Spring Boot下Druid连接池+mybatis
目前Spring Boot中默认支持的连接池有dbcp,dbcp2, hikari三种连接池。
引言: 在Spring Boot下默认提供了若干种可用的连接池,Druid来自于阿里系的一个开源连接池,在连接池之外,还提供了非常优秀的监控功能,这里讲解如何与Spring Boot实现集成。
1. 环境描述
Spring Boot 1.4.0.RELEASE, JDK 1.8
2. Druid介绍
Druid是一个JDBC组件,它包括三部分:
- DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。
- DruidDataSource 高效可管理的数据库连接池。
- SQLParser
Druid可以做什么?
- 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
- 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
- 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
- SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
- 扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
项目地址: https://github.com/alibaba/druid
3. Spring Boot与Druid的集成
MySQL Driver驱动包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
Spring Boot的JPA依赖包:
阿里系的Druid依赖包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.25</version>
</dependency>
Spring Boot中的application.properties配置信息:
# 驱动配置信息
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url = jdbc:mysql://127.0.0.1:3306/mealsystem?useUnicode=true&characterEncoding=utf-8
spring.datasource.username = root
spring.datasource.password = 123456
spring.datasource.driverClassName = com.mysql.jdbc.Driver #连接池的配置信息
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
spring.datasource.maxWait=60000
spring.datasource.timeBetweenEvictionRunsMillis=60000
spring.datasource.minEvictableIdleTimeMillis=300000
spring.datasource.validationQuery=SELECT 1 FROM DUAL
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
spring.datasource.filters=stat,wall,log4j
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
在Spring Boot1.4.0中驱动配置信息没有问题,但是连接池的配置信息不再支持这里的配置项,即无法通过配置项直接支持相应的连接池;这里列出的这些配置项可以通过定制化DataSource来实现。
由于Druid暂时不在Spring Bootz中的直接支持,故需要进行配置信息的定制:
DruidDBConfig类被@Configuration标注,用作配置信息; DataSource对象被@Bean声明,为Spring容器所管理, @Primary表示这里定义的DataSource将覆盖其他来源的DataSource。
# 下面为连接池的补充设置,应用到上面所有数据源中 # 初始化大小,最小,最大 spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # 配置获取连接等待超时的时间 spring.datasource.maxWait=60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 spring.datasource.timeBetweenEvictionRunsMillis=60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 1 FROM DUAL spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # 打开PSCache,并且指定每个连接上PSCache的大小 spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 spring.datasource.filters=stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 合并多个DruidDataSource的监控数据 #spring.datasource.useGlobalDataSourceStat=true
需要注意的是:spring.datasource.type旧的spring boot版本是不能识别的。
配置StatView的Servlet
Filter的实现类:
StatViewServlet:
这两个类相当于在web.xml中声明了一个servlet, 等价于如下的配置信息(web.xml):
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
filter的配置信息:
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
然后相应的配置工作就完成了,直接启动即可看到相应的应用了。
4. 运行界面以及介绍
访问地址: http://localhost:8080/druid/
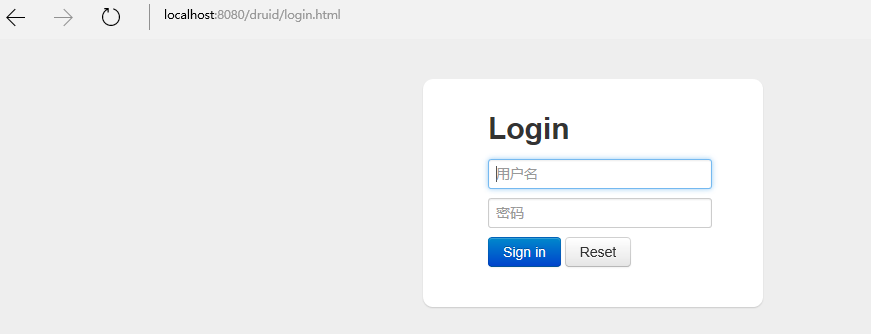
输入上面配置的密码:admin/123456
跳转到durid的监控界面:
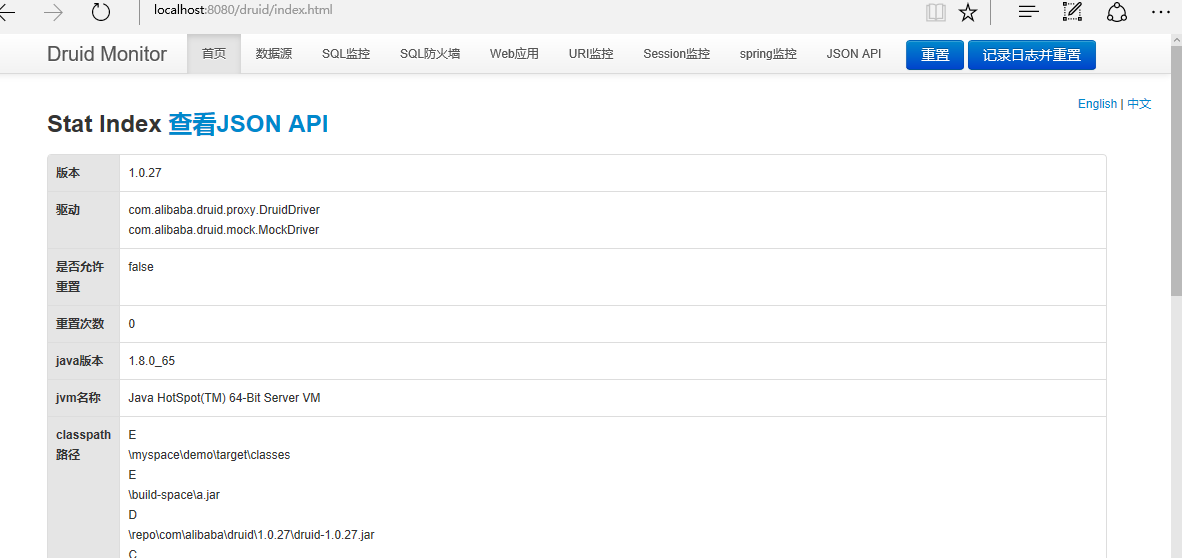
说明:
servlet参数说明:
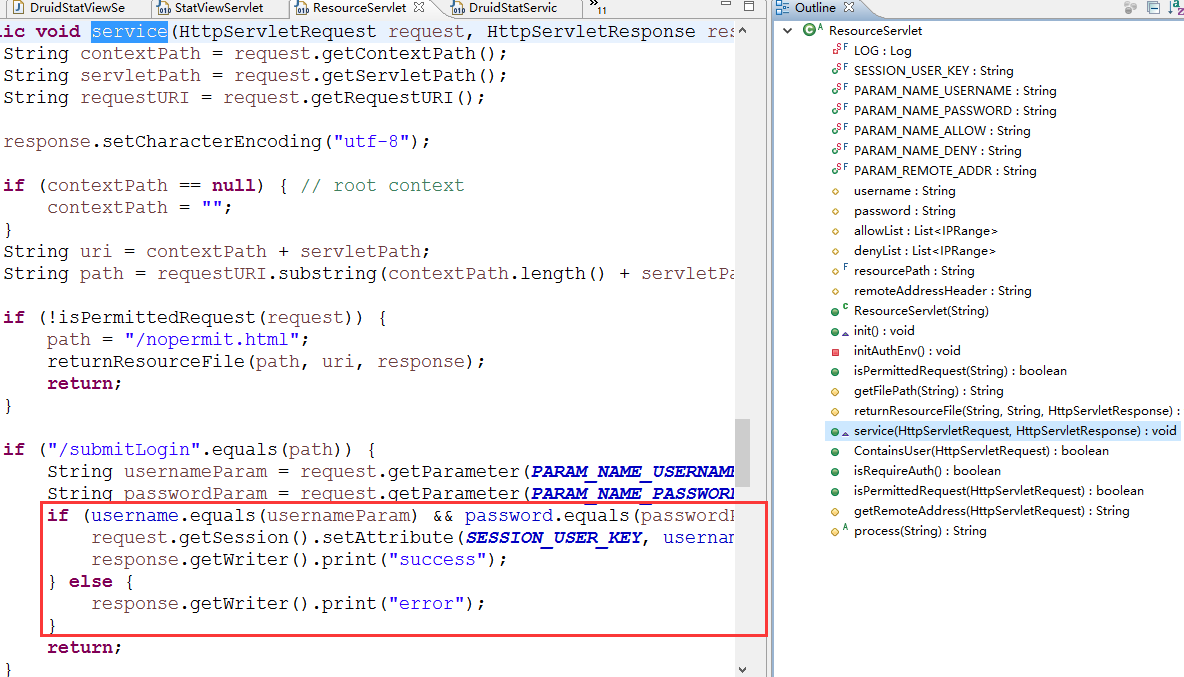
1、loginUsername和loginPassword
上面的账号及密码校验的代码在ResourceServlet.java中
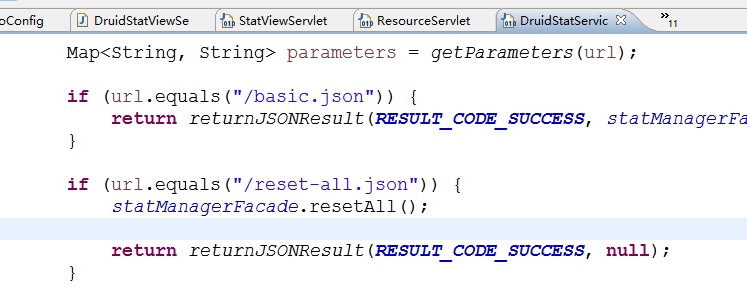
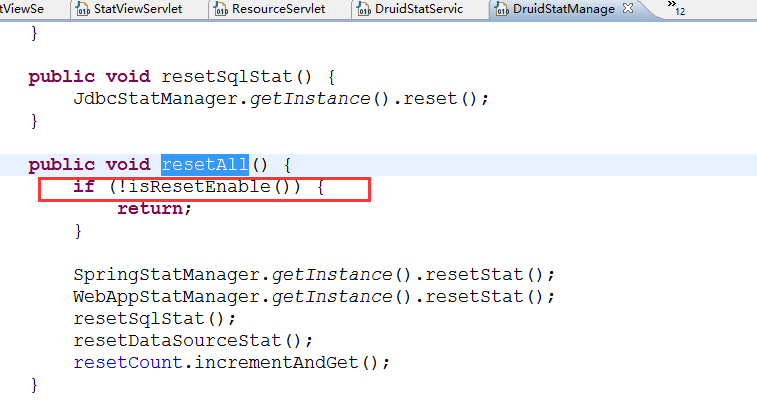
2、resetEnable参数,在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,会导致所有计数器清零,重新计数。你可以通过配置参数关闭它。(页面上的按钮还是可见的,但不会重置清空各类计数)
1.1 配置监控页面访问密码
需要配置Servlet的 loginUsername 和 loginPassword这两个初始参数。
具体可以参考: 为Druid监控配置访问权限(配置访问监控信息的用户与密码)
示例如下:
<!-- 配置 Druid 监控信息显示页面 -->
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<!-- 允许清空统计数据 -->
<param-name>resetEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 用户名 -->
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<!-- 密码 -->
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
2. 配置allow和deny
StatViewSerlvet展示出来的监控信息比较敏感,是系统运行的内部情况,如果你需要做访问控制,可以配置allow和deny这两个参数。比如:
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<param-name>allow</param-name>
<param-value>128.242.127.1/24,128.242.128.1</param-value>
</init-param>
<init-param>
<param-name>deny</param-name>
<param-value>128.242.127.4</param-value>
</init-param>
</servlet>
判断规则
- deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。
- 如果allow没有配置或者为空,则允许所有访问
ip配置规则
配置的格式
<IP>
或者
<IP>/<SUB_NET_MASK_size>
其中
128.242.127.1/24
24表示,前面24位是子网掩码,比对的时候,前面24位相同就匹配。
不支持IPV6
由于匹配规则不支持IPV6,配置了allow或者deny之后,会导致IPV6无法访问。
3. 配置resetEnable
在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,会导致所有计数器清零,重新计数。你可以通过配置参数关闭它。
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<param-name>resetEnable</param-name>
<param-value>false</param-value>
</init-param>
</servlet>二、mybatis-spring-boot-starter
官方说明:MyBatis Spring-Boot-Starter will help you use MyBatis with Spring Boot
其实就是myBatis看spring boot这么火热也开发出一套解决方案来凑凑热闹,但这一凑确实解决了很多问题,使用起来确实顺畅了许多。mybatis-spring-boot-starter主要有两种解决方案,一种是使用注解解决一切问题,一种是简化后的老传统。
当然任何模式都需要首先引入mybatis-spring-boot-starter的pom文件,现在最新版本是1.1.1(刚好快到双11了 :))
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>
好了下来分别介绍两种开发模式
无配置文件注解版
就是一切使用注解搞定。
1 添加相关maven文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
完整的pom包这里就不贴了,大家直接看源码
2、application.properties 添加相关配置
mybatis.type-aliases-package=com.neo.entity spring.datasource.driverClassName = com.mysql.jdbc.Driver
spring.datasource.url = jdbc:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=utf-8
spring.datasource.username = root
spring.datasource.password = root
springboot会自动加载spring.datasource.*相关配置,数据源就会自动注入到sqlSessionFactory中,sqlSessionFactory会自动注入到Mapper中,对了你一切都不用管了,直接拿起来使用就行了。
在启动类中添加对mapper包扫描@MapperScan
@SpringBootApplication
@MapperScan("com.neo.mapper")
public class Application { public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
或者直接在Mapper类上面添加注解@Mapper,建议使用上面那种,不然每个mapper加个注解也挺麻烦的
3、开发Mapper
第三步是最关键的一块,sql生产都在这里
public interface UserMapper {
@Select("SELECT * FROM users")
@Results({
@Result(property = "userSex", column = "user_sex", javaType = UserSexEnum.class),
@Result(property = "nickName", column = "nick_name")
})
List<UserEntity> getAll();
@Select("SELECT * FROM users WHERE id = #{id}")
@Results({
@Result(property = "userSex", column = "user_sex", javaType = UserSexEnum.class),
@Result(property = "nickName", column = "nick_name")
})
UserEntity getOne(Long id);
@Insert("INSERT INTO users(userName,passWord,user_sex) VALUES(#{userName}, #{passWord}, #{userSex})")
void insert(UserEntity user);
@Update("UPDATE users SET userName=#{userName},nick_name=#{nickName} WHERE id =#{id}")
void update(UserEntity user);
@Delete("DELETE FROM users WHERE id =#{id}")
void delete(Long id);
}
为了更接近生产我特地将user_sex、nick_name两个属性在数据库加了下划线和实体类属性名不一致,另外user_sex使用了枚举
- @Select 是查询类的注解,所有的查询均使用这个
- @Result 修饰返回的结果集,关联实体类属性和数据库字段一一对应,如果实体类属性和数据库属性名保持一致,就不需要这个属性来修饰。
- @Insert 插入数据库使用,直接传入实体类会自动解析属性到对应的值
- @Update 负责修改,也可以直接传入对象
- @delete 负责删除
注意,使用#符号和$符号的不同:
// This example creates a prepared statement, something like select * from teacher where name = ?;
@Select("Select * from teacher where name = #{name}")
Teacher selectTeachForGivenName(@Param("name") String name); // This example creates n inlined statement, something like select * from teacher where name = 'someName';
@Select("Select * from teacher where name = '${name}'")
Teacher selectTeachForGivenName(@Param("name") String name);
4、使用
上面三步就基本完成了相关dao层开发,使用的时候当作普通的类注入进入就可以了
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserMapperTest { @Autowired
private UserMapper UserMapper; @Test
public void testInsert() throws Exception {
UserMapper.insert(new UserEntity("aa", "a123456", UserSexEnum.MAN));
UserMapper.insert(new UserEntity("bb", "b123456", UserSexEnum.WOMAN));
UserMapper.insert(new UserEntity("cc", "b123456", UserSexEnum.WOMAN)); Assert.assertEquals(3, UserMapper.getAll().size());
} @Test
public void testQuery() throws Exception {
List<UserEntity> users = UserMapper.getAll();
System.out.println(users.toString());
} @Test
public void testUpdate() throws Exception {
UserEntity user = UserMapper.getOne(3l);
System.out.println(user.toString());
user.setNickName("neo");
UserMapper.update(user);
Assert.assertTrue(("neo".equals(UserMapper.getOne(3l).getNickName())));
}
}
源码中controler层有完整的增删改查,这里就不贴了
源码在这里spring-boot-mybatis-annotation
极简xml版本
极简xml版本保持映射文件的老传统,优化主要体现在不需要实现dao的是实现层,系统会自动根据方法名在映射文件中找对应的sql.
1、配置
pom文件和上个版本一样,只是application.properties新增以下配置
mybatis.config-locations=classpath:mybatis/mybatis-config.xml
mybatis.mapper-locations=classpath:mybatis/mapper/*.xml
指定了mybatis基础配置文件和实体类映射文件的地址
mybatis-config.xml 配置
<configuration>
<typeAliases>
<typeAlias alias="Integer" type="java.lang.Integer" />
<typeAlias alias="Long" type="java.lang.Long" />
<typeAlias alias="HashMap" type="java.util.HashMap" />
<typeAlias alias="LinkedHashMap" type="java.util.LinkedHashMap" />
<typeAlias alias="ArrayList" type="java.util.ArrayList" />
<typeAlias alias="LinkedList" type="java.util.LinkedList" />
</typeAliases>
</configuration>
这里也可以添加一些mybatis基础的配置
2、添加User的映射文件
<mapper namespace="com.neo.mapper.UserMapper" >
<resultMap id="BaseResultMap" type="com.neo.entity.UserEntity" >
<id column="id" property="id" jdbcType="BIGINT" />
<result column="userName" property="userName" jdbcType="VARCHAR" />
<result column="passWord" property="passWord" jdbcType="VARCHAR" />
<result column="user_sex" property="userSex" javaType="com.neo.enums.UserSexEnum"/>
<result column="nick_name" property="nickName" jdbcType="VARCHAR" />
</resultMap> <sql id="Base_Column_List" >
id, userName, passWord, user_sex, nick_name
</sql> <select id="getAll" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
</select> <select id="getOne" parameterType="java.lang.Long" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
WHERE id = #{id}
</select> <insert id="insert" parameterType="com.neo.entity.UserEntity" >
INSERT INTO
users
(userName,passWord,user_sex)
VALUES
(#{userName}, #{passWord}, #{userSex})
</insert> <update id="update" parameterType="com.neo.entity.UserEntity" >
UPDATE
users
SET
<if test="userName != null">userName = #{userName},</if>
<if test="passWord != null">passWord = #{passWord},</if>
nick_name = #{nickName}
WHERE
id = #{id}
</update> <delete id="delete" parameterType="java.lang.Long" >
DELETE FROM
users
WHERE
id =#{id}
</delete>
</mapper>
其实就是把上个版本中mapper的sql搬到了这里的xml中了
3、编写Dao层的代码
public interface UserMapper {
List<UserEntity> getAll();
UserEntity getOne(Long id);
void insert(UserEntity user);
void update(UserEntity user);
void delete(Long id);
}
对比上一步这里全部只剩了接口方法
springcloud应用,应用被阻塞住,用jstack看线程栈信息如下:
然后使用jstack -l 10>>dump.out 拿到当前堆栈快照后发现如下
"Thread-131" #404 prio=5 os_prio=0 tid=0x00007fe16823f000 nid=0x1d0 waiting on condition [0x00007fe15d79d000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000ad377df8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at com.alibaba.druid.pool.DruidDataSource.takeLast(DruidDataSource.java:1518)
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1143)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1014)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:994)
所有的请求都被druid的获取连接操作阻塞了,最后看源码如下

因为数据链接没有释放,连接池中无可用连接,导致请求被阻塞了
到这里基本上就是真相了,最后换成spring boot自带的连接池tomcat jdbc后一切正常
后记:
定位到问题后,发现网上很多人遇到了连接泄露的情况,可见druid的官方issue,如https://github.com/alibaba/druid/issues/1160
不过druid也提供了相应的方案,如下

虽然官方说可能是应用自己导致连接未被释放导致连接泄露,但是为什么切换别家的连接池后就毛事都没有呢?
Spring Boot下Druid连接池+mybatis的更多相关文章
- Spring Boot下Druid连接池的使用配置分析
https://blog.csdn.net/blueheart20/article/details/52384032
- spring boot配置druid连接池连接mysql
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Spring Boot使用Druid连接池基本配置
以下为Spring Boot配置Druid 一.pom.xml配置 <dependency> <groupId>com.alibaba</groupId> < ...
- Spring Boot 添加Druid连接池(1.5 版本)
Druid是一个关系型数据库连接池,是阿里巴巴的一个开源项目,地址:https://github.com/alibaba/druid .Druid不但提供连接池的功能,还提供监控功能,可以实时查看数据 ...
- Spring Boot [使用 Druid 数据库连接池]
导读 最近一段时间比较忙,以至于很久没有更新Spring Boot系列文章,恰好最近用到Druid, 就将Spring Boot 使用 Druid作为数据源做一个简单的介绍. Druid介绍: Dru ...
- Spring Boot之默认连接池配置策略
注意:如果我们使用spring-boot-starter-jdbc 或 spring-boot-starter-data-jpa “starters”坐标,Spring Boot将自动配置Hikari ...
- Spring Boot集成Druid数据库连接池
1. 前言 Druid数据库连接池由阿里巴巴开源,号称是java语言中最好的数据库连接池,是为监控而生的.Druid的官方地址是:https://github.com/alibaba/druid 通过 ...
- 深入理解Spring Boot数据源与连接池原理
Create by yster@foxmail.com 2018-8-2 一:开始 在使用Spring Boot数据源之前,我们一般会导入相关依赖.其中数据源核心依赖就是spring‐boot‐s ...
- SpringBoot下Druid连接池的使用配置
Druid是一个JDBC组件,druid 是阿里开源在 github 上面的数据库连接池,它包括三部分: * DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体 ...
随机推荐
- 启动tomcat报错:Failed to start component [StandardEngine[Catalina].StandardHost[localhost]
1.右键点击需要启动的tomcat,选择Clean和Clean Tomcat Work Directory,清除即可!
- python str使用笔记(更新)
判断字符串是否以某个串为结尾: str.endswith(strtmp) 返回True/False >>> strs='aba' >>> strs.endswith ...
- 行级锁 java||数据库
http://www.cnblogs.com/xiyubaby/p/4623516.html select * from t for update 会等待行锁释放之后,返回查询结果. select * ...
- Java中final的用法总结
1. 修饰基础数据成员的final 这是final的主要用途,其含义相当于C/C++的const,即该成员被修饰为常量,意味着不可修改.如java.lang.Math类中的PI和E是f ...
- LeetCode - Number of Recent Calls
Write a class RecentCounter to count recent requests. It has only one method: ping(int t), where t r ...
- Singer 学习三 使用Singer进行mongodb 2 postgres 数据转换
Singer 可以方便的进行数据的etl 处理,我们可以处理的数据可以是api 接口,也可以是数据库数据,或者 是文件 备注: 测试使用docker-compose 运行&&提供数据库 ...
- 【转】OPPO A77保持应用后台运行方法
原文网址:http://www.3533.com/news/16/201708/163086/1.htm OPPO A77保持应用后台运行方法.手机的运行内存大小有限,因此在出现运行应用过多时,系统就 ...
- OpenGL纹理
如果不用头文件,把所有东西堆在同一个cpp文件中,会出现“超出GPU内存的错误!” 1 //我们自己的着色器类 #ifndef SHADER_H #define SHADER_H #include & ...
- Go sql insert update使用举例
本文结合使用场景简单介绍sql中的insert.update的使用. 以下是代码: 如果记录已经存在,则更新,否则插入新记录. package main import ( "database ...
- java IO流(二)
一.字符编码 char计算机存储的都是二进制数据,其实就是一个一个的数值字符要存储,就必须让这个字符对应一个数 将一个字符转成数字,这个过程就叫编码,反过来将一个数字转成字符就叫解码 中国大陆 (GB ...