吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas
import pandas as pd # creating a DataFrame
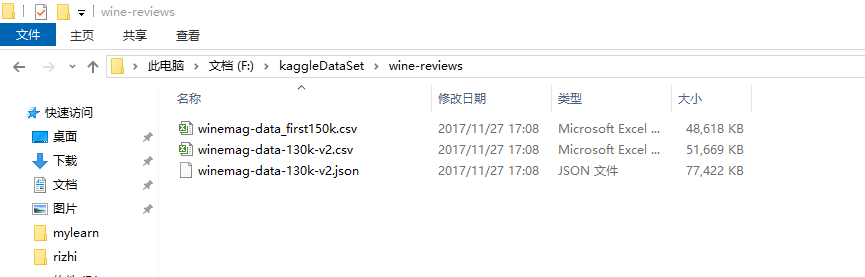
pd.DataFrame({'Yes': [50, 31], 'No': [101, 2]})
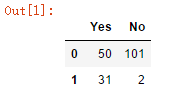
# another example of creating a dataframe
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland']})
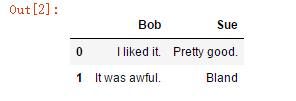
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index = ['Product A', 'Product B'])

# creating a pandas series
pd.Series([1, 2, 3, 4, 5])

# we can think of a Series as a column of a DataFrame.
# we can assign index values to Series in same way as pandas DataFrame
pd.Series([10, 20, 30], index=['2015 sales', '2016 sales', '2017 sales'], name='Product A')

# reading a csv file and storing it in a variable
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv")
# we can use the 'shape' attribute to check size of dataset
wine_reviews.shape
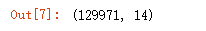
# To show first five rows of data, use 'head()' method
wine_reviews.head()
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
wine_reviews.head().to_csv("F:\\wine_reviews.csv")
import pandas as pd
reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
reviews
# access 'country' property (or column) of 'reviews'
reviews.country

# Another way to do above operation
# when a column name contains space, we have to use this method
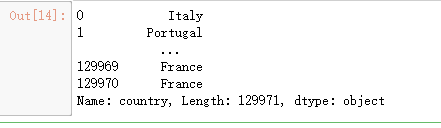
reviews['country']
# To access first row of country column
reviews['country'][0]

# returns first row
reviews.iloc[0]

# returns first column (country) (all rows due to ':')
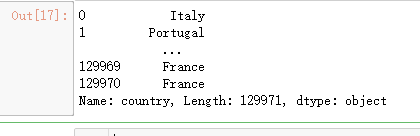
reviews.iloc[:, 0]
# retruns first 3 rows of first column
reviews.iloc[:3, 0]

# we can pass a list of indices of rows/columns to select
reviews.iloc[[0, 1, 2, 3], 0]

# We can also pass negative numbers as we do in Python
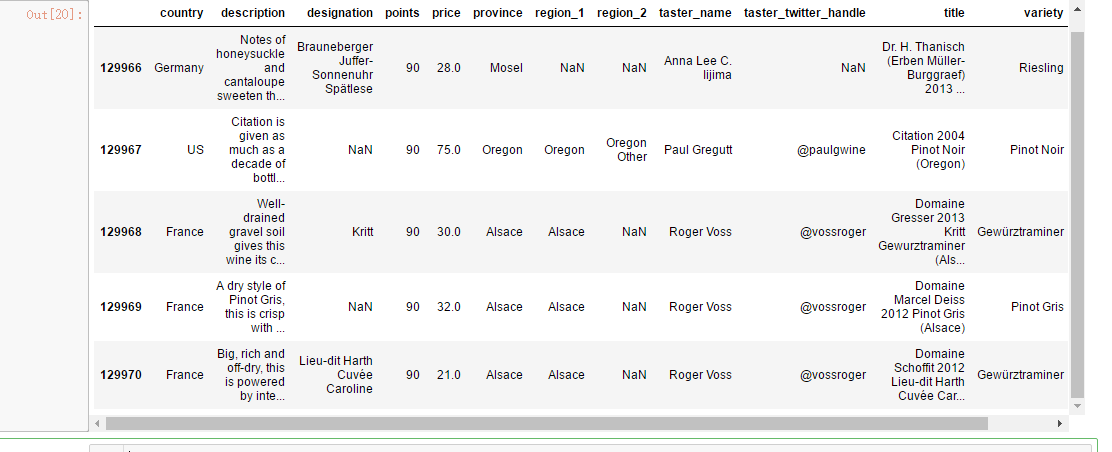
reviews.iloc[-5:]
# To select first entry in country column
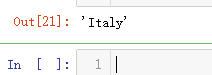
reviews.loc[0, 'country']
# select columns by name using 'loc'
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
# 'set_index' to the 'title' field
reviews.set_index('title')

# 1. Find out whether wine is produced in Italy
reviews.country == 'Italy'

# 2. Now select all wines produced in Italy
reviews.loc[reviews.country == 'Italy'] #reviews[reviews.country == 'Italy']
# Add one more condition for points to find better than average wines produced in Italy
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)] # use | for 'OR' condition
reviews.loc[reviews.country.isin(['Italy', 'France'])]
reviews.loc[reviews.price.notnull()]
reviews['critic'] = 'everyone'
reviews.critic

# using iterable for assigning
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']

吴裕雄--天生自然 python数据分析:葡萄酒分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv") df[&quo ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- NWERC 2015
2015-2016 Northwestern European Regional Contest (NWERC 2015) F H没做 似乎只有 B 题有点意思 D:数论分块枚举所有上取整区间,只需要 ...
- 3.docker machine 连接 aliyun 远程docker 服务器
1.在aliyun ecs 创建docker 服务器 docker-machine create -d aliyunecs machine-aliyunecs 2.远程连接 docker 获取客户端 ...
- docker 一些简略环境搭建及部分链接
1.center 7 搭建 docker https://www.cnblogs.com/yufeng218/p/8370670.html 2.docker 命令 https://www.cnblo ...
- Django 多对多 关系
多对多,本意就是多个一对多的关系 定义多对多 ManyToManyField 字段 from django.db import models # 学生类 class Student(models.Mo ...
- StartDT AI Lab | 智能运筹助力企业提升决策效率、优化决策质量
在人工智能和大数据时代,越来越多的云上数据和越来越智能的模型开始辅助人们做出各种最优决策,从运营效率.成本节约.最优配置等方方面面,实现降本增效,进一步提升商业效率.京东.美团.滴滴.顺丰等众多知名厂 ...
- 模型层字段-多表查询-神奇的双下划线查询-F,Q查询
Django ORM中常用的字段和参数 常用字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列,则自动会创建一个列名为id的列. In ...
- Opencv笔记(七)——访问与操作像素
一.获取矩阵的元素 1.获取三维矩阵img[i,j]处的元素 (b,g,r) = image[i,j],image大小为:MxNxK. 2.获取三维矩阵的子矩阵的全部元素 newimage = ima ...
- Metasploit详解
title date tags layout Metasploit 详解 2018-09-25 Metasploit post 一.名词解释 exploit 测试者利用它来攻击一个系统,程序,或服务, ...
- Java--面向对象三大特征-->封装、继承、多态
简介 在面向过程当中只有存在封装(对功能的封装 例如c语言中的函数),而在面向对象中才存在这三大特性. 继承 -->inheritance 1.子类可以从父类继承属性和方法(除去父类私有化的方法 ...
- CodeForces 91B Queue (线段树,区间最值)
http://codeforces.com/problemset/problem/91/B B. Queue time limit per test: 2 seconds memory limit p ...