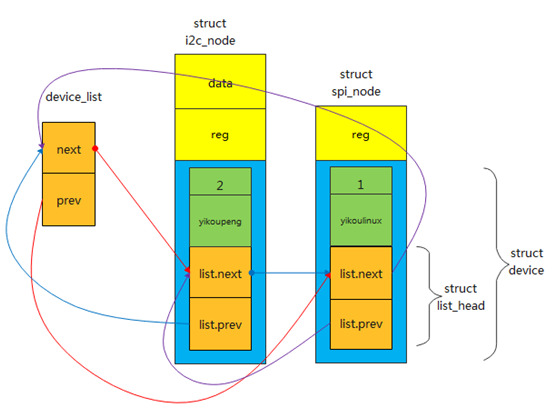
根据之前我们讲解的思想,这个链表链接起来后,应该是以下这种结构:
节点的插入
我们定义的节点要插入链表仍然是要依赖list_add(),既然我们定义了struct device这个结构体,那么我们完全可以参考linux内核,针对不同的节点封装函数,要注册到这个链表只需要调用该函数即可。
实现如下:
设备i2c的注册函数如下:
1 void i2c_register_device(struct device*dev)
2 {
3 dev.type = I2C_TYPE;
4 strcpy(dev.name,"yikoulinux");
5 list_add(&dev->list,&device_list);
6 }
设备spi的注册函数如下:
1 void spi_register_device(struct device*dev)
2 {
3 dev.type = SPI_TYPE;
4 strcpy(dev.name,"yikoupeng");
5 list_add(&dev->list,&device_list);
6 }
我们可以看到注册函数功能是填充了struct device 的type和name成员,然后再调用list_add()注册到链表中。这个思想很重要,因为Linux内核中许许多多的设备节点也是这样添加到其他的链表中的。要想让自己的C语言编程能力得到质的提升,一定要多读内核代码,即使看不懂也要坚持看,古人有云:代码读百遍其义自见。
节点的删除
同理,节点的删除,我们也统一封装成函数,同样只传递参数device即可:
1 void i2c_unregister_device(struct device *device)
2 {
3 // struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
4 list_del(&device->list);
5 }
6 void spi_unregister_device(struct device *device)
7 {
8 // struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
9 list_del(&device->list);
10 }
在函数中,可以用container_of提取出了设备节点的首地址,实际使用中可以根据设备的不同释放不同的资源。
宿主结构的遍历
节点的遍历,在这里我们通过设备链表device_list开始遍历,假设该节点名是node,通过list_for_each()可以得到node->dev->list的地址,然后利用container_of 可以得到node->dev、node的地址。
1 void display_list(struct list_head *list_head)
2 {
3 int i=0;
4 struct list_head *p;
5 struct device *entry;
6
7 printf("-------list---------\n");
8 list_for_each(p,list_head)
9 {
10 printf("node[%d]\n",i++);
11 entry=list_entry(p,struct device,list);
12
13 switch(entry->type)
14 {
15 case I2C_TYPE:
16 display_i2c_device(entry);
17 break;
18 case SPI_TYPE:
19 display_spi_device(entry);
20 break;
21 default:
22 printf("unknown device type!\n");
23 break;
24 }
25 display_device(entry);
26 }
27 printf("-------end----------\n");
28 }
由以上代码可知,利用内核链表的统一接口,找个每一个节点的list成员,然后再利用container_of 得到我们定义的标准结构体struct device,进而解析出节点的类型,调用对应节点显示函数,这个地方其实还可以优化,就是我们可以在struct device中添加一个函数指针,在xxx_unregister_device()函数中可以将该函数指针直接注册进来,那么此处代码会更精简高效一些。如果在做项目的过程中,写出这种面向对象思想的代码,那么你的地址是肯定不一样的。读者有兴趣可以自己尝试一下。
1 void display_i2c_device(struct device *device)
2 {
3 struct i2c_node *i2c_device=container_of(device, struct i2c_node, dev);
4 printf("\t i2c_device->data: %d\n",i2c_device->data);
5 printf("\t i2c_device->reg: %#x\n",i2c_device->reg);
6 }
7
8 void display_spi_device(struct device *device)
9 {
10 struct spi_node *spi_device=container_of(device, struct spi_node, dev);
11 printf("\t spi_device->reg: %#x\n",spi_device->reg);
12 }
上述代码提取出来宿主节点的信息。
实例代码
1 #include "list.h"
2 #include <stdio.h>
3 #include <string.h>
4
5 #define MAX_NAME_LEN 32
6 #define MAX_ID_LEN 10
7
8 struct list_head device_list;
9
10 #define I2C_TYPE 1
11 #define SPI_TYPE 2
12
13 char *dev_name[]={
14 "none",
15 "I2C",
16 "SPI"
17 };
18
19 struct device
20 {
21 int type;
22 char name[MAX_NAME_LEN];
23 struct list_head list;
24 };
25
26 struct i2c_node
27 {
28 int data;
29 unsigned int reg;
30 struct device dev;
31 };
32 struct spi_node
33 {
34 unsigned int reg;
35 struct device dev;
36 };
37 void display_i2c_device(struct device *device)
38 {
39 struct i2c_node *i2c_device=container_of(device, struct i2c_node, dev);
40
41 printf("\t i2c_device->data: %d\n",i2c_device->data);
42 printf("\t i2c_device->reg: %#x\n",i2c_device->reg);
43 }
44 void display_spi_device(struct device *device)
45 {
46 struct spi_node *spi_device=container_of(device, struct spi_node, dev);
47
48 printf("\t spi_device->reg: %#x\n",spi_device->reg);
49 }
50 void display_device(struct device *device)
51 {
52 printf("\t dev.type: %d\n",device->type);
53 printf("\t dev.type: %s\n",dev_name[device->type]);
54 printf("\t dev.name: %s\n",device->name);
55 }
56 void display_list(struct list_head *list_head)
57 {
58 int i=0;
59 struct list_head *p;
60 struct device *entry;
61
62 printf("-------list---------\n");
63 list_for_each(p,list_head)
64 {
65 printf("node[%d]\n",i++);
66 entry=list_entry(p,struct device,list);
67
68 switch(entry->type)
69 {
70 case I2C_TYPE:
71 display_i2c_device(entry);
72 break;
73 case SPI_TYPE:
74 display_spi_device(entry);
75 break;
76 default:
77 printf("unknown device type!\n");
78 break;
79 }
80 display_device(entry);
81 }
82 printf("-------end----------\n");
83 }
84 void i2c_register_device(struct device*dev)
85 {
86 struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
87
88 i2c_device->dev.type = I2C_TYPE;
89 strcpy(i2c_device->dev.name,"yikoulinux");
90
91 list_add(&dev->list,&device_list);
92 }
93 void spi_register_device(struct device*dev)
94 {
95 struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
96
97 spi_device->dev.type = SPI_TYPE;
98 strcpy(spi_device->dev.name,"yikoupeng");
99
100 list_add(&dev->list,&device_list);
101 }
102 void i2c_unregister_device(struct device *device)
103 {
104 struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
105
106 list_del(&device->list);
107 }
108 void spi_unregister_device(struct device *device)
109 {
110 struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
111
112 list_del(&device->list);
113 }
114 int main(void)
115 {
116
117 struct i2c_node dev1;
118 struct spi_node dev2;
119
120 INIT_LIST_HEAD(&device_list);
121 dev1.data = 1;
122 dev1.reg = 0x40009000;
123 i2c_register_device(&dev1.dev);
124 dev2.reg = 0x40008000;
125 spi_register_device(&dev2.dev);
126 display_list(&device_list);
127 unregister_device(&dev1.dev);
128 display_list(&device_list);
129 return 0;
130 }
代码主要功能:
117-118 :定义两个不同类型的节点dev1,dev2;
120 :初始化设备链表;
121-122、124:初始化节点数据;
123/125 :向链表device_list注册这两个节点;
126 :显示该链表;
127 :删除节点dev1;
128 :显示该链表。
程序运行截图
读者可以试试如何管理更多类型的节点。
实例3 实现节点在两个链表上自由移动
功能描述:
初始化两个链表,实现两个链表上节点的插入和移动。每个节点维护大量的临时内存数据。
节点创建
节点结构体创建如下:
1 struct mylist{
2 int number;
3 char type;
4 char *pmem; //内存存放地址,需要malloc
5 struct list_head list;
6 };
需要注意成员pmem,因为要维护大量的内存,我们最好不要直定义个很大的数组,因为定义的变量位于栈中,而一般的系统给栈的空间是有限的,如果定义的变量占用空间太大,会导致栈溢出,一口君曾经就遇到过这个bug。
链表定义和初始化
链表定义如下:
1 structlist_head active_head;
2 struct list_head free_head;
初始化
1 INIT_LIST_HEAD(&free_head);
2 INIT_LIST_HEAD(&active_head);
这两个链表如下:
关于节点,因为该实例是从实际项目中剥离出来,节点启示是起到一个缓冲去的作用,数量不是无限的,所以在此我们默认最多10个节点。
我们不再动态创建节点,而是先全局创建指针数组,存放这10个节点的地址,然后将这10个节点插入到对应的队列中。
数组定义:
1 structmylist*list_array[BUFFER_NUM];
这个数组只用于存放指针,所以定义之后实际情况如下:
初始化这个数组对应的节点:
1 static ssize_t buffer_ring_init()
2 {
3 int i=0;
4 for(i=0;i<BUFFER_NUM;i++){
5 list_array[i]=malloc(sizeof(struct mylist));
6 INIT_LIST_HEAD(&list_array[i]->list);
7 list_array[i]->pmem=kzalloc(DATA_BUFFER_SIZE,GFP_KERNEL);
8 }
9 return 0;
10 }
5:为下标为i的节点分配实际大小为sizeof(structmylist)的内存
6:初始化该节点的链表
7:为pmem成员从堆中分配一块内存
初始化完毕,链表实际情况如下:
节点插入
1 static ssize_t insert_free_list_all()
2 {
3 int i=0;
4
5 for(i=0;i<BUFFER_NUM;i++){
6 list_add(&list_array[i]->list,&free_head);
7 }
8 return 0;
9 }
6:用头插法将所有节点插入到free_head链表中
所有节点全部插入free链表后,结构图如下:
遍历链表
虽然可以通过数组遍历链表,但是实际在操作过程中,在链表中各个节点的位置是错乱的。所以最好从借助list节点来查找各个节点。
1 show_list(&free_head);
2 show_list(&active_head);
代码实现如下:
1 void show_list(struct list_head *list_head)
2 {
3 int i=0;
4 struct mylist*entry,*tmp;
5 //判断节点是否为空
6 if(list_empty(list_head)==true)
7 {
8 return;
9 }
10 list_for_each_entry_safe(entry,tmp,list_head,list)
11 {
12 printf("[%d]=%d\t",i++,entry->number);
13 if(i%4==0)
14 {
15 printf("\n");
16 }
17 }
18 }
节点移动
将节点从active_head链表移动到free_head链表,有点像生产者消费者模型中的消费者,吃掉资源后,就要把这个节点放置到空闲链表,让生产者能够继续生产数据,所以这两个函数我起名eat、spit,意为吃掉和吐,希望你们不要觉得很怪异。
1 int eat_node()
2 {
3 struct mylist*entry=NULL;
4
5 if(list_empty(&active_head)==true)
6 {
7 printf("list active_head is empty!-----------\n");
8 }
9 entry=list_first_entry(&active_head,struct mylist,list);
10 printf("\t eat node=%d\n",entry->number);
11 list_move_tail(&entry->list,&free_head);
12 }
节点移动的思路是:
- 利用list_empty判断该链表是否为空
- 利用list_first_entry从active_head链表中查找到一个节点,并用指针entry指向该节点
- 利用list_move_tail将该节点移入到free_head链表,注意此处不能用list_add,因为这个节点我要从原链表把他删除掉,然后插入到新链表。
将节点从free_head链表移动到active_head链表。
1 spit_node()
2 {
3 struct mylist*entry=NULL;
4
5 if(list_empty(&free_head)==true)
6 {
7 printf("list free_head is empty!-----------\n");
8 }
9 entry=list_first_entry(&free_head,struct mylist,list);
10 printf("\t spit node=%d\n",entry->number);
11 list_move_tail(&entry->list,&active_head);
12 }
大部分功能讲解完了,下面我们贴下完整代码。
代码实例
1 #include <stdint.h>
2 #include <stdio.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <byteswap.h>
6 #include <string.h>
7 #include <errno.h>
8 #include <signal.h>
9 #include <fcntl.h>
10 #include <ctype.h>
11 #include <termios.h>
12 #include <sys/types.h>
13 #include <sys/mman.h>
14 #include <sys/ioctl.h>
15 #include "list.h" // linux-3.14/scripts/kconfig/list.h
16
17 #undef NULL
18 #define NULL ((void *)0)
19
20 enum {
21 false = 0,
22 true = 1
23 };
24
25 #define DATA_TYPE 0x14
26 #define SIG_TYPE 0x15
27
28 struct mylist{
29 int number;
30 char type;
31 char *pmem;
32 struct list_head list;
33 };
34 #define FATAL do { fprintf(stderr, "Error at line %d, file %s (%d) [%s]\n",__LINE_,__FILE__,errno,strerror(errno));exit(1);}while(0)
35 struct list_head active_head;
36 struct list_head free_head;
37 #define BUFFER_NUM 10
38 #define DATA_BUFFER_SIZE 512
39 struct mylist*list_array[BUFFER_NUM];
40
41
42 int born_number(int number)
43 {
44 struct mylist *entry=NULL;
45
46 if(list_empty(&free_head)==true)
47 {
48 printf("list free_head is empty!----------------\n");
49 }
50 entry = list_first_entry(&free_head,struct mylist,list);
51 entry->type = DATA_TYPE;
52 entry->number=number;
53 list_move_tail(&entry->list,&active_head);
54 }
55
56 int eat_node()
57 {
58 struct mylist*entry=NULL;
59
60 if(list_empty(&active_head)==true)
61 {
62 printf("list active_head is empty!-----------\n");
63 }
64 entry=list_first_entry(&active_head,struct mylist,list);
65 printf("\t eat node=%d\n",entry->number);
66 list_move_tail(&entry->list,&free_head);
67 }
68 spit_node()
69 {
70 struct mylist*entry=NULL;
71
72 if(list_empty(&free_head)==true)
73 {
74 printf("list free_head is empty!-----------\n");
75 }
76 entry=list_first_entry(&free_head,struct mylist,list);
77 printf("\t spit node=%d\n",entry->number);
78 list_move_tail(&entry->list,&active_head);
79 }
80
81 void show_list(struct list_head *list_head)
82 {
83 int i=0;
84 struct mylist*entry,*tmp;
85
86 if(list_empty(list_head)==true)
87 {
88 return;
89 }
90 list_for_each_entry_safe(entry,tmp,list_head,list)
91 {
92 printf("[%d]=%d\t",i++,entry->number);
93 if(i%4==0)
94 {
95 printf("\n");
96 }
97 }
98 }
99 int list_num(struct list_head *list_head)
100 {
101 int i=0;
102 struct mylist *entry,*tmp;
103 // printf("----------show free list-------------\n");
104 list_for_each_entry_safe(entry,tmp,list_head,list)
105 {
106 i++;
107 }
108 return i;
109 }
110 static ssize_t buffer_ring_init()
111 {
112 int i=0;
113
114 for(i=0;i<BUFFER_NUM;i++){
115 list_array[i]=malloc(sizeof(struct mylist));
116 INIT_LIST_HEAD(&list_array[i]->list);
117 list_array[i]->pmem=kzalloc(DATA_BUFFER_SIZE,GFP_KERNEL);
118 list_add_tail(&list_array[i]->list,&free_head);
119 }
120 return 0;
121 }
122 static ssize_t insert_free_list_all()
123 {
124 int i=0;
125
126 for(i=0;i<BUFFER_NUM;i++){
127 list_add_tail(&list_array[i]->list,&free_head);
128 }
129 return 0;
130 }
131 static ssize_t buffer_ring_free()
132 {
133 int buffer_count=0;
134 struct mylist*entry=NULL;
135 for(;buffer_count<BUFFER_NUM;buffer_count++)
136 {
137 free(list_array[buffer_count]->pmem);
138 free(list_array[buffer_count]);
139 }
140 return 0;
141 }
142
143 int main(int argc,char**argv)
144 {
145 INIT_LIST_HEAD(&free_head);
146 INIT_LIST_HEAD(&active_head);
147 buffer_ring_init();
148 insert_free_list_all();
149 born_number(1);
150 born_number(2);
151 born_number(3);
152 born_number(4);
153 born_number(5);
154 born_number(6);
155 born_number(7);
156 born_number(8);
157 born_number(9);
158 born_number(10);
159
160 printf("\n----------active list[%d]------------\n",list_num(&active_head));
161 show_list(&active_head);
162 printf("\n--------------end-----------------\n");
163
164 printf("\n----------free list[%d]------------\n",list_num(&free_head));
165 show_list(&free_head);
166 printf("\n--------------end-----------------\n");
167
168 printf("\n\n active list----------> free list \n");
169
170 eat_node();
171 eat_node();
172 eat_node();
173
174 printf("\n----------active list[%d]------------\n",list_num(&active_head));
175 show_list(&active_head);
176 printf("\n--------------end-----------------\n");
177
178 printf("\n----------free list[%d]------------\n",list_num(&free_head));
179 show_list(&free_head);
180 printf("\n--------------end-----------------\n");
181
182
183 printf("\n\n free list----------> active list \n");
184
185 spit_node();
186 spit_node();
187
188 printf("\n----------active list[%d]------------\n",list_num(&active_head));
189 show_list(&active_head);
190 printf("\n--------------end-----------------\n");
191
192 printf("\n----------free list[%d]------------\n",list_num(&free_head));
193 show_list(&free_head);
194 printf("\n--------------end-----------------\n");
195
196 }
运行结果如下:
list_head短小精悍,读者可以借鉴此文实现其他功能。
参考文档:https://kernelnewbies.org/FAQ/LinkedLists
《Understanding linux kernel》
《Linux device drivers》
list.h比较长,就不在此贴出源码,如果读者想获取这个文件,关注公众号:一口Linux,一口君这还有大量的Linux学习资料。
在Linux内核中,提供了一个用来创建双向循环链表的结构 list_head。虽然linux内核是用C语言写的,但是list_head的引入,使得内核数据结构也可以拥有面向对象的特性,通过使用操作list_head 的通用接口很容易实现代码的重用,有点类似于C++的继承机制(希望有机会写篇文章研究一下C语言的面向对象机制)。
首先找到list_head结构体定义,kernel/inclue/linux/types.h 如下:
```c
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
```
需要注意的一点是,头结点head是不使用的,这点需要注意。
使用list_head组织的链表的结构如下图所示:

然后就开始围绕这个结构开始构建链表,然后插入、删除节点 ,遍历整个链表等等,其实内核已经提供好了现成的接口,接下来就让我们进入 kernel/include/linux/list.h中:
## 一. 创建链表
内核提供了下面的这些接口来初始化链表:
```c
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
```
如: 可以通过 LIST_HEAD(mylist) 进行初始化一个链表,mylist的prev 和 next 指针都是指向自己。
```c
structlist_head mylist = {&mylist, &mylist} ;
```
但是如果只是利用mylist这样的结构体实现链表就没有什么实际意义了,因为正常的链表都是为了遍历结构体中的其它有意义的字段而创建的,而我们mylist中只有 prev和next指针,却没有实际有意义的字段数据,所以毫无意义。
综上,我们可以创建一个宿主结构,然后在此结构中再嵌套mylist字段,宿主结构又有其它的字段(进程描述符 task_struct,页面管理的page结构,等就是采用这种方法创建链表的)。为简便理解,定义如下:
```c
struct mylist{
int type;
char name[MAX_NAME_LEN];
struct list_head list;
}
```
创建链表,并初始化
```c
structlist_head myhead;
INIT_LIST_HEAD(&myhead);
```
这样我们的链表就初始化完毕,链表头的myhead就prev 和 next指针分别指向myhead自己了,如下图:

## 二. 添加节点
内核已经提供了添加节点的接口了
### 1. list_add
如下所示。根据注释可知,是在链表头head后方插入一个新节点new。
```c
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
```
list_add再调用__list_add接口
```c
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
```
其实就是在myhead链表头后和链表头后第一个节点之间插入一个新节点。然后这个新的节点就变成了链表头后的第一个节点了。
接着上面步骤创建1个节点然后插入到myhead之后
```c
struct mylist node1;
node1.type = I2C_TYPE;
strcpy(node1.name,"yikoulinux");
list_add(&node1.list,&myhead);
```

然后在创建第二个节点,同样把它插入到header_task之后
```c
struct mylist node2;
node2.type = I2C_TYPE;
strcpy(node2.name,"yikoupeng");
list_add(&node2.list,&myhead);
```

以此类推,每次插入一个新节点,都是紧靠着header节点,而之前插入的节点依次排序靠后,那最后一个节点则是第一次插入header后的那个节点。最终可得出:先来的节点靠后,而后来的节点靠前,“先进后出,后进先出”。所以此种结构类似于 stack“堆栈”, 而header_task就类似于内核stack中的栈顶指针esp,它都是紧靠着最后push到栈的元素。
### 2. list_add_tail 接口
上面所讲的list_add接口是从链表头header后添加的节点。同样,内核也提供了从链表尾处向前添加节点的接口list_add_tail.让我们来看一下它的具体实现。
```c
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
```
从注释可得出:
(1)在一个特定的链表头前面插入一个节点
(2)这个方法很适用于队列的实现(why?)
进一步把__list_add()展开如下:
```c
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
```
所以,很清楚明了, list_add_tail就相当于在链表头前方依次插入新的节点(也可理解为在链表尾部开始插入节点,此时,header节点既是为节点,保持不变)
利用上面分析list_add接口的方法可画出数据结构图形如下。
(1)创建一个链表头(实际上应该是表尾)代码参考第一节;

(2)插入第一个节点 node1.list , 调用
```c
struct mylist node1;
node1.type = I2C_TYPE;
strcpy(node1.name,"yikoulinux");
list_add_tail(&node1.list,&myhead);
```

(3) 插入第二个节点node2.list,调用
```c
struct mylist node2;
node2.type = I2C_TYPE;
strcpy(node2.name,"yikoupeng");
list_add_tail(&node2.list,&myhead);
```

依此类推,每次插入的新节点都是紧挨着 header_task表尾,而插入的第一个节点my_first_task排在了第一位,my_second_task排在了第二位,可得出:先插入的节点排在前面,后插入的节点排在后面,“先进先出,后进后出”,这不正是队列的特点吗(First in First out)!
### 三. 删除节点
内核同样在list.h文件中提供了删除节点的接口 list_del(), 让我们看一下它的实现流程
```c
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
```
利用list_del(struct list_head *entry) 接口就可以删除链表中的任意节点了,但需注意,前提条件是这个节点是已知的,既在链表中真实存在,切prev,next指针都不为NULL。
### 四. 链表遍历
内核是同过下面这个宏定义来完成对list_head链表进行遍历的,如下 :
```c
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
```
上面这种方式是从前向后遍历的,同样也可以使用下面的宏反向遍历:
```c
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
```
而且,list.h 中也提供了list_replace(节点替换) list_move(节点移位) ,翻转,查找等接口,这里就不在一一分析了。
### 五. 宿主结构
1.找出宿主结构 list_entry(ptr, type, member)
上面的所有操作都是基于list_head这个链表进行的,涉及的结构体也都是:
```c
struct list_head {
struct list_head *next, *prev;
};
```
其实,正如文章一开始所说,我们真正更关心的是包含list_head这个结构体字段的宿主结构体,因为只有定位到了宿主结构体的起始地址,我们才能对对宿主结构体中的其它有意义的字段进行操作。
```c
struct mylist
{
int type;
char name[MAX_NAME_LEN];
struct list_head list;
};
```
那我们如何根据list这个字段的地址而找到宿主结构node1的位置呢?list.h中定义如下:
```c
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
```
list.h中提供了list_entry宏来实现对应地址的转换,但最终还是调用了container_of宏,所以container_of宏的伟大之处不言而喻。
### 2 container_of
做linux驱动开发的同学是不是想到了LDD3这本书中经常使用的一个非常经典的宏定义!
```c
container_of(ptr, type, member)
```
在LDD3这本书中的第三章字符设备驱动,以及第十四章驱动设备模型中多次提到,我觉得这个宏应该是内核最经典的宏之一。那接下来让我们揭开她的面纱:
此宏在内核代码 kernel/include/linux/kernel.h中定义(此处kernel版本为3.10;新版本4.13之后此宏定义改变,但实现思想保持一致)
而offsetof定义在 kernel/include/linux/stddef.h ,如下:

举个例子,来简单分析一下container_of内部实现机制。
例如:
```c
struct test
{
int a;
short b;
char c;
};
struct test *p = (struct test *)malloc(sizeof(struct test));
test_function(&(p->b));
int test_function(short *addr_b)
{
//获取struct test结构体空间的首地址
struct test *addr;
addr = container_of(addr_b,struct test,b);
}
```
展开container_of宏,探究内部的实现:
```c
typeof ( ( (struct test *)0 )->b ) ; (1)
typeof ( ( (struct test *)0 )->b ) *__mptr = addr_b ; (2)
(struct test *)( (char *)__mptr - offsetof(struct test,b)) (3)
```
(1) 获取成员变量b的类型 ,这里获取的就是short 类型。这是GNU_C的扩展语法。
(2) 用获取的变量类型,定义了一个指针变量 __mptr ,并且将成员变量 b的首地址赋值给它
(3) 这里的offsetof(struct test,b)是用来计算成员b在这个struct test 结构体的偏移。__mptr
是成员b的首地址, 现在 减去成员b在结构体里面的偏移值,算出来的是不是这个结构体的
首地址呀 。
### 3. 宿主结构的遍历
我们可以根据结构体中成员变量的地址找到宿主结构的地址,并且我们可以对成员变量所建立的链表进行遍历,那我们是不是也可以通过某种方法对宿主结构进行遍历呢?
答案肯定是可以的,内核在list.h中提供了下面的宏:
```c
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
```
其中,list_first_entry 和 list_next_entry宏都定义在list.h中,分别代表:获取第一个真正的宿主结构的地址;获取下一个宿主结构的地址。它们的实现都是利用list_entry宏。
```c
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
/**
* list_next_entry - get the next element in list
* @pos: the type * to cursor
* @member: the name of the list_head within the struct.
*/
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
```
最终实现了宿主结构的遍历
```c
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
```
首先pos定位到第一个宿主结构地址,然后循环获取下一个宿主结构地址,如果查到宿主结构中的member成员变量(宿主结构中struct list_head定义的字段)地址为head,则退出,从而实现了宿主结构的遍历。如果要循环对宿主结构中的其它成员变量进行操作,这个遍历操作就显得特别有意义了。
我们用上面的 nod结构举个例子:
```c
struct my_list *pos_ptr = NULL ;
list_for_each_entry (pos_ptr, &myhead, list )
{
printk ("val = %d\n" , pos_ptr->val);
}
```
# 实例1 一个简单的链表的实现
为方便起见,本例把内核的list.h文件单独拷贝出来,这样就可以独立于内核来编译测试。
### 功能描述:
本例比较简单,仅仅实现了单链表节点的创建、删除、遍历。
```c
#include "list.h"
#include <stdio.h>
#include <string.h>
#define MAX_NAME_LEN 32
#define MAX_ID_LEN 10
struct list_head myhead;
#define I2C_TYPE 1
#define SPI_TYPE 2
char *dev_name[]={
"none",
"I2C",
"SPI"
};
struct mylist
{
int type;
char name[MAX_NAME_LEN];
struct list_head list;
};
void display_list(struct list_head *list_head)
{
int i=0;
struct list_head *p;
struct mylist *entry;
printf("-------list---------\n");
list_for_each(p,list_head)
{
printf("node[%d]\n",i++);
entry=list_entry(p,struct mylist,list);
printf("\ttype: %s\n",dev_name[entry->type]);
printf("\tname: %s\n",entry->name);
}
printf("-------end----------\n");
}
int main(void)
{
struct mylist node1;
struct mylist node2;
INIT_LIST_HEAD(&myhead);
node1.type = I2C_TYPE;
strcpy(node1.name,"yikoulinux");
node2.type = I2C_TYPE;
strcpy(node2.name,"yikoupeng");
list_add(&node1.list,&myhead);
list_add(&node2.list,&myhead);
display_list(&myhead);
list_del(&node1.list);
display_list(&myhead);
return 0;
}
```
运行结果

# 实例2 如何在一个链表上管理不同类型的节点
## 功能描述:
本实例主要实现在同一个链表上管理两个不同类型的节点,实现增删改查的操作。
## 结构体定义
一个链表要想区分节点的不同类型,那么节点中必须要有信息能够区分该节点类型,为了方便节点扩展,我们参考Linux内核,定义一个统一类型的结构体:
```c
struct device
{
int type;
char name[MAX_NAME_LEN];
struct list_head list;
};
```
其中成员type表示该节点的类型:
```c
#defineI2C_TYPE 1
#define SPI_TYPE 2
```
有了该结构体,我们要定义其他类型的结构体只需要包含该结构体即可,这个思想有点像面向对象语言的基类,后续派生出新的属性叫子类,说到这,一口君又忍不住想挖个坑,写一篇如何用C语言实现面向对象思想的继承、多态、interface。
下面我们定义2种类型的结构体:
i2c这种类型设备的专用结构体:
```c
struct i2c_node
{
int data;
unsigned int reg;
struct device dev;
};
```
spi这种类型设备的专用结构体:
```c
struct spi_node
{
unsigned int reg;
struct device dev;
};
```
我特意让两个结构体大小类型不一致。
# 结构类型
链表头结点定义
```c
structlist_head device_list;
```
根据之前我们讲解的思想,这个链表链接起来后,应该是以下这种结构:
## 节点的插入
我们定义的节点要插入链表仍然是要依赖list_add(),既然我们定义了struct device这个结构体,那么我们完全可以参考linux内核,针对不同的节点封装函数,要注册到这个链表只需要调用该函数即可。
实现如下:
设备i2c的注册函数如下:
```c
void i2c_register_device(struct device*dev)
{
dev.type = I2C_TYPE;
strcpy(dev.name,"yikoulinux");
list_add(&dev->list,&device_list);
}
```
设备spi的注册函数如下:
```c
void spi_register_device(struct device*dev)
{
dev.type = SPI_TYPE;
strcpy(dev.name,"yikoupeng");
list_add(&dev->list,&device_list);
}
```
我们可以看到注册函数功能是填充了struct device 的type和name成员,然后再调用list_add()注册到链表中。这个思想很重要,因为Linux内核中许许多多的设备节点也是这样添加到其他的链表中的。要想让自己的C语言编程能力得到质的提升,一定要多读内核代码,即使看不懂也要坚持看,古人有云:代码读百遍其义自见。
## 节点的删除
同理,节点的删除,我们也统一封装成函数,同样只传递参数device即可:
```c
void i2c_unregister_device(struct device *device)
{
// struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
list_del(&device->list);
}
void spi_unregister_device(struct device *device)
{
// struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
list_del(&device->list);
}
```
在函数中,可以用container_of提取出了设备节点的首地址,实际使用中可以根据设备的不同释放不同的资源。
## 宿主结构的遍历
节点的遍历,在这里我们通过设备链表device_list开始遍历,假设该节点名是node,通过list_for_each()可以得到node->dev->list的地址,然后利用container_of 可以得到node->dev、node的地址。
```c
void display_list(struct list_head *list_head)
{
int i=0;
struct list_head *p;
struct device *entry;
printf("-------list---------\n");
list_for_each(p,list_head)
{
printf("node[%d]\n",i++);
entry=list_entry(p,struct device,list);
switch(entry->type)
{
case I2C_TYPE:
display_i2c_device(entry);
break;
case SPI_TYPE:
display_spi_device(entry);
break;
default:
printf("unknown device type!\n");
break;
}
display_device(entry);
}
printf("-------end----------\n");
}
```
由以上代码可知,利用内核链表的统一接口,找个每一个节点的list成员,然后再利用container_of 得到我们定义的标准结构体struct device,进而解析出节点的类型,调用对应节点显示函数,这个地方其实还可以优化,就是我们可以在struct device中添加一个函数指针,在xxx_unregister_device()函数中可以将该函数指针直接注册进来,那么此处代码会更精简高效一些。如果在做项目的过程中,写出这种面向对象思想的代码,那么你的地址是肯定不一样的。读者有兴趣可以自己尝试一下。
```c
void display_i2c_device(struct device *device)
{
struct i2c_node *i2c_device=container_of(device, struct i2c_node, dev);
printf("\t i2c_device->data: %d\n",i2c_device->data);
printf("\t i2c_device->reg: %#x\n",i2c_device->reg);
}
```
```c
void display_spi_device(struct device *device)
{
struct spi_node *spi_device=container_of(device, struct spi_node, dev);
printf("\t spi_device->reg: %#x\n",spi_device->reg);
}
```
上述代码提取出来宿主节点的信息。
## 实例代码
```c
#include "list.h"
#include <stdio.h>
#include <string.h>
#define MAX_NAME_LEN 32
#define MAX_ID_LEN 10
struct list_head device_list;
#define I2C_TYPE 1
#define SPI_TYPE 2
char *dev_name[]={
"none",
"I2C",
"SPI"
};
struct device
{
int type;
char name[MAX_NAME_LEN];
struct list_head list;
};
struct i2c_node
{
int data;
unsigned int reg;
struct device dev;
};
struct spi_node
{
unsigned int reg;
struct device dev;
};
void display_i2c_device(struct device *device)
{
struct i2c_node *i2c_device=container_of(device, struct i2c_node, dev);
printf("\t i2c_device->data: %d\n",i2c_device->data);
printf("\t i2c_device->reg: %#x\n",i2c_device->reg);
}
void display_spi_device(struct device *device)
{
struct spi_node *spi_device=container_of(device, struct spi_node, dev);
printf("\t spi_device->reg: %#x\n",spi_device->reg);
}
void display_device(struct device *device)
{
printf("\t dev.type: %d\n",device->type);
printf("\t dev.type: %s\n",dev_name[device->type]);
printf("\t dev.name: %s\n",device->name);
}
void display_list(struct list_head *list_head)
{
int i=0;
struct list_head *p;
struct device *entry;
printf("-------list---------\n");
list_for_each(p,list_head)
{
printf("node[%d]\n",i++);
entry=list_entry(p,struct device,list);
switch(entry->type)
{
case I2C_TYPE:
display_i2c_device(entry);
break;
case SPI_TYPE:
display_spi_device(entry);
break;
default:
printf("unknown device type!\n");
break;
}
display_device(entry);
}
printf("-------end----------\n");
}
void i2c_register_device(struct device*dev)
{
struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
i2c_device->dev.type = I2C_TYPE;
strcpy(i2c_device->dev.name,"yikoulinux");
list_add(&dev->list,&device_list);
}
void spi_register_device(struct device*dev)
{
struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
spi_device->dev.type = SPI_TYPE;
strcpy(spi_device->dev.name,"yikoupeng");
list_add(&dev->list,&device_list);
}
void i2c_unregister_device(struct device *device)
{
struct i2c_node *i2c_device=container_of(dev, struct i2c_node, dev);
list_del(&device->list);
}
void spi_unregister_device(struct device *device)
{
struct spi_node *spi_device=container_of(dev, struct spi_node, dev);
list_del(&device->list);
}
int main(void)
{
struct i2c_node dev1;
struct spi_node dev2;
INIT_LIST_HEAD(&device_list);
dev1.data = 1;
dev1.reg = 0x40009000;
i2c_register_device(&dev1.dev);
dev2.reg = 0x40008000;
spi_register_device(&dev2.dev);
display_list(&device_list);
unregister_device(&dev1.dev);
display_list(&device_list);
return 0;
}
```
代码主要功能:
117-118 :定义两个不同类型的节点dev1,dev2;
120 :初始化设备链表;
121-122、124:初始化节点数据;
123/125 :向链表device_list注册这两个节点;
126 :显示该链表;
127 :删除节点dev1;
128 :显示该链表。
程序运行截图

读者可以试试如何管理更多类型的节点。
# 实例3 实现节点在两个链表上自由移动
## 功能描述:
初始化两个链表,实现两个链表上节点的插入和移动。每个节点维护大量的临时内存数据。
## 节点创建
节点结构体创建如下:
```c
struct mylist{
int number;
char type;
char *pmem; //内存存放地址,需要malloc
struct list_head list;
};
```
需要注意成员pmem,因为要维护大量的内存,我们最好不要直定义个很大的数组,因为定义的变量位于栈中,而一般的系统给栈的空间是有限的,如果定义的变量占用空间太大,会导致栈溢出,一口君曾经就遇到过这个bug。
## 链表定义和初始化
链表定义如下:
```c
structlist_head active_head;
struct list_head free_head;
```
初始化
```c
INIT_LIST_HEAD(&free_head);
INIT_LIST_HEAD(&active_head);
```
这两个链表如下:

关于节点,因为该实例是从实际项目中剥离出来,节点启示是起到一个缓冲去的作用,数量不是无限的,所以在此我们默认最多10个节点。
我们不再动态创建节点,而是先全局创建指针数组,存放这10个节点的地址,然后将这10个节点插入到对应的队列中。
数组定义:
```c
structmylist*list_array[BUFFER_NUM];
```
这个数组只用于存放指针,所以定义之后实际情况如下:

初始化这个数组对应的节点:
```c
static ssize_t buffer_ring_init()
{
int i=0;
for(i=0;i<BUFFER_NUM;i++){
list_array[i]=malloc(sizeof(struct mylist));
INIT_LIST_HEAD(&list_array[i]->list);
list_array[i]->pmem=kzalloc(DATA_BUFFER_SIZE,GFP_KERNEL);
}
return 0;
}
```
5:为下标为i的节点分配实际大小为sizeof(structmylist)的内存
6:初始化该节点的链表
7:为pmem成员从堆中分配一块内存
初始化完毕,链表实际情况如下:
## 节点插入
```c
static ssize_t insert_free_list_all()
{
int i=0;
for(i=0;i<BUFFER_NUM;i++){
list_add(&list_array[i]->list,&free_head);
}
return 0;
}
```
8:用头插法将所有节点插入到free_head链表中
所有节点全部插入free链表后,结构图如下:

遍历链表
虽然可以通过数组遍历链表,但是实际在操作过程中,在链表中各个节点的位置是错乱的。所以最好从借助list节点来查找各个节点。
```c
show_list(&free_head);
show_list(&active_head);
```
代码实现如下:
```c
void show_list(struct list_head *list_head)
{
int i=0;
struct mylist*entry,*tmp;
//判断节点是否为空
if(list_empty(list_head)==true)
{
return;
}
list_for_each_entry_safe(entry,tmp,list_head,list)
{
printf("[%d]=%d\t",i++,entry->number);
if(i%4==0)
{
printf("\n");
}
}
}
```
## 节点移动
将节点从active_head链表移动到free_head链表,有点像生产者消费者模型中的消费者,吃掉资源后,就要把这个节点放置到空闲链表,让生产者能够继续生产数据,所以这两个函数我起名eat、spit,意为吃掉和吐,希望你们不要觉得很怪异。
```c
int eat_node()
{
struct mylist*entry=NULL;
if(list_empty(&active_head)==true)
{
printf("list active_head is empty!-----------\n");
}
entry=list_first_entry(&active_head,struct mylist,list);
printf("\t eat node=%d\n",entry->number);
list_move_tail(&entry->list,&free_head);
}
```
节点移动的思路是:
1. 利用list_empty判断该链表是否为空
2. 利用list_first_entry从active_head链表中查找到一个节点,并用指针entry指向该节点
3. 利用list_move_tail将该节点移入到free_head链表,注意此处不能用list_add,因为这个节点我要从原链表把他删除掉,然后插入到新链表。
将节点从free_head链表移动到active_head链表。
```c
spit_node()
{
struct mylist*entry=NULL;
if(list_empty(&free_head)==true)
{
printf("list free_head is empty!-----------\n");
}
entry=list_first_entry(&free_head,struct mylist,list);
printf("\t spit node=%d\n",entry->number);
list_move_tail(&entry->list,&active_head);
}
```
大部分功能讲解完了,下面我们贴下完整代码。
代码实例
```c
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <byteswap.h>
#include <string.h>
#include <errno.h>
#include <signal.h>
#include <fcntl.h>
#include <ctype.h>
#include <termios.h>
#include <sys/types.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include "list.h" // linux-3.14/scripts/kconfig/list.h
#undef NULL
#define NULL ((void *)0)
enum {
false = 0,
true = 1
};
#define DATA_TYPE 0x14
#define SIG_TYPE 0x15
struct mylist{
int number;
char type;
char *pmem;
struct list_head list;
};
#define FATAL do { fprintf(stderr, "Error at line %d, file %s (%d) [%s]\n",__LINE_,__FILE__,errno,strerror(errno));exit(1);}while(0)
struct list_head active_head;
struct list_head free_head;
#define BUFFER_NUM 10
#define DATA_BUFFER_SIZE 512
struct mylist*list_array[BUFFER_NUM];
int born_number(int number)
{
struct mylist *entry=NULL;
if(list_empty(&free_head)==true)
{
printf("list free_head is empty!----------------\n");
}
entry = list_first_entry(&free_head,struct mylist,list);
entry->type = DATA_TYPE;
entry->number=number;
list_move_tail(&entry->list,&active_head);
}
int eat_node()
{
struct mylist*entry=NULL;
if(list_empty(&active_head)==true)
{
printf("list active_head is empty!-----------\n");
}
entry=list_first_entry(&active_head,struct mylist,list);
printf("\t eat node=%d\n",entry->number);
list_move_tail(&entry->list,&free_head);
}
spit_node()
{
struct mylist*entry=NULL;
if(list_empty(&free_head)==true)
{
printf("list free_head is empty!-----------\n");
}
entry=list_first_entry(&free_head,struct mylist,list);
printf("\t spit node=%d\n",entry->number);
list_move_tail(&entry->list,&active_head);
}
void show_list(struct list_head *list_head)
{
int i=0;
struct mylist*entry,*tmp;
if(list_empty(list_head)==true)
{
return;
}
list_for_each_entry_safe(entry,tmp,list_head,list)
{
printf("[%d]=%d\t",i++,entry->number);
if(i%4==0)
{
printf("\n");
}
}
}
int list_num(struct list_head *list_head)
{
int i=0;
struct mylist *entry,*tmp;
// printf("----------show free list-------------\n");
list_for_each_entry_safe(entry,tmp,list_head,list)
{
i++;
}
return i;
}
static ssize_t buffer_ring_init()
{
int i=0;
for(i=0;i<BUFFER_NUM;i++){
list_array[i]=malloc(sizeof(struct mylist));
INIT_LIST_HEAD(&list_array[i]->list);
list_array[i]->pmem=kzalloc(DATA_BUFFER_SIZE,GFP_KERNEL);
list_add_tail(&list_array[i]->list,&free_head);
}
return 0;
}
static ssize_t insert_free_list_all()
{
int i=0;
for(i=0;i<BUFFER_NUM;i++){
list_add_tail(&list_array[i]->list,&free_head);
}
return 0;
}
static ssize_t buffer_ring_free()
{
int buffer_count=0;
struct mylist*entry=NULL;
for(;buffer_count<BUFFER_NUM;buffer_count++)
{
free(list_array[buffer_count]->pmem);
free(list_array[buffer_count]);
}
return 0;
}
int main(int argc,char**argv)
{
INIT_LIST_HEAD(&free_head);
INIT_LIST_HEAD(&active_head);
buffer_ring_init();
insert_free_list_all();
born_number(1);
born_number(2);
born_number(3);
born_number(4);
born_number(5);
born_number(6);
born_number(7);
born_number(8);
born_number(9);
born_number(10);
printf("\n----------active list[%d]------------\n",list_num(&active_head));
show_list(&active_head);
printf("\n--------------end-----------------\n");
printf("\n----------free list[%d]------------\n",list_num(&free_head));
show_list(&free_head);
printf("\n--------------end-----------------\n");
printf("\n\n active list----------> free list \n");
eat_node();
eat_node();
eat_node();
printf("\n----------active list[%d]------------\n",list_num(&active_head));
show_list(&active_head);
printf("\n--------------end-----------------\n");
printf("\n----------free list[%d]------------\n",list_num(&free_head));
show_list(&free_head);
printf("\n--------------end-----------------\n");
printf("\n\n free list----------> active list \n");
spit_node();
spit_node();
printf("\n----------active list[%d]------------\n",list_num(&active_head));
show_list(&active_head);
printf("\n--------------end-----------------\n");
printf("\n----------free list[%d]------------\n",list_num(&free_head));
show_list(&free_head);
printf("\n--------------end-----------------\n");
}
```
运行结果如下:

list_head短小精悍,读者可以借鉴此文实现其他功能。
参考文档:https://kernelnewbies.org/FAQ/LinkedLists
《Understanding linux kernel》
《Linux device drivers》
list.h比较长,就不在此贴出源码,如果读者想获取这个文件,可以识别下面的二维码填加一口君好友,索取该文件,一口君这还有大量的Linux学习资料。
玩转内核链表list_head,3个超级哇塞的的例子的更多相关文章
- linux内核的双链表list_head、散列表hlist_head
一.双链表list_head 1.基本概念 linux内核提供的标准链表可用于将任何类型的数据结构彼此链接起来. 不是数据内嵌到链表中,而是把链表内嵌到数据对象中. 即:加入链表的数据结构必须包含一个 ...
- Linux 内核链表使用举例
链表数据结构的定义非常简洁: struct list_head { struct list_head *next, *prev; }; list_head结构包括两个指向list_head结构的指针p ...
- Linux内核链表深度分析【转】
本文转载自:http://blog.csdn.net/coding__madman/article/details/51325646 链表简介: 链表是一种常用的数据结构,它通过指针将一系列数据节点连 ...
- Linux设备驱动工程师之路——内核链表的使用【转】
本文转载自:http://blog.csdn.net/forever_key/article/details/6798685 Linux设备驱动工程师之路——内核链表的使用 K-Style 转载请注明 ...
- 深入分析 Linux 内核链表--转
引用地址:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html 一. 链表数据结构简介 链表是一种常用的组织有序数据 ...
- linux内核链表分析
一.常用的链表和内核链表的区别 1.1 常规链表结构 通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个节点的联系.按照指针域的组织以及各个节 ...
- 深入分析 Linux 内核链表
转载:http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/ 一. 链表数据结构简介 链表是一种常用的组织有序数据的数据结构,它通过指 ...
- Linux 内核 链表 的简单模拟(2)
接上一篇Linux 内核 链表 的简单模拟(1) 第五章:Linux内核链表的遍历 /** * list_for_each - iterate over a list * @pos: the & ...
- Linux 内核 链表 的简单模拟(1)
第零章:扯扯淡 出一个有意思的题目:用一个宏定义FIND求一个结构体struct里某个变量相对struc的编移量,如 struct student { int a; //FIND(struct stu ...
- linux内核链表的移植与使用
一. Linux内核链表为双向循环链表,和数据结构中所学链表类似,具体不再细讲.由于在内核中所实现的函数十分经典,所以移植出来方便后期应用程序中的使用. /********************* ...
随机推荐
- 用pm2命令管理你的node项目
文章目录 前言 安装 运行项目 pm2的命令 前言 我在服务器上运行node项目,使用命令nohup npm start &,结果关闭终端之后,进程就会停止,看来nohup也不是万能的后台运行 ...
- LLM推理 - Nvidia TensorRT-LLM 与 Triton Inference Server
1. LLM部署-TensorRT-LLM与Triton 随着LLM越来越热门,LLM的推理服务也得到越来越多的关注与探索.在推理框架方面,tensorrt-llm是非常主流的开源框架,在Nvidia ...
- 在WPF中使用WriteableBitmap对接工业相机及常用操作
写作背景 写这篇文章主要是因为工业相机(海康.大恒等)提供的.NET开发文档和示例程序都是用WinForm项目来说明举例的,而在WPF项目中对图像的使用和处理与在WinForm项目中有很大不同.在Wi ...
- TI AM62x工业开发板规格书(单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F,主频1.4GHz)
1 评估板简介 创龙科技TL62x-EVM是一款基于TI Sitara系列AM62x单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F多核处理器设计的高性能低功耗工业评估板 ...
- n阶前缀和 の 拆解
二阶 \[\sum_{i=l}^{r} \sum^{i}_{j=1} a_j \] \[=\sum_{i=l}^{r} (r-i+1) a_i \] \[=(r+1)\sum_{i=l}^{r} a_ ...
- Web1.0、Web2.0 和 Web3.0 的区别
Web1.0.Web2.0 和 Web3.0 的区别主要体现在以下几个关键方面: 内容创作与交互: Web1.0:内容主要由网站所有者或少数专业人员创建,用户大多只是被动接收信息.例如,早期的雅虎.新 ...
- Nuxt.js头部魔法:轻松自定义页面元信息,提升用户体验
扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长 useHead 函数概述 useHead是一个用于在 Nuxt 应用中自定义页面头部属性的函数.它由Unhead库提供支持,允许开发者以编 ...
- Django 自定义创建密码重置确认页面
要实现上述功能,你需要修改模板文件以添加"忘记密码"链接,并创建新的视图函数来处理密码丢失修改页面.验证和密码修改.下面是你可以进行的步骤: 1. 修改模板文件 在登录页面的表单下 ...
- Raid0创建
实验步骤 步骤1: 确认硬盘 确认你的硬盘设备名. [root@servera ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 ...
- oeasy教您玩转vim - 16 跳到某行
跳到某行 回忆上节课内容 上下行 向 下 是 j 向 上 是 k 上下行首 向 下 到行首非空字符 + 向 上 到行首非空字符 - 这些 motion 都可以加上 [count] 来翻倍 首尾行 首行 ...