mybatis源码探索笔记-4(缓存原理)
前言
mybatis的缓存大家都知道分为一级和二级缓存,一级缓存系统默认使用,二级缓存默认开启,但具体用的时候需要我们自己手动配置。我们依旧还是先看一个demo。这儿只贴出关键代码
- public interface AssetInfoMapper {
- List<AssetInfo> get(@Param("name") String name, @Param("id")String id);
- }
- <mapper namespace="com.test.mapper.AssetInfoMapper">
- <cache></cache>
- <select id="get" resultType="com.megalith.entity.AssetInfo" useCache="true">
- select * from asset_info where id =#{id} and `name` = #{name}
- </select>
- </mapper>
- @Autowired
- private SqlSessionFactory sqlSessionFactory;
- @GetMapping("/get")
- public List<AssetInfo> get() {
- SqlSession sqlSession = sqlSessionFactory.openSession();
- AssetInfoMapper mapper = sqlSession.getMapper(AssetInfoMapper.class);
- List<AssetInfo> test = mapper.get("测试删除" , "123123123");
- System.out.println("获取test0的值:"+test.get(0).getName());
- test.get(0).setName("测试bug");
- List<AssetInfo> test2 = mapper.get("测试删除" , "123123123");
- System.out.println("获取test0的值:"+test2.get(0).getName());
- System.out.println(test == test2);
- System.out.println("---------------------------------");
- sqlSession.close();
- sqlSession = sqlSessionFactory.openSession();
- mapper = sqlSession.getMapper(AssetInfoMapper.class);
- List<AssetInfo> test3 = mapper.get("测试删除" , "123123123");
- System.out.println(test == test3);
- System.out.println("获取test0的值:"+test3.get(0).getName());
- return test;
- }
- 另外在初始化的SqlSessionFactoryBean中配置Conguration时配置上日志打印,方便观察
我们执行上面的方法后结果如下
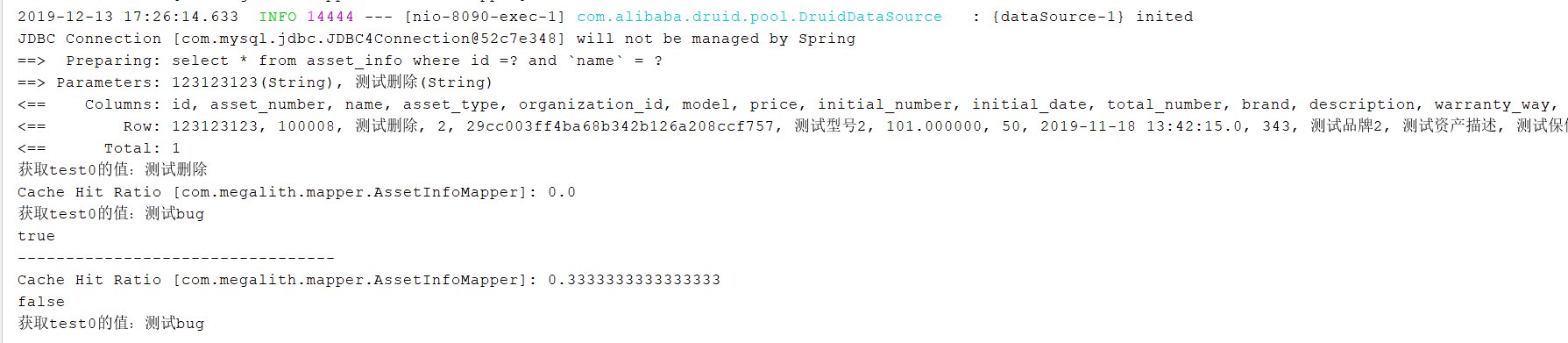
我们会发现
通过控制台发现以下情况,至于原因则看完了源代码之后相信会理解为何会有这个结果
1.只会执行一次sql
2.第一次和第二次获取的结果相同,第一次和第三次的结果不同。
3.第一次获取到值后修改其属性,影响了第二次及第三次查询出来的结果。
正文
1 二级缓存
说起二级缓存,得先说下二级缓存的设置,我们初始化mybatis在配置configuration的时候有个属性叫做cacheEnabled,这个属性可以手动设置,不设置的话默认为true,说明系统默认是支持二级缓存的,那二级缓存有没有初始化的地方呢,这个又要回到我们解析xxMapper.xml文件中的代码了。我们先来回顾下XmlCongiBuilder.parse()方法中
- public void parse() {
- if (!configuration.isResourceLoaded(resource)) {
- configurationElement(parser.evalNode("/mapper"));
- ...
- }
- }
- private void configurationElement(XNode context) {
- try {
- ...
- cacheElement(context.evalNode("cache"));
- ...
- } catch (Exception e) {
- throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
- }
- }
可以看到 在解析mapper.xml文件时,会找到mapper节点下的cache节点,
- private void cacheElement(XNode context) {
- //如果不为空则执行下面的逻辑
- if (context != null) {
- //获取缓存type 没有则默认为PERPETUAL
- String type = context.getStringAttribute("type", "PERPETUAL");
- //获取缓存type 看下类型是否是别名已注册了的
- Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
- //获取缓存算法 默认为LRU 淘汰最近最小使用
- String eviction = context.getStringAttribute("eviction", "LRU");
- //获取其别名类型
- Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
- //获取刷新间隔
- Long flushInterval = context.getLongAttribute("flushInterval");
- //获取缓存大小
- Integer size = context.getIntAttribute("size");
- //是否只读 默认false
- boolean readWrite = !context.getBooleanAttribute("readOnly", false);
- //是否有锁 默认false
- boolean blocking = context.getBooleanAttribute("blocking", false);
- //获取里面值
- Properties props = context.getChildrenAsProperties();
- //创建缓存
- builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
- }
- }
注意这儿总体的逻辑大致是判断mapper节点下是否有cache节点,如果有则获取其值并构建缓存。所以我们可以得出二级缓存是为每个mapper构建了一个缓存,并且需要我们在mapper中设置cache节点才能生效,二级缓存是mapper级别的缓存。我们可以再看下具体的构建逻辑
- public Cache useNewCache(Class<? extends Cache> typeClass,
- Class<? extends Cache> evictionClass,
- Long flushInterval,
- Integer size,
- boolean readWrite,
- boolean blocking,
- Properties props) {
- //构建cache
- Cache cache = new CacheBuilder(currentNamespace) //currentNamespace 即缓存的id
- .implementation(valueOrDefault(typeClass, PerpetualCache.class)) //缓存实现
- .addDecorator(valueOrDefault(evictionClass, LruCache.class)) //缓存算法
- .clearInterval(flushInterval) //刷新间隔
- .size(size) //缓存大小
- .readWrite(readWrite) //是否只读
- .blocking(blocking) //是否有锁
- .properties(props) //cache节点中的值
- .build(); //最终构建
- //在configuration中添加cache
- configuration.addCache(cache);
- //设置当前Builder的cache
- currentCache = cache;
- return cache;
- }
- /*********configuration中********/
- protected final Map<String, Cache> caches = new StrictMap<>("Caches collection");
- public void addCache(Cache cache) {
- caches.put(cache.getId(), cache);
- }
这儿可以看出主要是根据我们传入的值采用构建模式构建一个缓存,缓存id为nameSpace。最终存到了configuration中caches。我们注意这儿设置了一个currentCache,这个有什么用呢,其实在解析xml构建每个方法的MappedStatment时会设置到cache中,我们可以看下解析每个sql方法时其中有一个步骤
- MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
- .resource(resource)
- .fetchSize(fetchSize)
- .timeout(timeout)
- .statementType(statementType)
- .keyGenerator(keyGenerator)
- .keyProperty(keyProperty)
- .keyColumn(keyColumn)
- .databaseId(databaseId)
- .lang(lang)
- .resultOrdered(resultOrdered)
- .resultSets(resultSets)
- .resultMaps(getStatementResultMaps(resultMap, resultType, id))
- .resultSetType(resultSetType)
- .flushCacheRequired(valueOrDefault(flushCache, !isSelect)) //flushCache即该方法是否刷新缓存,如果没设置那么默认 select不刷新,其他更新操作默认刷新
- .useCache(valueOrDefault(useCache, isSelect)) //useCache即是否使用cache,如果没设置 那么默认 select使用 其他更新操作不使用
- .cache(currentCache);//设置当前的缓存
- private <T> T valueOrDefault(T value, T defaultValue) {
- return value == null ? defaultValue : value;
- }
通过这个方法构建的最后一步可以知道,mapper中的方法默认使用的都是一个缓存管理器。还有两个构建步骤需要注意即flushCacheRequired & useCache。这个注释已经写的比较明确,在后面我们使用二级缓存的时候,这两个属性非常重要,所以还请大家牢记
到此,二级缓存的初始化已经解析完毕,可以发现mybatis在解析mapper.xml的时候就已经为每个mapper生成了一个缓存管理器(如果配置了cache节点),那程序中是如何使用的呢?我们接着往下看
本文假设读者已经了解了mybatis的查询流程,如果不了解的建议先看我的前三篇博文
1.1 二级缓存使用的前置CachingExecutor
我们在查询时使用SqlSessionFactory.openSession方法时会同时构建一个Executor作为执行器,我们再简要看下创建Executor的逻辑
- public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
- executorType = executorType == null ? defaultExecutorType : executorType;
- executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
- Executor executor;
- if (ExecutorType.BATCH == executorType) {
- executor = new BatchExecutor(this, transaction);
- } else if (ExecutorType.REUSE == executorType) {
- executor = new ReuseExecutor(this, transaction);
- } else {
- executor = new SimpleExecutor(this, transaction);
- }
- if (cacheEnabled) { //判断是否使用缓存
- executor = new CachingExecutor(executor);
- }
- executor = (Executor) interceptorChain.pluginAll(executor);
- return executor;
- }
其中有一步需要注意if (cacheEnabled) ,如果条件成立 那么就会用静态代理的方法创建一个CachingExecutor,这个cacheEnabled则是我们的configuration的cacheEnabled属性,是我们一开始设置的。也可以不设置 ,默认为true,即默认开启二级缓存。所以我们会使用CachingExecutor来进行sql操作,那么具体的存储逻辑呢? 我们则来看一下CachingExecutor的查询逻辑
1.2构造cacheKey即缓存的key
我们随便找到其中查询方法
- @Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameterObject);
- CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
- return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
可以看到这儿根据我们的参数构造的了一个缓存的key,我们来具体看下创建缓存key的过程,最终调用的是BaseExecutor的方法
- @Override
- public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
- //创建一个缓存key
- CacheKey cacheKey = new CacheKey();
- //散列方法的类名+方法名
- cacheKey.update(ms.getId());
- //散列分页的开始数据位置
- cacheKey.update(rowBounds.getOffset());
- //散列分页的数据长度
- cacheKey.update(rowBounds.getLimit());
- //散列要执行的sql
- cacheKey.update(boundSql.getSql());
- //获取参数信息
- List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
- //获取类型转换器
- TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
- // mimic DefaultParameterHandler logic
- for (ParameterMapping parameterMapping : parameterMappings) {
- if (parameterMapping.getMode() != ParameterMode.OUT) {
- Object value;
- String propertyName = parameterMapping.getProperty();
- if (boundSql.hasAdditionalParameter(propertyName)) {
- value = boundSql.getAdditionalParameter(propertyName);
- } else if (parameterObject == null) {
- value = null;
- } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
- value = parameterObject;
- } else {
- MetaObject metaObject = configuration.newMetaObject(parameterObject);
- value = metaObject.getValue(propertyName);
- }
- //参数值进行散列
- cacheKey.update(value);
- }
- }
- if (configuration.getEnvironment() != null) {
- // 如果指定了环境 那么对环境id进行散列
- cacheKey.update(configuration.getEnvironment().getId());
- }
- return cacheKey;
- }
- /******************cacheKey*********************/
- public void update(Object object) {
- //每次都对hashcode新处理 并将传入的值加入updateList
- int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
- //参数数量+1
- count++;
//核实码 即每个参数值的hashcode相加- checksum += baseHashCode;
- baseHashCode *= count;
- hashcode = multiplier * hashcode + baseHashCode;
- //将传入的数据加入updateList
- updateList.add(object);
- }
可以看到 这个核心的缓存key主要对方法的全限定名,分页信息,执行的sql,参数类型以及参数值,环境id 进行散列并且存储信息。所以我们可以得知 mybatis对两次查询是否完全一致的判定标准就是前面的这几项是否完全一致。那么是否是这样呢,我们可以看下其equals方法
- @Override
- public boolean equals(Object object) {
- //如果内存地址一致那肯定一致
- if (this == object) {
- return true;
- }
- //类型不同肯定不一致
- if (!(object instanceof CacheKey)) {
- return false;
- }
- final CacheKey cacheKey = (CacheKey) object;
- //如果hashcode不同那肯定不同
- if (hashcode != cacheKey.hashcode) {
- return false;
- }
- //判断核实码
- if (checksum != cacheKey.checksum) {
- return false;
- }
- //判断参数数量
- if (count != cacheKey.count) {
- return false;
- }
- //判断每个传入的参数 即全限定名,分页信息,执行的sql,参数类型以及参数值,环境id 的equals是否满足
- for (int i = 0; i < updateList.size(); i++) {
- Object thisObject = updateList.get(i);
- Object thatObject = cacheKey.updateList.get(i);
- if (!ArrayUtil.equals(thisObject, thatObject)) {
- return false;
- }
- }
- return true;
- }
通过这个方法的最后代码可以得知最后还是对每个参数进行了equals判断,所以满足上面的说法
缓存key构造出来之后相信后面的逻辑大家也大概能理出来了,就是查询缓存,如果没有则查询数据库,然后把结果放入缓存,这是经典的缓存规则,不过mybatis的二级缓存并不是存储了就马上生效的。我们接着看
1.3 缓存逻辑
缓存key构造完成后 我们接着看查询逻辑,即1.2第一个代码块中的最后一句return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- private final TransactionalCacheManager tcm = new TransactionalCacheManager();
- @Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
- throws SQLException {
- //获取到方法对应mapper的cache
- Cache cache = ms.getCache();
- if (cache != null) {
- //如果该方法是更新操作 或者设置了刷新缓存 即flushCache 则刷新缓存
- flushCacheIfRequired(ms);
- //注意如果方法有resultHandler则不走缓存
- if (ms.isUseCache() && resultHandler == null) {
- //检查如果方法为存储过程 且有输出参数 那么会抛异常
- ensureNoOutParams(ms, boundSql);
- @SuppressWarnings("unchecked")
- //通过缓存管理器查询值
- List<E> list = (List<E>) tcm.getObject(cache, key);
- if (list == null) {
- //没查询到值或者之前的值为null,则从库查询
- list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- //将结果放入缓存管理器,注意此时还没有放入真正的缓存
- tcm.putObject(cache, key, list); // issue #578 and #116
- }
- //返回结果
- return list;
- }
- }
- //查库
- return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
- //刷新缓存
- private void flushCacheIfRequired(MappedStatement ms) {
- Cache cache = ms.getCache();
- if (cache != null && ms.isFlushCacheRequired()) {
- tcm.clear(cache);
- }
- }
这里面就用到了之前让大家注意看的构建MappedStatment时设置的那三个缓存有关的属性了。这儿则先获取到该方法对应的cache,即上面我们设置的currentCache.如果不为空则判断是否需要刷新刷新缓存,如果需要则刷新缓存,然后检查是否设置了usingCahce为true且该方法没有设置resultHandler。然后检查该方法为存储过程且有输出参数,如果是则抛异常。满足这些再从缓存中判断值,这儿的逻辑比较简单,都是经典的缓存处理原理。我们这儿可以得知 mapper中的设置了缓存节点,但select依旧不能用二级缓存的情况有 1.useCache设置为false,2.方法设置了ResultHandler,3.该方法sql为存储过程且有输出参数。同时注意如果flushCache设置为true那么每次调用都会刷新之前的缓存。
但是到这儿缓存依旧没有完全生效,我们可以看到这儿缓存操作的都tcm 即名为TransactionalCacheManager 的类,我们看下我们用到的clear和putObject方法具体的逻辑是什么
1.4 TransactionalCacheManager 缓存缓冲区管理器
- private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
- private TransactionalCache getTransactionalCache(Cache cache) {
- return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
- }
- public void putObject(Cache cache, CacheKey key, Object value) {
- getTransactionalCache(cache).putObject(key, value);
- }
- public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
可以看到这个类对我们传入的每个缓存key都会新建一个TransactionalCache对象,然后将这个存到map中 ,注意缓存的key为我们的cache管理器,传入TransactionalCache的是缓存key和缓存value,computeIfAbsent方法代表的意义是没有则新建一个,所以这儿会通过有参构造传入cache管理器创建一个TransactionalCache。所以我们看下这个类TransactionalCache的属性,以及我们调用的putObject逻辑
1.5TransactionalCache 缓存缓冲区
- public class TransactionalCache implements Cache {
- private static final Log log = LogFactory.getLog(TransactionalCache.class);
- //缓存处理器
- private final Cache delegate;
- //默认false 如果执行 clear为true同时会清除缓存
- private boolean clearOnCommit;
- //待生效的缓存
- private final Map<Object, Object> entriesToAddOnCommit;
- //未命中的缓存
- private final Set<Object> entriesMissedInCache;
- //构造方法
- public TransactionalCache(Cache delegate) {
- this.delegate = delegate;
- this.clearOnCommit = false;
- this.entriesToAddOnCommit = new HashMap<>();
- this.entriesMissedInCache = new HashSet<>();
- }
- @Override
- public String getId() {
- return delegate.getId();
- }
- @Override
- public int getSize() {
- return delegate.getSize();
- }
- @Override
- public Object getObject(Object key) {
- // 缓存管理器拿到缓存
- Object object = delegate.getObject(key);
- if (object == null) {
- //没拿到则添加到未命中缓存
- entriesMissedInCache.add(key);
- }
- // 如果此时清空缓存的标识为ture 直接返回null
- if (clearOnCommit) {
- return null;
- } else {
- return object;
- }
- }
- @Override
- public void putObject(Object key, Object object) {
- //添加到待提交的缓存
- entriesToAddOnCommit.put(key, object);
- }
- @Override
- public Object removeObject(Object key) {
- return null;
- }
- @Override
- public void clear() {
- //清除缓存
- clearOnCommit = true;
//等待队列也被清空- entriesToAddOnCommit.clear();
- }
- //执行提交
- public void commit() {
- //执行过clear方法,那么再次清除缓存管理器中的所有缓存
- if (clearOnCommit) {
- delegate.clear();
- }
- //将等待提交的缓存提交
- flushPendingEntries();
- //所有数据置为初始化状态
- reset();
- }
- //执行rollback时清除掉所有未命中的缓存 并且还会清空等待的缓存
- public void rollback() {
- unlockMissedEntries();
- reset();
- }
- private void reset() {
- clearOnCommit = false;
- entriesToAddOnCommit.clear();
- entriesMissedInCache.clear();
- }
- private void flushPendingEntries() {
- for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
- //存在真实缓存处理器中
- delegate.putObject(entry.getKey(), entry.getValue());
- }
- for (Object entry : entriesMissedInCache) {
- //将直到现在也为命中的缓存以值为null的形式存入
- if (!entriesToAddOnCommit.containsKey(entry)) {
- delegate.putObject(entry, null);
- }
- }
- }
- private void unlockMissedEntries() {
- for (Object entry : entriesMissedInCache) {
- try {
- delegate.removeObject(entry);
- } catch (Exception e) {
- log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
- + "Consider upgrading your cache adapter to the latest version. Cause: " + e);
- }
- }
- }
- }
可以看到该类最终的才是真正把缓存存到缓存管理器中的地方,其中的方法也是操作缓存的方法,我们执行的putObject只是将缓存加入了等待map而已,而commit方法中的flushPendingEntries()方法才是真正刷新缓存的地方,由于其时private方法,所以我们要主要看到底哪个地方调用了commit方法。并且如果执行了其clear方法,,缓存管理器中现有缓存将会被清空,等待队列也会被清空,获取缓存也会返回null。执行了rollback方法则会将所有的现有缓存清空且未命中缓存也会清空,clear方法我们上面判断flushCache的值的时候就调用过一次。 我们接着看commit,clear,rollback方法哪些地方会调用
1.6commit,clear,rollback 缓存实际操作
我们看下在CachingExecutor中哪些地方调用了这三个方法
- @Override
- public void close(boolean forceRollback) {
- try {
- //是否强制回滚
- if (forceRollback) {
- //回滚 即清空未命中缓存 且等待提交的缓存也会被清空
- tcm.rollback();
- } else {
- //提交 即将缓存存储真正的缓存管理器
- tcm.commit();
- }
- } finally {
- delegate.close(forceRollback);
- }
- }
- @Override
- public void commit(boolean required) throws SQLException {
- delegate.commit(required);
- //执行缓存管理器的commit 即将等待提交的缓存存入真正的缓存管理器中
- tcm.commit();
- }
- private void flushCacheIfRequired(MappedStatement ms) {
- Cache cache = ms.getCache();
- if (cache != null && ms.isFlushCacheRequired()) {
//清除缓存- tcm.clear(cache);
- }
- }
- @Override
- public void rollback(boolean required) throws SQLException {
- try {
- delegate.rollback(required);
- } finally {
- if (required) {
- tcm.rollback();
- }
- }
- }
其实这三个方法通过分析代码可以得知,close方法在我们执行SqlSession的close方法会执行,commit方法在我们执行SqlSession.commit方法会执行。而flushCacheIfRequired则会在执行update操作或者select操作时判断该方法的Mappedstatment的flushRequired决定执行。当然了 根据默认情况 如果mapper开启了二级缓存 那么update操作(默认flushCache为true)会执行而select操作不会执行默认flushCache为false)。
这儿我们还得注意DefualSqlSession的操作执行close或者commit或者rollback操作时会做一个判断,即会判断是否强制回滚或者数据已经被更改 (dirty属性为true)。满足其一缓存都会被清除
缓存也必须提交了才能生效
- executor.commit(isCommitOrRollbackRequired(force));
- private boolean isCommitOrRollbackRequired(boolean force) {
- return (!autoCommit && dirty) || force;
- }
所以我们可以得出结论
1.执行SqlSession.close操作且传入参数是否强制回滚(默认false)且系统没有数据被更改,则会提交缓存。如果强制回滚或者没有更新操作即dirty为fasle则清除等待缓存
2.执行SqlSession.commit操作会提交缓存
3.执行SqlSession.rollback且传入参数为true或者没有更新操作即dirty为fasle则不会清除缓存,否则会清除等待缓存
4.sql执行时如果方法的MappedStatment的flushRequied为true时则会执行clear方法清除等待缓存以及缓存管理器中的缓存
5.缓存是由具体的缓存管理器实现的,所以我们每次得到的对象都会经过序列化或者反序列化,缓存的对象是不相等的
6.二级缓存默认开启,且范围为mapper范围,但使用需要在mapper.xml中添加cache节点
7.在sql方法中,查询操作usecCache默认为true,flushCache默认为false。更新操作中useCache,默认false,flushCache默认为true。
2. 一级缓存
一级缓存的逻辑比二级缓存简单的多。同时一级缓存的优先级比二级缓存低
一级缓存的操作主要在BaseExecutor中,即二级缓存没有查找到之后使用CachingExecutor中封存的SimpleExecutor的query方法,由于SimpleExecutor没有实现这个方法,所以直接看父类BaseExecutor的方法
- protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads = new ConcurrentLinkedQueue<>();;
//一级缓存- protected PerpetualCache localCache = new PerpetualCache("LocalCache");
//存储过程有关的一级缓存- protected PerpetualCache localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");;
- @SuppressWarnings("unchecked")
- @Override
- public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
- ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
- //当前查询操作在进行且刷新标志位true
- if (queryStack == 0 && ms.isFlushCacheRequired()) {
- //刷新一级cache
- clearLocalCache();
- }
- List<E> list;
- try {
- //查询次数+1
- queryStack++;
- //从缓存拿
- list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
- if (list != null) {
- //不为空则判断下是否为存储过程 如果是的话执行下
- handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
- } else {
- //没找到缓存就直接去数据库查
- list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
- }
- } finally {
- //查询完成 次数-1
- queryStack--;
- }
- //如果没有查询操作在进行
- if (queryStack == 0) {
- //清空一些等待的任务
- for (DeferredLoad deferredLoad : deferredLoads) {
- deferredLoad.load();
- }
- // issue #601
- deferredLoads.clear();
- //如果缓存的scope是STATEMENT (默认为session),那则直接让一级缓存的作用只存在于一次查询中 即给我们一个控制一级缓存的地方
- if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
- //清除缓存
- clearLocalCache();
- }
- }
- return list;
- }
- //清除缓存 和存储过程输出参数缓存
- @Override
- public void clearLocalCache() {
- if (!closed) {
- localCache.clear();
- localOutputParameterCache.clear();
- }
- }
- /***************设置缓存操作************/
- private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
- List<E> list;
- //设置一个缓存标记位
- localCache.putObject(key, EXECUTION_PLACEHOLDER);
- try {
- //查询
- list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
- } finally {
- //清除缓存位
- localCache.removeObject(key);
- }
- //设置缓存
- localCache.putObject(key, list);
- //如果是存储过程
- if (ms.getStatementType() == StatementType.CALLABLE) {
- //存储下存储过程有关的东西
- localOutputParameterCache.putObject(key, parameter);
- }
- return list;
- }
- public class PerpetualCache implements Cache {
- private final String id;
- private Map<Object, Object> cache = new HashMap<>();
- ..................
- }
由于Executor是在我们使用SqlSession.openSession构建的,而一级缓存的存储PerpetualCache 又并非是静态属性,其也是用的非静态Map类来存储的,所以我们可以得知一级缓存的生命周期就是SqlSession的生命周期,同时由于其时用Map即内存存储的对象,所以我们缓存获取到的对象同一开始存的对象是完全相同的。并且方法的刷新标志FlushRequied位true时也会清空缓存。当然了我们执行update操作,或者SqlSession.commit或者SqlSession.close或者SqlSession.rollBack时也会清除本地缓存,源代码如下
- @Override
- public int update(MappedStatement ms, Object parameter) throws SQLException {
- ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
//每次都会执行更新操作- clearLocalCache();
- return doUpdate(ms, parameter);
- }
- @Override
- public void rollback(boolean required) throws SQLException {
- if (!closed) {
- try {
//清除一级缓存- clearLocalCache();
- flushStatements(true);
- } finally {
- if (required) {
- transaction.rollback();
- }
- }
- }
- }
- @Override
- public void commit(boolean required) throws SQLException {
- if (closed) {
- throw new ExecutorException("Cannot commit, transaction is already closed");
- }
//清除一级缓存- clearLocalCache();
- flushStatements();
- if (required) {
- transaction.commit();
- }
- }
- @Override
- public void commit(boolean required) throws SQLException {
- if (closed) {
- throw new ExecutorException("Cannot commit, transaction is already closed");
- }
//清除一级缓存- clearLocalCache();
- flushStatements();
- if (required) {
- transaction.commit();
- }
- }
所以也可以得出结论。
1.一级缓存的优先级低于二级缓存
2.一级缓存默认开启,范围为一次SqlSession的生命周期,手动设置Confiuration的LocalCacheScope为statment可使其的生命周期降低为一次查询
3.一级缓存使用内存管理,获得的都是同一个对象
4.查询操作如何flushRequered为true则会清除一级缓存,所有更新操作都会清除一级缓存
5.SqlSession执行commit或者close操作会清除一级缓存
完结
至此一二级缓存都分析完了,有没有想到一开始的结果是如何出现的呢?这儿可以简单的分析下步骤
1.查询数据,走到二级缓存后没有查询到数据,往下走
2.走到一级缓存,依然没有数据,查询数据库,此时执行sql
3.将结果存入一级缓存的map,由于一级缓存是map存储在内存中,所以一级缓存获取到的对象是一个对象
4.此时二级缓存处获取到了查询的结果,将结果存储在二级缓存等待提交区,然后返回结果
5.我们第一次获取到了结果 ,此时是从一级缓存拿到的,我们修改其中的属性则等于修改了一级缓存中的对象属性
6.我们再次执行查询,由于查询条件方法相同所以缓存key相同,走到二级缓存,此时由于二级缓存还没提交,所以查询结果为空
7.走到一级缓存,查询到了结果返回,此时不执行sql。
8.再次走到二级缓存,二级缓存再次将结果存入等待队列,此时会覆盖之前的等待队列中的对象(属性已经被我们更改)
9.将结果返回,此时得到的依旧是一级缓存的结果,且属性被第5步中更改了,但是和第一次查询到的对象依旧是同一个对象,所以属性是修改后的属性且和第一次查询的对象相同
10.执行close方法,此时会提交本次的二级缓存等待队列
11.再次执行查询方法,由于方法签名一致,走到二级缓存时获取到了缓存的对象(属性已经被更改),此时不执行sql,同时二级缓存不是缓存在内存中,所以获取到的是一个新对象
mybatis源码探索笔记-4(缓存原理)的更多相关文章
- mybatis源码探索笔记-5(拦截器)
前言 mybatis中拦截器主要用来拦截我们在发起数据库请求中的关键步骤.其原理也是基于代理模式,自定义拦截器时要实现Interceptor接口,并且要对实现类进行标注,声明是对哪种组件的指定方法进行 ...
- mybatis源码探索笔记-1(构建SqlSessionFactory)
前言 mybatis是目前进行java开发 dao层较为流行的框架,其较为轻量级的特性,避免了类似hibernate的重量级封装.同时将sql的查询与与实现分离,实现了sql的解耦.学习成本较hibe ...
- mybatis源码探索笔记-3(使用代理mapper执行方法)
前言 前面两章我们构建了SqlSessionFactory,并通过SqlSessionFactory创建了我们需要的SqlSession,并通过这个SqlSession获取了我们需要的代理mapper ...
- mybatis源码探索笔记-2(构建SqlSession并获取代理mapper)
前言 上篇笔记我们成功的装载了Configuration,并写入了我们全部需要的信息.根据这个Configuration创建了DefaultSqlSessionFactory.本篇我们实现构建SqlS ...
- Mybatis源码研究7:缓存的设计和实现
Mybatis源码研究7:缓存的设计和实现 2014年11月19日 21:02:14 酷酷的糖先森 阅读数:1020 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- mybatis源码学习(三)-一级缓存二级缓存
本文主要是个人学习mybatis缓存的学习笔记,主要有以下几个知识点 1.一级缓存配置信息 2.一级缓存源码学习笔记 3.二级缓存配置信息 4.二级缓存源码 5.一级缓存.二级缓存总结 1.一级缓存配 ...
- 手把手带你阅读Mybatis源码(三)缓存篇
前言 大家好,这一篇文章是MyBatis系列的最后一篇文章,前面两篇文章:手把手带你阅读Mybatis源码(一)构造篇 和 手把手带你阅读Mybatis源码(二)执行篇,主要说明了MyBatis是如何 ...
- mybatis源码学习:一级缓存和二级缓存分析
目录 零.一级缓存和二级缓存的流程 一级缓存总结 二级缓存总结 一.缓存接口Cache及其实现类 二.cache标签解析源码 三.CacheKey缓存项的key 四.二级缓存TransactionCa ...
- 【MyBatis源码分析】插件实现原理
MyBatis插件原理----从<plugins>解析开始 本文分析一下MyBatis的插件实现原理,在此之前,如果对MyBatis插件不是很熟悉的朋友,可参看此文MyBatis7:MyB ...
随机推荐
- mysql 同时支持多少连接MYSQL 查看最大连接数和修改最大连接数
MySQL查看最大连接数和修改最大连接数 1.查看最大连接数 show variables like '%max_connections%'; 2.修改最大连接数 set GLOBAL max_con ...
- C语言数据结构——第一章 数据结构的概念
一.数据结构的基本概念 1.1-数据结构是什么? 数据结构是计算机存储和组织数据的方式.数据结构是指相互之间存在一种或多种特定关系的数据元素的集合.一般情况下,精心选择的数据结构可以带来更高的运行或者 ...
- python入门(二十讲):爬虫
什么是爬虫? 按照一定的规则,自动地抓取万维网信息的程序或脚本. 爬虫目的: 从网上爬取出来大量你想获取类型的数据,然后用来分析大量数据的类似点或者其他信息来对你所进行的工作提供帮助. 为什么选择py ...
- linux备忘命令
1,安装vim以后把vim中的tab键设置为4个空格 vim ~/.vimrc一下,如果没有会创建新的, 然后添加下面两行: set ts=4 set expandtab 如果第二行内容是noexpa ...
- 【代码审计】seacms 前台Getshell分析
一.漏洞分析 漏洞触发点search.php 211-213行 跟进parseIf 函数 ./include/main.class.php 这里要注意 3118行的位置,可以看到未做任何处理的eval ...
- 【资源分享】RPG Maker 2000/2003 简体中文版
*----------------------------------------------[下载区]----------------------------------------------* ...
- Linux 内核内存池
内核中经常进行内存的分配和释放.为了便于数据的频繁分配和回收,通常建立一个空闲链表——内存池.当不使用的已分配的内存时,将其放入内存池中,而不是直接释放掉. Linux内核提供了slab层来管理内存的 ...
- java中的main方法参数String[] args的说明
参数String[] args 的作用是在运行main方法时,在控制台输入参数 class Test{ public static void main(String[] args){ for(Stri ...
- 本地mongodb数据库导出到远程数据库中
把本地Mongodb中的数据导入(批量插入)到服务器的数据库中 1.导出数据: mongoexport -d admin -c users -o outdatafile.dat 选项解释: -d 指明 ...
- Cesium 基于MapBox底图加载3DTiles 模型
3DTiles 模型采用 CATIA V5 R22 --->3dxml --->GLB--->B3DM var extent = Cesium.Rectangle.fromDeg ...