Hadoop -- HDFS 读写数据
一、HDFS读写文件过程
1.读取文件过程
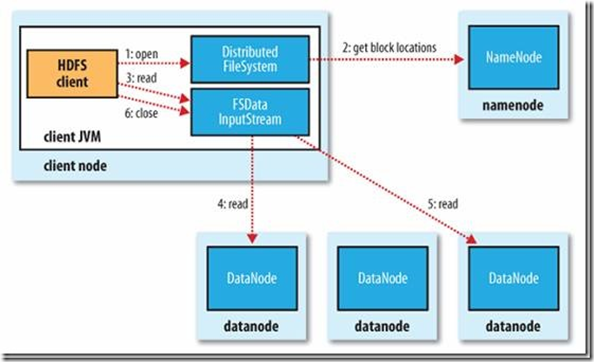
1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
2) FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3) FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
4) DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
5) 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
6) 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
7) 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
8) 失败的数据节点将被记录,以后不再连接。
2.写文件过程
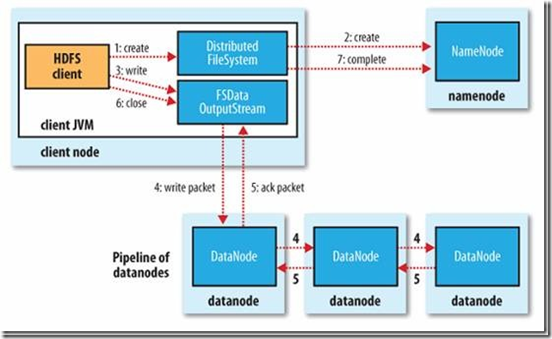
1) 初始化FileSystem,客户端调用create()来创建文件
2) FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
3) FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
4) DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
5) DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
6) 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
7) 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
啦啦啦
Hadoop -- HDFS 读写数据的更多相关文章
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS 读写数据流程
一.上传数据 二.下载数据 三.读写时的节点位置选择 1.网络节点距离(机架感知) 下图中: client 到 DN1 的距离为 4 client 到 NN 的距离为 3 DN1 到 DN2 的距离为 ...
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hdfs读写数据出错
1.Hdfs读数据出错:若在读数据的过程中,客户端和DataNode的通信出现错误,则会尝试连接下一个 包含次文件块的DataNode.同时记录失败的DataNode,此后不再被连接. 2.Hdfs在 ...
- [Hadoop]HDFS机架感知策略
HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和BlockReport信息,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- Hadoop HDFS (3) JAVA訪问HDFS之二 文件分布式读写策略
先把上节未完毕的部分补全,再剖析一下HDFS读写文件的内部原理 列举文件 FileSystem(org.apache.hadoop.fs.FileSystem)的listStatus()方法能够列出一 ...
随机推荐
- linux和CentOS下网卡启动、配置等ifcfg-eth0教程(转自)
转自:http://www.itokit.com/2012/0415/73593.html it 动力总结系统安装好后,通过以下二个步骤就可以让你的系统正常上网(大多正常情况下).步骤1.配置/etc ...
- Android Fragment 详解(未完...)
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. 之前写过一篇关于 Fragment 生命周期的文章 ...
- Android跨进程通信:图文详解 Binder机制 原理
binder原理讲的很详细 https://blog.csdn.net/carson_ho/article/details/73560642
- WinPython
WinPython http://winpython.github.io/
- SimpleCaptcha生成图片验证码内容为乱码
转自:https://blog.csdn.net/wlwlwlwl015/article/details/51482065 前言 报表中发现有中文乱码和中文字体不整齐(重叠)的情况,首先考虑的就是操作 ...
- redis 基本信息查询
在客户端可以用telnet命令 telnet ip port 再输入info 返回如下信息:
- Spark机器学习(5):SVM算法
1. SVM基本知识 SVM(Support Vector Machine)是一个类分类器,能够将不同类的样本在样本空间中进行分隔,分隔使用的面叫做分隔超平面. 比如对于二维样本,分布在二维平面上,此 ...
- Java 基础【17】 异常与自定义异常
1.异常的分类 Throwable 是所有异常类的基类,它包括两个子类:Exception 和 Error. a. 错误 (Error) 错误是无法难通过程序来解决的,所以程序不应该抛出这种类型的对象 ...
- springboot本地读取resources/images没问题,上传到云服务器打成jar包就读取不到问题
//String watermarkfileName = this.getClass().getClassLoader().getResource("images/watermark.png ...
- TLS/HTTPS 证书生成与验证
最近在研究基于ssl的传输加密,涉及到了key和证书相关的话题,走了不少弯路,现在总结一下做个备忘 科普:TLS.SSL.HTTPS以及证书 不少人可能听过其中的超过3个名词,但它们究竟有什么关联呢? ...