(原)MobileNetV2
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/9410574.html
论文:
MobileNetV2: Inverted Residuals and Linear Bottlenecks
网址:
https://arxiv.org/abs/1801.04381
代码:
官方的tensorflow代码:
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
非官方的pytorch代码:
https://github.com/tonylins/pytorch-mobilenet-v2
参考网址:
https://blog.csdn.net/u011995719/article/details/79135818
https://github.com/Randl/MobileNetV2-pytorch/blob/master/model.py#L54
1. 深度可分离卷积
2. 线性瓶颈层(linear bottlenecks)
mobileNetV2使用了线性瓶颈层。原因是,当使用ReLU等激活函数时,会导致信息丢失。如下图所示,低维(2维)的信息嵌入到n维的空间中,并通过随机矩阵T对特征进行变换,之后再加上ReLU激活函数,之后在通过T-1进行反变换。当n=2,3时,会导致比较严重的信息丢失,部分特征重叠到一起了;当n=15到30时,信息丢失程度降低,但是变换矩阵已经是高度非凸的了。
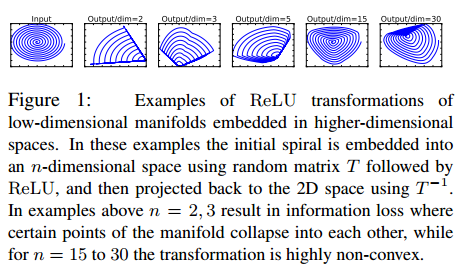
由于非线性层会毁掉一部分信息,因而非常有必要使用线性瓶颈层。且线性瓶颈层包含所有的必要信息,扩张层则是供非线性层丰富信息使用。
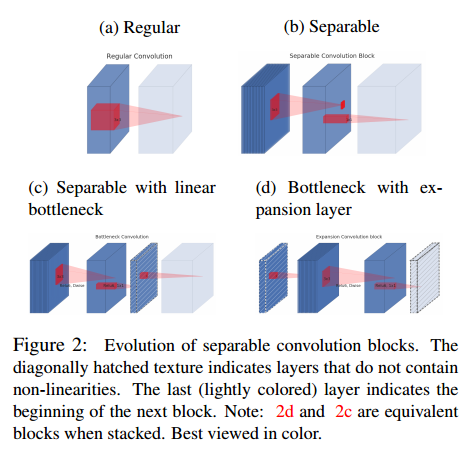
下图对比了不同的卷积方式,其中颜色最浅的代表下一个块(本块输出,下块输入)。带斜杠的为不包含ReLU等非线性激活函数的层。传统的卷积如(a)所示,输入和输出维度不一样,且卷积核直接对输入的红色立方体进行滤波。(b)为可分离卷积,左侧3*3卷积的每个卷积核只对输入的对应层进行滤波,此时特征维度不变;右边的1*1的卷积对特征进行升维或者降维(图中为升维)。(c)中为带线性瓶颈层的可分离卷积,输入通过3*3 depthwise卷积+ReLU6,得到中间相同维度的特征。之后在通过1*1conv+ReLU6,得到降维后的特征(带斜线立方体)。之后在通过1*1卷积(无ReLU)进行升维。(d)中则是维度比较低的特征,先通过1*1conv(无ReLU)升维,而后通过3*3 depthwise卷积+ReLU6保持特征数量不变,再通过1*1conv+ReLU6得到降维后的下一层特征(下一层特征在升维时,无ReLU,因而图中最右边立方体带斜线)。
说明:(b)不太确定,因为如果左侧3*3的卷积为depthwise convolution的话,左侧红色矩形映射到中间应该是一个点,和(c)一样,但是(b)中出现了一个方框,不太懂。。。
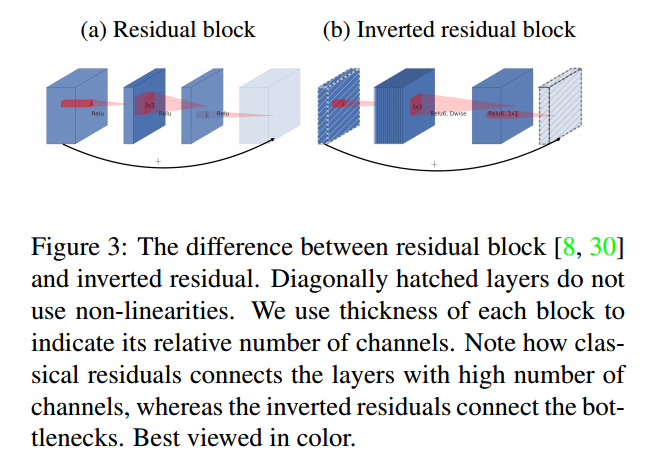
文中提出了反转残差块(inverted residual block)的概念。下图显示了传统的残差块和反转残差块的区别。传统的残差块如(a)将高维特征先使用1*1conv降维,然后在使用3*3conv进行滤波,并使用1*1conv进行升维(这些卷积中均包含ReLU),得到输出特征(下一层的输入),并进行element wise的相加。反转残差块则是将低维特征使用1*1conv升维(不含ReLU),而后使用3*3conv+ReLU对特征进行滤波,并使用1*1conv+ReLU对特征再降维,得到本层特征的输出(即下一层特征的输入,由于下一层的输入在使用1*1conv升维时,无ReLU,因而最右边的立方体带斜线),并进行element wise的相加。
反转的原因,上面已经提到,瓶颈层的输入包含了所有的必要信息,因而右侧最左边的层后面不加ReLU,防止信息丢失。升维后,信息更加丰富,此时加上ReLU,之后在降维,理论上可以保持所有的必要信息不丢失。
为何使用ReLU?使用ReLU可以增加模型的稀疏性。过于稀疏了,信息就丢失了。。。
那瓶颈层内部为何需要升维呢?原因是为了增加模型的表达能力(不确定这样理解是否正确):当使用ReLU对某通道的信息进行处理后,该通道会不可避免的丢失信息;然而如果有足够多的通道的话,某通道丢失的信息,可能仍旧保留在其他通道中,因而才会在瓶颈层内部对特征进行升维。文中附录证明了,瓶颈层内部升维足够大时,能够抵消ReLU造成的信息丢失(如文中将特征维度扩大了6倍)。
瓶颈层的具体结构如下表所示。输入通过1*1的conv+ReLU层将维度从k维增加到tk维,之后通过3*3conv+ReLU可分离卷积对图像进行降采样(stride>1时),此时特征维度已经为tk维度,最后通过1*1conv(无ReLU)进行降维,维度从tk降低到k’维。
需要注意的是,除了整个模型中的第一个瓶颈层的t=1之外,其他瓶颈层t=6(论文中Table 2),即第一个瓶颈层内部并不对特征进行升维。

另外,对于瓶颈层,当stride=1时,才会使用elementwise 的sum将输入和输出特征连接(如下图左侧);stride=2时,无short cut连接输入和输出特征(下图右侧)。

3. 网络模型
MobileNetV2的模型如下图所示,其中t为瓶颈层内部升维的倍数,c为特征的维数,n为该瓶颈层重复的次数,s为瓶颈层第一个conv的步幅。
需要注意的是:
1) 当n>1时(即该瓶颈层重复的次数>1),只在第一个瓶颈层stride为对应的s,其他重复的瓶颈层stride均为1
2) 只在stride=1时,输出特征尺寸和输入特征尺寸一致,才会使用elementwise sum将输出与输入相加
3) 当n>1时,只在第一个瓶颈层特征维度为c,其他时候channel不变。
例如,对于该图中562*24的那层,共有3个该瓶颈层,只在第一个瓶颈层使用stride=2,后两个瓶颈层stride=1;第一个瓶颈层由于输入和输出尺寸不一致,因而无short cut连接,后两个由于stride=1,输入输出特征尺寸一致,会使用short cut将输入和输出特征进行elementwise的sum;只在第一个瓶颈层最后的1*1conv对特征进行升维,后两个瓶颈层输出维度不变(不要和瓶颈层内部的升维弄混了)。
该层输入特征为56*56*24,第一个瓶颈层输出为28*28*32(特征尺寸降低,特征维度增加,无short cut),第二个、第三个瓶颈层输入和输出均为28*28*32(此时c=32,s=1,有short cut)。
另外,下表中还有一个k。MobileNetV1中提出了宽度缩放因子,其作用是在整体上对网络的每一层维度(特征数量)进行瘦身。MobileNetV2中,当该因子<1时,最后的那个1*1conv不进行宽度缩放;否则进行宽度缩放。

4. pytorch代码
import torch.nn as nn
import math def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
) def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
) class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2] self.use_res_connect = self.stride == 1 and inp == oup self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(inp * expand_ratio, inp * expand_ratio, 3, stride, 1, groups=inp * expand_ratio, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
) def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x) class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
# setting of inverted residual blocks
self.interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
] # building first layer
assert input_size % 32 == 0
input_channel = int(32 * width_mult)
self.last_channel = int(1280 * width_mult) if width_mult > 1.0 else 1280
self.features = [conv_bn(3, input_channel, 2)]
# building inverted residual blocks
for t, c, n, s in self.interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(InvertedResidual(input_channel, output_channel, s, t))
else:
self.features.append(InvertedResidual(input_channel, output_channel, 1, t))
input_channel = output_channel
# building last several layers
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
self.features.append(nn.AvgPool2d(input_size/32))
# make it nn.Sequential
self.features = nn.Sequential(*self.features) # building classifier
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(self.last_channel, n_class),
) self._initialize_weights() def forward(self, x):
x = self.features(x)
x = x.view(-1, self.last_channel)
x = self.classifier(x)
return x def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
(原)MobileNetV2的更多相关文章
- 【原】谈谈对Objective-C中代理模式的误解
[原]谈谈对Objective-C中代理模式的误解 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 这篇文章主要是对代理模式和委托模式进行了对比,个人认为Objective ...
- 【原】FMDB源码阅读(三)
[原]FMDB源码阅读(三) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 FMDB比较优秀的地方就在于对多线程的处理.所以这一篇主要是研究FMDB的多线程处理的实现.而 ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- 【原】FMDB源码阅读(二)
[原]FMDB源码阅读(二) 本文转载请注明出处 -- polobymulberry-博客园 1. 前言 上一篇只是简单地过了一下FMDB一个简单例子的基本流程,并没有涉及到FMDB的所有方方面面,比 ...
- 【原】FMDB源码阅读(一)
[原]FMDB源码阅读(一) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 说实话,之前的SDWebImage和AFNetworking这两个组件我还是使用过的,但是对于 ...
- 【原】AFNetworking源码阅读(六)
[原]AFNetworking源码阅读(六) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 这一篇的想讲的,一个就是分析一下AFSecurityPolicy文件,看看AF ...
- 【原】AFNetworking源码阅读(五)
[原]AFNetworking源码阅读(五) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇中提及到了Multipart Request的构建方法- [AFHTTP ...
- 【原】AFNetworking源码阅读(四)
[原]AFNetworking源码阅读(四) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇还遗留了很多问题,包括AFURLSessionManagerTaskDe ...
随机推荐
- [SDOI2012]象棋
题解: sd的题目也真是奇怪 第一题有了最短路第二题还有 第二题有了网络流第三题还有 显然是可以网络流的 但考虑每个点只能存在一个这个条件 刚开始我以为是建分层图..但发现这个时间复杂度太高了 其实我 ...
- Unity 之 Game视图不显示
如果你确认的Scene视图没有问题,试着检查一下 物体的Layer 与 camera的Culling mask是否一致,或者说camera的Culling mask中是否包含物体的layer 这是相机 ...
- Loader监听数据源的变化
步骤: 1.新建一个继承SQLiteOpenHelper的帮助类 2.在MainActivity中定义LoaderManager和SimpleCursorAdapter 3.按顺序重写如下方法:ini ...
- 如何使用redis设计关系数据库
目录 redis设计关系数据库 前言 设计用户信息表结构 hash存储记录 set存储id 图示 索引/查询: 1.select 查询所有记录 : 类似sql的select from table_na ...
- 免费的ASP.NET空间和SQLServer2008 Express
Login Register Web Hosting Support Forum Ask Experts Articles ASP.NET 4.5 & SQL 2012 Hosting P ...
- 网页图表Highcharts实践教程之图表代码构成
网页图表Highcharts实践教程之图表代码构成 Highcharts第一个实例 下面我们来实现本书的第一个Highcharts实例. [实例1-1]下面来制作北京连续一周最高温度折线图.操作过程如 ...
- mac下配置Apache虚拟域名方案,以及遇到的坑
1. 配置Apache虚拟域名 1.执行 sudo vi /etc/apache2/httpd.conf 开始配置httpd.conf 的文件; //配置listen 80端口(默认配置), ...
- {}+[]与console.log({}+[])结果不同?从JavaScript的大括号谈起
看到这样一个问题:为什么直接在控制台运行{} + []和用console.log({} + [])输出,两者结果不一样? 于是乎打开chrome的控制台运行了一下: 为什么结果会这样呢?不得已学习一下 ...
- idea 开发插件。
作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱:313134555@qq.com E-mail: 313134555 @qq.com idea 开发插件. Intellij ID ...
- bzoj4946: [Noi2017]蔬菜 神烦贪心
题目链接 bzoj4946: [Noi2017]蔬菜 题解 挺神的贪心 把第次买的蔬菜拆出来,记下每种蔬菜到期的日期,填第一单位蔬菜比其他的要晚 按价格排序后,贪心的往前面可以填的位置填就可以了.找可 ...