hadoop学习笔记(九):mapReduce1.x和2.x
一、MapReduce1.0的数据分割到数据计算的过程
MapReduce是我们再进行离线大数据处理的时候经常要使用的计算模型,MapReduce的计算过程被封装的很好,我们只用使用Map和Reduce函数
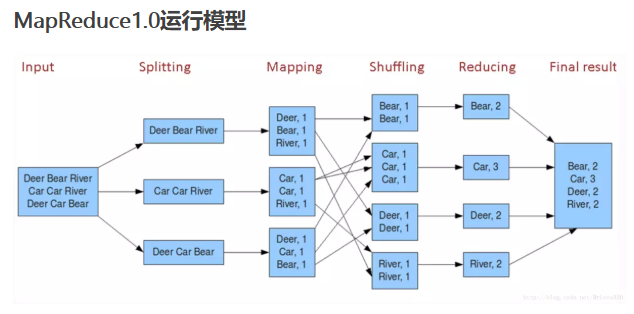
nput
Input但是输入文件的存储位置,
但是注意这里并一定是一些博客说的当然是HDFS似的分布式文件系统位置,默认是HDFS文件系统,当然也可以修改。
,它也可以是本机上的文件位置。
我们来仔细分析下input
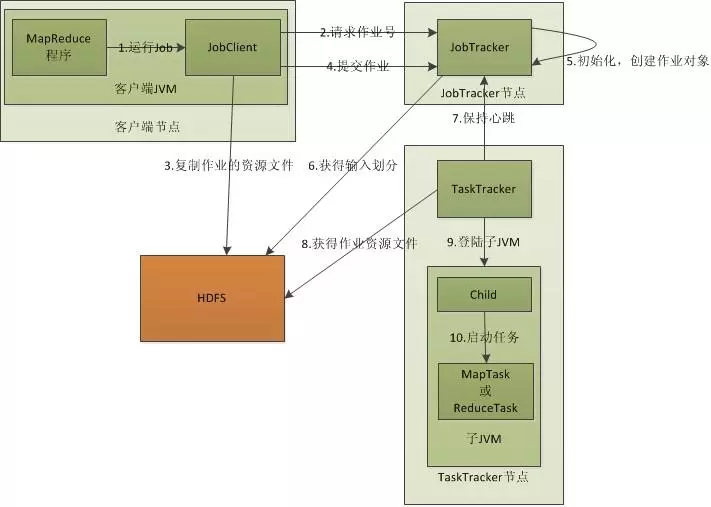
首先我们知道要和JobTracker打交道是离不开JobClient这个接口的,就如上图所示,
然后JobClient中的Run方法 会让 JobClient 把所有 Hadoop Job 的信息,比如 mapper reducer jar path, mapper / reducer class name, 输入文件的路径等等,告诉给 JobTracker,如下面的代码所示
public int run(String[] args) throws Exception {
//create job
Job job = Job.getInstance(getConf(), this.getClass().getSimpleName());
// set run jar class
job.setJarByClass(this.getClass());
// set input . output
FileInputFormat.addInputPath(job, new Path(PropReader.Reader("arg1")));
FileOutputFormat.setOutputPath(job, new Path(PropReader.Reader("arg2")));
// set map
job.setMapperClass(HFile2TabMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
// set reduce
job.setReducerClass(PutSortReducer.class);
return ;
}
除此以外,JobClient.runJob() 还会做一件事,使用 InputFormat类去计算如何把 input 文件 分割成一份一份,然后交给 mapper 处理。inputformat.getSplit() 函数返回一个 InputSplit 的 List, 每一个 InputSplit 就是一个 mapper 需要处理的split数据。
一个 Hadoop Job的 input 既可以是一个很大的 file, 也可以是多个 file; 无论怎样,getSplit() 都会计算如何分割 input.
如果是HDFS文件系统,我们都知道其可以通过将文件分割为block的形式存放在很多台电脑上,使其可以存放很大的文件。那么Mapper是如何确定一个HDFS文件中的block存放哪几台电脑,有什么数据?
inputFormat它实际上是个 interface, 需要 类 来继承,提供分割 input 的逻辑。
Jobclient 有一个方法叫 setInputFormat(), 通过它,我们可以告诉 JobTracker 想要使用的 InputFormat 类 是什么。如果我们不设置,Hadoop默认的是 TextInputFormat, 它默认为文件在 HDFS上的每一个 Block 生成一个对应的 InputSplit. 所以大家使用 Hadoop 时,也可以编写自己的 input format, 这样可以自由的选择分割 input 的算法,甚至处理存储在 HDFS 之外的数据。
JobTracker 尽量把 mapper 安排在离它要处理的数据比较近的机器上,以便 mapper 从本机读取数据,节省网络传输时间。具体实现是如何实现?
对于每个 map任务, 我们知道它的 split 包含的数据所在的主机位置,我们就把 mapper 安排在那个相应的主机上好了,至少是比较近的host. 你可能会问:split 里存储的 主机位置是 HDFS 存数据的主机,和 MapReduce 的主机 有什么相关呢?为了达到数据本地性,其实通常把MapReduce 和 HDFS 部署在同一组主机上。
既然一个 InputSplit 对应一个 map任务, 那么当 map 任务收到它所处理数据的位置信息,它就可以从 HDFS 读取这些数据了。
接下来我们再从map函数看Input
map函数接受的是一个 key value 对。
实际上,Hadoop 会把每个 mapper 的输入数据再次分割,分割成一个个 key-value对, 然后为每一个 key-value对,调用Map函数一次. 为了这一步分割,Hadoop 使用到另一个类: RecordReader. 它主要的方法是 next(), 作用就是从 InputSplit 读出一条 key-value对.
RecordReader 可以被定义在每个 InputFormat 类中。当我们通过 JobClient.setInputFormat() 告诉 Hadoop inputFormat 类名称的时候, RecordReader 的定义也一并被传递过来。
所以整个Input,
1.JobClient输入输入文件的存储位置
2.JobClient通过InputFormat接口可以设置分割的逻辑,默认是按HDFS文件分割。
3.Hadoop把文件再次分割为key-value对。
4.JobTracker负责分配对应的分割块由对应的maper处理,同时 RecordReader负责读取key-value对值。
Mapper
JobClient运行后获得所需的配置文件和客户端计算所得的输入划分信息。并将这些信息都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);
然后输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
JobTracker通过TaskTracker 向其汇报的心跳情况和slot(情况),每一个slot可以接受一个map任务,这样为了每一台机器map任务的平均分配,JobTracker会接受每一个TaskTracker所监控的slot情况。
JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行,分配时根据slot的情况作为标准。
TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
Map通过 RecordReader 读取Input的key/value对,map根据用户自定义的任务,运行完毕后,产生另外一系列 key/value,并将其写入到Hadoop的内存缓冲取中,在内存缓冲区中的key/value对按key排序,此时会按照reduce partition进行,分到不同partition中,一旦内存满就会被写入到本地磁盘的文件里,这个文件叫spill file。
shuffle
Shuffle是我们不需要编写的模块,但却是十分关键的模块。

在map中,每个 map 函数会输出一组 key/value对, Shuffle 阶段需要从所有 map主机上把相同的 key 的 key value对组合在一起,(也就是这里省去的Combiner阶段)组合后传给 reduce主机, 作为输入进入 reduce函数里。
Partitioner组件 负责计算哪些 key 应当被放到同一个 reduce 里
HashPartitioner类,它会把 key 放进一个 hash函数里,然后得到结果。如果两个 key 的哈希值 一样,他们的 key/value对 就被放到同一个 reduce 函数里。我们也把分配到同一个 reduce函数里的 key /value对 叫做一个reduce partition.
我们看到 hash 函数最终产生多少不同的结果, 这个 Hadoop job 就会有多少个 reduce partition/reduce 函数,这些 reduce函数最终被JobTracker 分配到负责 reduce 的主机上,进行处理。
我们知道map阶段可能会产生多个spill file 当 Map 结束时,这些 spill file 会被 merge 起来,不是 merge 成一个 file,而是也会按 reduce partition 分成多个。
当 Map tasks 成功结束时,他们会通知负责的 tasktracker, 然后消息通过 jobtracker 的 heartbeat 传给 jobtracker. 这样,对于每一个 job, jobtracker 知道 map output 和 map tasks 的关联。Reducer 内部有一个 thread 负责定期向 jobtracker 询问 map output 的位置,直到 reducer 得到所有它需要处理的 map output 的位置。
Reducer 的另一个 thread 会把拷贝过来的 map output file merge 成更大的 file. 如果 map task 被 configure 成需要对 map output 进行压缩,那 reduce 还要对 map 结果进行解压缩。当一个 reduce task 所有的 map output 都被拷贝到一个它的 host上时,reduce 就要开始对他们排序了。
排序并不是一次把所有 file 都排序,而是分几轮。每轮过后产生一个结果,然后再对结果排序。最后一轮就不用产生排序结果了,而是直接向 reduce 提供输入。这时,用户提供的 reduce函数 就可以被调用了。输入就是 map 任务 产生的 key value对.
同时reduce任务并不是在map任务完全结束后才开始的,Map 任务有可能在不同时间结束,所以 reduce 任务没必要等所有 map任务 都结束才开始。事实上,每个 reduce任务有一些 threads 专门负责从 map主机复制 map 输出(默认是5个)。
Reduce

reduce() 函数以 key 及对应的 value 列表作为输入,按照用户自己的程序逻辑,经合并 key 相同的 value 值后,产 生另外一系列 key/value 对作为最终输出写入 HDFS。
一定要注意以上为MapReduce1.0的过程,而且现在MapReduce已经升级到了2.0版本
--------------------------------------------------------------------------------------------------------------------------------------------
下面是自己理解总结
二、map reduce1.x中角色分工以及容易遇见的问题
1.JobTracker
主节点,单点,负责调度所有的作用和监控整个集群的资源负载。 -------------------》因为管理的任务和进程太多容易造成单点故障和单点瓶颈
2.TaskTracker
从节点,自身节点资源管理和JobTracker进行心跳联系,汇报资源和获取task。
3.Client
程序员根据需求编写代码java之后封装成jar上传到HDFS系统,以作业为单位,规划作业计算分布,提交作业资源到HDFS,最终提交作业到JobTracker。
问题:
1.JobTracker负载过重,存在单点故障。
2.资源管理和计算调度强耦合,其它计算框架难以复用其资源管理。
3.不同框架对资源不能全局管理。
注意点:
MRv1
一、job Tracker、Task Tracker等组件的工作流程示例
1、将客户端编写的java代码设置split个数,多少个reduce多少个reduce,从哪里去读这些数据呀。计算完毕之后写到哪里去呀等参数之后,之后会将java代码打成jar包提交到HDFS系统的放到NameNode上。而不是Job Tracker上,因为这个放到这个上面会出现单点瓶颈或者单点故障的问题当提交到Namenode之后Job Tracker从中获取到具体的任务配置之后,
2、一个Task Tracker是负责所在的结点上资源进程的占用情况
3、client客户端写的用于设置split、reduce的个数的java接口代码,打成的jar包,上传到NameNode上之后,由每一个已经有Task Tracker进程的结点上下载下来相应的jar文件,按照jar文件的设置,对去开启相应的Map Task 或者Reduce Task进程在相应的结点上
4、Jao Tracker负载的任务:资源的管理、任务的管理、任务的调度,都是他的任务,
四、改进后的 MRv2

角色:
1、Resource Manager资源管理进程 相当于1.x中的jao Tracker ,但是现在负责的任务只有资源的管理
2、application Master:叫任务调度作业角色,专门用来调度任务的,比如我在哪个结点上面开辟container呀,容器上开辟reduce等,但是对于资源的情况,肯定是和Resource manager进行交互的
完成Job Tracker的任务调度工作,但是此时的app Master 不知道下层的资源的占用情况,所以他要发出Resource Request请求到Resouce Manager结点,看下层的结点资源占用情况,并根据Resource Manager 的安排,去相应的结点去开辟进程Map、和Reduce等
但是这个 application Master也不知该去干什么,他会从HDFS中拉取部署的jar,之后去找Resource Manager,这个管理者根据自己已经知道的下层存储的资源的情况,根据app Master 的所规划好的方案,去看看行不行,如果可以的话,app Master就会去到相应的结点上开辟相应的map或者reduce进程
3、app Master收到Resource Manager 确认命令之后,就会到相应的结点先开辟一个Container容器的这样的角色, 之后开辟的reduce Task还是其他的Map Task等都会在这个容器中开辟,因为每一个容器都有提前设定好的大小的,当开辟的pan、reduce Task超过设定的大小之后,就会被立马的kill掉,这样规定的原因:防止占用太多的空间资源,而且
4、Node manager:管控自己本节点上的资源的使用,当开启或者关闭container的时候会把结点的资源占用情况反馈给Resouce Manager,此时Resource mmanager就会知道每一个结点的资源的占用情况,之后外界客户端会直接和resource Manager进行交互,他会直接的指派不太忙的结点使用了。
5、在mr 2.0中所有的角色都是Container,就连Recourse manager也是先开辟的容器再去在容器里面创建的这个进程角色
6、长服务:整个集群的运行过程中,一个角色始终要是存在的,到结束才消亡,这个是长服务,是需要自己手动去搭建的
在mr2.x中的长服务:Resource manager、Node Manager
短服务:不是一直存在的,只有需client向resource Manager发放作业job的时候才会产生,如yarn 中 的app master整个不需要环境的搭建,程序启动过程中会自动的启动整个
7、node manager是通过监控管理container的生命周期去管控自己本节点上的资源的情况,之后想Resource manger进行汇报
8、container中 包括CPU 几点NN,I/O大小
yarn优势:


注意点:
1、app master仅仅是对资源进程规划,真正的做决定的还是Resource Mangager
2、 整个的mr2是基于yarn管理的,这样就克服了mr1中的资源管理和任务调度的高耦合的问题

参考:
https://www.jianshu.com/p/461f86936972
hadoop学习笔记(九):mapReduce1.x和2.x的更多相关文章
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(两)设置单节点集群
本文描写叙述怎样设置一个单一节点的 Hadoop 安装.以便您能够高速运行简单的操作,使用 Hadoop MapReduce 和 Hadoop 分布式文件系统 (HDFS). 參考官方文档:Hadoo ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
随机推荐
- ASP.NET常用内置对象(三)Server
Server对象是HttpServerUtility的一个实例,也是上下文对象HttpContext的一个属性,提供用于处理Web请求的Helper方法. Server.MapPath("& ...
- 【算法】用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
public class Solution { Stack<Integer> stack1 = new Stack<Integer>(); Stack<Integer&g ...
- jQuery---下拉菜单案例
下拉菜单案例 <!DOCTYPE html> <html> <head lang="en"> <meta charset="UT ...
- ssh配置跳板机-带密钥
ssh配置跳板机堡垒机带密钥 ~/.ssh/config 添加以下配置: # 跳板机地址 Host jumper HostName jumper.com User jumper port 23333 ...
- CR(Code Review)代码评审如何发挥作用
在CODE中经常会发起代码评审和进行评审任务,可是根据目前的做法流程,我认为它就是走走形式,为了应付检查,根本没有达到预期的效果,即审查代码质量.学习他人写的代码和提高自身写代码的能力.对此,将从两方 ...
- Keras 回归 拟合 收集
案例1 from keras.models import Sequential from keras.layers import Dense, LSTM, Activation from keras. ...
- Codeforces 764C Timofey and a tree
Each New Year Timofey and his friends cut down a tree of n vertices and bring it home. After that th ...
- [USACO10MAR] 伟大的奶牛聚集 - 树形dp
每个点有重数,求到所有点距离最小的点 就是魔改的重心了 #include <bits/stdc++.h> using namespace std; #define int long lon ...
- MariaDB Windows 安装
1.复制安装文件到服务器 2.解压到指定的目录,并创建my.ini: 3.编辑my.ini文件内容 [client] port=3307 [mysql] default-character-set=u ...
- ubuntu19.04 redis启动和停止及连接
1.启动停止 如果以(sudo apt install redis-server)方式安装 启动: sudo srevice redis start 停止: sudo srevice redi ...