温故知新-Mysql索引结构&页&聚集索引&非聚集索
- Posted by 微博@Yangsc_o
- 原创文章,版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0
{kind=link}
摘要
第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础。
第二部分结合MySQL数据库中MyISAM和InnoDB数据存储引擎中索引的架构实现讨论聚集索引、非聚集索引及覆盖索引等话题。
索引
索引概述
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
索引优势劣势
- 优势
- 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
- 劣势
- 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有Memory引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
- Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从
Mysql5.6版本开始支持全文索引
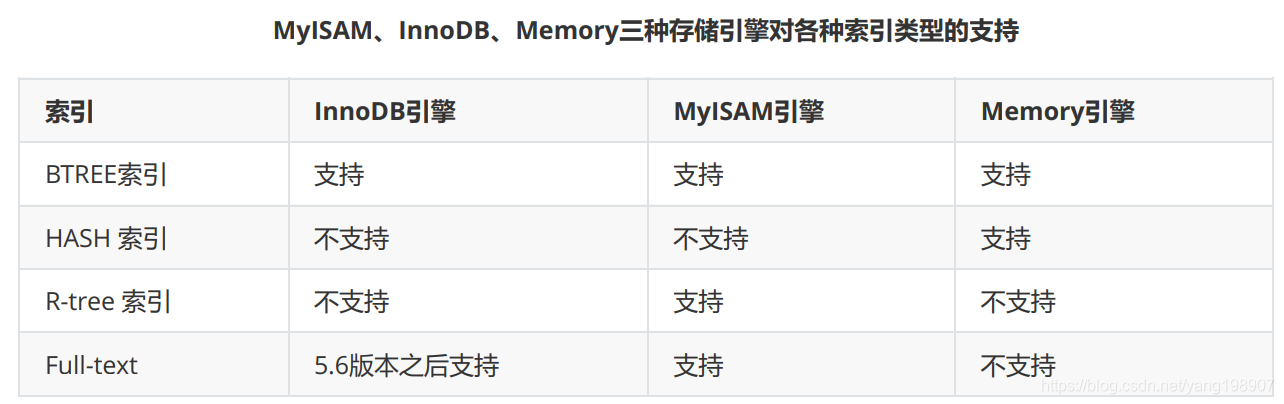
- 平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为 索引;
聚集索引 复合索引区别:
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
BTREE 结构
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
- 树中每个节点最多包含m个孩子。
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
- 若根节点不是叶子节点,则至少有两个孩子。
- 所有的叶子节点都在同一层。
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。当n>4时,中间节点分裂到
父节点,两边节点分裂。
插入 C N G A H E K Q M F W L T Z D P R X Y S 数据为例。
动画演示
演变过程如下,可以通过上面的网站走一下这个过程:
1). 插入前4个字母 C N G A
2). 插入H,n>4,中间元素G字母向上分裂到新的节点
3). 插入E,K,Q不需要分裂
4). 插入M,中间元素M字母向上分裂到父节点G
5). 插入F,W,L,T不需要分裂
6). 插入Z,中间元素T向上分裂到父节点中
7). 插入D,中间元素D向上分裂到父节点中。然后插入P,R,X,Y不需要分裂
8). 最后插入S,NPQR节点n>5,中间节点Q向上分裂,但分裂后父节点DGMT的n>5,中间节点M向上分裂
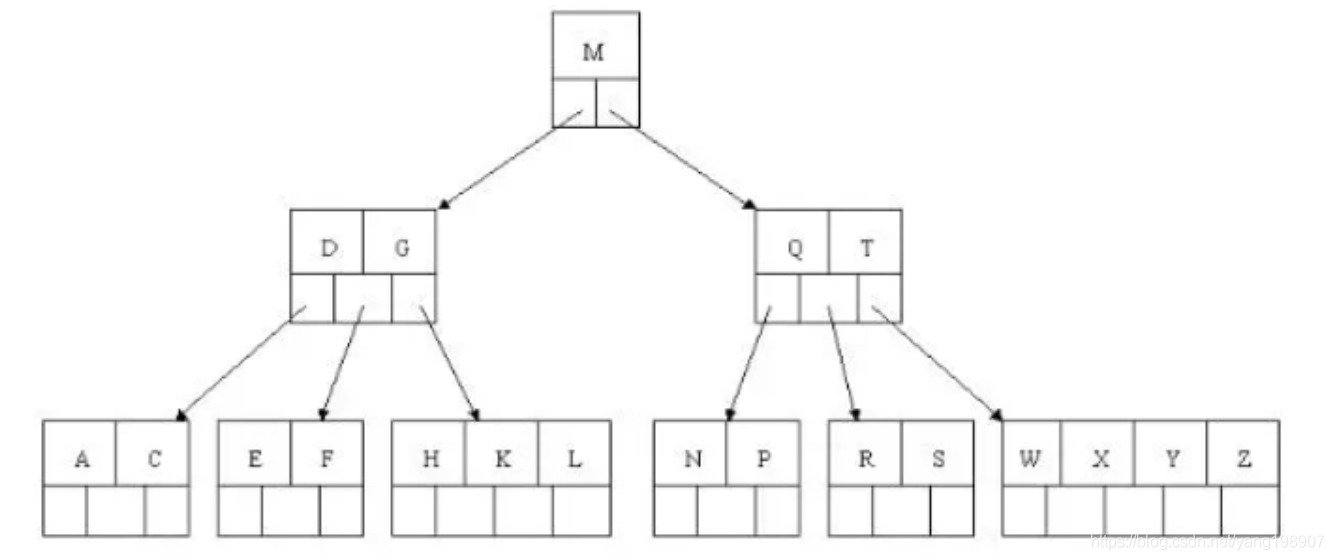
- BTREE树 和 二叉树相比,查询数据的效率更高, 因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。
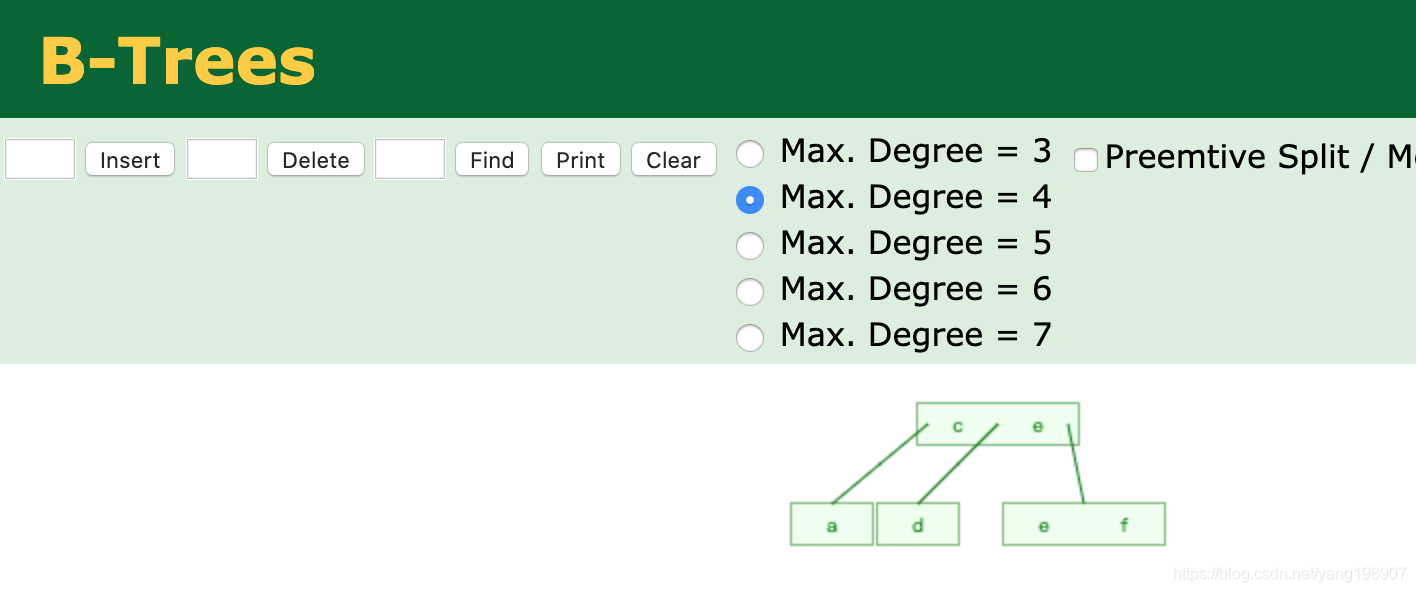
B+TREE 结构
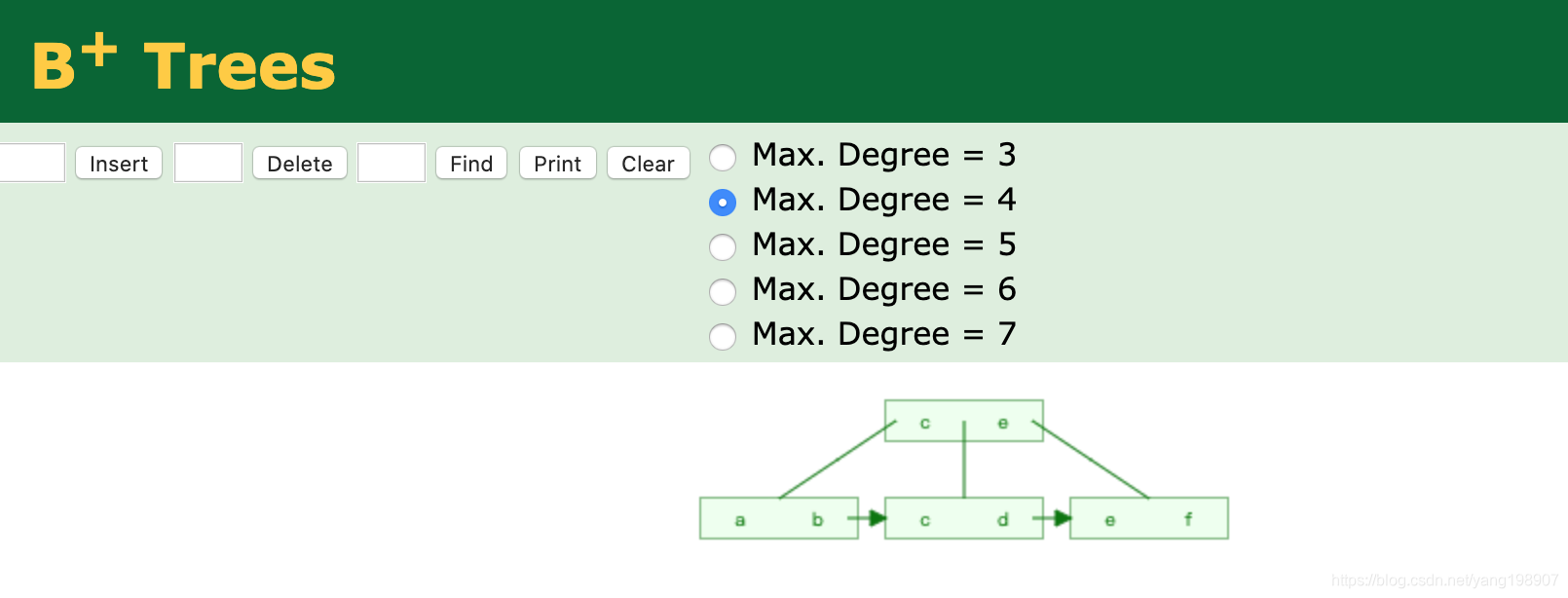
B+Tree为BTree的变种,B+Tree与BTree的区别为:
1). n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
2). B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
3). 所有的非叶子节点都可以看作是key的索引部分
通过下面的图,可以非常直观的看出来二者的差异:
页
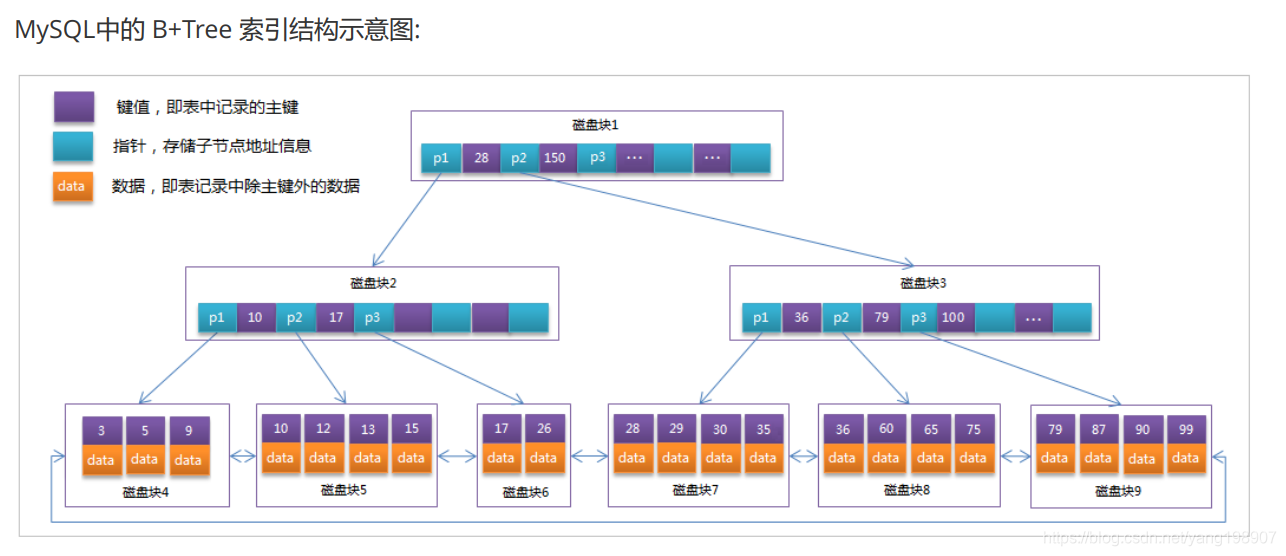
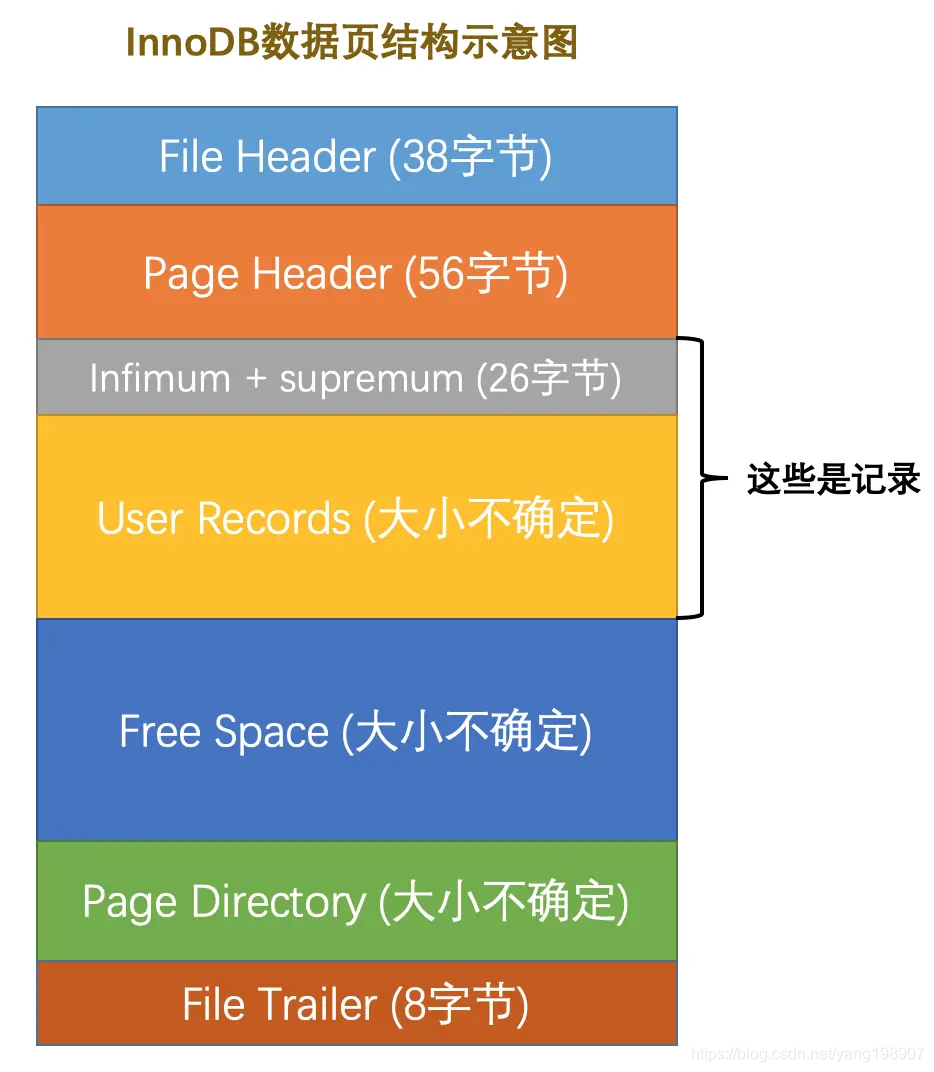
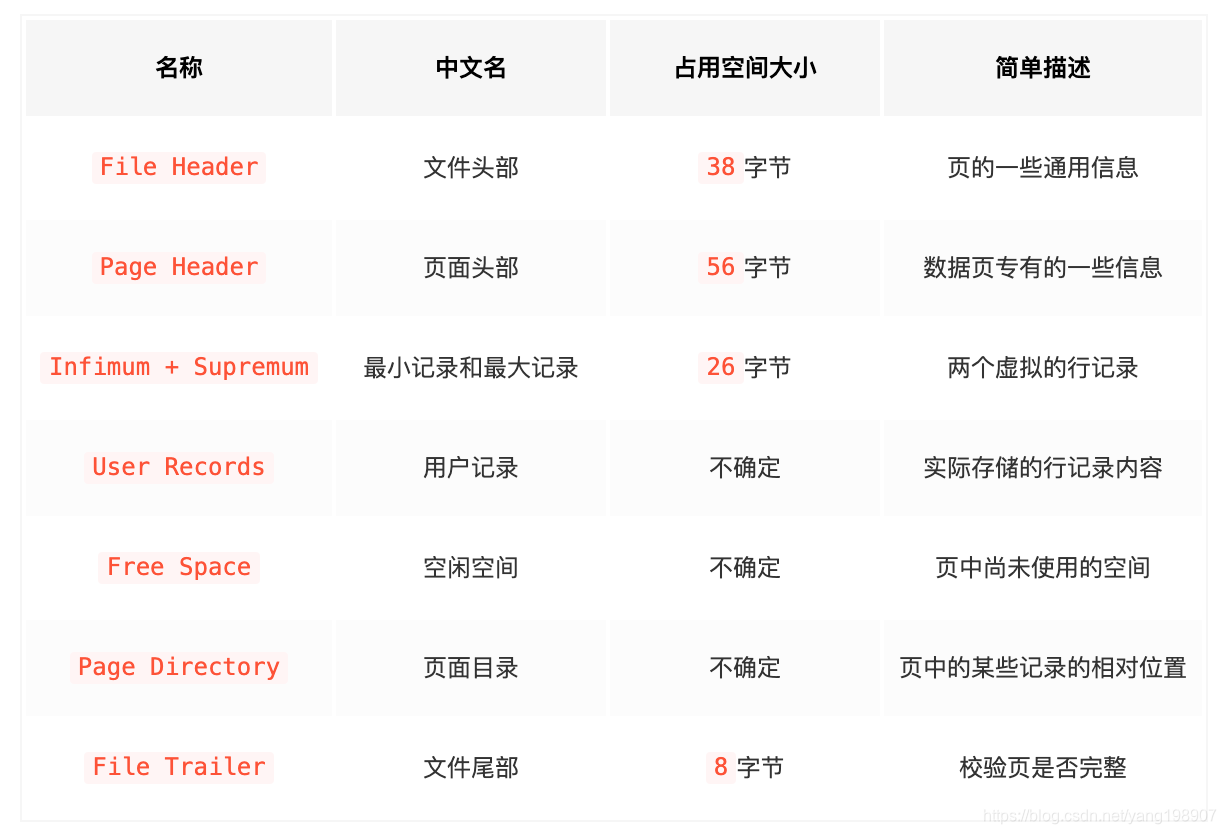
它是InnoDB管理存储空间的基本单位,一个页的大小一般是16KB。InnoDB为了不同的目的而设计了许多种不同类型的页,比如存放表空间头部信息的页,存放Insert Buffer信息的页,存放INODE信息的页,存放undo日志信息的页等等等等。
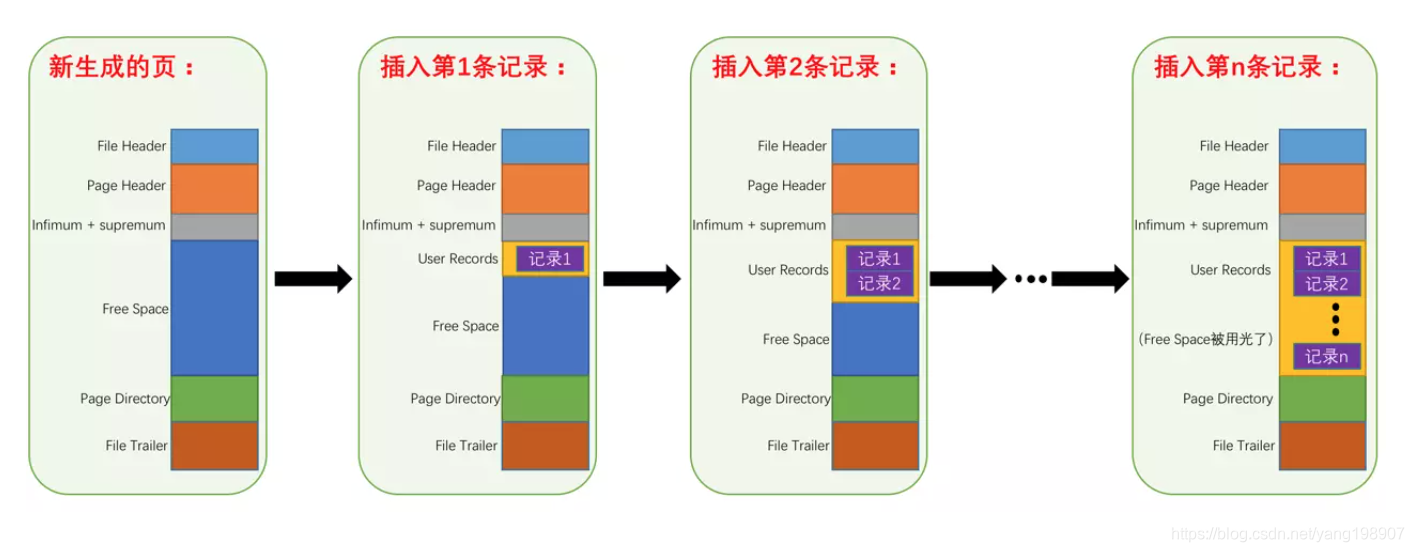
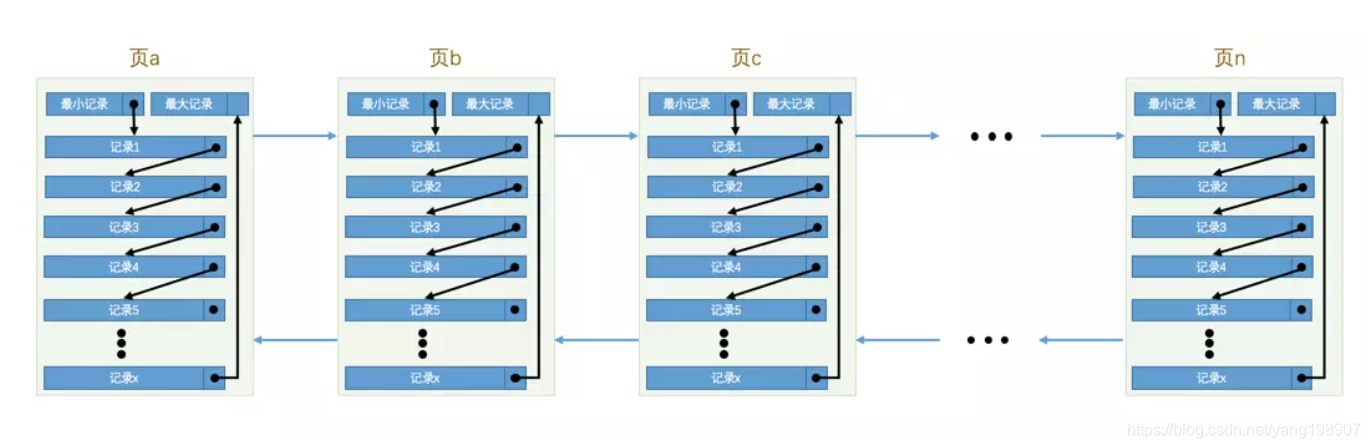
- 一个B+树节点就是一个页(16KB)
- B+树叶子节点前后形成双向链表
- 页与页之间是双向链表页里面的数据是单向链表 如图所示:
索引分类
- 单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引 :索引列的值必须唯一,但允许有空值
- 复合索引 :即一个索引包含多个列
索引语法
- 创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,…)
示例 :
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
- 追加索引
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
- 查看索引
show index from table_name;
- 删除索引
DROP INDEX index_name ON tbl_name;
索引设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高
效的使用索引。
- 对查询频次较高,且数据量比较大的表建立索引
- 索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合
- 使用唯一索引,区分度越高,使用索引的效率越高。
- 索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然也就水涨船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低DML操作的效率,增加相应操作的时间消耗。另外索引过多的话MySQL也会犯选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价。
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
聚触索引 & 非聚触索引
聚集索引与非聚集索引的区别是:叶节点是否存放一整行记录
InnoDB 主键使用的是聚簇索引和辅助索引,MyISAM 不管是主键索引,还是二级索引使用的都是非聚簇索引。
下图形象说明了聚簇索引表(InnoDB)和非聚簇索引(MyISAM)的区别:
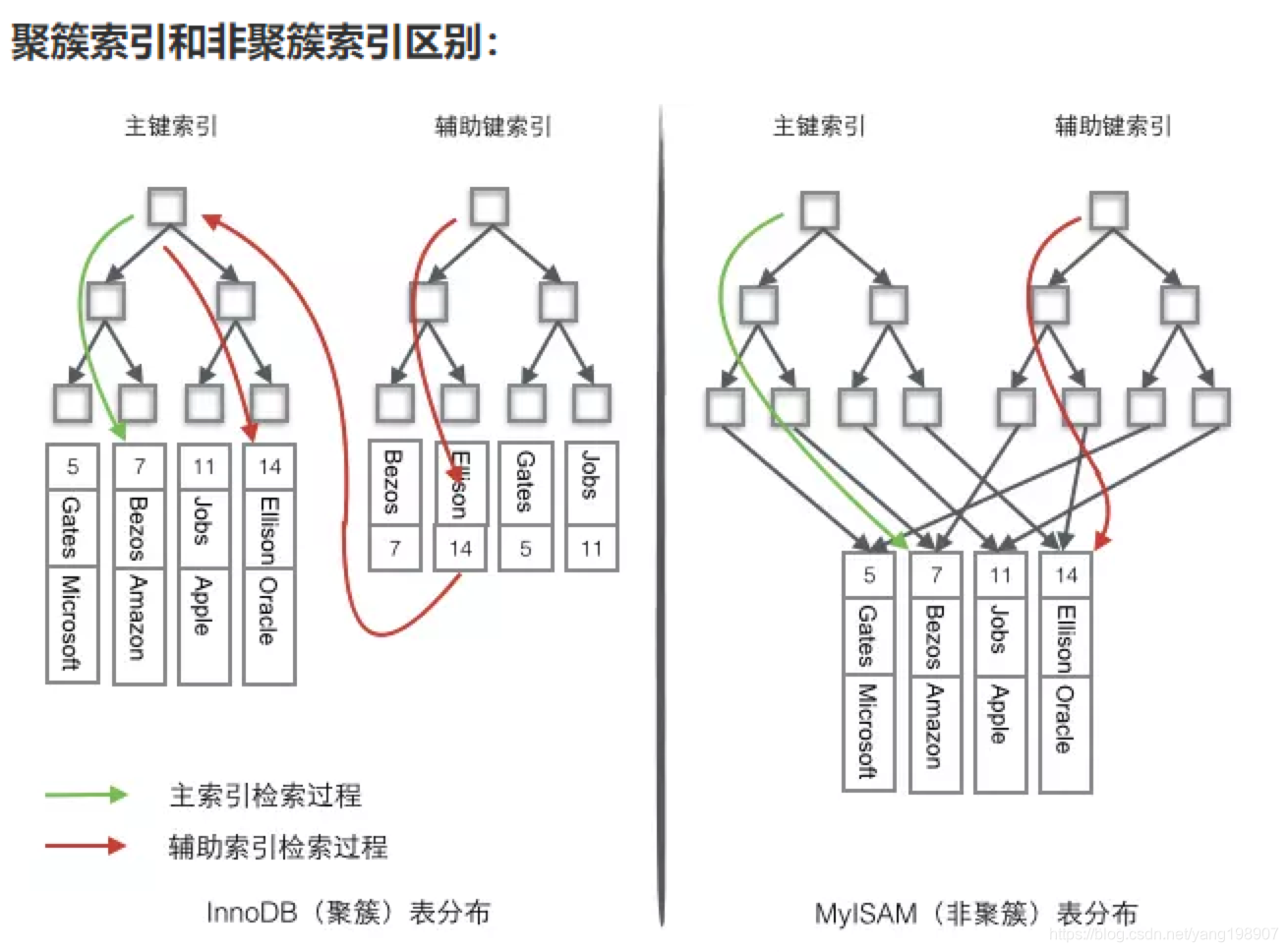
对于聚簇索引表来说(左图),表数据是和主键一起存储的,主键索引的叶结点存储行数据(包含了主键值),二级索引的叶结点存储行的主键值。使用的是B+树作为索引的存储结构,非叶子节点都是索引关键字,但非叶子节点中的关键字中不存储对应记录的具体内容或内容地址。叶子节点上的数据是主键与具体记录(数据内容)。
对于非聚簇索引表来说(右图),表数据和索引是分成两部分存储的,主键索引和二级索引存储上没有任何区别。使用的是B+树作为索引的存储结构,所有的节点都是索引,叶子节点存储的是索引+索引对应的记录的数据。
聚簇索引的优点:
- 需要取出一定范围内的数据时,用聚簇索引也比用非聚簇索引好。
- 当通过聚簇索引查找目标数据时理论上比非聚簇索引要快,因为非聚簇索引定位到对应主键时还要多一次目标记录寻址,即多一次I/O。
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
聚簇索引的缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
- 二级索引(辅助索引)访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。二级索引的叶节点存储的是主键值,而不是行指针(非聚簇索引存储的是指针或者说是地址),这是为了减少当出现行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多的空间。
- 采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距,聚簇索引遍历所有的叶子节点,非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有记录值,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
参考:
- MySQL 是怎样运行的:从根儿上理解 MySQL
- MySQL索引背后的数据结构及算法原理
你的鼓励也是我创作的动力
{kind=link}
温故知新-Mysql索引结构&页&聚集索引&非聚集索的更多相关文章
- SQL Server 索引和表体系结构(非聚集索引)
非聚集索引 概述 对于非聚集索引,涉及的信息要比聚集索引更多一些,由于整个篇幅比较大涉及接下来的要写的“包含列的索引”,“索引碎片”等一些知识点,可能要结合起来阅读理解起来要更容易一些.非聚集索引和聚 ...
- 索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引.我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构. 非聚集索引的逻辑呈现 简单来说,非聚集索引是表的子 ...
- 【SqlServer】聚集索引与主键、非聚集索引
目录结构: contents structure [-] 聚集索引和非聚集索引的区别 聚集索引和主键的区别 主键和(非)聚集索引的常规操作 聚集索引.非聚集索引在SqlServer.MySQL.Ora ...
- 数据库索引--------B/B+树、聚集、非聚集、符合索引
摘录自博客:http://www.cnblogs.com/morvenhuang/archive/2009/03/30/1425534.html 一.引言 对数据库索引的关注从未淡出我的们的讨论,那么 ...
- SQLServer中重建聚集索引之后会影响到非聚集索引的索引碎片吗
本文出处:http://www.cnblogs.com/wy123/p/7650215.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- Mysql索引结构及常见索引的区别
一.Mysql索引主要有两种结构:B+Tree索引和Hash索引 Hash索引 mysql中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是M ...
- mysql 聚集和非聚集索引 解析
一.聚集索引(聚簇索引) 1. 什么是聚集索引? 比如要查找'hello',则直接找内容为hello的行,我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”. 聚集索引的叶子节点 ...
- 索引深入浅出(5/10):非聚集索引的B树结构在堆表
在“索引深入浅出:非聚集索引的B树结构在聚集表”里,我们讨论了在聚集表上的非聚集索引,这篇文章我们讨论下在堆表上的非聚集索引. 非聚集索引可以在聚集表或堆表上创建.当我们在聚集表上创建非聚集索引时,聚 ...
- oracle索引原理(b-tree,bitmap,聚集,非聚集索引)
B-TREE索引 一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点. 可以用下图一来描述B树索引的结构.其中,B表示分支节点,而L表示叶子节点. 对于分支节点块(包括根节点块)来说,其所 ...
随机推荐
- mybatis 自动生成代码工具
配置官网: http://www.mybatis.org/generator/configreference/xmlconfig.html 源码:https://github.com/mybatis/ ...
- Jenkins 实现 ldap认证
使用自己搭建的openldap: 使用Test LdapSetting测试的结果: 所测试的用户在:svn,jenkins,gitlab,sonarqube,wpsadmin组下 若用户不在jenki ...
- 【雕爷学编程】Arduino动手做(61)---电压检测传感器
37款传感器与执行器的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止这37种的.鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为 ...
- MY FIRST PAGE!
RT. This is my first time to create and customize my cnblogs. Nice to see you!
- 【python爬虫】scrapy入门7:Scrapy中runspider和crawl的区别
runspider:不依赖创建项目 命令:scrapy runspider myspider.py 等同于 pyhton myspider.py crawl:使用spider进行爬取,依赖项目创建 ...
- centOS 6.8下使用Gparted进行分区扩容
centOS 6.8下使用Gparted进行分区扩容 机器环境:windows上运行的VMware虚拟机,系统为centOS 6.8. 由于前期分区分配空间过小,无法满足后续的数据存储预期,所 ...
- Spring基础之AOP
一.AOP能解决什么问题 业务层每个service都要管理事务,在每个service中单独写事务,就会产生很多重复性的代码,而且修改事务时,需要修改源码,不利于维护.为此,把横向重复的代码,纵向抽取形 ...
- JavaScript变量语法扩展
1.更新变量 一个变量被重新赋值后,它原有的值会被覆盖,变量值将会以最后一次赋值为准. 2.同时声明多个变量 var age = 18 , address ='火影村' , gz = 2000 ; ...
- [Flutter] 音频播放插件 audioplayers 的一个路径坑
pubsepc.yaml 文件 flutter: assets: video/video-01.mp4 video/video-02.mp4 audio/bg.mp3 以上关于视频的文件的配置,都能正 ...
- C# 7.0 新增功能&结合微软简化理解
C# 7.0更新时间为2019.2左右 C# 7.0 ~ 7.3 分别需要VS2017 与 .NET Core 1.0. .NET Core 2.0 SDK..NET Core 2.1 SDK,需要在 ...