【Python全栈-数据库】数据库基础
数据库的简介
数据库基本概念:
数据库(database,DB)是指长期存储在计算机内的,有组织,可共享的数据的集合。
数据库中的数据按一定的数学模型组织、描述和存储,具有较小的冗余,较高的数据独立性和易扩展性,并可为各种用户共享。
数据库管理系统软件
数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据,数据库管理员也通过dbms进行数据库的维护工作。它可使多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。大部分DBMS提供数据定义语言DDL(Data Definition Language)和数据操作语言DML(Data Manipulation Language),供用户定义数据库的模式结构与权限约束,实现对数据的追加、删除等操作。 数据库管理系统是数据库系统的核心,是管理数据库的软件。数据库管理系统就是实现把用户意义下抽象的逻辑数据处理,转换成为计算机中具体的物理数据处理的软件。有了数据库管理系统,用户就可以在抽象意义下处理数据,而不必顾及这些数据在计算机中的布局和物理位置。 常见的数据库管理软件:甲骨文的oracle,IBM的db2,sql server, Access,Mysql(开源,免费,跨平台). 数据库可视化管理软件如:
web端:PhpMyAdmin
客户端软件:Navicat(推荐****)
数据库系统:
数据库系统DBS(Data Base System,简称DBS)通常由软件、数据库和数据管理员组成。其软件主要包括操作系统、各种宿主语言、实用程序以及数据库管理系统。
数据库由数据库管理系统统一管理,数据的插入、修改和检索均要通过数据库管理系统进行。数据管理员负责创建、监控和维护整个数据库,使数据能被任何有权使用的人有效使用。

MySQL数据库-基础篇
mysql 数据库初始化
安装:
linux:
--yum -y install mariadb mariadb-server
OR
--yum -y install mysql mysql-server
window:
--http://dev.mysql.com/downloads/mysql/
以windows为例安装之后:
问题描述:在命令行输入 mysql -u root -p 登录mysql,返回”Can't connect to MySQL server on localhost (10061)”错误
解决方法:1、将mysql加入到Windows的服务中。切换到mysql 安装目录下的bin文件夹,命令行运行"mysqld --install"
D:\MySQL\mysql-8.0.11-winx64\bin>mysqld --install Service successfully installed.
cmd 启动或停止数据库:
启动mysql服务与停止mysql服务命令:
--
-- net start mysql
-- net stop mysql
或者直接命令行->services.msc->服务->Mysql 右击启动
查看:
-- ps aux |grep mysqld #查看进程
-- netstat -an |grep 3306 #查看端口
设置密码:
-- mysqladmin -uroot password '123' #设置初始密码,初始密码为空因此-p选项没有用
-- mysqladmin -u root -p123 password '1234' #修改root用户密码
登录:
-- mysql #本地登录,默认用户root,空密码,用户为root@127.0.0.1
-- mysql -uroot -proot #本地登录,指定用户名和密码,用户为root@127.0.0.1
-- mysql -uroot -p1234 -h 192.168.31.95 #远程登录,用户为root@192.168.31.95
mysql的常用基本命令
查看数据库端口:
show global variables like 'port';
设置服务器ip 端口 用户名 密码等:
-- mysql -h 服务器IP -P 端口号 -u 用户名 -p 密码 --prompt 命令提示符 --delimiter 指定分隔符
-- mysql -h 127.0.0.1 -P 3306 -uroot -p123
-- quit------exit----\q;
--
--
-- \s; ------my.ini文件:[mysql] default-character-set=gbk [mysqld] character-set-server=gbk
--
-- prompt 命令提示符(\D:当前日期 \d:当前数据库 \u:当前用户)
--
-- \T(开始日志) \t(结束日志)
--
-- show warnings;
--
-- help() ? \h
--
-- \G;
--
-- select now();
-- select version();
-- select user;
--
-- \c 取消命令
--
-- delimiter 指定分隔符 查看存在的数据库:
show databases;
创建数据库:
create database [db_name];
使用数据库:
use mydata1;
查看数据库所有表:
show tables;
忘记密码怎么办?
方法1:启动mysql时,跳过授权表
[root@controller ~]# service mysqld stop
[root@controller ~]# mysqld_safe --skip-grant-table &
[root@controller ~]# mysql
mysql> select user,host,password from mysql.user;
+----------+-----------------------+-------------------------------------------+
| user | host | password |
+----------+-----------------------+-------------------------------------------+
| root | localhost | *A4B6157319038724E3560894F7F932C8886EBFCF |
| root | localhost.localdomain | |
| root | 127.0.0.1 | |
| root | ::1 | |
| | localhost | |
| | localhost.localdomain | |
| root | % | *23AE809DDACAF96AF0FD78ED04B6A265E05AA257 |
+----------+-----------------------+-------------------------------------------+
mysql> update mysql.user set password=password("123") where user="root" and host="localhost";
mysql> flush privileges;
mysql> exit
[root@controller ~]# service mysqld restart
[root@controller ~]# mysql -uroot -p123
方法2(删库):
删除与权限相关的库mysql,所有的授权信息都丢失,主要用于测试数据库或者刚刚建库不久没有授权数据的情况(从删库到跑路)
[root@controller ~]# rm -rf /var/lib/mysql/mysql
[root@controller ~]# service mysqld restart
[root@controller ~]# mysql
sql及其规范
sql是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持sql。
<1> 在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写;
<2> SQL语句可单行或多行书写,以“;”结尾。关键词不能跨多行或简写。
<3> 用空格和缩进来提高语句的可读性。子句通常位于独立行,便于编辑,提高可读性。
SELECT * FROM tb_table
WHERE NAME="YUAN";
<4> 注释:单行注释:--
多行注释:/*......*/
<5>sql语句可以折行操作
<6> DDL,DML和DCL(数据定义语言DDL、数据操纵语言DML、数据控制语言DCL)
-- --SQL中 DML、DDL、DCL区别 .
--
--
-- -- DML(data manipulation language):
-- 它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的
-- 数据进行操作的语言
--
-- -- DDL(data definition language):
-- DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)
-- 的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
--
-- -- DCL(Data Control Language):
-- 是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)
-- 语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权
-- 力执行DCL
二. SQL语言的分类 SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件> 2 .数据操纵语言DML
数据操纵语言DML主要有三种形式:
1) 插入:INSERT
2) 更新:UPDATE
3) 删除:DELETE 3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、
索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER
| | | | |
表 视图 索引 同义词 簇 DDL操作是隐性提交的!不能rollback 4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制
数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。 2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚---ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL>ROLLBACK; 3) COMMIT [WORK]:提交。 在数据库的插入、删除和修改操作时,只有当事务在提交到数据
库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看
到所做的事情,别人只有在最后提交完成后才可以看到。
提交数据有三种类型:显式提交、隐式提交及自动提交。下面分
别说明这三种类型。 (1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT; (2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,
EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。 (3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,
系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
数据库SQL语言分类
数据库操作语言(DDL)---DatabaseDefineLanguage
-- 1.创建数据库(在磁盘上创建一个对应的文件夹)
create database [if not exists] db_name [character set xxx]
Create Database If Not Exists MyDB Character Set UTF8;
-- 2.查看数据库 show databases;查看所有数据库 show create database db_name; 查看数据库的创建方式 -- 3.修改数据库 alter database db_name --修改数据库名称 alter database character set gbk --修改数据库编码方式 -- 4.删除数据库
drop database [if exists] db_name; -- 5.使用数据库
切换数据库 use db_name; -- 注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
查看当前使用的数据库 select database(); mysql数据类型
MySQL支持的数据类型有3种:数值、日期/时间和Text类型。
--->Text类型

CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
--->日期/时间类型
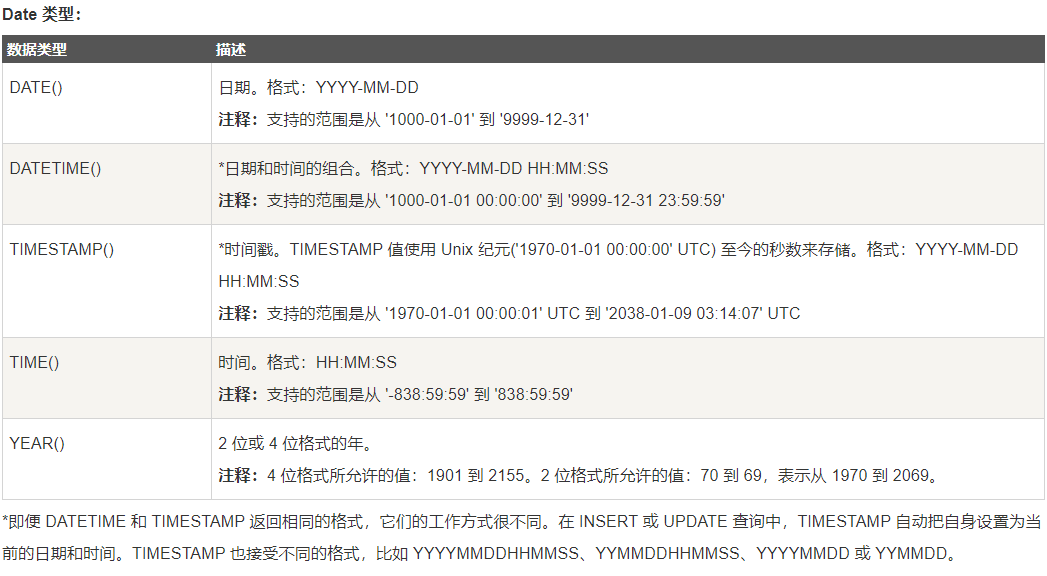
--->Number类型
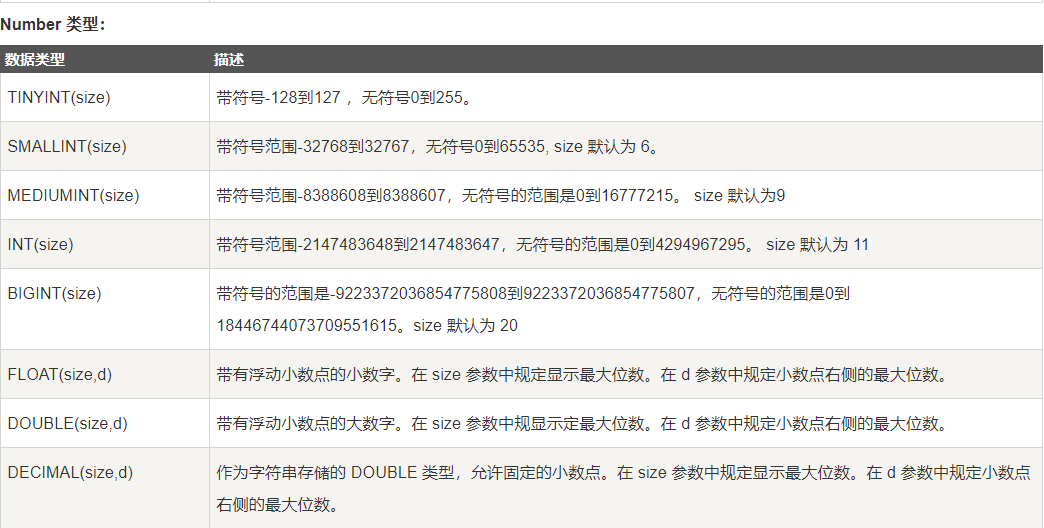
注意:以上的 size 代表的并不是存储在数据库中的具体的长度,如 int(4) 并不是只能存储4个长度的数字。
实际上int(size)所占多少存储空间并无任何关系。int(3)、int(4)、int(8) 在磁盘上都是占用 4 btyes 的存储空间。就是在显示给用户的方式有点不同外,int(M) 跟 int 数据类型是相同的。
例如:
1、int的值为10 (指定zerofill)
int(9)显示结果为000000010
int(3)显示结果为010
就是显示的长度不一样而已 都是占用四个字节的空间
PRIMARY KEY 主键:唯一且不能为空
AUTO_INCREMENT 约束条件:自增 float(6,2) 表示6位数,其中小数点后面两位:表示的范围是0.01~9999.99
char(3) 存储的的字符串长度是3位,应用如存储手机号、身份证号等
varchar(20) 表示存储槽字符串长度为0~20位
数据表操作 (* * * * *)
基础操作
-- 1.创建表(类似于一个excel表)【注意:创建表之前应该进入数据库,如 use database_name; ,然后再操作创建表】
create table tab_name(
field1 type[完整性约束条件],
field2 type,
...
fieldn type
)[character set xxx];
-- 创建一个员工表employee
create table employee(
id int primary key auto_increment ,
name varchar(20),
gender bit default 1, -- gender char(1) default 1 ----- 或者 TINYINT(1)
birthday date,
entry_date date,
job varchar(20),
salary double(4,2) unsigned,
resume text -- 注意,这里作为最后一个字段不加逗号
);
Create Table If Not Exists `world`(
`ID` Bigint(8) unsigned Primary key Auto_Increment,
`Name` text,
`Birthday` DateTime
)Engine InnoDB; --指定存储引擎为innodb(mysql5.0以后默认为innodb)
判断是否已经存在表
/* 约束:
primary key (非空且唯一) :能够唯一区分出当前记录的字段称为主键!
unique
not null
auto_increment 主键字段必须是数字类型。
外键约束 foreign key */ -- 2.查看表信息
desc tab_name 查看表结构
show columns from tab_name 查看表结构
show tables 查看当前数据库中的所有的表
show create table tab_name 查看当前数据库表建表语句 -- 3.修改表结构
-- (1)增加列(字段)
alter table tab_name add [column] 列名 类型[完整性约束条件][first|after 字段名];
alter table user add addr varchar(20) not null unique first/after username;
#添加多个字段
alter table users2
add addr varchar(20),
add age int first,
add birth varchar(20) after name; -- (2)修改一列类型
alter table tab_name modify 列名 类型 [完整性约束条件][first|after 字段名];
alter table users2 modify age tinyint default 20;
alter table users2 modify age int after id; -- (3)修改列名
alter table tab_name change [column] 列名 新列名 类型 [完整性约束条件][first|after 字段名];
alter table users2 change age Age int default 28 first; -- (4)删除一列
alter table tab_name drop [column] 列名;
-- 思考:删除多列呢?删一个填一个呢?
alter table users2
add salary float(6,2) unsigned not null after name,
drop addr; -- (5)修改表名
rename table 表名 to 新表名;
-- (6)修该表所用的字符编码方式
alter table student character set utf8; -- 4.删除表
drop table tab_name; ---5 添加主键,删除主键
alter table tab_name add primary key(字段名称,...)
alter table users drop primary key; eg:
mysql> create table test5(num int auto_increment);
ERROR 1075 (42000): Incorrect table definition; there can be only one auto column and it must be defined as a key
create table test(num int primary key auto_increment);
-- 思考,如何删除主键?
alter table test modify id int; -- auto_increment没了,但这样写主键依然存在,所以还要加上下面这句
alter table test drop primary key; -- 仅仅用这句也无法直接删除主键 -- 唯一索引
alter table tab_name add unique [index|key] [索引名称](字段名称,...) alter table users add unique(name)-- 索引值默认为字段名show create table users;
alter table users add unique key user_name(name);-- 索引值为user_name -- 添加联合索引
alter table users add unique index name_age(name,age);#show create table users; -- 删除唯一索引
alter table tab_name drop {index|key} index_name
表的基本结构
create table 表名(
列名 类型 是否可以为空,
列名 类型 是否可以为空
)ENGINE=InnoDB DEFAULT CHARSET=utf8 //默认是innodb 和utf8 可以不写
是否可空,
null表示空,非字符串
not null - 不可空
默认值,创建列时可以指定默认值,当插入数据时如果未设置值时,则自动添加默认值
create table tb1(
nid int not null defalut 2,
num int not null )
设置自增步长:
自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列)
create table tb1(
nid int not null auto_increment primary key,
num int null
)
或
create table tb1(
nid int not null auto_increment,
num int null,
index(nid)
) 注意:1、对于自增列,必须是索引(含主键)。
2、对于自增可以设置步长和起始值
show session variables like 'auto_inc%';
set session auto_increment_increment=2;
set session auto_increment_offset=10; shwo global variables like 'auto_inc%';
set global auto_increment_increment=2;
set global auto_increment_offset=10;
主键(非空且唯一):
主键,一种特殊的唯一索引,不允许有空值,
如果主键使用单个列,则它的值必须唯一,
如果是多列,则其组合必须唯一。
//单列 nid必须唯一
create table tb1(
nid int not null auto_increment primary key,
num int null
) //多列 nid 和num的组合唯一
create table tb1(
nid int not null,
num int not null,
primary key(nid,num)
)
外键foreign key:
外键,一个特殊的索引,只能是指定内容
//一个出版社出版多本书(一对多)
creat table publisher(
nid int not null primary key,
name varchar(32) not null
) create table book(
nid int not null primary key,
price float(10,2) null ,
name varchar(32) not null,
constraint fk_bp foreign key (name) references book(nid)
)
案例:创建文章表
create table article(
id int primary key auto_increment ,
title varchar(20),
publish_date INT,
click_num INT,
is_top TINYINT(1),
content TEXT
);
删除表
drop table 表名
清空表
delete from 表名
truncate table 表名
修改表
添加列:alter table 表名 add 列名 类型
删除列:alter table 表名 drop column 列名
修改列:
alter table 表名 modify column 列名 类型; -- 修改类型
alter table 表名 change 原列名 新列名 类型; -- 修改列名,类型 添加主键:
alter table 表名 add primary key(列名);
删除主键:
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);
删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;
删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
表记录操作(* * * * *)
表记录之 增,删,改
-- 1.增加一条记录 insert into [tab_name] (field1,filed2,.......) values (value1,value2,.......)
create table employee_new(
id int primary key auto_increment,
name varchar(20) not null unique,
birthday varchar(20), salary float(7,2) ); insert into employee_new (id,name,birthday,salary) values (1,'yuan','1990-09-09',9000);
insert into employee_new (name,salary) values ('xialv',1000);
insert into employee_new values (2,'alex','1989-08-08',3000); -- 插入多条数据 (当没有 filed 时 values的参数必须完整)
insert into employee_new values (4,'alvin1','1993-04-20',3000), (5,'alvin2','1995-05-12',5000); -- set插入: insert into tab_name set 字段名=值
insert into employee_new set id=12,name="alvin3"; -- 2.修改表记录
update tab_name set field1=value1,field2=value2,......[where 语句]
/* UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。
WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。*/
update employee_new set birthday="1989-10-24" WHERE id=1; 需求--- 将yuan的薪水在原有基础上增加1000元。
update employee_new set salary=salary+1000 where name='yuan'; -- 3.删除表纪录 delete from tab_name [where ....]
/* 如果不跟where语句则删除整张表中的数据;where 限定删除指定行的数据;
delete语句只能删除表中的内容,不能删除表本身;
想要删除表,用drop table tab_name;
TRUNCATE TABLE也可以删除表中的所有数据,该语句首先摧毁表,再新建表。此种方式删除的数据不能在事务中恢复。*/ 需求-- 删除表中名称为’alex’的记录。
delete from employee_new where name='alex'; 注意:WHERE 定位语句中 and 和 or 的用法!!
--删除表中ID=2 和 ID=3 的记录(删除了两条记录)
delete from employee_new where id=2 or id=3;
--删除表中department="技术部" 并且 age=30 的记录(删除了一条记录)
delete from employ_new where department="技术部" and age=30; 比较两种删除表的方式!
-- 删除表中所有记录。表中数据一条一条的删除(适用于表中有少量数据)
delete from employee_new; --注意auto_increment没有被重置:alter table employee auto_increment=1;
-- 使用truncate删除表中记录。删除这个表 然后创建一个新表(适用于表中有大量数据)
truncate table emp_new;
思考:
<1> 存储时间用varchar可不可以呢?它与date数据类型又有什么区别呢?
<2> 表中数据三条,id分别为1,2,3,突然插入一个id=7,那么下次作为主键的字增长的id会从几开始增长呢?(从7开始)
表记录之查(单表查询) (* * * * *)
(1)select 语句
-- 查询表达式
SELECT *|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数 ---创建表结构
CREATE TABLE ExamResult( id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
JS DOUBLE ,
Django DOUBLE ,
Flask DOUBLE
); ---向表中增加数据
INSERT INTO ExamResult VALUES (1,"李明",98,98,98),
(2,"张强",35,98,67),
(3,"李杰",59,59,62),
(4,"苏轼",88,89,82),
(5,"王五",88,98,67),
(6,"王安石",86,100,55); -- (1)select [distinct] *|field1,field2,...... from tab_name
-- 其中from指定从哪张表筛选,* 表示查找所有列,也可以指定一个列
-- 表明确指定要查找的列,distinct 用来剔除重复行。 -- 查询表中所有学生的信息。
select * from ExamResult;
-- 查询表中所有学生的姓名和对应的js成绩。
select name,JS from ExamResult;
-- 过滤表中重复数据。
select distinct JS ,name from ExamResult; -- (2)select 也可以使用表达式,并且可以使用: 字段 as 别名 或者:字段 别名 -- 在所有学生分数上加10分,这只是做一次显示用,实际上数据库中数据没有变化。
select name,JS+10,Django+10,OpenStack+10 from ExamResult;
-- 统计每个学生的总分。
select name,JS+Django+OpenStack from ExamResult;
-- 使用别名表示学生总分。
select name as 姓名,JS+Django+OpenStack as 总成绩 from ExamResult;
-- 别名方式2
select name,JS+Django+OpenStack 总成绩 from ExamResult;
select name JS from ExamResult; -- what will happen?---->记得加逗号,将name 别名设置为JS
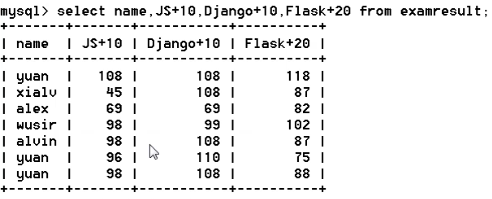
(2)使用where子句,进行过滤查询
-- 查询姓名为XXX的学生成绩
select * from ExamResult where name='yuan';
-- 查询js成绩大于90分的同学
select id,name,JS from ExamResult where JS>90;
-- 查询总分大于200分的所有同学
select name,JS+Django+OpenStack as 总成绩 from ExamResult where JS+Django+OpenStack>200 ; -- where子句中运算符的使用:
-- 比较运算符:
> < >= <= <> !=
between 80 and 100 (闭区间 值包括80和100)
in(80,90,100) (三个值80,90,100)
like '唐%'
/*
pattern可以是 % 或者 _ ,
如果是 % 则表示任意多字符,此例如唐僧,唐国强,唐吉坷德
如果是 _ 则表示一个字符 如唐_,只有唐僧符合。两个 _ 则表示两个字符: 只有唐国强 符合
*/ -- 逻辑运算符
在多个条件直接可以使用逻辑运算符 and or not
-- 练习
-- 查询JS分数在 70-100之间的同学。
select name ,JS from ExamResult where JS between 80 and 100; -- 查询Django分数为75,76,77的同学。
select name ,Django from ExamResult where Django in (75,98,77); -- 查询所有姓王的学生成绩。
select * from ExamResult where name like '王%'; -- 查询JS分>90,Django分>90的同学。
select id,name from ExamResult where JS>90 and Django >90; -- 查找缺考js的学生的姓名
select name from ExamResult whert Js is null;
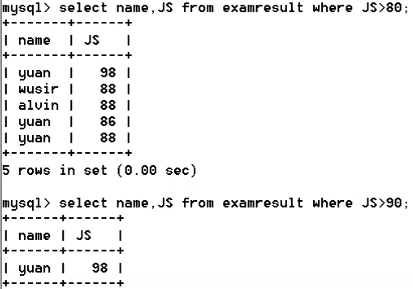
(3)Order by 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名
-- select * [field1,field2...] from tab_name order by field [Asc|Desc]
-- Asc 升序、Desc 降序,其中asc为默认值 ORDER BY 子句应位于SELECT语句的结尾。
-- 练习:
-- 对JS成绩排序后输出。
select * from ExamResult order by JS;
-- 对总分排序按降序输出姓名 总成绩
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0)) as 总成绩 from ExamResult order by 总成绩 desc;
-- 对姓李的学生总成绩排序输出
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))as 总成绩 from ExamResult
where name like '李%' order by 总成绩 desc;
-- 对JS 成绩大于80分的 从高到低排列
select JS from ExamResult where JS>80 order by JS Desc;
(4)group by 分组查询
CREATE TABLE order_menu(
id INT PRIMARY KEY auto_increment,
product_name VARCHAR (20),
price FLOAT(6,2),
born_date DATE,
class VARCHAR (20)); INSERT INTO order_menu (product_name,price,born_date,class) VALUES
("苹果",20,20170612,"水果"),
("香蕉",80,20170602,"水果"),
("水壶",120,20170612,"电器"),
("被罩",70,20170612,"床上用品"),
("音响",420,20170612,"电器"),
("床单",55,20170612,"床上用品"),
("草莓",34,20170612,"水果"); -- 注意,按分组条件分组后每一组只会显示第一条记录 -- group by 字句,其后可以接多个列名,也可以跟having子句,对group by 的结果进行筛选。 -- 按位置字段筛选
select * from order_menu group by 5; -- 练习:对购物表按类名分组后显示每一组商品的价格总和
select class,SUM(price) from order_menu group by class; -- 练习:对购物表按类名分组后显示每一组商品价格总和超过150的商品
select class,SUM(price) from order_menu group by class HAVING SUM(price)>150;
/*
having 和 where两者都可以对查询结果进行进一步的过滤,差别有:
<1>where语句只能用在分组之前的筛选,having可以用在分组之后的筛选;
<2>使用where语句的地方都可以用having进行替换
<3>having中可以用聚合函数,where中就不行。
(where的效率高)如果既能用where又能用having 优先选用where
*/
-- GROUP_CONCAT() 函数
SELECT id,GROUP_CONCAT(name),GROUP_CONCAT(JS) from ExamResult GROUP BY id;
(5)聚合函数
先不要管聚合函数要干嘛,先把要求的内容查出来再包上聚合函数即可。--(一般和分组查询配合使用)
--<1> 统计表中所有记录
-- COUNT(列名):统计行的个数
-- 统计一个班级共有多少学生?先查出所有的学生,再用count包上
select count(*) from ExamResult;
select count(name) from ExamResult where JS>70;
-- 统计JS成绩大于70的学生有多少个?
select count(JS) from ExamResult where JS>70;
-- 统计总分大于280的人数有多少?
select count(name) from ExamResult where (ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))>280;
-- 注意:count(*)统计所有行; count(字段)不统计null值.
-- SUM(列名):统计满足条件的行的内容和
-- 统计一个班级JS总成绩?先查出所有的JS成绩,再用sum包上
select JS as JS总成绩 from ExamResult;
select sum(JS) as JS总成绩 from ExamResult;
-- 统计一个班级各科分别的总成绩
select sum(JS) as JS总成绩,
sum(Django) as Django总成绩,
sum(OpenStack) as OpenStack from ExamResult;
-- 统计一个班级各科的成绩总和
select sum(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0)) as 总成绩 from ExamResult;
-- 统计一个班级JS成绩平均分
select sum(JS)/count(*) from ExamResult ;
-- 注意:sum仅对数值起作用,否则会报错。
-- AVG(列名): 求平均值
-- 求一个班级JS平均分?先查出所有的JS分,然后用avg包上。
select avg(ifnull(JS,0)) from ExamResult;
-- 求一个班级总分平均分
select avg((ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0)))
from ExamResult ;
-- Max、Min :最大值、最小值
-- 求班级最高分和最低分(数值范围在统计中特别有用)
select Max((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最高分 from ExamResult;
select Min((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最低分 from ExamResult;
-- 求购物表中单价最高的商品名称及价格
---SELECT id, MAX(price) FROM order_menu;--id和最高价商品是一个商品吗?
SELECT MAX(price) FROM order_menu;
-- 注意:null 和所有的数计算都是null,所以需要用ifnull将null转换为0!
-----ifnull(JS,0)
-- with rollup的使用
--<2> 统计分组后的组记录
(6)Mysql在执行sql语句时的执行顺序
SQL语句的执行顺序
from where group by having select order by limit
SQL执行顺序的一个典型案例
select 考生姓名, max(总成绩) as max总成绩 from tb_Grade where 考生姓名 is not null
group by 考生姓名 having max(总成绩) > 600 order by max总成绩 /*在上面的示例中 SQL 语句的执行顺序如下: (1). 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据 (2). 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据 (3). 执行 GROUP BY 子句, 把 tb_Grade 表按 "学生姓名" 列进行分组(注:这一步开始才可以使用select中的别名,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用) (4). 计算 max() 聚集函数, 按 "总成绩" 求出总成绩中最大的一些数值 (5). 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的. (7). 执行 ORDER BY 子句, 把最后的结果按 "Max 成绩" 进行排序. */
注意:在where 中不能使用select 中的别名,而having和order by可以用别名
select JS as JS成绩 from ExamResult where JS成绩 >70; ---- 不成功 select JS as JS成绩 from ExamResult having JS成绩 >90; --- 成功
(7)limit
SELECT * from ExamResult limit 3; --显示前3条 SELECT * from ExamResult limit 2,5; --跳过前2条显示接下来的五条纪录 显示3,4,5,6,7 SELECT * from ExamResult limit 2,2;
(8)使用正则表达式查询
SELECT * FROM employee WHERE emp_name REGEXP '^yu';
SELECT * FROM employee WHERE emp_name REGEXP 'yun$';
SELECT * FROM employee WHERE emp_name REGEXP 'm{2}';
外键约束
参考:https://blog.csdn.net/qq_34306360/article/details/79717682
外键的基本概念:
1、MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引,InnoDB不能自动地创建索引。 2、外键可以是一对一的,一个表的记录只能与另一个表的一条记录连接,或者是一对多的,一个表的记录与另一个表的多条记录连接。 3、如果需要更好的性能,并且不需要完整性检查,可以选择使用MyISAM表类型,如果想要在MySQL中根据参照完整性来建立表并且希望在此基础上保持良好的性能,最好选择表结构为innoDB类型。 4、外键的使用条件 ① 两个表必须是InnoDB表,MyISAM表暂时不支持外键 ② 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立; ③ 外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以; 5、外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作。
外键的概念
创建外键
---每一个班主任会对应多个学生 , 而每个学生只能对应一个班主任(一对多关系)
----主表(班主任表) CREATE TABLE ClassInfo(
id TINYINT PRIMARY KEY auto_increment,
name VARCHAR (20),
age INT ,
is_marriged boolean -- show create table ClassCharger: tinyint(1)
)ENGINE=INNODB; INSERT INTO ClassInfo (name,age,is_marriged) VALUES ("冰冰",21,0),
("丹丹",24,1),
("歪歪",22,0),
("姗姗",30,1),
("小雨",31,1); ----子表(学生表)
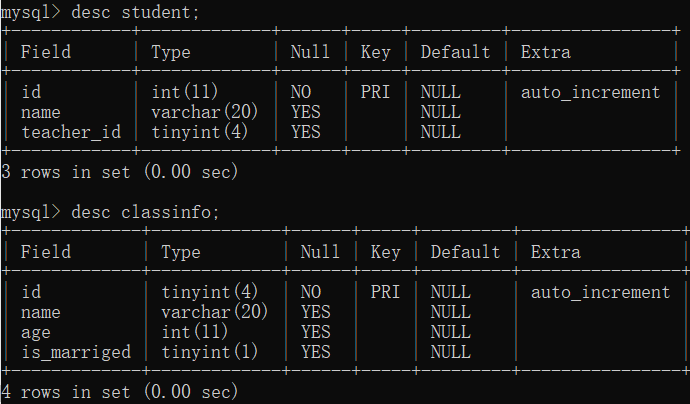
CREATE TABLE Student(
id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
teacher_id TINYINT --切记:作为外键一定要和关联主键的数据类型保持一致(注意!最后一条后面的 逗号, 不能要)
) ENGINE=INNODB; INSERT INTO Student(name,teacher_id) VALUES ("alvin1",2),
("alvin2",4),
("alvin3",1),
("alvin4",3),
("alvin5",1),
("alvin6",3),
("alvin7",2); DELETE FROM ClassInfo WHERE name="冰冰";
INSERT student (name,teacher_id) VALUES ("yuan",1);
-- 删除居然成功,可是 alvin3显示还是有班主任id=1的冰冰的; -----------增加外键和删除外键--------- ALTER TABLE student ADD CONSTRAINT abc
FOREIGN KEY(teacher_id)
REFERENCES classInfo(id); ALTER TABLE student DROP FOREIGN KEY abc;
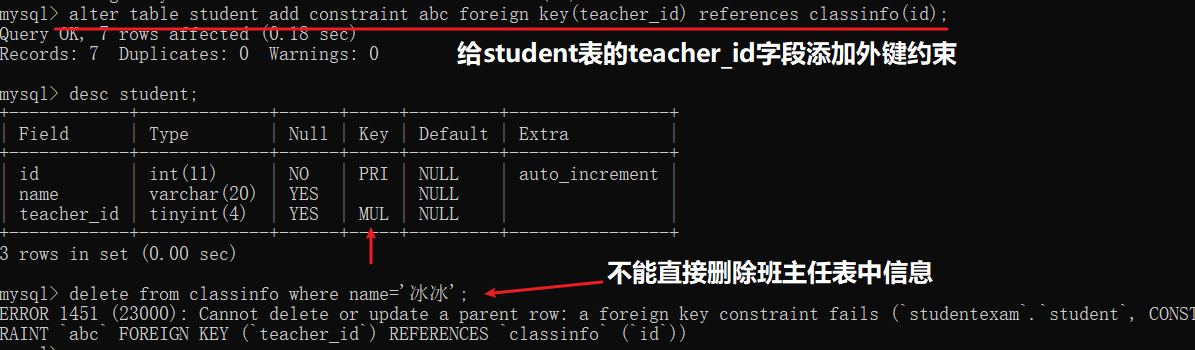
INNODB支持的ON语句(cascade set null restrict 和 no action)
--外键约束对子表的含义: 如果在父表中找不到候选键,则不允许在子表上进行insert/update --外键约束对父表的含义: 在父表上进行update/delete 在子表中有一条或多条对应匹配行的候选键时,
父表的行为取决于:在定义子表的外键时指定的on update/on delete子句 -----------------innodb支持的四种方式--------------------------------------- -----cascade方式 在父表上update/delete记录时,同步update/delete掉子表的匹配记录
-----外键的级联删除:如果父表中的记录被删除,则子表中对应的记录自动被删除-------- FOREIGN KEY (teacher_id) REFERENCES ClassInfo(id)
ON DELETE CASCADE ------set null方式 在父表上update/delete记录时,将子表上匹配记录的列设为null
-- 要注意子表的外键列不能为not null FOREIGN KEY (teacher_id) REFERENCES ClassInfo(id)
ON DELETE SET NULL ------Restrict方式 :拒绝对父表进行删除更新操作(了解) ------No action方式 在mysql中同Restrict,如果子表中有匹配的记录,则不允许对父表对应候选键
-- 进行update/delete操作(了解)
出版社(主表)-书籍(子表)
需求---删除南方出版社 及其出版的所有书
create table Publisher(
pid int primary key auto_increment,
name varchar(32) not null,
addr varchar(64)
); insert into Publisher (name,addr) values ('人民教育出版社','北京'),
('南方出版社','南京'),('浙江大学出版社','杭州'); create table Book(
bid int primary key auto_increment ,
title varchar(20),
publish_date varchar(32),
price float(10,2),
pub_id int not null,
constraint fk_bp foreign key (pub_id) references Publisher(pid) on delete cascade
); insert into Book (title,publish_date,price,pub_id) values
('python入门到精通','2013-6-14',65.99,3),
('java入门到精通','2006-6-14',45.99,2),
('C++ plus','2006-3-20',45.99,1),
('php开发','2012-3-20',33.99,3),
('django','2016-9-20',85.99,2); //需求---删除南方出版社 及其出版的所有书
delete from publisher where name='南方出版社';
多表查询
创建表
-- 准备两张表
-- company.employee
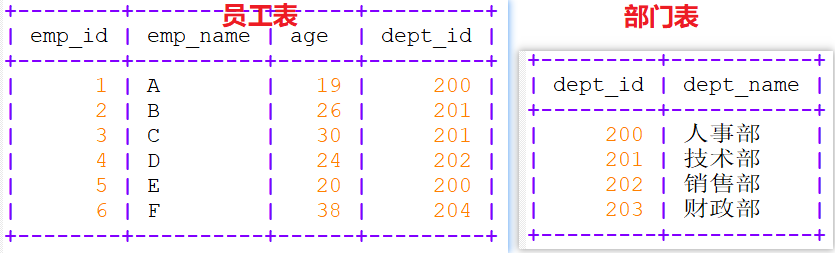
-- company.department create table employee(
emp_id int auto_increment primary key not null,
emp_name varchar(50),
age int,
dept_id int
); insert into employee(emp_name,age,dept_id) values
('A',19,200),
('B',26,201),
('C',30,201),
('D',24,202),
('E',20,200),
('F',38,204); create table department(
dept_id int,
dept_name varchar(100)
); insert into department values
(200,'人事部'),
(201,'技术部'),
(202,'销售部'),
(203,'财政部'); mysql> select * from employee;
+--------+----------+------+---------+
| emp_id | emp_name | age | dept_id |
+--------+----------+------+---------+
| 1 | A | 19 | 200 |
| 2 | B | 26 | 201 |
| 3 | C | 30 | 201 |
| 4 | D | 24 | 202 |
| 5 | E | 20 | 200 |
| 6 | F | 38 | 204 |
+--------+----------+------+---------+
rows in set (0.00 sec) mysql> select * from department;
+---------+-----------+
| dept_id | dept_name |
+---------+-----------+
| 200 | 人事部 |
| 201 | 技术部 |
| 202 | 销售部 |
| 203 | 财政部 |
+---------+-----------+
rows in set (0.01 sec)
多表查询之连接查询
1. 笛卡尔积查询
mysql> SELECT * FROM employee,department; -- select employee.emp_id,employee.emp_name,employee.age,
-- department.dept_name from employee,department; +--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 1 | A | 19 | 200 | 201 | 技术部 |
| 1 | A | 19 | 200 | 202 | 销售部 |
| 1 | A | 19 | 200 | 203 | 财政部 |
| 2 | B | 26 | 201 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 2 | B | 26 | 201 | 202 | 销售部 |
| 2 | B | 26 | 201 | 203 | 财政部 |
| 3 | C | 30 | 201 | 200 | 人事部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 202 | 销售部 |
| 3 | C | 30 | 201 | 203 | 财政部 |
| 4 | D | 24 | 202 | 200 | 人事部 |
| 4 | D | 24 | 202 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 4 | D | 24 | 202 | 203 | 财政部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| 5 | E | 20 | 200 | 201 | 技术部 |
| 5 | E | 20 | 200 | 202 | 销售部 |
| 5 | E | 20 | 200 | 203 | 财政部 |
| 6 | F | 38 | 204 | 200 | 人事部 |
| 6 | F | 38 | 204 | 201 | 技术部 |
| 6 | F | 38 | 204 | 202 | 销售部 |
| 6 | F | 38 | 204 | 203 | 财政部 |
+--------+----------+------+---------+---------+-----------+
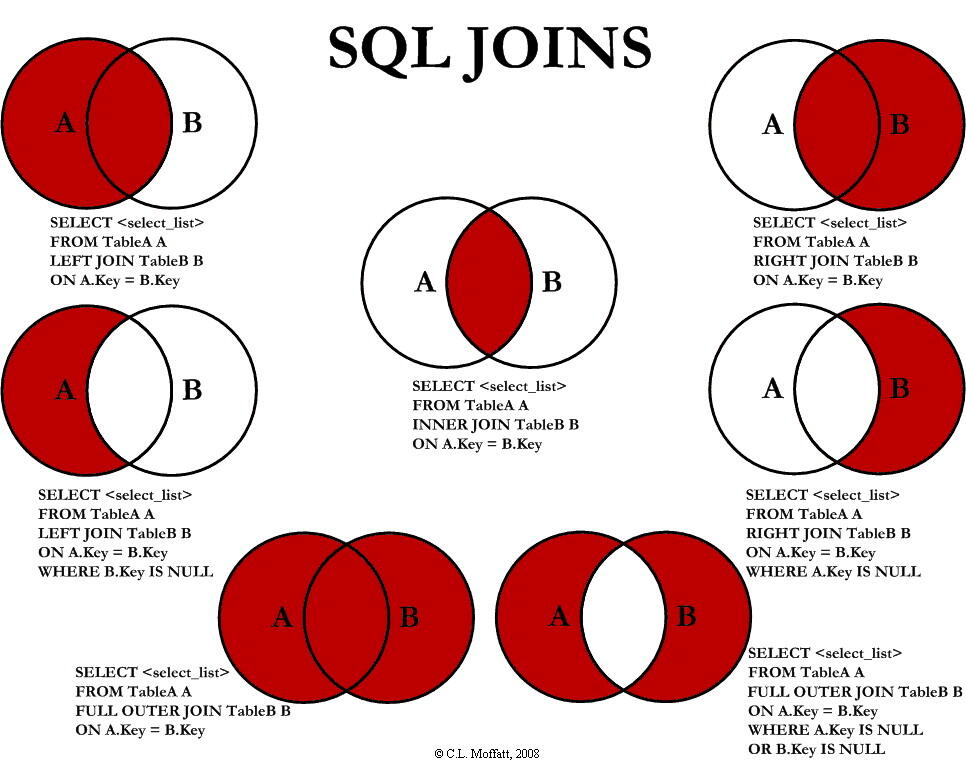
一张图看懂 join的分别
2. 内连接 inner join
-- 查询两张表中都有的关联数据,相当于利用条件从笛卡尔积结果中筛选出了正确的结果。
select * from employee,department where employee.dept_id = department.dept_id;
-- 另一种写法inner join
select * from employee inner join department on employee.dept_id = department.dept_id;
+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
+--------+----------+------+---------+---------+-----------+
3. 外连接 left join right join
mysql不支持 full join 使用union代替
tableA_name left join tableB_name on 条件 union tableA_name right join tableB_name on 条件
(1)左外连接:在内连接的基础上增加左边有右边没有的结果(左边为主)
select * from employee left join department on employee.dept_id = department.dept_id;
+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 6 | F | 38 | 204 | NULL | NULL |
+--------+----------+------+---------+---------+-----------+
--(2)右外连接:在内连接的基础上增加右边有左边没有的结果(右边为主)
select * from employee RIGHT JOIN department on employee.dept_id = department.dept_id;
+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| NULL | NULL | NULL | NULL | 203 | 财政部 |
+--------+----------+------+---------+---------+-----------+
--(3)全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
-- mysql不支持全外连接 full JOIN
-- mysql可以使用union 方式间接实现全外连接
select * from employee RIGHT JOIN department on employee.dept_id = department.dept_id UNION
select * from employee LEFT JOIN department on employee.dept_id = department.dept_id;
+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| NULL | NULL | NULL | NULL | 203 | 财政部 |
| 6 | F | 38 | 204 | NULL | NULL |
+--------+----------+------+---------+---------+-----------+
-- 注意 union与union all的区别:union会去掉相同的纪录
练习:
-- 多表查询
-- 连接查询:
-- 内连接:inner join
-- 外链接:left join
-- 全连接:full join--mysql不支持,mysql 要使用union create table employee(
emp_id int auto_increment primary key not null,
emp_name varchar(50),
age int,
dept_id int
); insert into employee(emp_name,age,dept_id) values
('A',19,200),
('B',26,201),
('C',30,201),
('D',24,202),
('E',20,200),
('F',38,204); create table department(
dept_id int,
dept_name varchar(100)
); insert into department values
(200,'人事部'),
(201,'技术部'),
(202,'销售部'),
(203,'财政部'); -- 内连接
select employee.emp_name,employee.dept_id,department.dept_name from employee,department where emp_name="A" and employee.dept_id=department.dept_id; select employee.emp_name,employee.dept_id,department.dept_name from employee inner join department on emp_name="A" and employee.dept_id=department.dept_id; -- 外链接
select employee.emp_name,employee.dept_id,department.dept_name from employee,department where employee.dept_id=department.dept_id;
-- 以左边为主
select employee.emp_name,employee.dept_id,department.dept_name from employee left join department on employee.dept_id=department.dept_id;
-- 以右边为主
select employee.emp_name,employee.dept_id,department.dept_name from employee right join department on employee.dept_id=department.dept_id;
-- 全连接
select employee.emp_name,employee.dept_id,department.dept_name from employee left join department on employee.dept_id=department.dept_id union
select employee.emp_name,employee.dept_id,department.dept_name from employee right join department on employee.dept_id=department.dept_id;
全外连接练习1:
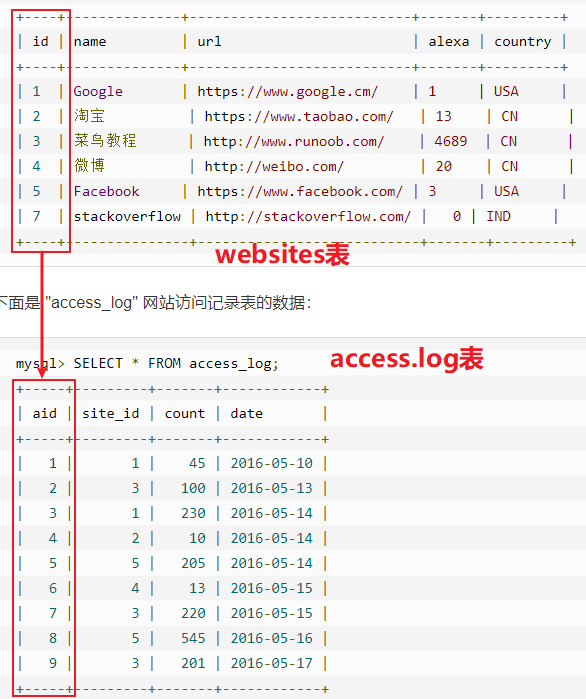
选取出websites.id != access_log.site_id 的部分
select * from websites left join access_log on websites.id=access_log.site_id
where websites.id is null or access_log.site_id is null union
select * from websites right join access_log on websites.id=access_log.site_id
where websites.id is null or access_log.site_id is null; +------+---------------+------------------------------+-------+---------+------+---------+-------+------+
| id | name | url | alexa | country | aid | site_id | count | date |
+------+---------------+------------------------------+-------+---------+------+---------+-------+------+
| 6 | 百度 | https://www.baidu.com/ | 4 | CN | NULL | NULL | NULL | NULL |
| 7 | stackoverflow | http://www.stackoverflow.org | NULL | IND | NULL | NULL | NULL | NULL |
+------+---------------+------------------------------+-------+---------+------+---------+-------+------+
多表查询之复合条件连接查询
-- 查询员工年龄大于等于25岁的部门
SELECT DISTINCT department.dept_name
FROM employee,department
WHERE employee.dept_id = department.dept_id
AND age>25;
--以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.emp_id,employee.emp_name,employee.age,department.dept_name
from employee,department
where employee.dept_id = department.dept_id
order by age asc;
练习:
-- 问题1:找出技术部总共有多少人
select employee.emp_name,employee.dept_id,department.dept_name from employee,department
where department.dept_name="技术部" and employee.dept_id=department.dept_id; -- 问题2:找出公司所有部门中年龄大于25岁的员工
select employee.emp_name,employee.age,department.dept_name from employee,department
where employee.age>25 and employee.dept_id=department.dept_id; -- 问题3:查询employ 和department表,以age字段的升序显示
select employee.emp_name,employee.age,department.dept_name from employee,department
where employee.dept_id=department.dept_id order by employee.age;
多表查询之子查询
-- 子查询是将一个查询语句嵌套在另一个查询语句中。
-- 内层查询语句的查询结果,可以为外层查询语句提供查询条件。
-- 子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
-- 还可以包含比较运算符:= 、 !=、> 、<等 -- 1. 带IN关键字的子查询 ---查询employee表,但dept_id必须在department表中出现过 select * from employee
where dept_id IN
(select dept_id from department); +--------+----------+------+---------+
| emp_id | emp_name | age | dept_id |
+--------+----------+------+---------+
| 1 | A | 19 | 200 |
| 2 | B | 26 | 201 |
| 3 | C | 30 | 201 |
| 4 | D | 24 | 202 |
| 5 | E | 20 | 200 |
+--------+----------+------+---------+
5 rows in set (0.01 sec) -- 2. 带比较运算符的子查询
=、!=、>、>=、<、<=、<> -- 查询员工年龄大于等于25岁的部门
select dept_id,dept_name from department
where dept_id IN
(select DISTINCT dept_id from employee where age>=25);
+---------+-----------+
| dept_id | dept_name |
+---------+-----------+
| 201 | 技术部 |
| 202 | 销售部 |
+---------+-----------+
-- 3. 带EXISTS关键字的子查询 -- EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
-- 而是返回一个真假值。Ture或False
-- 当返回Ture时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询 select * from employee
WHERE EXISTS
(SELECT dept_name from department where dept_id=203); #该条件判断为True 执行前面的select * from employee --department表中存在dept_id=203,Ture select * from employee
WHERE EXISTS
(SELECT dept_name from department where dept_id=205); -- Empty set (0.00 sec) ps: create table t1(select * from t2);
参考:https://www.cnblogs.com/yuanchenqi/articles/6357507.html
【Python全栈-数据库】数据库基础的更多相关文章
- Python全栈开发【基础四】
Python全栈开发[基础四] 本节内容: 匿名函数(lambda) 函数式编程(map,filter,reduce) 文件处理 迭代器 三元表达式 列表解析与生成器表达式 生成器 匿名函数 lamb ...
- Python全栈开发【基础三】
Python全栈开发[基础三] 本节内容: 函数(全局与局部变量) 递归 内置函数 函数 一.定义和使用 函数最重要的是减少代码的重用性和增强代码可读性 def 函数名(参数): ... 函数体 . ...
- Python全栈开发【基础二】
Python全栈开发[基础二] 本节内容: Python 运算符(算术运算.比较运算.赋值运算.逻辑运算.成员运算) 基本数据类型(数字.布尔值.字符串.列表.元组.字典) 其他(编码,range,f ...
- Python全栈开发【基础一】
Python全栈开发[第一篇] 本节内容: Python 的种类 Python 的环境 Python 入门(解释器.编码.变量.input输入.if流程控制与缩进.while循环) if流程控制与wh ...
- Python全栈 MongoDB 数据库(概念、安装、创建数据)
什么是关系型数据库? 是建立在关系数据库模型基础上的数据库,借助于集合代数等概念和方法来处理数据库中的数据, 同时也是一个被组织成一组拥有正式描述性的表格( ...
- Python全栈 MongoDB 数据库(聚合、二进制、GridFS、pymongo模块)
断网了2天 今天补上 聚合操作: 对文档的信息进行整理统计的操作 返回:统计后的文档集合 db.collection.aggregate() 功能:聚合函数,完成聚合操作 参数:聚合条件,配 ...
- 巨蟒python全栈开发数据库攻略1:基础攻略
1.什么是数据库? 2.数据库分类 3.数据库简单介绍 4.安装数据库 5.修改root密码 6.修改字符集 7.sql介绍 8.简单sql操作
- 巨蟒python全栈开发数据库前端1:HTML基础
1.HTML介绍 什么是前端? 前端就是我们打开浏览器的页面.,很多公司都有自己的浏览器的页面,这个阶段学习的就是浏览器界面 比如京东的界面:https://www.jd.com/ 引子 例1 soc ...
- Python全栈 MongoDB 数据库(Mongo、 正则基础、一篇通)
终端命令: 在线安装: sudo apt-get install mongodb 默认安装路径 : /var/lib/mong ...
- 巨蟒python全栈开发数据库攻略2:基础攻略2
1.存储引擎表类型 2.整数类型和sql_mode 3.浮点类&字符串类型&日期类型&集合类型&枚举类型 4.数值类型补充 5.完整性约束
随机推荐
- centos下安装Loadrunner
背景: 网上的资料呀,真是浑水摸鱼的多,有些人直接拷贝别人的帖子,这样有啥意思呢,只会让别人要搜索的时候,更扰乱些! 这里我不写步骤,我用shell把步骤弄了一下,看的懂的看,看不懂的留言吧.就酱,看 ...
- Private表示该属性(方法)为只有本类内部可以访问(类内部可见)。
Public表示该属性(方法)公开: (想用private还要用set和get方法供其他方法调用,这样可以保证对属性的访问方式统一,并且便于维护访问权限以及属性数据合法性) 如果没有特殊情况,属性一定 ...
- Kubernetes集群部署之二CA证书制作
创建TLS证书和秘钥 kubernetes 系统的各组件需要使用 TLS 证书对通信进行加密,本文档使用 CloudFlare 的 PKI 工具集 cfssl 来生成 Certificate Auth ...
- GDC2017 把“现实的天空”在游戏内再现【Forza Horizon 3】的天空表现
原文链接 http://game.watch.impress.co.jp/docs/news/1047800.html 完全表现出现实世界中各种偶然而不可预料的风景! [Forza Horiz ...
- python利用lxml读写xml格式文件
之前在转换数据集格式的时候需要将json转换到xml文件,用lxml包进行操作非常方便. 1. 写xml文件 a) 用etree和objectify from lxml import etree, o ...
- [Hinton] Neural Networks for Machine Learning - RNN
Link: Neural Networks for Machine Learning - 多伦多大学 Link: Hinton的CSC321课程笔记 补充: 参见cs231n 2017版本,ppt写得 ...
- 【Docker】文件拷贝
从容器复制到主机sudo docker cp containerID:container_path host_path docker cp 5c6ce895b979:/root/LearnPaddle ...
- nodejs小问题拾遗
1.npm WARN saveError ENOENT: no such file or directory, open 'C:\Users\Root\package.json' cd 切换到D:\n ...
- Linux Platform驱动模型(三) _platform+cdev
平台总线是一种实现设备信息与驱动方法相分离的方法,利用这种方法,我们可以写出一个更像样一点的字符设备驱动,即使用cdev作为接口,平台总线作为分离方式: xjkeydrv_init():模块加载函数 ...
- fs项目---->migrate-mongo的使用(一)
tw项目中用的是mongo数据库,数据的迁移也是需求的一部分.这时我们可以使用migrate-mongo在nodejs中方便的进行数据的迁移,以下记录一下使用的过程. 一.migrate-mongo的 ...