机器学习(ML)七之模型选择、欠拟合和过拟合
训练误差和泛化误差
需要区分训练误差(training error)和泛化误差(generalization error)。前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平方损失函数和softmax回归用到的交叉熵损失函数。
直观地解释训练误差和泛化误差这两个概念。训练误差可以认为是做往年高考试题(训练题)时的错误率,泛化误差则可以通过真正参加高考(测试题)时的答题错误率来近似。假设训练题和测试题都随机采样于一个未知的依照相同考纲的巨大试题库。如果让一名未学习中学知识的小学生去答题,那么测试题和训练题的答题错误率可能很相近。但如果换成一名反复练习训练题的高三备考生答题,即使在训练题上做到了错误率为0,也不代表真实的高考成绩会如此。
机器学习里,我们通常假设训练数据集(训练题)和测试数据集(测试题)里的每一个样本都是从同一个概率分布中相互独立地生成的。基于该独立同分布假设,给定任意一个机器学习模型(含参数),它的训练误差的期望和泛化误差都是一样的。例如,如果我们将模型参数设成随机值(小学生),那么训练误差和泛化误差会非常相近。
模型的参数是通过在训练数据集上训练模型而学习出的,参数的选择依据了最小化训练误差(高三备考生)。所以,训练误差的期望小于或等于泛化误差。也就是说,一般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。
机器学习模型应关注降低泛化误差。
模型选择
在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这一过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。为了得到有效的模型,我们通常要在模型选择上下一番功夫。下面,我们来描述模型选择中经常使用的验证数据集(validation data set)。
验证数据集
测试集只能在所有超参数和模型参数选定后使用一次。不可以使用测试数据选择模型,如调参。由于无法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
然而在实际应用中,由于数据不容易获取,测试数据极少只使用一次就丢弃。因此,实践中验证数据集和测试数据集的界限可能比较模糊。从严格意义上讲,除非明确说明,否则中实验所使用的测试集应为验证集,实验报告的测试结果(如测试准确率)应为验证结果(如验证准确率)。
K 折交叉验证
由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是K折交叉验证(K-fold cross-validation)。K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
欠拟合和过拟合
模型训练中经常出现的两类典型问题:
1、模型无法得到较低的训练误差,一现象称作欠拟合(underfitting);
2、模型的训练误差远小于它在测试数据集上的误差,该现象为过拟合(overfitting)。
在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。
模型复杂度
为了解释模型复杂度,以多项式函数拟合为例。给定一个由标量数据特征x和对应的标量标签y组成的训练数据集,多项式函数拟合的目标是找一个K阶多项式函数
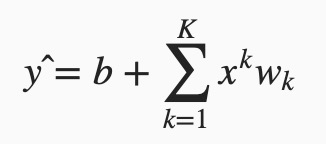
来近似y。在上式中,wk是模型的权重参数,b是偏差参数。与线性回归相同,多项式函数拟合也使用平方损失函数。特别地,一阶多项式函数拟合又叫线性函数拟合。
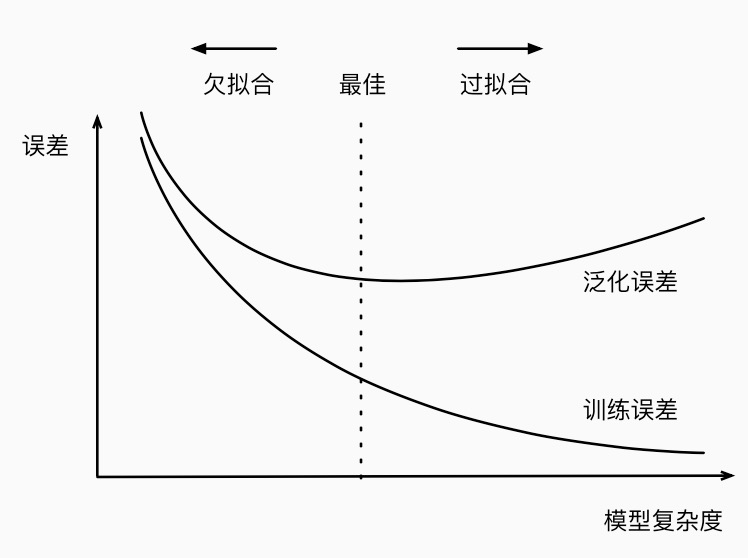
因为高阶多项式函数模型参数更多,模型函数的选择空间更大,所以高阶多项式函数比低阶多项式函数的复杂度更高。因此,高阶多项式函数比低阶多项式函数更容易在相同的训练数据集上得到更低的训练误差。给定训练数据集,模型复杂度和误差之间的关系通常如下图所示。给定训练数据集,如果模型的复杂度过低,很容易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的一个办法是针对数据集选择合适复杂度的模型。
训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
权重衰减
模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。应对过拟合问题的常用方法:权重衰减(weight decay)。
方法
权重衰减等价于L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述L2范数正则化,再解释它为何又称权重衰减。
L2范数正则化在模型原损失函数基础上添加L2范数惩罚项,从而得到训练所需要最小化的函数。L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以“线性回归”中的线性回归损失函数

丢弃法
除了权重衰减以外,深度学习模型常常使用丢弃法(dropout)来应对过拟合问题。丢弃法有一些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
方法
“多层感知机”描述了一个单隐藏层的多层感知机。其中输入个数为4,隐藏单元个数为5,且隐藏单元hihi(i=1,…,5i=1,…,5)的计算表达式为

多项式函数拟合实验代码
#!/usr/bin/env python
# coding: utf-8 # In[1]: get_ipython().run_line_magic('matplotlib', 'inline')
import d2lzh as d2l
from mxnet import autograd, gluon, nd
from mxnet.gluon import data as gdata, loss as gloss, nn # 生成数据集
#
# 我们将生成一个人工数据集。在训练数据集和测试数据集中,给定样本特征x,我们使用如下的三阶多项式函数来生成该样本的标签:
# $$y = 1.2x - 3.4x^2 + 5.6x^3 + 5 + \epsilon,$$
# 其中噪声项ϵ服从均值为0、标准差为0.1的正态分布。训练数据集和测试数据集的样本数都设为100。 # In[2]: n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
features = nd.random.normal(shape=(n_train + n_test, 1))
poly_features = nd.concat(features, nd.power(features, 2),
nd.power(features, 3))
labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1]
+ true_w[2] * poly_features[:, 2] + true_b)
labels += nd.random.normal(scale=0.1, shape=labels.shape) # In[3]: #查看生成的数据集的前两个样本
features[:2], poly_features[:2], labels[:2] # In[4]: # 定义作图函数semilogy,其中 y 轴使用了对数尺度。
# 本函数已保存在d2lzh包中方便以后使用
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend) # 和线性回归一样,多项式函数拟合也使用平方损失函数。因为我们将尝试使用不同复杂度的模型来拟合生成的数据集,所以我们把模型定义部分放在fit_and_plot函数中。多项式函数拟合的训练和测试步骤与“softmax回归的从零开始实现”一节介绍的softmax回归中的相关步骤类似。 # In[5]: num_epochs, loss = 100, gloss.L2Loss() def fit_and_plot(train_features, test_features, train_labels, test_labels):
net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize()
batch_size = min(10, train_labels.shape[0])
train_iter = gdata.DataLoader(gdata.ArrayDataset(
train_features, train_labels), batch_size, shuffle=True)
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': 0.01})
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
with autograd.record():
l = loss(net(X), y)
l.backward()
trainer.step(batch_size)
train_ls.append(loss(net(train_features),
train_labels).mean().asscalar())
test_ls.append(loss(net(test_features),
test_labels).mean().asscalar())
print('final epoch: train loss', train_ls[-1], 'test loss', test_ls[-1])
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('weight:', net[0].weight.data().asnumpy(),
'\nbias:', net[0].bias.data().asnumpy()) # ### 三阶多项式函数拟合(正常)
# 我们先使用与数据生成函数同阶的三阶多项式函数拟合。实验表明,这个模型的训练误差和在测试数据集的误差都较低。训练出的模型参数也接近真实值:$$w_1 = 1.2, w_2=-3.4, w_3=5.6, b = 5$$ # In[6]: fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:]) # ### 线性函数拟合(欠拟合)
# 我们再试试线性函数拟合。很明显,该模型的训练误差在迭代早期下降后便很难继续降低。在完成最后一次迭代周期后,训练误差依旧很高。线性模型在非线性模型(如三阶多项式函数)生成的数据集上容易欠拟合。 # In[7]: fit_and_plot(features[:n_train, :], features[n_train:, :], labels[:n_train],
labels[n_train:]) # ### 训练样本不足(过拟合)
# 事实上,即便使用与数据生成模型同阶的三阶多项式函数模型,如果训练样本不足,该模型依然容易过拟合。让我们只使用两个样本来训练模型。显然,训练样本过少了,甚至少于模型参数的数量。这使模型显得过于复杂,以至于容易被训练数据中的噪声影响。在迭代过程中,尽管训练误差较低,但是测试数据集上的误差却很高。这是典型的过拟合现象。 # In[8]: fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :], labels[0:2],
labels[n_train:])
高维线性回归实验
# ### 高维线性回归实验
# 以高维线性回归为例来引入一个过拟合问题,并使用权重衰减来应对过拟合。设数据样本特征的维度为p。对于训练数据集和测试数据集中特征为$x_1, x_2, \ldots, x_p$的任一样本,我们使用如下的线性函数来生成该样本的标签:
# $$y = 0.05 + \sum_{i = 1}^p 0.01x_i + \epsilon,$$
# 其中噪声项$\epsilon$服从均值为0、标准差为0.01的正态分布。为了较容易地观察过拟合,我们考虑高维线性回归问题,如设维度p=200;同时,我们特意把训练数据集的样本数设低,如20。 # In[10]: get_ipython().run_line_magic('matplotlib', 'inline')
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import data as gdata, loss as gloss, nn n_train, n_test, num_inputs = 20, 100, 200
true_w, true_b = nd.ones((num_inputs, 1)) * 0.01, 0.05 features = nd.random.normal(shape=(n_train + n_test, num_inputs))
labels = nd.dot(features, true_w) + true_b
labels += nd.random.normal(scale=0.01, shape=labels.shape)
train_features, test_features = features[:n_train, :], features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:] # In[11]: def init_params():
w = nd.random.normal(scale=1, shape=(num_inputs, 1))
b = nd.zeros(shape=(1
DROPOUT代码实现
# ### dropout代码实现 # In[17]: import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn def dropout(X, drop_prob):
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return X.zeros_like()
mask = nd.random.uniform(0, 1, X.shape) < keep_prob
return mask * X / keep_prob # In[18]: X = nd.arange(16).reshape((2, 8))
dropout(X, 0) # In[19]: dropout(X, 0.5) # In[20]: dropout(X, 1) # In[22]:
机器学习(ML)七之模型选择、欠拟合和过拟合的更多相关文章
- 转:机器学习 规则化和模型选择(Regularization and model selection)
规则化和模型选择(Regularization and model selection) 转:http://www.cnblogs.com/jerrylead/archive/2011/03/27/1 ...
- MXNET:欠拟合、过拟合和模型选择
当模型在训练数据集上更准确时,在测试数据集上的准确率既可能上升又可能下降.这是为什么呢? 训练误差和泛化误差 在解释上面提到的现象之前,我们需要区分训练误差(training error)和泛化误差( ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- DL基础补全计划(三)---模型选择、欠拟合、过拟合
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- Stanford机器学习笔记-6. 学习模型的评估和选择
6. 学习模型的评估与选择 Content 6. 学习模型的评估与选择 6.1 如何调试学习算法 6.2 评估假设函数(Evaluating a hypothesis) 6.3 模型选择与训练/验证/ ...
- PRML读书会第一章 Introduction(机器学习基本概念、学习理论、模型选择、维灾等)
主讲人 常象宇 大家好,我是likrain,本来我和网神说的是我可以作为机动,大家不想讲哪里我可以试试,结果大家不想讲第一章.估计都是大神觉得第一章比较简单,所以就由我来吧.我的背景是统计与数学,稍懂 ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 偏差(Bias)和方差(Variance)——机器学习中的模型选择zz
模型性能的度量 在监督学习中,已知样本 ,要求拟合出一个模型(函数),其预测值与样本实际值的误差最小. 考虑到样本数据其实是采样,并不是真实值本身,假设真实模型(函数)是,则采样值,其中代表噪音,其均 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
随机推荐
- IHostingEnvironment VS IHostEnvironment - .NET Core 3.0中的废弃类型
原文: https://andrewlock.net/ihostingenvironment-vs-ihost-environment-obsolete-types-in-net-core-3/ 作者 ...
- centos 7.3 服务器环境搭建——MySQL 安装和配置
centos 7.3 服务器环境搭建——MySQL 安装和配置服务器信息如下:服务器:阿里云系统 centos 7.3 (阿里云该版本最新系统)mysql版本:5.7.18 (当前时间最新版本)连接服 ...
- 02_css3.0 前端长度单位 px em rem vm vh vm pc pt in 你真的懂了吗?
1:废话不多说,直接看如下图表: 2:px就不过多介绍了,就是像素点的大小,加入您的屏幕分辨率为1920,则每一个相当于每一个有横着的1920个像素点: 3:em 为相对单位,一般以 body 内的 ...
- 安装 redis
官方下载地址:http://redis.io/download,但是官方没有64位的Windows下的可执行程序. 目前有个开源的托管在github上, 地址:https://github.com/S ...
- bootstrap:按钮下拉菜单
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- mysql 执行计划查看
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈.explain执行计划包含的信息 其中最重要的字段为:id ...
- python 多进程处理图像,充分利用CPU
默认情况下,Python程序使用一个CPU以单个进程运行.不过如果你是在最近几年配置的电脑,通常都是四核处理器,也就是有8个CPU.这就意味着在你苦苦等待Python脚本完成数据处理工作时,你的电脑其 ...
- C++ 排序引用的优化
链接:https://www.nowcoder.com/acm/contest/83/B来源:牛客网 题目描述 第一次期中考终于结束啦!沃老师是个语文老师,他在评学生的作文成绩时,给每位学生的分数都是 ...
- Git创建远程分支并提交代码到远程分支
1.可以在VS中新建分支 2.可以通过git branch -r 命令查看远端库的分支情况 这些红色都是远程的分支 3.从已有的分支创建新的分支(如从master分支),创建一个dev分支 (不用vs ...
- 玩转Django2.0---Django笔记建站基础十一(二)((音乐网站开发))
11.5 歌曲排行榜 歌曲排行榜是通过首页的导航链接进入的,按照歌曲的播放次数进行降序显示.从排行榜页面的设计图可以看到,网页实现三个功能:网页顶部搜索.歌曲分类筛选和歌曲信息列表,其说明如下: 1. ...