MS SQL统计信息浅析下篇
MS SQL统计信息浅析上篇对SQL SERVER 数据库统计信息做了一个整体的介绍,随着我对数据库统计信息的不断认识、理解,于是有了MS SQL统计信息浅析下篇。 下面是我对SQL Server统计信息的一些探讨或认识,如有不对的地方,希望大家能够指正。
触发统计信息更新条件疑问
关于这个触发统计信息更新的条件。因为我在很多资料上看到过,例如Microsoft SQL Server 企业级平台管理实践。 我自己上篇也是这样解释的。
1:普通表上,触发数据库自动更新统计信息的条件
1、 在一个空表中有数据的改动。
2、 当统计信息创建时,表的行数只有500或以下,且后来统计对象中的引导列(统计信息的第一个字段数据)的更改次数大于500.
3、 当表的统计信息收集时,超过了500行,且统计对象的引导列(统计信息的第一个字段数据)后来更改次数超过500+表总行数的20%时
2:临时表
If the statistics object is defined on a temporary table, it is out of date as discussed above, except that there is an additional threshold for recomputation at 6 rows, with a test otherwise identical to test 2 in the previous list.。
3: 表变量
表变量没有统计信息
官方资料http://msdn.microsoft.com/en-us/library/dd535534%28v=sql.100%29.aspx 也是这样解释的。
A statistics object is considered out of date in the following cases:
If the statistics is defined on a regular table, it is out of date if:
- The table size has gone from 0 to >0 rows (test 1).
- The number of rows in the table when the statistics were gathered was 500 or less, and the colmodctr of the leading column of the statistics object has changed by more than 500 since then (test 2).
- The table had more than 500 rows when the statistics were gathered, and the colmodctr of the leading column of the statistics object has changed by more than 500 + 20% of the number of rows in the table when the statistics were gathered (test 3).
· For filtered statistics, the colmodctr is first adjusted by the selectivity of the filter before these conditions are tested. For example, for filtered statistics with predicate selecting 50% of the rows, the colmodctr is multiplied by 0.5.
· One limitation of the automatic update logic is that it tracks changes to columns in the statistics, but not changes to columns in the predicate. If there are many changes to the columns used in predicates of filtered statistics, consider using manual updates to keep up with the changes.
· If the statistics object is defined on a temporary table, it is out of date as discussed above, except that there is an additional threshold for recomputation at 6 rows, with a test otherwise identical to test 2 in the previous list.
Table variables do not have statistics at all.
但是又一次我的实验显示不是那么一回事,有兴趣的可以按照下面SQL语句试试,
CREATE TABLE TEST1
(
ID INT ,
NAME VARCHAR(8) ,
CONSTRAINT PK_TEST1 PRIMARY KEY(ID)
)
GO
SELECT name AS index_name,
STATS_DATE(OBJECT_ID, index_id) AS StatsUpdated
FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID('dbo.TEST1')
GO
index_name StatsUpdated
------------------------------------ -----------------------
PK_TEST1 NULL
INSERT INTO TEST1
SELECT 1001, 'Kerry' ;
此时查看统计信息的更新日期,发现空表插入一条数据并没有触发数据库更新其统计信息。

INSERT INTO TEST1
SELECT '1002', 'Jimmy' ;
即使我再插入一条或几条数据,统计信息依然不会更新,DBCC SHOW_STATISTICS(TEST1, PK_TEST1) 查看依然如此

这明显跟第一条规则:在一个空表中有数据的改动会触发统计信息明显不符。 Why? 难道官方文档有问题? 那么我就去验证第二条规则
DECLARE @Index INT;
SET @Index =2;
WHILE @Index <= 510
BEGIN
INSERT INTO TEST1 VALUES(@Index, 'k'+LTRIM(STR(@Index)));
SET @Index = @Index + 1;
END
SELECT name AS index_name,
STATS_DATE(OBJECT_ID, index_id) AS StatsUpdated
FROM sys.indexes
WHERE OBJECT_ID = OBJECT_ID('dbo.TEST1')
DBCC SHOW_STATISTICS(TEST1, PK_TEST1)
查看居然发现统计信息还是没有更新。规则2似乎也没有生效,哇靠,怎么会这样呢? 估计有人会怀疑是不是我没有开启数据库”自动更新统计信息“和”自动创建统计信息“选项,其实当时我也这样怀疑过,甚至怀疑数据库版本问题,如果你按照这个做实验估计你也很纳闷,为什么呢? 其实出现这种情况,是因为还少了触发条件,大家可以先将整个表DROP掉,然后从简单开始,插入一条数据后,
CREATE TABLE TEST1
(
ID INT ,
NAME VARCHAR(8) ,
CONSTRAINT PK_TEST1 PRIMARY KEY(ID)
)
GO
INSERT INTO TEST1
SELECT 1001, 'Kerry' ;
执行SQL语句后SELECT * FROM TEST1,此时查看统计信息是否更新,发现没有,但是如果执行SELECT * FROM TEST1 WHERE ID=1语句后,你会发现统计信息居然更新了。官方文档果然诚不欺我啊,呵呵。

其实也就是说统计信息的更新不光需要满足上述条件,还需特定的SQL触发, 例如上面两条语句
SELECT * FROM TEST1
SELECT * FROM TEST1 WHERE ID=1001
第一条SQL不会触发,而第二条SQL会触发。 它们之间的区别是就是查询条件,第二条语句查询条件ID包含在统计信息PK_TEST1里面。那么大家猜测一下
SELECT * FROM TEST1 WHERE Name='Kerry'
这条语句会不会触发统计信息的更新呢? 我的实验是不会。于是我设计了另外一个小实验,来验证我的另外一个想法, 如下所示:
IF EXISTS(SELECT 1 FROM SYSOBJECTS WHERE NAME = 'TEST1' AND XTYPE = 'U')
BEGIN
DROP TABLE TEST1;
END
GO
CREATE TABLE TEST1
(
ID INT ,
NAME VARCHAR(8) ,
Sex VARCHAR(2) ,
CONSTRAINT PK_TEST1 PRIMARY KEY(ID,NAME)
)
GO
INSERT INTO TEST1
SELECT 1001, 'Kerry','男' ;
SELECT * FROM TEST1 WHERE Name='Kerry'
结果告诉我,上面这个SQL语句依然不能触发更新统计信息,那么可以总结归纳为,触发统计信息更新的SQL语句里面必须有统计信息的第一个字段作为条件才能成功触发统计信息的更新。
统计信息存储位置探讨
关于统计信息存储在哪些系统表,我们先从简单的入手。一个简单的表Employee为示例

使用SP_HELPSTATS 可以查看表拥有哪些统计信息,那么如果看过我上篇 ,就可以通过分析存储过程SP_HELPSTATS了解到其实这里查看的统计信息其实是从sys.stats取值,当然还需要关联sys.stats_columns 与sys.columns

但是上面的统计信息位于哪里呢?在SQL SERVER 2000 里面,在sysindexes里面有一列statblob,统计信息应该就放在这里面.官方文档里面指明statblob字段就是统计信息的二进制大对象。
select name, statblob from sysindexes where id= object_id('Login_Log')

但是从SQL SERVER 2005开始,这一列返回null值,statblob本身存储在一张内部目录表中。
那么如何查看统计信息呢? 其实可以用下面两种方式:
方法1:DBCC SHOW_STATISTICS('Employee', 'PK_Employee_ID_Name') WITH STATS_STREAM

.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
0x0100000002000000000000000000000084A41ED3000000001103000000000000B902000000000000380300003800000004000A00000000000000000000000000E7030480E7000000280000000000000024D0000000000000070000007E3A170111A300000F270000000000000F270000000000000000803F76BCD13876BCD1380000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003000000030000000200000014000000873ADE41003C1C460000000000008040873ABE4100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000190000000000000000000000000000005D0000000000000045010000000000004D0100000000000018000000000000002F000000000000004600000000000000100014000000803F000000000000803F10270000040000100014000000803F00301C460000803F1D4E0000040000100014000000803F000000000000803F1E4E00000400000300000078DC020011A30000000000008087C340778200000000000003000000000000C08E371A3F00000000000000000000000000000000000000000000000000000000000000000000000000000000A003CA000FA30000000000008087C340778200000000000003000000000000C08E371A3F0000000000000000000000000000000000000000000000000000000000000000000000000000000049805F010DA30000000000008087C340778200000000000003000000000000C08E371A3F000000000000000000000000000000000000000000000000000000000000000000000000000000000F27000000000000
方法2: 必须通过DAC方式登录数据库,才能查看到。
SELECT name, imageval
FROM sys.stats AS s
INNER JOIN sys.sysobjvalues AS o
ON s.object_id = o.objid
AND s.stats_id = o.subobjid
WHERE
s.object_id = OBJECT_ID('dbo.Employee');

0x070000007E3A170111A300000F270000000000000F270000000000000000803F76BCD13876BCD1380000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003000000030000000200000014000000873ADE41003C1C460000000000008040873ABE4100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000190000000000000000000000000000005D0000000000000045010000000000004D0100000000000018000000000000002F000000000000004600000000000000100014000000803F000000000000803F10270000040000100014000000803F00301C460000803F1D4E0000040000100014000000803F000000000000803F1E4E00000400000300000078DC020011A30000000000008087C340778200000000000003000000000000C08E371A3F00000000000000000000000000000000000000000000000000000000000000000000000000000000A003CA000FA30000000000008087C340778200000000000003000000000000C08E371A3F0000000000000000000000000000000000000000000000000000000000000000000000000000000049805F010DA30000000000008087C340778200000000000003000000000000C08E371A3F000000000000000000000000000000000000000000000000000000000000000000000000000000000F27000000000000
将上面两段二进制码分两行放到UE或文本编辑器,右对齐后发现下面下面的十六进制码是上面十六进制码的一部分。部分截图如下所示。

至于两种的区别,暂时还没有搞懂。
有个叫joe-chang的大神http://sqlblog.com/blogs/joe_chang/archive/2012/05/05/decoding-stats-stream.aspx 这篇博客介绍了一些如何解码统计信息(文章看起来确实很深奥、枯燥)。我用其提供的p_Stat2008c存储过程的执行结果与DBCC SHOW_STATISTICS的结果做了对比分析,如下所示,从里面可以找到很多对应信息,图片里面没法弄很多线条,大致整了几条。
DBCC SHOW_STATISTICS(Employee,PK_Employee_ID_Name);
exec [dbo].[p_Stat2008c] @Table='Employee', @Index ='PK_Employee_ID_Name'

也就是说统计信息基本上是可以解析出来的。只是相当复杂。
有效维护更新数据库统计信息
如果要有效的维护、更新数据库的统计信息,下面有一些建议,仅供参考
1:一般建议开启“自动创建统计信息”和“自动更新统计信息”选项(默认开启)。让数据库自动维护、更新统计信息。在比较繁忙的OLTP系统中建议开启“自动异步更新统计信息”选项, 否则应该关闭这个选项,尤其是OLAP系统。
关于自动异步更新统计信息开启的建议:Use asynchronous statistics update if synchronous update causes undesired delay
If you have a large database and an OLTP workload, and if you enable AUTO_UPDATE_STATISTICS, some transactions that normally run in a fraction of a second may very infrequently take several seconds or more because they cause statistics to be updated. If you want to avoid the possibility of this noticeable delay, enable AUTO_UPDATE_STATISTICS_ASYNC. For workloads with long-running queries, getting the best plan is more important than an infrequent delay in compilation. In such cases, use synchronous rather than asynchronous auto update statistics.
2: 如果需要,可以选项性的使用FULLSCAN更新统计信息。
更新统计信息是一件消耗资源的事情,尤其是对那些大表。很多时候SQL SERVER引擎会根据抽样更新统计信息,例如80%进行抽样更新统计信息。此时统计信息的准确性就跟采样的比例有很大的关系。尤其对某些特殊的表(数据分布严重不均)影响非常大。所以有时候可以选择性的使用FULLSCAN来更新统计信息。SQL SERVER一般会在统计信息的准确度度和资源合理消耗之间做一个平衡。其实有很多特殊例子,最明显就是数据分布非常不均时,此时统计信息的准确性对执行计划的影响就非常大。
3:Consider more frequent statistics gathering for ascending keys
考虑更频繁的收集ascending keys的统计数据。升序键列,如IDENTITY列或代表真实世界的时间戳datetime列,频繁的INSERT可能会导致表的统计信息不正确,因为新插入的值不在直方图之中。所以需要频繁的收集ascending keys的统计数据。
4:考虑少用表值函数和表变量
对于表变量和表值函数,它们没有统计信息,所以数据库优化器需去猜测它们的基数,这样得到的执行计划就非常不可靠。
5:在脚本中考虑使用字符串代替局部变量,在存储过程考虑使用参数代替局部变量
如果你在查询谓词中使用局部变量而不是参数或字符串,那么优化器会诉诸于减少质量的估计或谓词的选择性的一个猜想选择性(If you use a local variable in a query predicate instead of a parameter or literal, the optimizer resorts to a reduced-quality estimate, or a guess for selectivity of the predicate)。在查询中使用参数或字符串而不是局部变量,优化器能选择一个更好的查询计划。请看下面例子。
declare @StartOrderDate datetime
set @StartOrderDate = '20040731'
select * from Sales.SalesOrderHeader h, Sales.SalesOrderDetail d
WHERE h.SalesOrderID = d.SalesOrderId
AND h.OrderDate >= @StartOrderDate

{kind=link}
SELECT * FROM Sales.SalesOrderHeader h, Sales.SalesOrderDetail d
WHERE h.SalesOrderID = d.SalesOrderId
AND h.OrderDate >= '20040731'

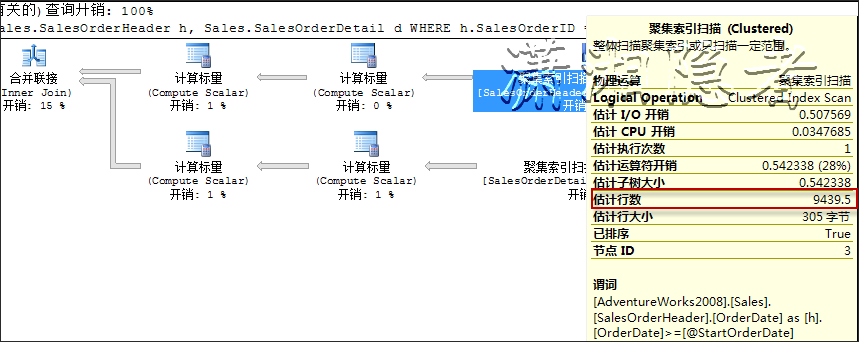
两者的对比如下所示。使用字符串得到的执行计划明显优于使用局部变量(注意,不同版本的数据库或可用内存不同,得到的执行计划可能有所差异,请以各自实验为准)

consider (1) rewriting the query to use literals instead of variables, (2) using sp_executesql with parameters that replace your use of local variables, or (3) using a stored procedure with parameters that replace your use of local variables. Dynamic SQL via EXEC may also be useful for eliminating local variables, but it typically results in higher compilation overhead and more complex programming. A new enhancement in SQL Server 2008 is that the OPTION(RECOMPILE) hint
USE [YourSQLDba]
GO
/****** Object: StoredProcedure [yMaint].[UpdateStats] Script Date: 04/25/2014 14:26:10 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [yMaint].[UpdateStats]
@JobNo Int
, @SpreadUpdStatRun Int
as
Begin
declare @seqStatNow Int
declare @cmptlevel Int
declare @dbName sysname
declare @sql nvarchar(max)
declare @lockResult int
Declare @seq Int -- row sequence for row by row processing
Declare @scn sysname -- schema name
Declare @tb sysname -- table name
declare @sampling Int -- page count to get an idea if the size of the table
Declare @idx sysname -- index name
Declare @object_id int -- a proof that an object exists
Begin Try
Create table #TableNames
(
scn sysname
, tb sysname
, sampling nvarchar(3)
, seq int
, primary key clustered (seq)
)
Update Maint.JobSeqUpdStat
Set @seqStatNow = (seq + 1) % @SpreadUpdStatRun, seq = @seqStatNow
Set @DbName = ''
While(1 = 1) -- simple do loop
Begin
Select top 1 -- first next in alpha sequence after the last one.
@DbName = DbName
, @cmptLevel = CmptLevel
From #Db
Where DbName > @DbName
Order By DbName
-- exit if nothing after the last one processed
If @@rowcount = 0 Break --
-- If database is not updatable, skip update stats for this database
If DATABASEPROPERTYEX(@DbName, 'Updateability') = N'READ_ONLY'
Continue
-- If database is in emrgency, skip update stats for this database
If DatabasepropertyEx(@DbName, 'Status') IN (N'Emergency')
Continue
-- makes query boilerplate with replacable parameter identified by
-- labels between "<" et ">"
-- this query select table for which to perform update statistics
truncate table #TableNames
set @sql =
'
set nocount on
;With
TableSizeStats as
(
select
object_schema_name(Ps.object_id, db_id("<DbName>")) as scn --collate <srvCol>
, object_name(Ps.object_id, db_id("<DbName>")) as tb --collate <srvCol>
, Sum(Ps.Page_count) as Pg
From
sys.dm_db_index_physical_stats (db_id("<DbName>"), NULL, NULL, NULL, "LIMITED") Ps
Group by
Ps.object_id
)
Insert into #tableNames (scn, tb, seq, sampling)
Select
scn
, tb
, row_number() over (order by scn, tb) as seq
, Case
When pg > 200001 Then "10"
When Pg between 50001 and 200000 Then "20"
When Pg between 5001 and 50000 Then "30"
else "100"
End
From
TableSizeStats
where (abs(checksum(tb)) % <SpreadUpdStatRun>) = <seqStatNow>
'
set @sql = replace(@sql,'<srvCol>',convert(nvarchar(100), Serverproperty('collation')))
Set @sql = replace(@sql,'<seqStatNow>', convert(nvarchar(20), @seqStatNow))
Set @sql = replace(@sql,'<SpreadUpdStatRun>', convert(nvarchar(20), @SpreadUpdStatRun))
set @sql = replace(@sql,'"','''') -- to avoid doubling of quotes in boilerplate
set @sql = replace(@sql,'<DbName>',@DbName)
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'Table selection for update statistics'
, @sql = @sql
, @JobNo = @JobNo
, @forDiagOnly = 1
Exec yMaint.LockMaintDb @jobNo, 'U', @DbName, @LockResult output
If @lockResult < 0 -- messages are issued from yMaint.LockMaintDb
Continue
set @seq = 0
While (1 = 1)
begin
Select top 1 @scn = scn, @tb = tb, @sampling = sampling, @seq = seq
from #TableNames where seq > @seq order by seq
if @@rowcount = 0 break
Set @sql = 'Select @object_id = object_id("<DbName>.<scn>.<tb>") '
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '"', '''')
Exec sp_executeSql @Sql, N'@object_id int output', @object_id output
If @object_id is not null
Begin
Set @sql = 'update statistics [<DbName>].[<scn>].[<tb>] WITH sample <sampling> PERCENT'
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '<sampling>', @sampling)
set @sql = replace (@sql, '"', '''')
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'update statistics selected'
, @sql = @sql
, @JobNo = @JobNo
End
end -- While
Exec yMaint.UnLockMaintDb @jobNo, @DbName
End -- While boucle banque par banque
End try
Begin catch
Exec yExecNLog.LogAndOrExec @jobNo = @jobNo, @context = 'yMaint.UpdateStats Error', @err = '?'
End Catch
End -- yMaint.UpdateStats
USE [YourSQLDba]
GO
/****** Object: StoredProcedure [yMaint].[UpdateStats] Script Date: 04/25/2014 14:26:10 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [yMaint].[UpdateStats]
@JobNo Int
, @SpreadUpdStatRun Int
as
Begin
declare @seqStatNow Int
declare @cmptlevel Int
declare @dbName sysname
declare @sql nvarchar(max)
declare @lockResult int
Declare @seq Int -- row sequence for row by row processing
Declare @scn sysname -- schema name
Declare @tb sysname -- table name
declare @sampling Int -- page count to get an idea if the size of the table
Declare @idx sysname -- index name
Declare @object_id int -- a proof that an object exists
Begin Try
Create table #TableNames
(
scn sysname
, tb sysname
, sampling nvarchar(3)
, seq int
, primary key clustered (seq)
)
Update Maint.JobSeqUpdStat
Set @seqStatNow = (seq + 1) % @SpreadUpdStatRun, seq = @seqStatNow
Set @DbName = ''
While(1 = 1) -- simple do loop
Begin
Select top 1 -- first next in alpha sequence after the last one.
@DbName = DbName
, @cmptLevel = CmptLevel
From #Db
Where DbName > @DbName
Order By DbName
-- exit if nothing after the last one processed
If @@rowcount = 0 Break --
-- If database is not updatable, skip update stats for this database
If DATABASEPROPERTYEX(@DbName, 'Updateability') = N'READ_ONLY'
Continue
-- If database is in emrgency, skip update stats for this database
If DatabasepropertyEx(@DbName, 'Status') IN (N'Emergency')
Continue
-- makes query boilerplate with replacable parameter identified by
-- labels between "<" et ">"
-- this query select table for which to perform update statistics
truncate table #TableNames
set @sql =
'
set nocount on
;With
TableSizeStats as
(
select
object_schema_name(Ps.object_id, db_id("<DbName>")) as scn --collate <srvCol>
, object_name(Ps.object_id, db_id("<DbName>")) as tb --collate <srvCol>
, Sum(Ps.Page_count) as Pg
From
sys.dm_db_index_physical_stats (db_id("<DbName>"), NULL, NULL, NULL, "LIMITED") Ps
Group by
Ps.object_id
)
Insert into #tableNames (scn, tb, seq, sampling)
Select
scn
, tb
, row_number() over (order by scn, tb) as seq
, Case
When pg > 200001 Then "10"
When Pg between 50001 and 200000 Then "20"
When Pg between 5001 and 50000 Then "30"
else "100"
End
From
TableSizeStats
where (abs(checksum(tb)) % <SpreadUpdStatRun>) = <seqStatNow>
'
set @sql = replace(@sql,'<srvCol>',convert(nvarchar(100), Serverproperty('collation')))
Set @sql = replace(@sql,'<seqStatNow>', convert(nvarchar(20), @seqStatNow))
Set @sql = replace(@sql,'<SpreadUpdStatRun>', convert(nvarchar(20), @SpreadUpdStatRun))
set @sql = replace(@sql,'"','''') -- to avoid doubling of quotes in boilerplate
set @sql = replace(@sql,'<DbName>',@DbName)
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'Table selection for update statistics'
, @sql = @sql
, @JobNo = @JobNo
, @forDiagOnly = 1
Exec yMaint.LockMaintDb @jobNo, 'U', @DbName, @LockResult output
If @lockResult < 0 -- messages are issued from yMaint.LockMaintDb
Continue
set @seq = 0
While (1 = 1)
begin
Select top 1 @scn = scn, @tb = tb, @sampling = sampling, @seq = seq
from #TableNames where seq > @seq order by seq
if @@rowcount = 0 break
Set @sql = 'Select @object_id = object_id("<DbName>.<scn>.<tb>") '
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '"', '''')
Exec sp_executeSql @Sql, N'@object_id int output', @object_id output
If @object_id is not null
Begin
Set @sql = 'update statistics [<DbName>].[<scn>].[<tb>] WITH sample <sampling> PERCENT'
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '<sampling>', @sampling)
set @sql = replace (@sql, '"', '''')
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'update statistics selected'
, @sql = @sql
, @JobNo = @JobNo
End
end -- While
Exec yMaint.UnLockMaintDb @jobNo, @DbName
End -- While boucle banque par banque
End try
Begin catch
Exec yExecNLog.LogAndOrExec @jobNo = @jobNo, @context = 'yMaint.UpdateStats Error', @err = '?'
End Catch
End -- yMaint.UpdateStats
6:Consider filtered statistics for heterogeneous data
Sometimes rows with different schema are mapped to a single physical table, with multipurpose columns such as ntext1, ntext2, bigint1, bigint2 storing semantically unrelated data. Typically, there is also a special-purpose rowtype column that defines what is the semantic meaning of the data stored in each column. Such design is useful for storing arbitrary user-defined lists without changing the underlying database schema. As a result, the same column may end up storing telephone numbers and city names, and a histogram on such column may not be very useful, due to the limit of 200 steps. To avoid this, define separate statistics for each rowtype in this table.:
7:Consider filtered statistics for partitioned tables
Statistics are defined at the table level. Changes to partitions affect statistics only indirectly, through the column modification counters. Switching in a partition is treated as an insert of its rows into the table, triggering statistics update based on the 20% rule, as outlined above. Filtered statistics, through their predicates, can target only rows in certain partition or partitions. There is no requirement to align to the boundaries of the partitions when defining the statistics.
Often, customers partition a table by the Date column, keeping a partition for every month, and updating only the last partition; older months receive the majority of the complex, read-only queries. In this scenario, creating separate, full-scan statistics on the read-only region of the table results in more accurate cardinality estimates. In order to benefit from the separate statistics object, queries must be contained within the read-only region. Similarly, separate statistics objects can be created for different regions based on the different access patterns.
8:定期自动去更新统计信息,我推荐使用YourSQLDba,这个工具开源、方便扩展。最重要的是你能了解是如何处理的。
USE [YourSQLDba]
GO
/****** Object: StoredProcedure [yMaint].[UpdateStats] Script Date: 04/25/2014 14:26:10 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [yMaint].[UpdateStats]
@JobNo Int
, @SpreadUpdStatRun Int
as
Begin
declare @seqStatNow Int
declare @cmptlevel Int
declare @dbName sysname
declare @sql nvarchar(max)
declare @lockResult int
Declare @seq Int -- row sequence for row by row processing
Declare @scn sysname -- schema name
Declare @tb sysname -- table name
declare @sampling Int -- page count to get an idea if the size of the table
Declare @idx sysname -- index name
Declare @object_id int -- a proof that an object exists
Begin Try
Create table #TableNames
(
scn sysname
, tb sysname
, sampling nvarchar(3)
, seq int
, primary key clustered (seq)
)
Update Maint.JobSeqUpdStat
Set @seqStatNow = (seq + 1) % @SpreadUpdStatRun, seq = @seqStatNow
Set @DbName = ''
While(1 = 1) -- simple do loop
Begin
Select top 1 -- first next in alpha sequence after the last one.
@DbName = DbName
, @cmptLevel = CmptLevel
From #Db
Where DbName > @DbName
Order By DbName
-- exit if nothing after the last one processed
If @@rowcount = 0 Break --
-- If database is not updatable, skip update stats for this database
If DATABASEPROPERTYEX(@DbName, 'Updateability') = N'READ_ONLY'
Continue
-- If database is in emrgency, skip update stats for this database
If DatabasepropertyEx(@DbName, 'Status') IN (N'Emergency')
Continue
-- makes query boilerplate with replacable parameter identified by
-- labels between "<" et ">"
-- this query select table for which to perform update statistics
truncate table #TableNames
set @sql =
'
set nocount on
;With
TableSizeStats as
(
select
object_schema_name(Ps.object_id, db_id("<DbName>")) as scn --collate <srvCol>
, object_name(Ps.object_id, db_id("<DbName>")) as tb --collate <srvCol>
, Sum(Ps.Page_count) as Pg
From
sys.dm_db_index_physical_stats (db_id("<DbName>"), NULL, NULL, NULL, "LIMITED") Ps
Group by
Ps.object_id
)
Insert into #tableNames (scn, tb, seq, sampling)
Select
scn
, tb
, row_number() over (order by scn, tb) as seq
, Case
When pg > 200001 Then "10"
When Pg between 50001 and 200000 Then "20"
When Pg between 5001 and 50000 Then "30"
else "100"
End
From
TableSizeStats
where (abs(checksum(tb)) % <SpreadUpdStatRun>) = <seqStatNow>
'
set @sql = replace(@sql,'<srvCol>',convert(nvarchar(100), Serverproperty('collation')))
Set @sql = replace(@sql,'<seqStatNow>', convert(nvarchar(20), @seqStatNow))
Set @sql = replace(@sql,'<SpreadUpdStatRun>', convert(nvarchar(20), @SpreadUpdStatRun))
set @sql = replace(@sql,'"','''') -- to avoid doubling of quotes in boilerplate
set @sql = replace(@sql,'<DbName>',@DbName)
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'Table selection for update statistics'
, @sql = @sql
, @JobNo = @JobNo
, @forDiagOnly = 1
Exec yMaint.LockMaintDb @jobNo, 'U', @DbName, @LockResult output
If @lockResult < 0 -- messages are issued from yMaint.LockMaintDb
Continue
set @seq = 0
While (1 = 1)
begin
Select top 1 @scn = scn, @tb = tb, @sampling = sampling, @seq = seq
from #TableNames where seq > @seq order by seq
if @@rowcount = 0 break
Set @sql = 'Select @object_id = object_id("<DbName>.<scn>.<tb>") '
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '"', '''')
Exec sp_executeSql @Sql, N'@object_id int output', @object_id output
If @object_id is not null
Begin
Set @sql = 'update statistics [<DbName>].[<scn>].[<tb>] WITH sample <sampling> PERCENT'
set @sql = replace (@sql, '<DbName>', @DbName)
set @sql = replace (@sql, '<scn>', @scn)
set @sql = replace (@sql, '<tb>', @tb)
set @sql = replace (@sql, '<sampling>', @sampling)
set @sql = replace (@sql, '"', '''')
Exec yExecNLog.LogAndOrExec
@context = 'yMaint.UpdateStats'
, @Info = 'update statistics selected'
, @sql = @sql
, @JobNo = @JobNo
End
end -- While
Exec yMaint.UnLockMaintDb @jobNo, @DbName
End -- While boucle banque par banque
End try
Begin catch
Exec yExecNLog.LogAndOrExec @jobNo = @jobNo, @context = 'yMaint.UpdateStats Error', @err = '?'
End Catch
End -- yMaint.UpdateStats
参考资料:
http://msdn.microsoft.com/en-us/library/dd535534.aspx
http://sqlblog.com/blogs/joe_chang/archive/2012/05/05/decoding-stats-stream.aspx
MS SQL统计信息浅析下篇的更多相关文章
- MS SQL 统计信息浅析上篇
统计信息概念 统计信息是一些对象,这些对象包含在表或索引视图中一列或多列中的数据分布有关的统计信息.数据库查询优化器使用这些统计信息来估计查询结果中的基数或行数. 通过这些基数估计,查询优化器可以生成 ...
- SQL统计信息解释
[SQL基础]统计信息解释 在平时优化SQL的时候,最长用的就是:SET STATISTICS ON,它可以用来查看我们写的查询语句到底性能如何,不过,究竟这个性能的指标是怎么样的呢?首先需要明白的, ...
- Insert插入不同的列数量,统计信息对比
一.实验目的: Insert插入表中相同的行数量,不同的列数量,通过10046 和autotrace工具对比查看逻辑读.物理读.time数据,并得出相应结论 二.测试 2.1测试流程: =>[为 ...
- SQL Server统计信息偏差影响表联结方式案例浅析
我们知道数据库中的统计信息的准确性是非常重要的.它会影响执行计划.一直想写一篇关于统计信息影响执行计划的相关博客,但是都卡在如何构造一个合适的例子上,所以一直拖着没有写.巧合,最近在生产环境中遇到 ...
- SQL Server信息偏差影响表联结方式统计
SQL Server统计信息偏差影响表联结方式案例浅析 我们知道数据库中的统计信息的准确性是非常重要的.它会影响执行计划.一直想写一篇关于统计信息影响执行计划的相关博客,但是都卡在如何构造一个合适 ...
- SQL Server 统计信息更新时采样百分比对数据预估准确性的影响
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,“一招鲜吃遍天” ...
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
- SQL Server2016 新功能实时查询统计信息
SQL Server2016 新功能实时查询统计信息 很多时候有这样的场景,开发抱怨DBA没有调优好数据库,DBA抱怨开发写的程序代码差,因此,DBA和开发都成为了死对头,无法真正排查问题. DBA只 ...
- 通过手动创建统计信息优化sql查询性能案例
本质原因在于:SQL Server 统计信息只包含复合索引的第一个列的信息,而不包含复合索引数据组合的信息 来源于工作中的一个实际问题, 这里是组合列数据不均匀导致查询无法预估数据行数,从而导致无法选 ...
随机推荐
- 附录D 安装ZooKeeper
D.1 安装ZooKeeper D.1.1 下载ZooKeeper ZooKeeper是Apache基金会的一个开源.分布式应用程序协调服务,是Google的Chubby一个开源的实现.它是 ...
- 给ubuntu中的软件设置desktop快捷方式(以android studio为例)
ubuntu的快捷方式都在/usr/share/applications/路径下有很多*.desktop(eclipse的快捷方式也可以类似设置) 下面就建立我们的studio sudo gedit ...
- YAML 语法
YAML 语法 来源:yaml 这个页面提供一个正确的 YAML 语法的基本概述, 它被用来描述一个 playbooks(我们的配置管理语言). 我们使用 YAML 是因为它像 XML 或 JSON ...
- SQL Server安全(11/11):审核(Auditing)
在保密你的服务器和数据,防备当前复杂的攻击,SQL Server有你需要的一切.但在你能有效使用这些安全功能前,你需要理解你面对的威胁和一些基本的安全概念.这篇文章提供了基础,因此你可以对SQL Se ...
- Nancy之基于Nancy.Hosting.Self的小Demo
继昨天的Nancy之基于Nancy.Hosting.Aspnet的小Demo后, 今天来做个基于Nancy.Hosting.Self的小Demo. 关于Self Hosting Nancy,官方文档的 ...
- LINQ to SQL语句(9)之Top/Bottom和Paging和SqlMethods
适用场景:适量的取出自己想要的数据,不是全部取出,这样性能有所加强. Take 说明:获取集合的前n个元素:延迟.即只返回限定数量的结果集. var q = ( from e in db.Employ ...
- 适配器模式 - Adapter
Adapter Pattern, 适用场景: 接口匹配兼容: 客户代码统一调用同一接口: 在.NET中,DataAdapter用作DataSet和数据源之间的适配器以保存和检索数据. 参考:
- 利用节点更改table内容
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title> new document ...
- sql where传入类型不同,造成查询结果差异问题
话说故事是这样的.请听小生慢慢道来: 原有数据样式如下: 正常结果: 问题展现: 此问题主要原因如下: 以下皆可在官网中找到: 为数据类型从高到低依次:(ps:小生用翻译工具翻译,就不在此献丑了) 根 ...
- 番外一:关于thinkphp框架下的文件导入路径问题
总的来说,要使在thinkphp框架下面HTML导入的图片.css文件和js文件有效,只有两种方法:(1)使用绝对路径:(2)在项目目录下创建新目录Public,把所有的img文件夹.js文件夹和cs ...