ElasticSearch:Lucene和ElasticSearch
Lucene的概念:
关于索引
索引(index)和搜索(搜索),在lucene以及es里面索引是一个动作,即插入动作,包括创建索引以及为索引添加文档;所有则是针对索引(添加)的文档按照评分规则进行查询索引数据,然后计算(比如评分,聚合等),以获取相应数据。
索引相关有文档相关因子(norm):norm是基于文档加权值(boost)计算出来的,和文档一并存储在索引中;
倒排项格式(Post format),到了lucene4.0,提出了解码器架构(codec architecture),让开发者能够自定义索引文件的存储方式;其中Lucenne定义了很多种倒排的格式,以解决不同的问题;
关于文档:
文档,是字段的容器,也是索引和查询操作的单元;
词向量(term vector),是针对每个文档的倒排索引(inverse index);默认是关闭,只是在某些操作比如关键字高亮上面会有这种功能打开;
字段(field),分词之后,也就是将文档进行结构化之后的列信息(元数据);
词项(term),分词之后,结构化之后的列对应的值信息,可以是一个词,也可以是短语;
Doc values:ES的核心是倒排索引,倒排索引的结构是key-value,但是key为文档的field的value,value则是文档列表;对于聚合和切面(该技术已经废弃),是要按照field为单位进行计算,倒排索引只适合于无聚合的查询;对于聚合这类计算是按照field为单位进行计算的,所以有了docvalues这种索引存储结构。我理解她是按照类似于document-field:value这样的梯度结构存储的。

上面这张图基本描述了Lucene里面的基本元素和概念;右侧上半部分是核心对象,字段,词项以及词条;左侧下半部分,实线部分的是原始的文本,文本里面包含的是"词项",然后会被Lucene解析为field,这个解析的过程都是在Lucene中完成的;解析之后,形成文档(document),文档并不只是field的容器,他还记录了词向量,就是一个文档内部的倒排索引,这个索引是啥形式不知道?还有norm,是文档相关因子,是在索引的时候的时候,根据文档加权值(boost)计算得来的(注意这个是创建索引的时候的boost,而不是查询的boost;这个是一个稳定的不变的值,是来自索引之时的)。
查询,包括两部分:词项和操作符(operator),词项就是分词后的value,操作符可以是boolean的操作符(还可以是其他的吗?),AND,OR,NOT,+,-等。这里term还有通过修饰符(modifier)比如*,?等进行修饰;

到此,其实elasticsearch和RDS之间其实有很多共同的地方:其实最终存储的目标都是结构化的数据;但是RDS是输入只能是结构化的数据,ES则可以接收非结构化的数据(文本),ES其实强大的地方就在于可以通过logstash等组件能够基于规则,解析非结构化的数据为结构化的数据,这个也是ES和RDS的本质的区别。
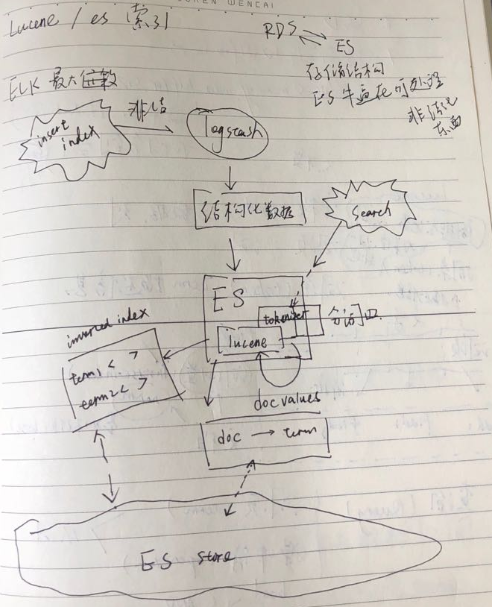
关于解析:
那么这种非结构化解析(analysis)是如何进行的呢?解析数据由三部分组件构成:
分词器(tokernizer):分词器用于对于文字进行分析(结构化处理);
过滤器:过滤器主要用于对于文字的整形和过滤,比如对于文字的大小写处理,移除非ASCII的字符等等,这个和servlet里面的filter很像,层层处理,每一个层不同的职责。
字符映射器(character mapper): 字符过滤器则是在分词前对于文件做一些预处理,比如HTML去掉标签。
ES的基本概念
基本概念:
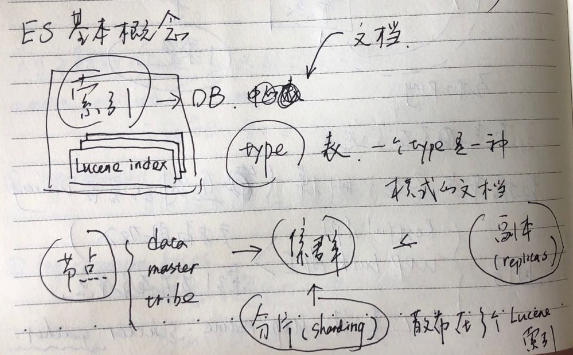
索引,ES的索引和Lucene的索引类似,不过ES的底层是现实多个条Lucene的索引的组合;ES的索引有些像数据库;
类型(type),定义了某种共通文字模式提出来,形成一种type,比如同一个源的日志,他们可以定义为一个type,这个概念比较类似于数据库中表;但是type这个概念未来将会逐渐淡出ES;因为它造成了很多困惑,这是因为在Lucene中只有索引和字段的概念;ES封装的这个type(表),所有的同名字段其实在底层实现是有lucene同一个字段来表示,之时通过另外一个字段来表示该字段属于哪个"type";这也是为什么同一个索引,不同type中的同名field必须要要同类型的原因;所以如果想要将同名字段分开来设定(比如不同的类型),将会导致底层的Lucene的异常;除此之外,type其实是希望同一个索引下,字段类型大致相同的源作为一个type,其实是允许两个源字段有差异,对于我无人有的字段可能处理为""或者NULL(有待确认),这种松制约之下,如果绑在同一个type的源,字段真的差别很大,将会导致稀疏存储,影响Lucene的压缩能力。
所以,其实不同的type可以考虑用不同的index来进行处理,而不是维持这种似是而非的关系型数据库的层级关系。
ES集群:
节点角色:
Data:数据节点;
Master:管理节点;监督各个节点情况,一个集群只有一个主节点(master node),Master管理集群的索引的元数据以及监督各个datanode的存活情况(会ping数据节点以验证存活);创建索引也是发生在主节点,因为只有主节需要记录元数据信息;
Client:用于减轻Data计算量的负载均衡的节点,比如scatter阶段获取数据,汇总过程则可以走的client节点,减轻Data节点压力;
Tribe:用于跨集群查询;但是这里有个坑,即通过Tribe进行查询的时候,尽量避免两个集群有同名索引,因为每次只能返回一个索引;返回哪一个可以是随记,或者是配置prefer集群,但是这大都无法满足需要。
分片(sharding):ES是分布式架构,数据存储也是分布式存储;一个索引在物理上是存储在多个文件中,可以便于并行查询,以及横向扩展;副本(replicas):用于数据备份和负载均衡;
关于集群证明周期:
1. Discovery
首先是集群节点的启动,节点会通过discover阶段向网络中配置的同名集群发送广播信息,告诉大家:我来了,我要加入你们,记住了。
2. Recovery
集群节点启动之后,间互ping以判断对方是否存活,master会ping data节点,如果不通,则会把它给删掉;知道该节点重启,通过discovery节点向master发送通知(其实是广播过程);data节点也会ping master节点,如果不通则需要进行选举,选出一个新的master;
3. Communication
RESTful API
UDP bulk API,但是UDP协议不保证数据传输的准确性;更多的是在集群内部使用(局域网UDP丢包情况较少);
DSL(Domain Specisal Language),就是基于JSON的结构化查询规则;
这里注意对于ES的查询都是连个阶段,Scatter以及Gather,第一个阶段发生在各个索引的物理文件上,然后进入到第二个阶段,对于数据进行汇总处理,可以是Data节点,也可以是Client节点。
ElasticSearch:Lucene和ElasticSearch的更多相关文章
- 开源搜索引擎评估:lucene sphinx elasticsearch
开源搜索引擎评估:lucene sphinx elasticsearch 开源搜索引擎程序有3大类 lucene系,java开发,包括solr和elasticsearch sphinx,c++开发,简 ...
- 干货 |《从Lucene到Elasticsearch全文检索实战》拆解实践
1.题记 2018年3月初,萌生了一个想法:对Elasticsearch相关的技术书籍做拆解阅读,该想法源自非计算机领域红火已久的[樊登读书会].得到的每天听本书.XX拆书帮等. 目前市面上Elast ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- Elasticsearch原理学习--为什么Elasticsearch/Lucene检索可以比MySQL快?
转载于:http://vlambda.com/wz_wvS2uI5VRn.html 同样都可以对数据构建索引并通过索引查询数据,为什么Lucene或基于Lucene的Elasticsearch会比关系 ...
- 《从Lucene到Elasticsearch全文检索实战》的P184页
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @books.json 这句话在书中是以crul的命令 ...
- 【ElasticSearch篇】--ElasticSearch从初识到安装和应用
一.前述 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,在企业中全文搜索时,特别常用. 二.常用概念 clu ...
- elasticsearch(六) 之 elasticsearch优化
目录 elasticsearch 优化 从硬件上 : 从软件上: 从用户使用层 elasticsearch 优化 从硬件上 : 使用SSD 硬盘,解决io导致的瓶颈. 增大内存 但不超过32G(单实例 ...
- 【原创】《从0开始学Elasticsearch》—初识Elasticsearch
目录 1. Elasticsearch 是什么2. Elasticsearch 中基本概念3. Elasticsearch 安装4. 访问 Elasticsearch 1. Elasticsearch ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- 【分布式搜索引擎】Elasticsearch之开启Elasticsearch的用户名密码验证
一.首先在elasticsearch配置文件中开启x-pack验证, 修改config目录下面的elasticsearch.yml文件,在里面添加如下内容,并重启 xpack.security.ena ...
随机推荐
- ionic的actionsheet安卓样式不正常的坑及解决之道
这是actionsheet该有的样子,可是android下变成了这样: 百度后,发现修改lonic.css,注释这段代码就可以了:
- python django 创建虚拟环境
DRF---django-rest-framework: 1.通过一个案例简单回顾一下django, 一.前后端分离,不分离 不分离:前端页面的显示,都是由后端返回的,就是说后端处理了参数,数据库,之 ...
- 2017中国大学生程序设计竞赛 - 网络选拔赛 HDU 6154 CaoHaha's staff(几何找规律)
Problem Description "You shall not pass!"After shouted out that,the Force Staff appered in ...
- Django + nginx + uswgi 的部署总结
一.引言 自己小组内写了一个网站,需要部署到远程服务器,搜索了好多资料,但是大部分资料都比较繁琐,并且没有一个教程能够直接从头到尾适合,在部署过程中,我是按照很多教程然后综合试验着逐渐部署成功,其中有 ...
- threejs path controls example html
<!DOCTYPE html> <html lang="en"> <head> <title>three.js webgl - pa ...
- Redis过期策略(转)
1.设置过期时间 expire key time(以秒为单位)--这是最常用的方式 setex(String key, int seconds, String value)--字符串独有的方式 具体的 ...
- Python urllib.quote
转: 编码:urllib.quote(string[, safe]),除了三个符号“_.-”外,将所有符号编码,后面的参数safe是不编码的字符, 使用的时候如果不设置的话,会将斜杠,冒号,等号,问号 ...
- 百练-16年9月推免-C题-图像旋转
C:图像旋转 查看 提交 统计 提问 总时间限制: 1000ms 内存限制: 65536kB 描述 输入一个n行m列的黑白图像,将它顺时针旋转90度后输出. 输入 第一行包含两个整数n和m,表示图 ...
- ortp 发送RTP实例
参考源代码目录src/tests/rtpsend.c ortp_init(); ortp_scheduler_init(); ortp_set_log_level_mask(O ...
- get新技能:上传了 flv 或 MP4 文件到服务器,可访问总是出现 “无法找到该页”的 404 错误
为什么我上传了 flv 或 MP4 文件到服务器,可访问总是出现 “无法找到该页”的 404 错误 为什么我上传了 flv 或 MP4 文件到服务器,可输入正确地址通过协议来访问总是出现 “无法找到该 ...