Java实现BFS广度优先查找
1 问题描述
广度优先查找(Breadth-first Search,BFS)按照一种同心圆的方式,首先访问所有和初始顶点邻接的顶点,然后是离它两条边的所有未访问顶点,以此类推,直到所有与初始顶点同在一个连通分量中的顶点都被访问过了为止。如果仍然存在未被访问的顶点,该算法必须从图的其他连接分量中的任意顶点重新开始。
2 解决方案
2.1 蛮力法
此处借用《算法设计与分析基础》(第3版)上一段文字介绍及其配图来讲解,下面程序中使用的图就是配图中所给的数据,在程序中,使用邻接矩阵来表示配图中图。

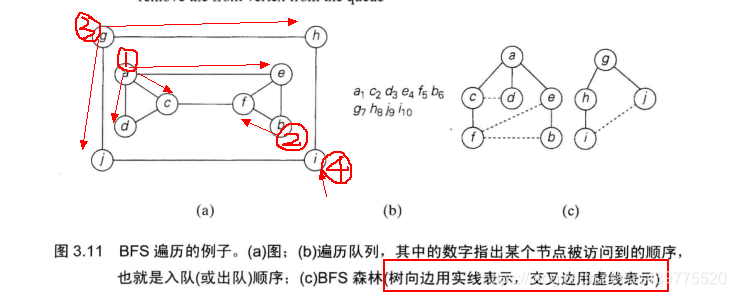
PS:下面所给程序的运行结果和配图中图(b)顺序在fb那两个位置不一致,下面程序运行结果顺序是acdebfghji,原因是在遍历的过程中,我所写代码是按照字母顺序来进行遍历的,书上所讲可能是使用链表来存储顶点,具体怎么实现本人也未去仔细探讨…
package com.liuzhen.chapterThree;
public class BreadthFirstSearch {
public int count = 0; //计算广度优先遍历总次数,初始化为0
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历,其最终具体结果代表该顶点在最终遍历顺序中的位置
* result用于存放广度优先遍历的顶点顺序
*/
public void bfs(int[][] adjMatrix,int[] value,char[] result){
for(int i = 0;i < value.length;i++){
if(value[i] == 0){ //当该顶点未被遍历时
char temp = (char) ('a' + i);
result[count] = temp;
System.out.println();
System.out.println("出发点:"+temp+"地");
bfsVisit(adjMatrix,value,result,i); //使用迭代遍历该顶点周边所有邻接顶点
}
}
}
/*
* adjMatrix是待遍历图的邻接矩阵
* value是待遍历图顶点用于是否被遍历的判断依据,0代表未遍历,非0代表已被遍历,其最终具体结果代表该顶点在最终遍历顺序中的位置
* result用于存放广度优先遍历的顶点顺序
* number是当前正在遍历的顶点在邻接矩阵中的数组下标编号
*/
public void bfsVisit(int[][] adjMatrix,int[] value,char[] result,int number){
value[number] = ++count; //出发顶点已被遍历,其在遍历结果中最终位置为++count
for(int i = 0;i < value.length;i++){
if(adjMatrix[number][i] == 1 && value[i] == 0){ //当改顶点与出发顶点相邻且未被遍历时
char temp = (char) ('a' + i);
result[count] = temp;
System.out.print("到达"+temp+"地"+"\t");
value[i] = ++count; //当前被遍历顶点,其在遍历结果中最终位置为++count
}
}
}
public static void main(String[] args){
int[] value = new int[10]; //初始化后,各元素均为0
char[] result = new char[10];
char[] result1 = new char[10];
int[][] adjMatrix = {{0,0,1,1,1,0,0,0,0,0},
{0,0,0,0,1,1,0,0,0,0},
{1,0,0,1,0,1,0,0,0,0},
{1,0,1,0,0,0,0,0,0,0},
{1,1,0,0,0,1,0,0,0,0},
{0,1,1,0,1,0,0,0,0,0},
{0,0,0,0,0,0,0,1,0,1},
{0,0,0,0,0,0,1,0,1,0},
{0,0,0,0,0,0,0,1,0,1},
{0,0,0,0,0,0,1,0,1,0}};
BreadthFirstSearch test = new BreadthFirstSearch();
test.bfs(adjMatrix, value, result);
System.out.println();
System.out.println("判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历):");
for(int i = 0;i < value.length;i++)
System.out.print(" "+value[i]);
//依据具体顶点在遍历结果顺序中最终位置,计算其具体遍历顺序为result1数组序列
for(int i = 0;i < value.length;i++){
result1[value[i]-1] = (char) ('a' + i);
}
System.out.println();
System.out.println("判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历,其具体数字代表其原地点在被遍历结果中所处位置:):");
for(int i = 0;i < value.length;i++)
System.out.print(" "+result1[i]);
System.out.println();
System.out.println("广度优先查找遍历顺序如下:");
for(int i = 0;i < result.length;i++)
System.out.print(" "+result[i]);
}
}
运行结果:
出发点:a地
到达c地 到达d地 到达e地
出发点:b地
到达f地
出发点:g地
到达h地 到达j地
出发点:i地
判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历):
5 2 3 4 6 7 8 10 9
判断节点是否被遍历结果(0代表未遍历,非0代表已被遍历,其具体数字代表其原地点在被遍历结果中所处位置:):
a c d e b f g h j i
广度优先查找遍历顺序如下:
a c d e b f g h j i
Java实现BFS广度优先查找的更多相关文章
- 算法笔记_021:广度优先查找(Java)
目录 1 问题描述 2 解决方案 2.1 蛮力法 1 问题描述 广度优先查找(Breadth-first Search,BFS)按照一种同心圆的方式,首先访问所有和初始顶点邻接的顶点,然后是离它两条边 ...
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- Java中常用的查找算法——顺序查找和二分查找
Java中常用的查找算法——顺序查找和二分查找 神话丿小王子的博客 一.顺序查找: a) 原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数据最后一位 ...
- Java学习之二分查找算法
好久没写算法了.只记得递归方法..结果测试下爆栈了. 思路就是取范围的中间点,判断是不是要找的值,是就输出,不是就与范围的两个临界值比较大小,不断更新临界值直到找到为止,给定的集合一定是有序的. 自己 ...
- Java进阶(三十九)Java集合类的排序,查找,替换操作
Java进阶(三十九)Java集合类的排序,查找,替换操作 前言 在Java方向校招过程中,经常会遇到将输入转换为数组的情况,而我们通常使用ArrayList来表示动态数组.获取到ArrayList对 ...
- BFS广度优先搜索 poj1915
Knight Moves Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 25909 Accepted: 12244 Descri ...
- JS广度优先查找无向无权图两点间最短路径
广度优先查找无向无权图两点间最短路径,可以将图看成是以起点为根节点的树状图,每一层是上一层的子节点,一层一层的查找,直到找到目标节点为止. 起点为0度,与之相邻的节点为1度,以此类推. // 广度优先 ...
- 0算法基础学算法 搜索篇第二讲 BFS广度优先搜索的思想
dfs前置知识: 递归链接:0基础算法基础学算法 第六弹 递归 - 球君 - 博客园 (cnblogs.com) dfs深度优先搜索:0基础学算法 搜索篇第一讲 深度优先搜索 - 球君 - 博客园 ( ...
- 算法竞赛——BFS广度优先搜索
BFS 广度优先搜索:一层一层的搜索(类似于树的层次遍历) BFS基本框架 基本步骤: 初始状态(起点)加到队列里 while(队列不为空) 队头弹出 扩展队头元素(邻接节点入队) 最后队为空,结束 ...
随机推荐
- gather函数
gather(input, dim, index):根据 index,在 dim 维度上选取数据,输出的 size 与 index 一致 # input (Tensor) – 源张量 # ...
- 使用Python创建一个系统监控程序--李渣渣(lizaza.cn)
最近在做个人网站,但是由于服务器资源不足,偶尔会出现系统崩溃的现象,所以想写一个程序来实时监控系统状态.当系统资源占用过高时发送邮件提醒. psutil(进程和系统实用程序)是一个跨平台的库,用于检索 ...
- 如何在Github快速找到资源(资源快速检索)
github 资源检索 Github上的资源如漫天星辰,如果没有技巧,盲目的瞎找,想找到自己想要学习的的知识和资源如大海捞针!!!! 掌握正确的方法,可以说是"妈妈再也不用担心,你找不到代码 ...
- webpack配置篇
开发环境(development)和生产环境(production)的构建目标差异很大.在开发环境中,我们需要具有强大的.具有实时重新加载(live reloading)或热模块替换(hot modu ...
- Jquery学习2---倒计时
以下代码是mvc4.0代码,其功能是让页面上的数字3,变2,变1 然后跳转页面 @{ ViewBag.Title = "LoginOut"; } <html> < ...
- centos8.0安装docker & docker-compose
centos8.0安装docker&docker-compose 背景简介: 现在centos已经到了8 ,一直在接触容器方面,为了尝鲜,下载了CentOS8,并尝试安装docker& ...
- python list 与 String 互相转换
str0 = '127.0.0.1' list0 = str0.split('.') print(list0) #['127', '0', '0', '1'] str1 = '#'.join(list ...
- Java——关键字和保留字
Java关键字50个 abstract assert boolean break byte case catch char class const continue default do double ...
- redis 启动停止重启
启动服务: service redis start 停止服务: service redis stop 重启服务: service redis restart
- 12.Java连接Redis_Jedis_常用API
上一篇总结我们使用我们本地的Eclipse中创建的jedis工程,链接到了我们处于VMware虚拟机上的Linux系统上的Redis服务,我们接下来讲一下jedis的一些常用的API. (1)jedi ...