day5模块学习--re正则模块
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
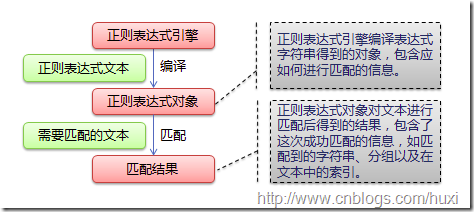
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
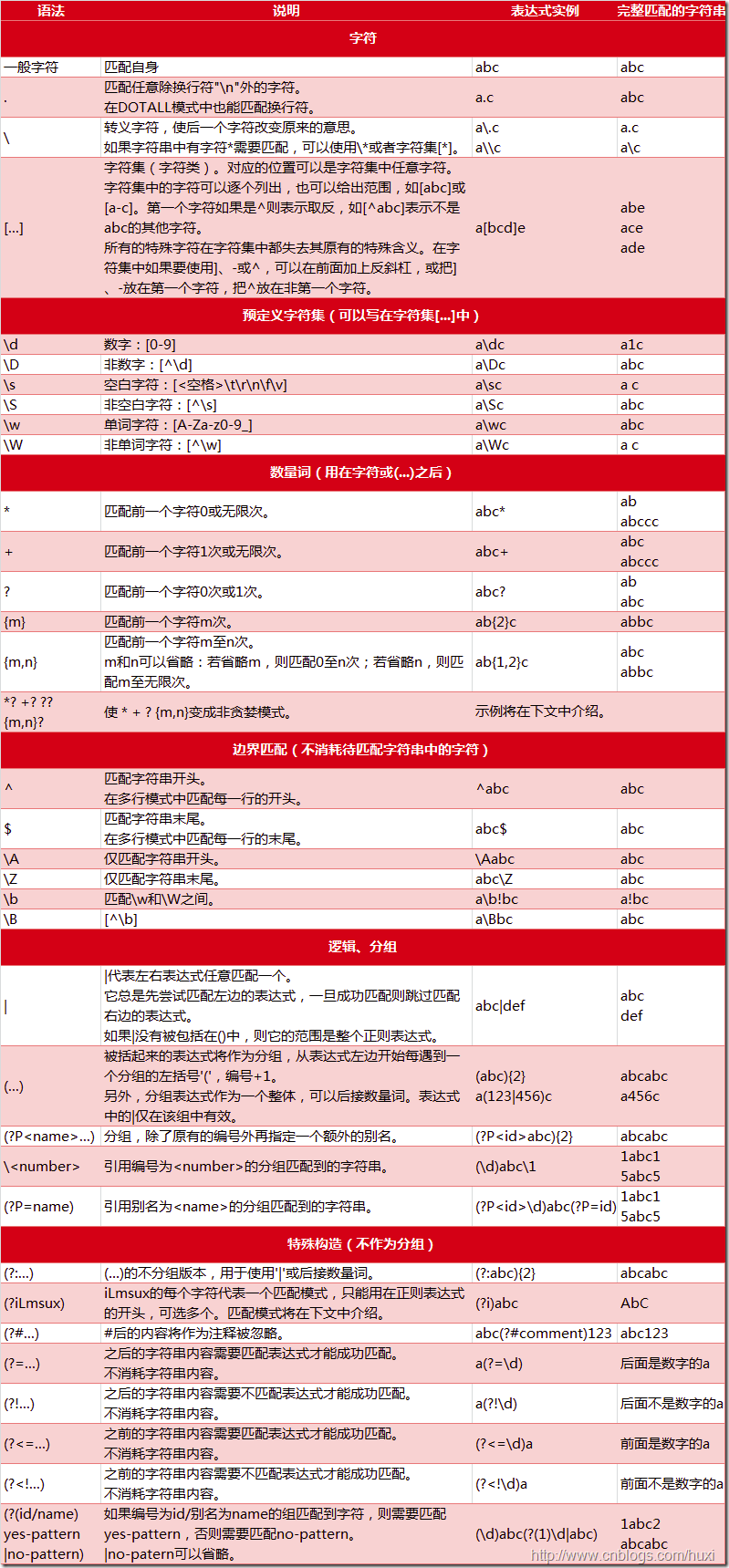
下图列出了Python支持的正则表达式元字符和语法:
1.”.“匹配任意除换行符以外的字符
>>> string = "abafsdafd\nafdasfd" #包含换行符
>>> string1 = "adfasdfadfasdfwer12345656耿" #不包含换行符
>>> import re
>>> m = re.search(".+",string) #验证是否可以匹配换行符
>>> m.group()
'abafsdafd'
>>> n = re.search(".+",string1)
>>> n.group()
'adfasdfadfasdfwer12345656耿'
从上面输出结果可以看出,”.“是匹配任意除了换行符的字符。遇到"\n"换行符即终止匹配。
2.”\"转义字符
转义字符,使后一个字符改变原来的意思。如果字符串中有*号需要匹配,可以使用\*或者字符集[*],"a\.c"代表匹配a.c "a\\c"代表匹配a\c
>>> str_num = "22.567979mafdasdf"
>>> m = re.search("\d+\.\d+",str_num)
>>> m.group()
'22.567979'
我们知道,"."在python中代表的含义是除了"\n"之外的所有字符,如果这里不进行转义的话,匹配出来的就是任意非"\n"字符,因此要使用"\"进行转义。
>>> string = "dfafdasfd\fafdasfda"
>>> string
'dfafdasfd\x0cafdasfda'
在python中,如果字符串中包含"\",有时候会显示不出来,或者修改后面的内容,把别人改变了,这个不知道在Linux平台上是怎么回事。
3.[...]字符集(字符类)
[...]:字符集(字符类)对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出[0,1,2,3,4,5,6,7,8,9],也可以给出范围[0-9]。第一个字符集如果是^表示取反,如[^abc]表示不是abc的其他字符。
所有的特殊字符在字符集中都失去其原有的特殊意义。在字符集中如果要使用]、或^,可以在前面加上"\"反斜杠,或把]\、-放在第一个字符,把^放在非第一个字符。
>>> string = "dafdafdasf[adfas^fad"
>>> m = re.search("[a-z]+\[",string)
>>> m.group()
'dafdafdasf['
从上面脚本可以看出,如果要匹配[要在前面加上"\"转义字符。
>>> m = re.search("\w+[[]",string) (1)在字符集中匹配"["
>>> m.group()
'dafdafdasf['
>>> n = re.search("w+[\[]",string) (2)转义匹配,验证在字符集中匹配[是否需要加[\]
>>> n.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
在字符集中如果要使用]、或^,可以在前面加上"\"反斜杠,或把]\、-放在第一个字符,把^放在非第一个字符。
预定义字符集
1.\d数字
>>> m = re.search("\d",string)
>>> m.group()
'1'
\d是匹配数字,等价于[0-9]
2.\D非数字 等价于[^\d]
>>> string = "dfaMNA12581耿fa"
>>> m = re.search("\D",string)
>>> m.group()
'd'
>>> n = re.search("[^\d]",string)
>>> n.group()
'd'
>>> l = re.search("[^0-9]",string)
>>> l.group()
'd'
从上面可以看出,“\D”是用来匹配非数字的,匹配除了数字0-9意外的任意字符,等价于[^0-9]或[^\d]
3.\s空白字符 [<空格>\r\t\n\f\v]
“\s”是匹配任意非空字符,如[<空格>\r\t\n\f\v]等,实例如下:
>>> m = re.search("\s+",string) #\s进行匹配空白字符
>>> m.group()
' \t \n \x0c \x0b \r'
从上面可以看出,\s是匹配任意空白字符,如空格、\r、\t、\n、\f、\v等
4.\S非空白字符 \S与\s正好相反,是匹配任意非空字符。等价于[^\s]匹配任意非空字符
>>> string = "faMM耿 \t \n \f \v \rDASDF"
>>> n = re.search("\S+",string)
>>> n.group()
'faMM耿'
从上面可以看出"\S"是匹配任意非空字符,遇到空的字符即停止了,匹配任意非空字符,"."匹配任意字符,除了换行符之外。
>>> m = re.search(".+",string)
>>> m.group()
'faMM耿 \t '
从上面看出,“\S”和“.”还是有差别的,一个是任意非空字符,一个是匹配任意除了"\n"意外任意非空字符。
5.\w 单词字符[A-Z0-9a-z_]
\w是匹配单词字符,下面来看下能不能匹配汉字或其他:
>>> string = "faMM耿 \t \n \f \v \rDASDF"
>>> m = re.search("\w+",string)
>>> m.group()
'faMM耿' (1)脚本
>>> format_string = "fdMM更KKMM长 /大MM \n \tMMKDSI"
>>> m = re.search("\w+",format_string)
>>> m.group()
'fdMM更KKMM长' (2)脚本
可以看出,"\w"是可以匹配汉字的,不能匹配空格,换行符这些,但是能够匹配汉字。
6.\W 等价于非单词字符 [^\w]
>>> import re
>>> string = "naefda曾 LmKDS 1316547\n\t\r@@3$&^$"
>>> m = re.search("\W+",string)
>>> m.group()
' '
从上面可以看出"\W "匹配出来了空,说明" "不是单词字符,"\W"是匹配非单词字符。
数量词(用在字符或(...)之后)
1."*" 匹配前一个字符0或无限次 前一个字符
"*"是匹配前一个字符0或无限次
>>> import re
>>> string = "naefda曾 LmKDS 1316547\n\t\r@@3$&^$"
>>> m = re.search("\w*",string)
>>> m.group()
'naefda曾'
>>> n = re.search("\d*",string)
>>> n.group()
''
>>> n = re.search("耿",string)
>>> n
>>> n.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
从上面脚本代码可以看出,当使用*要查找的字符在开头的时候就会匹配到,在中间就匹配不到。这种懒惰的匹配方式,如果其他情况下匹配不到,则会返回错误。
2.“+” 匹配前一个字符一次或无限次 前一个字符(牢记,只是匹配前面一个)
>>> import re
>>> string = "naefda曾 LmKDS 1316547\n\t\r@@3$&^$"
>>> m = re.search("\w+",string)
>>> m.group()
'naefda曾'
>>> n = re.search("\s+",string)
>>> n.group()
' '
>>> d = re.search("更",string)
>>> d.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
从上面可以看出,"+"是匹配前一个字符一次或无限次,如果匹配不到,则返回None
3."?" 匹配前一个字符0次或一次 前一个字符(牢记,只是匹配前面一个)
>>> import re
>>> string = "naefda曾 LmKDS 1316547\n\t\r@@3$&^$"
>>> m = re.search("\w?",string)
>>> m.group()
'n'
>>> n = re.search("f?",string)
>>> n.group()
''
从上面可以看出,?是以贪婪的方式进行匹配。?是匹配前一个字符0次或1次。从上面的例子中发现一个问题,即"?"和"*"都是从头开始进行匹配,如果开头匹配不到,就返回"",等价于如果使用search()出现”?"和“*”等价于使用match()从头开始匹配,找不到则不找了,不一样的是match()返回的是None,而seach()返回的是""。
4.{m} 代表匹配前一个字符m次 前一个字符(牢记,只是匹配前面一个)
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> m = re.search("\d{4}",string) #代表匹配数字四次
>>> m.group()
'1134'
>>> n = re.search("\d{10}",string)
>>> n.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
从上面可以看出,如果匹配不到,则返回None;{m}是代表匹配前一个字符m次,要注意在匹配的时候,我们可以像下面一样设定一个匹配区间,这样就不会出现匹配超标的情况。
5.{m,n} 匹配一个字符m次至n次 前一个字符(牢记,只是匹配前面一个)
m和n可以省略,如省略m({,n})则匹配0到n次;若省略n({m,}),则匹配m至无限次。
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> m = re.search("\d{1,10}",string)
>>> m.group()
'1134657'
>>> n = re.search("\d{,5}",string)
>>> n.group()
''
>>> d = re.search("\d{4,}",string)
>>> d.group()
'1134657'
从上面可以看出,{m,n}是匹配在一个范围内的个数,但是我们也发现了一个问题,千万不要让正则表达式匹配包含0次的情况,一旦匹配0次,那么就会出现如果开头匹配不到之后,就不匹配的情况,直接返回""。
*? +? ?? {m,n}?使*,+,?,{m,n}变成非贪婪模式。
边界匹配
1.^ 匹配字符串开头,在多行模式中,匹配第一行的开头
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> m = re.search("^da",string)
>>> m.group()
'da'
开头匹配,相当于使用match()进行匹配了。
2.$ 匹配字符串末尾,在多行模式中匹配每一行的末尾
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> m = re.search("#!",string)
>>> m.group()
'#!'
"$"是匹配字符串的末尾,不管前面,值匹配末尾是否是要匹配的内容。
3.\A 仅匹配字符串开头
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> m = re.search("\Adaf",string)
>>> m.group()
'daf'
“\A”是仅匹配字符串开头,即仅仅从字符串的开头进行匹配。
4.\Z 仅匹配字符串末尾
>>> import re
>>> string = "dafMM\n更1134657Qqcd m,l#!"
>>> n = re.search("l#!",string)
>>> n.group()
'l#!'
"\Z"是仅匹配字符串末尾,仅从末尾进行匹配,可能\Z和$的区别就是,$是匹配每行的末尾,而\Z是仅匹配字符串的末尾。
5.\b 匹配\w和\W之间的字符
6.\B 匹配非\w和\W之间的字符 即[^\b]
逻辑分组
1.“|” 代表左右表达式任意匹配一个
它总是先尝试匹配左边的表达式,一旦成功则跳过右边的表达式。如果|没有被包含在()中,则它的范围是整个正则表达式
>>> import re
>>> m = re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict()
>>> m
{'city': '81', 'birthday': '1993', 'province': '3714'}
可以依次分组匹配,生成一个字典,groupdict(),分组匹配,给匹配到的字符串起名字。
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
- import re
- #将正则表达式编译成Pattern对象
- pattern = re.compile(r'hello')
- #使用pattern匹配文本,获得匹配结果,无法匹配时将返回None
- match = pattern.match("hello world!")
- if match:
- #使用match获得分组信息
- print(match.group())
上面正则匹配中,首先进行了编译,编译成正则格式,然后进行匹配。
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
>>> string = "aafaaMMaaaa"
>>> m = re.search("aa?",string)
>>> m.group()
'aa'
>>> n = re.search("aaa?",string)
>>> n.group()
'aa'
>>> d = re.search("aaaa?",string)
>>> d.group()
'aaaa'
上面代码中,"?"的作用是匹配前一个字符,就是这个正则符号前面的那个字符0次或一次。
正则表达式匹配中文(http://blog.csdn.net/tao_627/article/details/51019972)
import re
name = "ge耿长学164——///大师傅"
# name = name.encode('utf-8')
d = re.search(u"([\u4e00-\u9fa5]+)",name)
print(d.group())
unicode中中文的编码为/u4e00-/u9fa5
上面的正则表达式u"([\u4e00-\u9fa5]+)"就是用来匹配中文字符的,
匹配非中文字符集如下:
import re
name = "ge耿长学164——///大师傅"
# name = name.encode('utf-8')
d = re.search(u"([^\u4e00-\u9fa5]+)",name)
print(d.group())
只需在正则表达式里面加上^,非的意思,就是匹配中文意外的其他字符。
day5模块学习--re正则模块的更多相关文章
- Python 模块学习:os模块
一.os模块概述 Python os模块包含普遍的操作系统功能.如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的.(一语中的) 二.常用方法 1.os.name 输出字符串指示正在使用的平台 ...
- [转] Python 模块学习:os模块
一.os模块概述 Python os模块包含普遍的操作系统功能.如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的.(一语中的) 二.常用方法 1.os.name 输出字符串指示正在使用的平台 ...
- python模块学习:os模块
一.os模块概述 Python os模块包含普遍的操作系统功能.例如文件的复制.创建.修改.删除文件及文件夹... 二.常用方法 1.os.listdir() 返回指定目录下的所有文件和目录名. ...
- Scikit-Learn模块学习笔记——数据集模块datasets
scikit-learn 的 datasets 模块包含测试数据相关函数,主要包括三类: datasets.load_*():获取小规模数据集.数据包含在 datasets 里 datasets.fe ...
- Python 模块学习:re模块
今天学习了Python中有关正则表达式的知识.关于正则表达式的语法,不作过多解释,网上有许多学习的资料.这里主要介绍Python中常用的正则表达式处理函数. 方法/属性 作用 match() 决定 R ...
- Python3 学习第八弹: 模块学习一之模块变量
__name__变量 用于判断该python文件是否作为主程序运行.若该文件为导入,__name__值为其文件名,若为主程序,则其值为__main__ 这也就是为什么经常看到有一些python文件中有 ...
- python模块学习之hashlib模块学习
# 加密模块 import hashlib # md5 加密 md5 # 1.初始化md5模块 生成md5对象 # 2.引入要加密的数据 update # 3.获取加密值 hexdigest m = ...
- [Python模块学习]用qrcode模块生成二维码
转自:https://blog.csdn.net/jy692405180/article/details/65937077
- python模块学习之six模块
Six:Python 2和3兼容性库 Six提供了简单的实用程序,用于覆盖Python 2和Python 3之间的差异.它旨在支持在Python 2和3中都可以进行修改的代码库. 六个只包含一个Pyt ...
随机推荐
- 第三节:工厂+反射+配置文件(手写IOC)对缓存进行管理。
一. 章前小节 在前面的两个章节,我们运用依赖倒置原则,分别对 System.Web.Caching.Cache和 System.Runtime.Cacheing两类缓存进行了封装,并形成了ICach ...
- JAVA实现二叉树(简易版--实现了二叉树的各种遍历)
1,个人感觉二叉树的实现主要还是如何构造一颗二叉树.构造二叉树函数的设计方法多种多样,本例采用 addNode 方法实现.以下程序通过定义内部类来表示二叉树的结点,然后再实现了二叉树这种数据结构的一些 ...
- 关于Mac OS虚拟机下共享文件夹的方法
1.确保左上角苹果标志的旁边是“Finder”: 2.点击"Finder": 3.选择“偏好设置设置”: 4.然后在“通用”标签下勾选“已连接服务器”: OK,搞定! 完成以上 ...
- MySQL锁解决并发问题详解
文章分为以下几个要点 问题描述以及解决过程 MySQL锁机制 数据库加锁分析 下面讨论的都是基于MySQL的InnoDB. 0. 问题描述以及解决过程 因为涉及到公司利益问题,所以下面很多代码和数据库 ...
- 二、ARM处理器
2.1 介绍 ARM核心的基本结构指ARM架构显示处理器中处理的数据大小.指令架构.寄存器等的结构和运行原理 ARM核心是利用ARM架构的基本原理实现的处理器核心部分. ARM的主要架构如下: ARM ...
- Scapy Fuzz实现——S7协议从建连到“正常交流“(一)
转载:安全客 酝酿了“三秒钟“,准备理清逻辑写写我学习的心得,自认为和Siemens S7协议有过一段时间浅浅的“交流”,所以这过程中涉及到了自己整理的自认为有用的东西,涉及工具.脚本这般,发出来让大 ...
- modbus-vcr介绍
相关链接:modbus-vcr modbus-vcr是一个Ettercap的插件,被使用在缺少数据完整性的工业控制系统协议方面. 这个Ettercap插件执行一个MITM攻击在使用Modbus协议的系 ...
- 让 IE9 以下的浏览器支持 Media Queries
1. 如何让 IE9 以下的浏览器支持 css3 的media query 需要用到的 min-width/max-width 属性 css3 的媒体查询 IE 浏览器的支持程度是从 IE9开始支持, ...
- TCP传输协议
TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接,四次挥手断开连接. 三次握手 是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接建立成功.在so ...
- J - Joseph and Tests Gym - 102020J (二分+线段树)
题目链接:https://cn.vjudge.net/contest/283920#problem/J 题目大意:首先给你n个门的高度,然后q次询问,每一次询问包括两种操作,第一种操作是将当前的门的高 ...