DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入
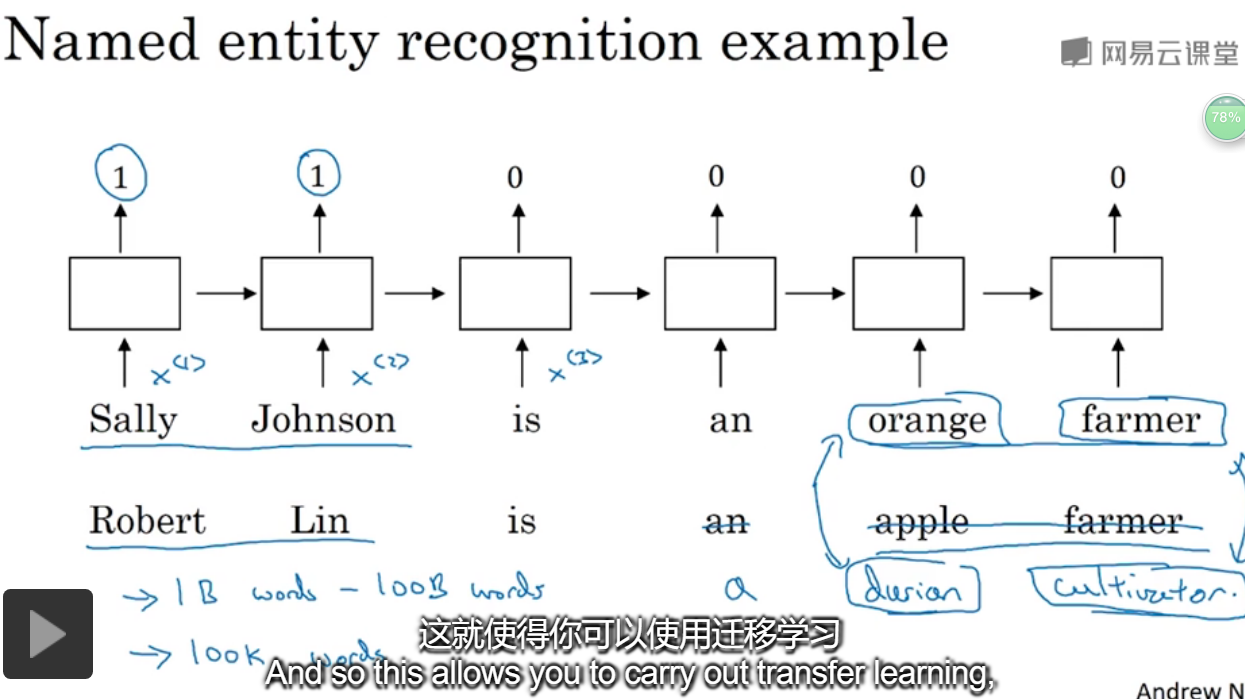
给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名。
但是如果是榴莲种植员可能就无法判断了,因为比较不常见。
此时使用 词嵌入,是一个训练好的模型,能够表示说,oragne和durian是类似的词,farmer和cultivator是同义词。
词向量需要在大量数据上进行训练,此时又谈到了迁移学习。

首先从大的语料库中学习词嵌入,然后将模型运用到小的数据集上,或许还可以从小数据集上更新模型。
2.词嵌入的特征

类比。给出几类名词,并且都有4个特征来表示,对于男人和女人,两个向量相减的结果≈国王-女王,可以发现发现了其中的相似性。对语言可以有更深入的理解。
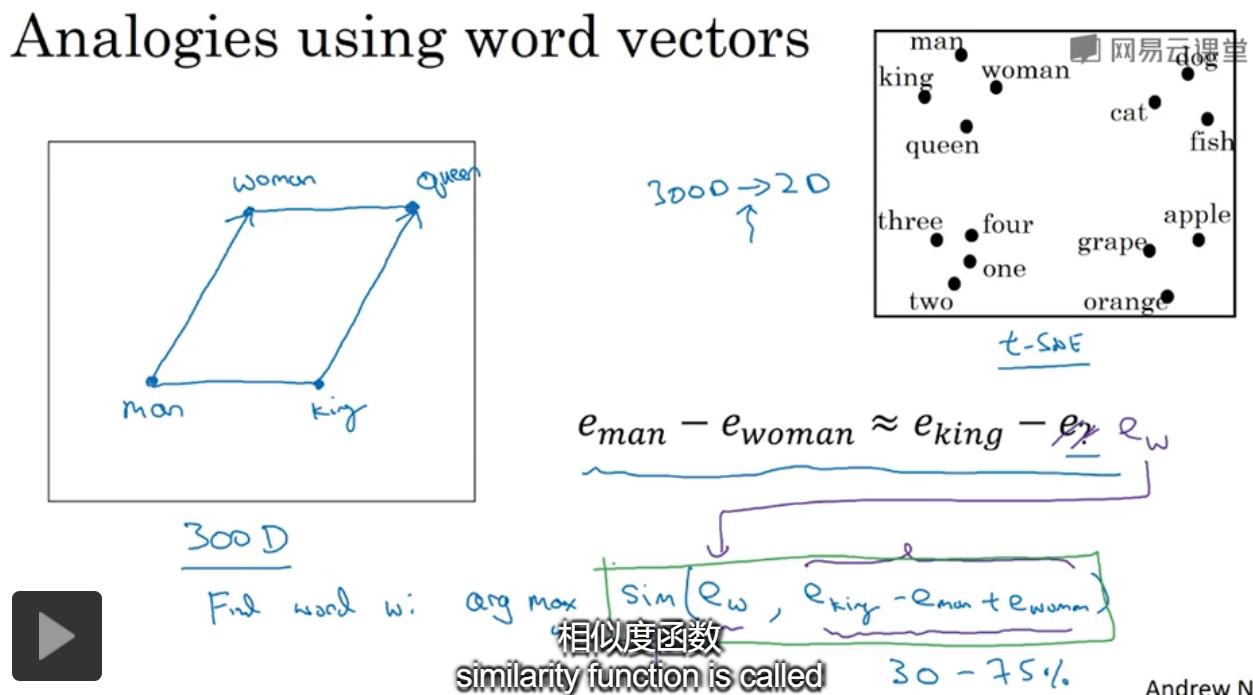
假设在300维的空间中,对于图中,需要找到相似的单词,只需要对所有word遍历,计算给的式子的相似性就可以了。
提到了tsne中,进行数据降到2维是非线性的,就无法保持空间中平行四边形的结果了。

最常用的相似度是cosin,也就是两个向量之间的夹角。
如果在一个足够大的语料库中进行学习,语料库中每个word都有一个向量来表示,这样模型就可以学到很多相似的单词。比如图中给出的。
3.嵌入矩阵
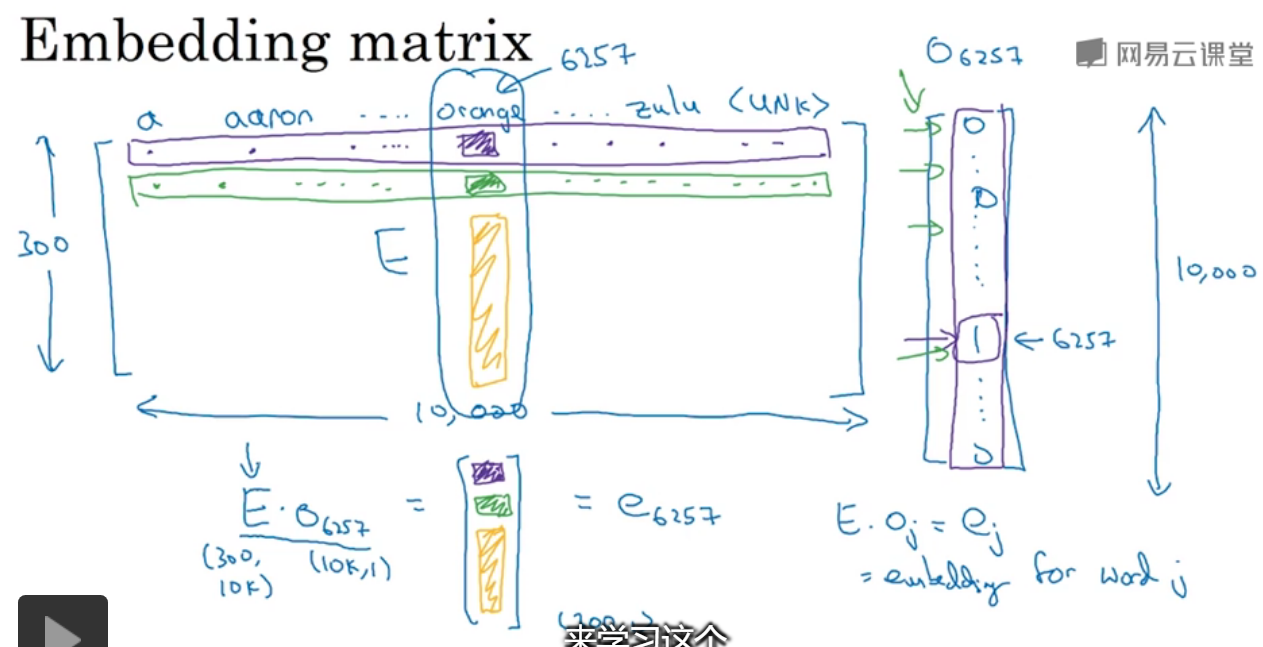
有一个300*10000的特征矩阵,与一个one-hot向量相乘,可得到对应列表示的单词。
由于有大量的0存在,做矩阵运算很耗时,通常会找到one-hot向量中的1值。
在keras中有一个嵌入矩阵,可以从中提取你需要的列,而不是对矩阵进行运算。
4.学习词嵌入

对于一个句子,来预测下一个单词,给出了单词的index,通过E嵌入矩阵,将one-hot转化为300维的向量,那么输入就是6*300维的向量。
通过嵌入矩阵的变换,可能orange\apple\durian\pear等都会由相同的向量来表示。
还可以设置窗口,=4则考虑当前词的前4个来进行预测。

如果要建立一个语言模型,一般选择目标词之前的几个作为上下文;如果要学习词嵌入,可以选择其他的上下文。
被预测的juice被称为target,可以选取不同长度范围的上下文, 只选一个的预测算法被称为skip gram。
//但是到目前为止都没讲到底E是怎么学习得到的?
5.word2vec

假设选取好了上下文为orange,那么随机选择在它的一定范围内的word作为预测target,左右进行选择,是skip-gram主要解决的问题。

假设词典大小为10万,ec是上下文word的嵌入向量,Θt是与输出t有关的参数,即某个词和标签相符的概率???
index[orange]=6257,index[juice]=4834,输入one-hotc并通过E进行转化,然后使用softmax进行预测,y是一个one-hot向量,yhat也是一个形状和y一样的,
并且定义损失函数为交叉熵。softmax能够预测出,下一个单词为字典中每个单词的概率,也就是10万个概率。

这张PPT里讲到了两个点,
1.语料库通常都是非常大的,在计算softmax的分母时,会十分耗时,那么通常的解决办法是分级softmax,通过二叉树进行确定当前单词具体在前多少个(前5k,后5k?)位置,这样求和的范围就会变小了。
这样时间就变为了原来的log级别,通常应用的softmax不是正好二分平衡的,常会根据单词出现的频率而有不同的深度,常出现的就会在低等级,而像durian不常出现就会在下面。
2.如何采样上下文c呢?
如果等概率选,那么出现频率高的就会选中次数很多,从而他们的ec会被常常更新,所以采用不均概率采样。
6.负采样
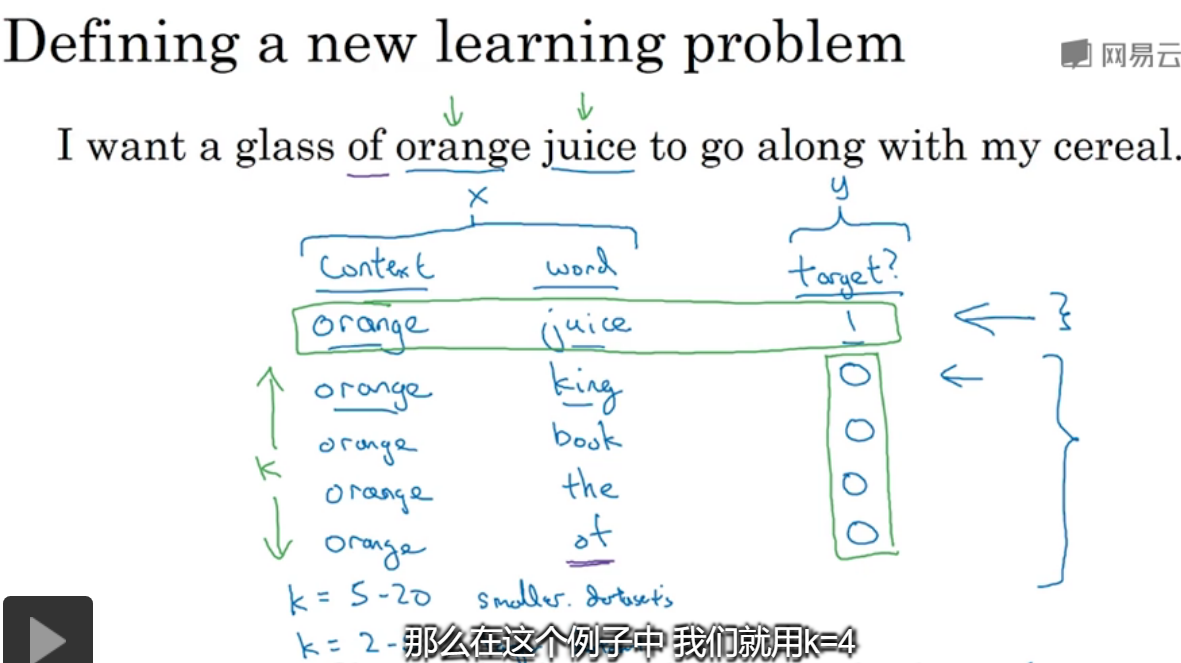
选定了上下文,从词典中随机选取单词word,并且有对应的target值,重复k次,这样就得到了训练集。
对于k的选取,在小数据集中选5-20之间,大数据集是2-5之间。

在x中,context设置为t,word为t,在选中的样本中,正负比为1:K,
那么就可以进行训练,比如对于orange,得到的是一个10000的结果,其中一个就是juice的概率,可以将其视为10000个二元分类器,但并不是每次迭代都训练全部10000个,只需训练其中的5个,其中一个对应juice,令4个(K=4,选取4个负样本时)随机选取的负样本。
转化为10000个二元分类问题,每次训练只需更新其中5个,每一个都比较好计算。

关于如何对负样本采样,根据出现频率/频率的倒数,这样的都是不平均的, 由于语料库中的单词本来就不是平均出现的,所以论文里说最好的选取方法是从根据频率的3/4方,比上所以词频的3/4的和。
7.GloVe词向量

对于xij表示的是i出现在j的上下文中的次数,计数频率,i=t,j=c,在一定范围内任意的word组成的对。
xij=xji,因为是相对来说的。
如何进行优化呢?

就是幻灯片中所表现的内容,没有详细地讲f(xij)函数=0,当xij=0时,对所有word分别作为c和t就最小值,就是优化目标。

//没太明白这张幻灯片在讲什么,整理了公式。
8.情绪分类
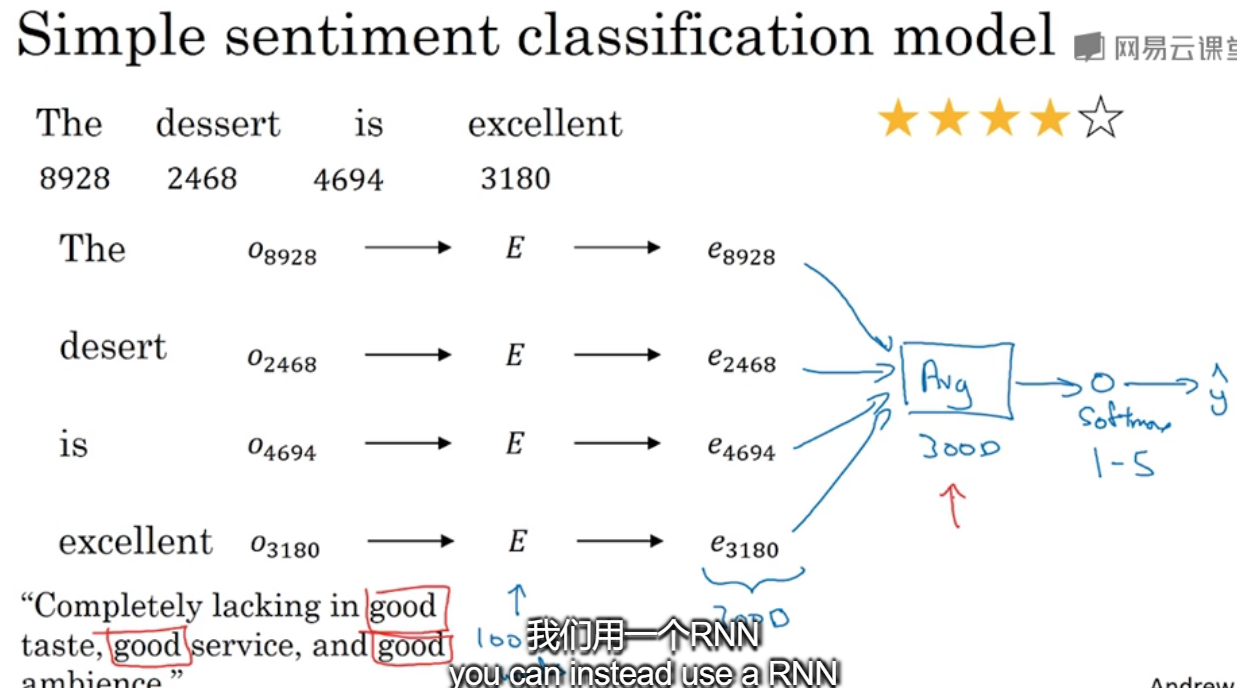
给出了单词的index,通过嵌入矩阵转换为对应的嵌入向量,可以将其求和或者平均输入softmax分类器,最终输出1-5星。
但是这样不考虑词序的话,可能会导致问题,比如左下角的例子,有3个good很可能被判定为好评。那么使用RNN来进行。
9.词嵌入除偏

通过模型进行训练得到的,很可能是存在偏见bias的,比如男人对:程序员,女人对家庭主妇等等。
词嵌入能反映性别、种族、性取向等的歧视。//这还不是从材料中学习到的吗?AI的歧视不是由于人类世界中存在吗?..

如何解决问题,对那些不涉及性别的单词,对在非歧视方向做投影,使他们到性别的举例相等。
DLNg序列模型第二周NLP与词嵌入的更多相关文章
- DLNg序列模型第一周
1.为何选择序列模型? 给出上面一些序列数据的例子,真的很神奇,语音识别.音乐生成.情感分类.DNS序列分析.机器翻译.视频活动检测.命名实体识别. 2.数字符号 对于输入序列x,进行人名识别,输出中 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- deeplearning.ai 序列模型 Week 2 NLP & Word Embeddings
1. Word representation One-hot representation的缺点:把每个单词独立对待,导致对相关词的泛化能力不强.比如训练出“I want a glass of ora ...
- 带你了解NLP的词嵌入
摘要:今天带领大家学习自然语言处理中的词嵌入的内容. 本文分享自华为云社区<[MindSpore易点通]深度学习系列-词嵌入>,作者:Skytier. 1 特征表示 在自然语言处理中,有一 ...
- Deep Learning.ai学习笔记_第五门课_序列模型
目录 第一周 循环序列模型 第二周 自然语言处理与词嵌入 第三周 序列模型和注意力机制 第一周 循环序列模型 在进行语音识别时,给定一个输入音频片段X,并要求输出对应的文字记录Y,这个例子中输入和输出 ...
- 词向量表示:word2vec与词嵌入
在NLP任务中,训练数据一般是一句话(中文或英文),输入序列数据的每一步是一个字母.我们需要对数据进行的预处理是:先对这些字母使用独热编码再把它输入到RNN中,如字母a表示为(1, 0, 0, 0, ...
- TensorFlow NMT的词嵌入(Word Embeddings)
本文转载自:http://blog.stupidme.me/2018/08/05/tensorflow-nmt-word-embeddings/,本站转载出于传递更多信息之目的,版权归原作者或者来源机 ...
- 吴恩达《深度学习》-课后测验-第五门课 序列模型(Sequence Models)-Week 2: Natural Language Processing and Word Embeddings (第二周测验:自然语言处理与词嵌入)
Week 2 Quiz: Natural Language Processing and Word Embeddings (第二周测验:自然语言处理与词嵌入) 1.Suppose you learn ...
- 吴恩达《深度学习》-第五门课 序列模型(Sequence Models)-第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings)-课程笔记
第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings) 2.1 词汇表征(Word Representation) 词汇表示,目 ...
随机推荐
- 设计模式学习--Singleton
What Singleton:保证一个类仅有一个实例,并提供一个访问它的全局访问点. Why Singletion是我比较熟悉的设计模式之一,在平常的开发过程中,也曾几次用到,它主要适用于如下场景: ...
- MySQL主从同步添加至zabbix监控
参考文档:https://blog.csdn.net/hellowidow_2020/article/details/78985368 https://www.cnblogs.com/cdjia ...
- 企业级iptables防火墙实战
iptables生产中在内网一般是关闭的,外围需要开启 大并发情况下,不能开启iptables,会影响性能,使用硬件外网防火墙 学好iptables的基础 1,OSI7层模型以及不同层对应哪些协议 2 ...
- AIX装机问题123
好久没有实施,好记性不如好笔记,那就记录下吧 1文件系统创建挂载 通过smit工具很容易简单举例创建一个jfs2类型文件系统并挂载 创建lv smit mklv 创建jfs2类型文件系统 指定lv s ...
- sklearn.utils.shuffle-训练数据打乱的最佳方法
在进行模型训练前,我们要将数据打乱,以获得更好的训练效果.可以使用sklearn.utils中的shuffle,获得打乱后的数据索引,最后,迭代生成打乱后的batch数据,一个写好的模块如下. 思路是 ...
- hive归档分区
归档hive历史分区不会减少hdfs存储空间,但是可以有效减轻hadoop namenode的压力,尤其在于小文件比较多的情况下. $mkdir $HIVE_HOME/auxlib $ cp /opt ...
- lame音频编码注意的点
1.注意每次编码的PCM数据不能太短,如果太短编码函数长期返回-1这样的错误,将导致编码器彻底失效程序奔溃的问题,经测试32000在3200下稳定,大概1/10码率是没有问题的,具体请自行查询或调试 ...
- centos 安装oracle 报Checking swap space: 0 MB available, 150 MB required. Failed <<<<
1 系统环境 centos 6.5 oracle 11g 内存 16G 硬盘 ssd 250G 2 运行安装命令: [oracle@localhost database]$ ./runInstalle ...
- Flink - TypeInformation
Flink 自己创建一套独立的类型系统, 参考, https://ci.apache.org/projects/flink/flink-docs-release-0.10/internals/type ...
- 转:JAVA中解决Filter过滤掉css,js,图片文件等问题
原文链接:https://www.cnblogs.com/ermeng/p/6440966.html public void doFilter(ServletRequest request, Serv ...