【翻译】OpenVINO Pre-Trained 预训练模型介绍
OpenVINO 系列软件包预训练模型介绍
本文翻译自 Intel OpenVINO 的 "Overview of OpenVINO Toolkit Pre-Trained Models"
原文链接: https://docs.openvinotoolkit.org/latest/_models_intel_index.html
翻译:coneypo,working in Intel for IoT,有问题或者建议欢迎留言交流
Q&A
问:用 Pre-trained model 可以干什么?
答:我们可以用 Pre-trained 的模型直接输入数据进行 model inference / 推理,而不需要收集数据集自己 Train 一个 model,这些训练好的模型拿来即用,适合新手学习;
问:如何使用 OpenVINO 预训练模型进行推算?
答:
1. 先下载安装 OpenVINO 环境: https://docs.openvinotoolkit.org/cn/index.html;
2. OpenVINO 提供的 model zoo 的示例代码在这个 repo :
$ git clone https://github.com/opencv/open_model_zoo
$ cd /open_model_zoo/demos/python_demos/
3. 比如有一个 face_recognition_demo/ 文件夹,里面有个 README.md 告诉怎么配置参数:
python ./face_recognition_demo.py ^
-m_fd <path_to_model>/face-detection-retail-0004.xml ^
-m_lm <path_to_model>/landmarks-regression-retail-0009.xml ^
-m_reid <path_to_model>/face-reidentification-retail-0095.xml ^
--verbose ^
-fg "C:/face_gallery"4. 下载模型
$ cd /<OPENVINO_INSTALL_DIR>/deployment_tools/open_model_zoo/tools/downloader/
$ sudo ./downloader.py --name face-detection-retail-0004
$ sudo ./downloader.py --name landmarks-regression-retail-0009.xml
$ sudo ./downloader.py --name face-reidentification-retail-0095.xml
5. 运行 face_recognition_demo.py
这篇文章中会介绍如下模型:
- Object Detection Models / 目标检测模型
- Object Recognition Models / 目标识别模型
- Reidentification Models / 回归模型
- Semantic Segmentation Models / 语义分割模型
- Instance Segmentation Models / 实例分割模型
- Human Pose Estimation Models / 人类姿势识别模型
- Image Processing/ 图像处理
- Text Detection / 文本检测
- Text Recognition / 文本识别
- Text Spotting / 文本识别
- Action Recognition Models / 动作识别模型
- Image Retrieval / 图像检索
- Compressed models / 压缩模型
OpenVINO 软件包提供一系列预训练模型,你可以用来进行学习,或者进行参考设计;
OpenVINO 的版本会在 Github_open_model zoo 上面进行维护;
这些模型也可以通过模型下载器 (<OPENVINO_INSTALL_DIR>/deployment_tools/open_model_zoo/tools/downloader) 下载,或者在 01.org 进行手动下载;
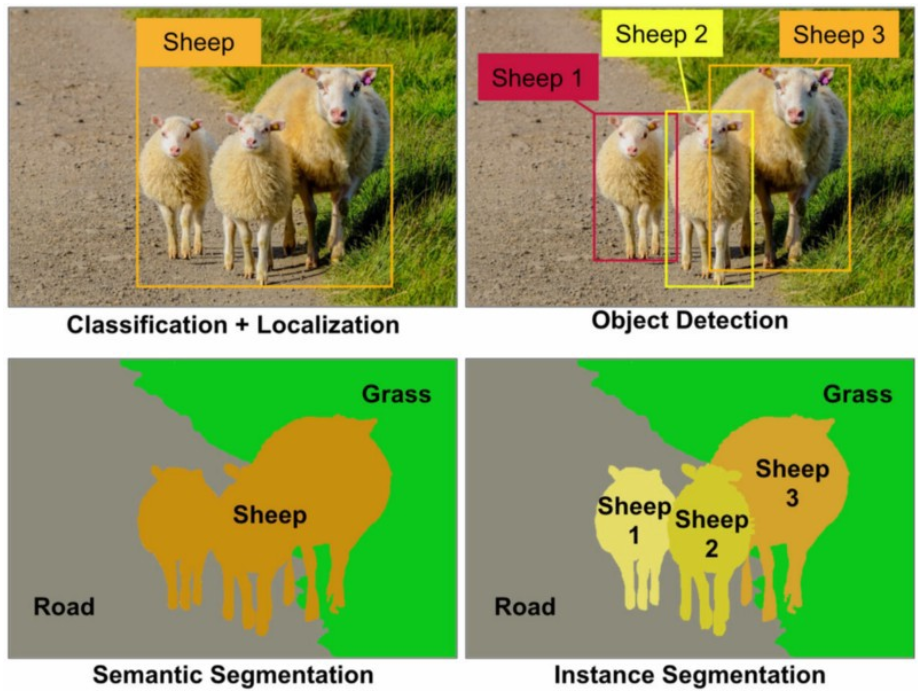
*(补充)Classification / 分类,Detection / 检测,Semantic Segmentation / 语义分割,Instance Segmentation / 实例分割 区别
Object Detection Models / 目标检测模型
OpenVINO 提供一系列热门目标,如人脸/人/汽车等等的检测模型;大多数网络都是基于 SSD (Single Shot MultiBox Detector),而且准确度和性能都不错;
针对于检测相同类型目标的网络(比如 face-detection-adas-0001 和 face-detection-retail-0004),能够以较小的性能代价,让我们达到更高的精度和更广的适用范围;
因此你可以期待一个更大的神经网络,来更好的检测相同类型的对象;
Object Recognition Models / 目标识别模型
目标识别模型用来进行 Classification / 分类,Regression / 回归,Charcter recognition / 特征识别;
针对某种特征进行检测之后,再使用这些神经网络进行检测/识别(比如在人脸识别之后,再进行年龄/性别的识别);
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| age-gender-recognition-retail-0013 | 0.094 | 2.138 |
| head-pose-estimation-adas-0001 | 0.105 | 1.911 |
| license-plate-recognition-barrier-0001 | 0.328 | 1.218 |
| vehicle-attributes-recognition-barrier-0039 | 0.126 | 0.626 |
| emotions-recognition-retail-0003 | 0.126 | 2.483 |
| landmarks-regression-retail-0009 | 0.021 | 0.191 |
| facial-landmarks-35-adas-0002 | 0.042 | 4.595 |
| person-attributes-recognition-crossroad-0230 | 0.174 | 0.735 |
| gaze-estimation-adas-0002 | 0.139 | 1.882 |
Reidentification Models / 再识别模型
在视频中,进行精准的目标追踪是计算机视觉的典型应用场景;
它通常会因为一系列的事情而变得相对比较复杂,这些事情可以描述为 "Relatively long absence of an object" / 一个对象相对较长的缺失;
比如,可能由于 occlusion / 遮挡 或者 out-of-frame movement / 框外移动 导致的;
针对这种情况,最好将目标视为 "seen before" / 先前见过的,而不管其在图像中的当前位置,或者距离上次识别出位置经过多长时间;
下面的网络用在以上这种情况,这些网络获取一个人的图像,然后将这个人的特征在高维空间中进行评估;这些特征向量会进行进一步评估:通过比较欧式距离来确定是否是同一个人;
这里提供了几种模型,在性能和精确度之间进行权衡(模型更大,性能更好):
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) | RANK-1 ON MARKET-1501 数据集 |
|---|---|---|---|
| person-reidentification-retail-0031 | 0.028 | 0.280 | 92.11% |
| person-reidentification-retail-0248 | 0.174 | 0.183 | 84.3% |
| person-reidentification-retail-0249 | 0.564 | 0.597 | 92.9% |
| person-reidentification-retail-0300 | 3.521 | 5.289 | 96.3% |
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) | RANK-1 ON MARKET-1501 数据集 |
|---|---|---|---|
| face-reidentification-retail-0095 | 0.588 | 1.107 | 99.33% |
Semantic Segmentation Models / 语义分割模型
语义分割可以归为目标检测的拓展问题;
返回的不是特征框,语义分割模型返回输入图像(图像中每个像素的颜色代表着特定的类别)的 Painted version / 涂色块;
这些网络比目标检测网络要复杂的多,但是提供了一个像素级别的分类,属于同一类的像素会被归为一类(涂上相同颜色),而且可以检测到复杂图形中的空间(比如道路中的可用区域);
| 模型名称 | 复杂度(GFLOPS) | 大小 (MP) |
|---|---|---|
| road-segmentation-adas-0001 | 4.770 | 0.184 |
| semantic-segmentation-adas-0001 | 58.572 | 6.686 |
| unet-camvid-onnx-0001 | 260.1 | 31.03 |
| icnet-camvid-ava-0001 | 151.82 | 25.45 |
| icnet-camvid-ava-sparse-30-0001 | 151.82 | 25.45 |
| icnet-camvid-ava-sparse-60-0001 | 151.82 | 25.45 |
Instance Segmentation Models / 实例分割模型
实例分割模型是目标检测和语义分割的拓展;
实例分割模型不是对每个目标实例进行特征框预测分析,而是为每个实例生成像素级别的遮罩;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| instance-segmentation-security-1025 | 30.146 | 26.69 |
| instance-segmentation-security-0050 | 46.602 | 30.448 |
| instance-segmentation-security-0083 | 365.626 | 143.444 |
| instance-segmentation-security-0010 | 899.568 | 174.568 |
Human Pose Estimation Models / 人类姿势估计模型
人体姿势估计任务用来预测姿势:对于输入的图像或者视频,推断出带有特征点和特征点之间连接的身体骨骼;特征点是身体器官:比如耳朵,眼睛,鼻子,胳膊,膝盖等等;
有两种主要的分类:top-down / 从上往下, bottom-up / 从下往上;
第一种方法在给定的帧中,检测出人,然后裁剪和调整,运行姿势估计网络为每个检测出来的人,这种方法很精确;
第二种找到给定的帧中,所有的特征点,然后根据人的实例进行分类,因此比第一种更快,因为网络只运行了一次;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| human-pose-estimation-0001 | 15.435 | 4.099 |
Image Processing / 图像处理
深度学习模型在图像处理中应用来提高输出质量:
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| single-image-super-resolution-1032 | 11.654 | 0.030 |
| single-image-super-resolution-1033 | 16.062 | 0.030 |
| text-image-super-resolution-0001 | 1.379 | 0.003 |
Text Detection / 文本检测
深度学习模型在文本检测中进行应用:
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| text-detection-0003 | 51.256 | 6.747 |
| text-detection-0004 | 23.305 | 4.328 |
Text Recognition / 文本识别
深度学习模型在文本识别中应用;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| text-recognition-0012 | 1.485 | 5.568 |
| handwritten-score-recognition-0003 | 0.792 | 5.555 |
| handwritten-japanese-recognition-0001 | 117.136 | 15.31 |
Text Spotting / 文本定位识别
深度学习模型用于文本检测识别;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| text-spotting-0002-detector | 185.169 | 26.497 |
| text-spotting-0002-recognizer-encoder | 2.082 | 1.328 |
| text-spotting-0002-recognizer-decoder | 0.002 | 0.273 |
Action Recognition Models / 动作识别模型
动作识别模型对一个视频短片(通过堆叠来自输入视频的采样帧得到的张量)预测动作;
一些模型从不同的视频片段中提取(比如 driver-action-recognition-adas-0002 可能会使用预计算的高维度)特征(嵌入) 然后整合到一个临时模型中,用分类分数来预测一个向量;
计算嵌入的模型称为 encoder / 编码器,用来预测真实标签的模型称为 decoder / 解码器;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| driver-action-recognition-adas-0002-encoder | 0.676 | 2.863 |
| driver-action-recognition-adas-0002-decoder | 0.147 | 4.205 |
| action-recognition-0001-encoder | 7.340 | 21.276 |
| action-recognition-0001-decoder | 0.147 | 4.405 |
| asl-recognition-0004 | 6.660 | 4.133 |
Image Retrieval / 图像检索
深度学习模型用来进行图像检索(根据相似度对图像进行排序);
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| image-retrieval-0001 | 0.613 | 2.535 |
Compressed Models / 压缩模型
深度学习压缩模型;
| 模型名称 | 复杂度 (GFLOPS) | 大小 (MP) |
|---|---|---|
| resnet50-binary-0001 | 1.002 | 7.446 |
| resnet18-xnor-binary-onnx-0001 | - | - |
欢迎使用 Intel OpenVINO Toolkit 进行 AI 开发,OpenVINO(SW)+ MyriadX VPU(HW) 主要侧重于 Inference 推算时的加速,借助 Intel VPU 可以对边缘端设备推演时进行加速;
我会在之后的 blog 里面更新详细的 sample code 的用法;
开发过程中若有问题欢迎留言;
【翻译】OpenVINO Pre-Trained 预训练模型介绍的更多相关文章
- Pytorch——BERT 预训练模型及文本分类
BERT 预训练模型及文本分类 介绍 如果你关注自然语言处理技术的发展,那你一定听说过 BERT,它的诞生对自然语言处理领域具有着里程碑式的意义.本次试验将介绍 BERT 的模型结构,以及将其应用于文 ...
- 我的Keras使用总结(3)——利用bottleneck features进行微调预训练模型VGG16
Keras的预训练模型地址:https://github.com/fchollet/deep-learning-models/releases 一个稍微讲究一点的办法是,利用在大规模数据集上预训练好的 ...
- 【小白学PyTorch】5 torchvision预训练模型与数据集全览
文章来自:微信公众号[机器学习炼丹术].一个ai专业研究生的个人学习分享公众号 文章目录: 目录 torchvision 1 torchvision.datssets 2 torchvision.mo ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- 预训练模型时代:告别finetune, 拥抱adapter
NLP论文解读 原创•作者 |FLIPPED 研究背景 随着计算算力的不断增加,以transformer为主要架构的预训练模型进入了百花齐放的时代.BERT.RoBERTa等模型的提出为NLP相关问题 ...
- 管正雄:基于预训练模型、智能运维的QA生成算法落地
分享嘉宾:管正雄 阿里云 高级算法工程师 出品平台:DataFunTalk 导读:面对海量的用户问题,有限的支持人员该如何高效服务好用户?智能QA生成模型给业务带来的提效以及如何高效地构建算法服务,为 ...
- 文本分类实战(九)—— ELMO 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- [Pytorch]Pytorch加载预训练模型(转)
转自:https://blog.csdn.net/Vivianyzw/article/details/81061765 东风的地方 1. 直接加载预训练模型 在训练的时候可能需要中断一下,然后继续训练 ...
随机推荐
- vue--基础应用 全选
1.用computed实现全选 <body> <div id="app"> <input type="checkbox" v-mo ...
- (转)const的内部链接属性(C++中适用)
转载自:http://xiangwangfeng.com/2011/05/02/const%E7%9A%84%E5%86%85%E9%83%A8%E9%93%BE%E6%8E%A5%E5%B1%9E% ...
- docker-ce 在windows10下使用volume的注意事项
最近想搭建一套CI/CD环境尝试一下,因为手里云服务太小了(1C1G),撑不起来gitlab和jenkins.恰巧年前配了台高配版的windows机器,就想在家里的机器上通过docker装gitlab ...
- Spring Boot入门系列(九)如何实现异步执行任务
前面介绍了Spring Boot 如何整合定时任务,不清楚的朋友可以看看之前的文章:https://www.cnblogs.com/zhangweizhong/category/1657780.htm ...
- HTTP2.0学习 与 Nginx和Tomcat配置HTTP2.0
目录 一.HTTP2.0 1.1 简介 1.2 新的特性 1.3 h2c 的支持度 二.Nginx 对 http2.0 的支持 2.1 Nginx 作为服务端使用http2.0 2.2 Nginx 作 ...
- JS事件流模型
JS事件流模型 事件捕获Event Capturing是一种从上而下的传播方式,以click事件为例,其会从最外层根节向内传播到达点击的节点,为从最外层节点逐渐向内传播直到目标节点的方式. 事件冒泡E ...
- Github代码高级搜索小技巧
Github搜索之代码搜索 可以使用下列搜索限定符的任意组合进行代码搜索 提示:通过将一连串的搜索语法添加到搜索限定符来进一步提高搜索结果的精度. ·代码搜索注意事项 由于搜索代码的复杂性,有一些搜索 ...
- nmap加载nse脚本在内网渗透中的使用-上
转载自:https://mp.weixin.qq.com/s/zEgHxJEOfaiYVZYmg7NnXA? 大多数情况下,大家都认为nmap只是一个扫描工具,而不把当成是一个渗透工具.nmap集成了 ...
- hdu1532 用BFS求拓扑排序
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1285 题目给出一些点对之间的先后顺序,要求给出一个字典序最小的拓扑排列.对于拓扑排序的问题,我们有DF ...
- 金融和IT的区别
在进入金融圈之前, 我写了十五年的代码, 在San Francisco Bay Area(也就是中国人所说的硅谷)工作过两三年. 去年因为Fintech和香港.NET俱乐部的缘故, 我接触了私人银行和 ...