打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——《TSDB云边一体化时序时空数据库技术揭秘》
自修 —— 阿里云智能数据库产品事业部高级专家

认识TSDB
第一代时序时空数据处理工具 虽然通用关系数据库可以存储时序数据,但是由于缺乏针对时间的特殊优化,比如按时间间隔存储和检索数据等等,因此在处理这些数据时效率相对不高。 第一代时序数据典型来源于监控领域,直接基于平板文件的简单存储工具成为这类数据的首先存储方式。 以RRDTool,Wishper为代表,通常这类系统处理的数据模型比较单一,单机容量受限,并且内嵌于监控告警方案。
第二代面向时序时空领域的数据库伴随着大数据和Hadoop的发展,时序数据量开始迅速增长,系统业务对于处理时序数据的扩展性等方面提出更多的要求。 基于通用存储而专门构建的时间序列数据库开始出现,它可以按时间间隔高效地存储和处理这些数据。像OpenTSDB,KairosDB等等。
这类时序数据库在继承通用存储优势的基础上,利用时序的特性规避部分通用存储的劣势,并且在数据模型,聚合分析方面做了贴合时序的大量创新。 比如OpenTSDB继承了HBase的宽表属性结合时序设计了偏移量的存储模型,利用salt缓解热点问题等等。 然而它也有诸多不足之处,比如低效的全局UID机制,聚合数据的加载不可控,无法处理高基数标签查询等等。 随着docker,kubernetes, 微服务等技术的发展,以及对于IoT的发展预期越来越强烈。
在数据随着时间而增长的过程中,时间序列数据成为增长最快的数据类型之一。 高性能,低成本的垂直型时序数据库开始诞生,以InfluxDB为代表的具有时序特征的数据存储引擎逐步引领市场。 它们通常具备更加高级的数据处理能力,高效的压缩算法和符合时序特征的存储引擎。 比如InfluxDB的基于时间的TSMT存储,Gorilla压缩,面向时序的窗口计算函数p99,rate,自动rollup等等。 同时由于索引分离的架构,在膨胀型时间线,乱序等场景下依然面临着很大的挑战。
第三代云时序时空数据库 从2016年开始,各大云厂商纷纷布局TSDB,2017.4 Microsoft发布时序见解预览版,提供的完全托管、端到端的存储和查询高度情景化loT时序数据解决方案。强大的可视化效果用于基于资产的数据见解和丰富的交互式临时数据分析。 针对数据类型分为暖数据分析和原始数据分析,按照存储空间和查询量分别计费。2018.11 Amazon在AWS re Invent大会发布Timestream预览版。适用于 IoT 和运营应用程序等场景。 提供自适应查询处理引擎快速地分析数据,自动对数据进行汇总、保留、分层和压缩处理。 按照写入流量,存储空间,查询数据量的方式计费,以serverless的形式做到最低成本管理。
阿里云智能TSDB团队自2016年第一版时序数据库落地后,逐步服务于DBPaaS,Sunfire等集团业务,在2017年中旬公测后,于2018年3月底正式商业化。 在此过程中,TSDB在技术方面不断吸纳时序领域各家之长,逐步形成了高性能低成本,免运维,易用性逐步提升,边云一体化,生态丰富等产品优势。
技术揭秘

1. 分布式流式聚合器
时序聚合运算是时序数据库区别于通用数据库的特色之一。TSDB的聚合器主要算子涵盖了插值,降采样,降维等等OpenTSDB协议中的计算函数。借鉴传统数据库执行模式,引入pipeline的执行模式(aka Volcano / Iterator 执行模式)。
Pipeline包含不同的执行计算算子(operator), 一个查询被物理计划生成器解析分解成一个DAG或者operator tree, 由不同的执行算子组成,DAG上的root operator负责驱动查询的执行,并将查询结果返回调用者。在执行层面,采用的是top-down需求驱动 (demand-driven)的方式,从root operator驱动下面operator的执行。这样的执行引擎架构具有优点:
- 这种架构方式被很多数据库系统采用并证明是有效;
- 接口定义清晰,不同的执行计算算子可以独立优化,而不影响其他算子;
- 易于扩展:通过增加新的计算算子,很容易实现扩展功能。比如目前查询协议里只定义了tag上的查询条件。如果要支持指标值上的查询条件(cpu.usage <= 70% and cpu.usage <=90%),可以通过增加一个新的FieldFilterOp来实现
- 从查询优化器到生成执行计划,把查询语句重写成子查询后构建Operator Tree, 执行器驱动Operators完成聚合逻辑,执行Fragment顺序:Filtering -> Grouping -> Downsampling -> Interpolation -> Aggregation -> Rate Conversion -> Functions
- 区分不同查询场景,采用不同聚合算子分别优化,支持结果集的流式读取和物化, Operator的结果在包含None,dsOp等情况下采用流式聚合,而一些时间线之间的聚合仍然是物化运算。
2.时空数据的查询和分析
在介绍时空数据的查询分析之前,简单介绍下什么是时空数据以及时空数据的特点。
大数据时代产生了大量的有时间和空间、标记对象个体行为的时空数据。
比如个人手机产生的信令数据、共享出行的司乘位置和订单数据、车联网和无人驾驶行业的实时车辆数据、物流的位置流数据,以及外卖小哥的送餐轨迹等,都是这类数据。
时空数据的特点之一是复杂性和目标的多样性,存在许多时空分析方法,比如聚类,预测,变化检测,频繁模式挖掘,异常检测和关系挖掘。
时空数据另外一个特点是数据量级呈指数型增长,也是时序数据的在高维空间的展开。传统数据库可伸缩性差,难以管理海量时空数据。高并发情况下,由于存储和计算没有分离,时空数据的检索会是很大瓶颈,可能造成检索性能急剧下降,响应时间超过数分钟。
面对这样的数据量、计算量和对分析延时要求的挑战,时空数据库TSDB从多个技术维度进行了突破。如存储计算分离、高性能时空索引、时空SQL优化器、时空计算引擎、时空数据压缩算法。
时空过滤条件的识别与下推
有别于通用数据的<,>和=关系,时空数据的查询过滤条件通常是一些类似于st_contains(),
st_intersects() 的空间分析函数。因此SQL优化器会解析识别过滤条件之中的时空过滤条件,根据存储引擎的特性,决定哪些过滤条件可以下推,如果有无法下推的条件,则会将这些条件留在Filter算子之中,由计算引擎来进行过滤。而如果过滤条件可以被下推,则优化器会生成新的Filter算子。优化前后的关系算子如下图所示:
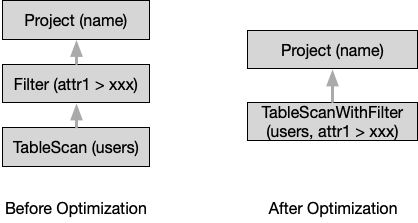
时空计算引擎
在通用数据库中,JOIN是两张表之中某两个列相等,对应的有NestedLoopJOIN、HashJOIN,SortMergeJOIN等算法。
对于时空数据而言,找到两个相等的几何对象几乎不可能,多是基于st_contains()等空间位置关系或是st_distance()距离关系,来做JOIN。
比如找出云栖小镇附近1公里的所有出租车,JOIN条件就是出租车位置要包含在云栖小镇为圆心,半径1公里的圆形空间范围之内;比如找出离我最近的出租车,这就要用到KNN JOIN。而这些JOIN就超出了通用数据库JOIN算法可以优化的范畴。
在时空数据库TSDB之中,采用了专门的Scalable Sweeping-Based Spatial Join算法、时空索引、存储层+计算层的Two level index进行优化。当SQL优化器识别到两表JOIN的条件为时空分析函数时,如果参数等条件都符合要求,则SQL优化器会生成专门的时空JOIN算子,采用专门的JOIN算法来实现,这样的算法比朴素的JOIN算子性能要高出很多。
开源生态
TSDB 提供开源influxDB 和 开源Prometheus 两大生态的支持。
influxDB是DBengines上排名第一的时序数据库,阿里云influxDB®在开源influxDB基础之上提供一下功能:
1.水平可扩展集群方案
2.全局内存管理
3.全面兼容TICK生态
水平可扩展集群方案
- 使用raft实现influxDB数据节点的高可用,同时提供多个高可用方案,让用户可以在可用性和成本中选择最适合自己的方案。
- 阿里云influxDB®支持根据数据量大小,动态增加influxDB数据节点的高可用组。
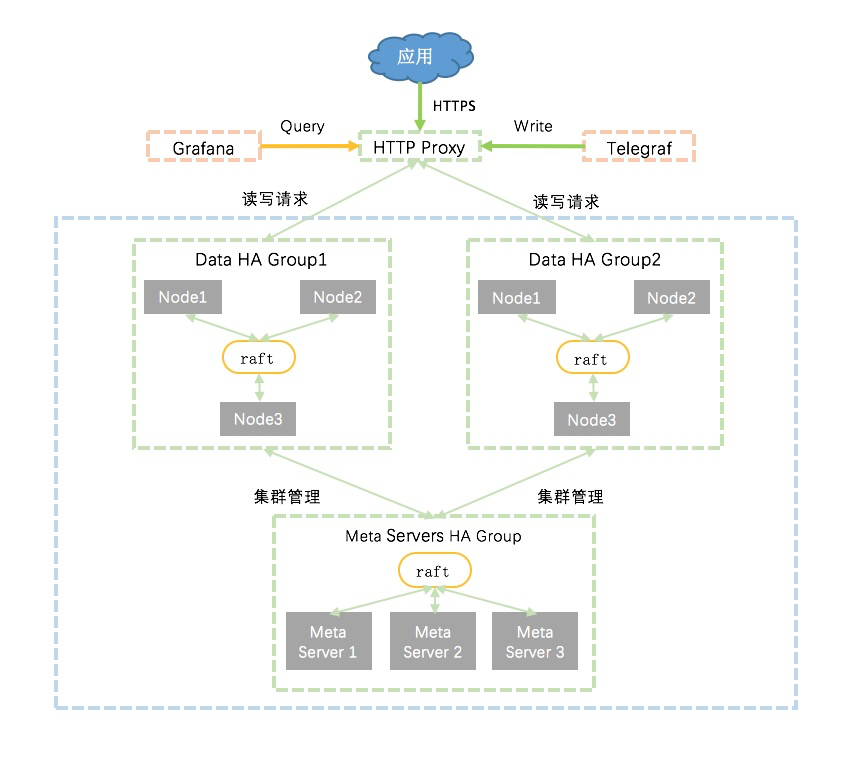
全局内存管理
- 阿里云influxDB®通过对influxDB代码的优化,实现了全局内存管理,可以通过动态调整内存使用
- 全局内存管理支持阿里云influxDB创建任意多个database
- 全局内存管理实现了数据写入以及数据查询的内存管理,可以非常显著的防止由于OOM引发的稳定性问题,提高整个系统的可用性
TICK生态兼容
- 阿里云influxDB全面兼容TICK生态,支持对接telegraf,chronograf以及kapacitor
- 除此之外,阿里云influxDB支持对接grafana,用户能够使用更加丰富的图形化工具展示influxDB中的数据
- 阿里云influxDB提供“一键式”的数据采集工具,用户可以非常方便的安装、启动数据采集工具,并且在阿里云管理平台上管理数据采集工具
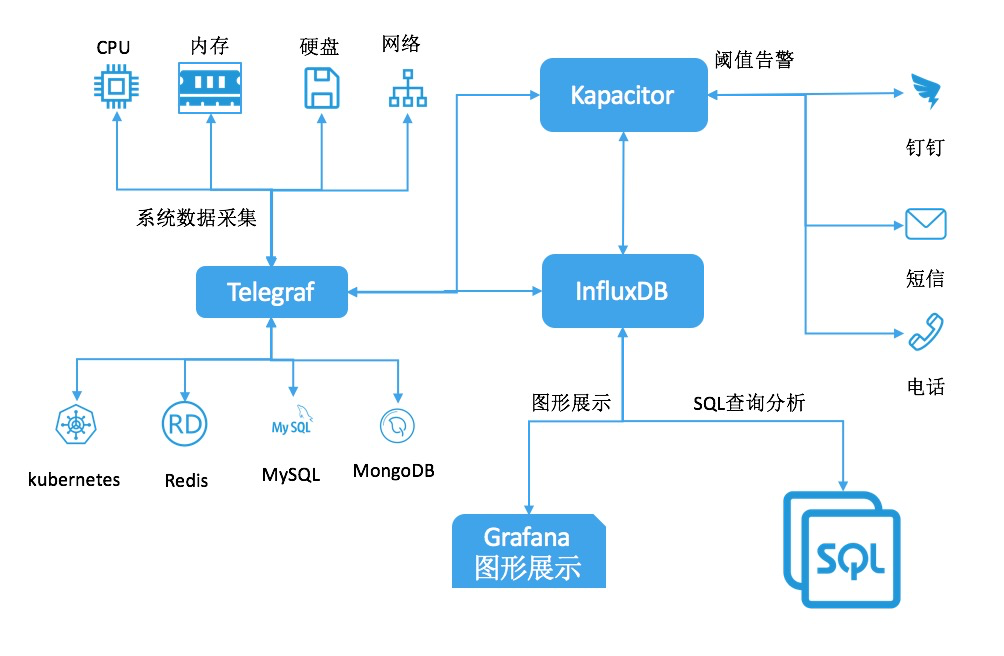
阿里云influxDB不但提供高可用、集群方案,更加稳定性的服务以及拥抱开源生态,也积极集成数据采集,可视化以及告警等功能,同时提供全自动监控,全托管“无运维”的服务。
Prometheus是K8S开源监控报警系统和时序列数据库,阿里云也提供Prometheus服务。相对于开源Prometheus,阿里云Prometheus有以下特性:
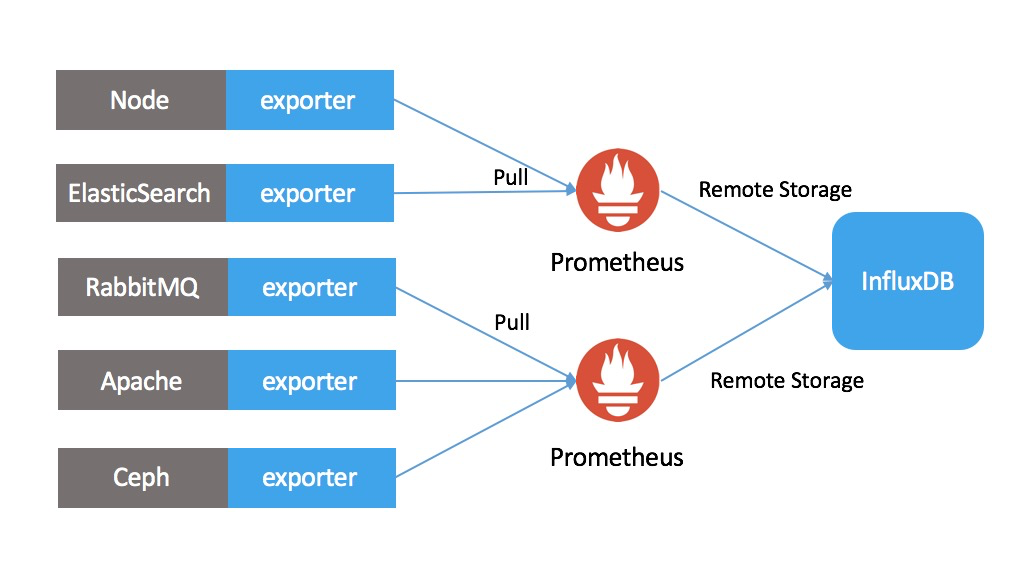
原生态对接Prometheus
- 无缝对接InfluxDB
- 无需代码修改、仅需修改配置
长期数据存储
- InfluxDB通过Remote Storage长期存储Prometheus数据
- InfluxDB远程存储可以实现“多写一读”的查询模式,多个prometheus对接同一个influxDB,允许联合查询多个Prometheus,实现数据“全局化”查询
高可用与高可靠
- InfluxDB高可用为Prometheus提供高可用存储功能
- InfluxDB使用的云盘实现Prometheus数据高可靠,有效防止数据丢失
阿里云Prometheus充分使用阿里云InfluxDB的能力,增强阿里云Prometheus的能力,实现数据的长期存储,高可用,高可靠,同时实现数据的“全局化”查询。
总结
阿里云时序时空数据库TSDB系列产品,聚焦于物联网、监控APM、交通出行、车联网、物流等行业,致力于打造云边一体化的时序时空数据库,欢迎各位开发者和企业客户使用,给我们提出宝贵意见。
相关资源
- 阿里云TSDB 控制台:https://common-buy.aliyun.com/?commodityCode=hitsdbpre#/buy
- 产品使用文档:https://help.aliyun.com/product/54825.html?spm=a2c4g.11186623.6.540.d264305f22n7Kk
本文作者: 自修
本文为云栖社区原创内容,未经允许不得转载。
打造“云边一体化”,时序时空数据库TSDB技术原理深度解密的更多相关文章
- 云栖深度干货 | 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——<TSDB云边一体化时序时空数据库技术揭秘> 自修 —— 阿里云智能数据库产品事业部高级专家 认识TSDB 第一代时序时 ...
- 什么是时序时空数据库TSDB
时序时空数据库(Time Series & Spatial Temporal Database,简称 TSDB)是一种高性能.低成本.稳定可靠的在线时序时空数据库服务,提供高效读写.高压缩比存 ...
- 零距离接触阿里云时序时空数据库TSDB
概述 最近,Amazon新推出了完全托管的时间序列数据库Timestream,可见,各大厂商对未来时间序列数据库的重视与日俱增.阿里云TSDB是阿里巴巴集团数据库事业部研发的一款高性能分布式时序时空数 ...
- 【沙龙报名中】集结腾讯技术专家,共探AI技术原理与实践
| 导语 9月7日,上海市长宁区Hello coffee,云+社区邀您参加<AI技术原理与实践>沙龙活动,聚焦人工智能技术在各产业领域的应用落地,共话AI技术带来的机遇与挑战,展望未来. ...
- 融云技术分享:解密融云IM产品的聊天消息ID生成策略
本文来自融云技术团队原创分享,原文发布于“融云全球互联网通信云”公众号,原题<如何实现分布式场景下唯一 ID 生成?>,即时通讯网收录时有部分改动. 1.引言 对于IM应用来说,消息ID( ...
- 百度云加速时使用Cloudflare的技术
百度云加速时使用Cloudflare的技术 引用“百度的关于我们”这是在打脸吗?就是把英文翻译过来换个验证码 百度是全球最大的中文搜索引擎.最大的中文网站.2000年1月创立于北京中关村.如今,百度已 ...
- 10月15日 | 云栖大会“淘宝移动技术实践&开放论坛”来了!
参会报名链接:http://baichuan.taobao.com/marketing/yunqi#?baichuan_channel=cnblogs 顺应移动互联网消费升级趋势, 淘宝作为移动领域的 ...
- 阿里云PolarDB及其共享存储PolarFS技术实现分析(下)
上篇介绍了PolarDB数据库及其后端共享存储PolarFS系统的基本架构和组成模块,是最基础的部分.本篇重点分析PolarFS的数据IO流程,元数据更新流程,以及PolarDB数据库节点如何适配Po ...
- 微信小程序云开发-从0打造云音乐全栈小程序
第1章 首门小程序“云开发”课程,你值得学习本章主要介绍什么是小程序云开发以及学习云开发的重要性,并介绍项目的整体架构,真机演示项目功能,详细介绍整体课程安排.课程适用人群以及需要掌握的前置知识.通过 ...
随机推荐
- string参考
#include <iostream> #include <string.h> class string { private: char *data; public: stri ...
- 在三台服务器,搭建redis三主三从集群
一.资源准备 1.准备三台服务器H1.H2.H3 172.26.237.83 H1 172.26.237.84 H2 172.26.237.85 H3 二.配置服务器 1.在H1服务器设置SSH免密登 ...
- lombok 注解简单介绍
一.Lombok 的简单介绍和使用 Lombok是一个可以帮助我们简化 Java 代码编写的工具类,通过采用注解的方式简化了 JavaBean 的编写,使我们写的类更加简洁. 1. 添加 Lombok ...
- spring事件监听(eventListener)
原理:观察者模式 spring的事件监听有三个部分组成,事件(ApplicationEvent).监听器(ApplicationListener)和事件发布操作. 事件 事件类需要继承Applicat ...
- PHP ftp_close() 函数
定义和用法 ftp_close() 函数关闭 FTP 连接. 语法 ftp_close(ftp_connection) 参数 描述 ftp_connection 必需.规定要关闭的 FTP 连接. 实 ...
- 区间dp+预处理——cf1278F(难题)
感觉很难的区间dp,主要是状态难想 /* 对于一个区间[i,j],设其最小的颜色编号是c=Min[i,j],那么该区间显然有一大段是以c为底的 设这个颜色在该区间出现位置的两端是L[c],R[c],那 ...
- CF 1076E Vasya and a Tree(线段树+树剖)
传送门 解题思路 首先按照每个修改时\(x\)的深度\(+d\)从大到小排序,然后按照深度分层,一层一层的修改,修改的时候就直接暴力修改子树,然后每做完一层把答案都取下来,因为以后的所有修改的深度都小 ...
- Makefile中的函数
Makefile 中的函数 Makefile 中自带了一些函数, 利用这些函数可以简化 Makefile 的编写. 函数调用语法如下: $(<function> <arguments ...
- SQL比较时间查询语句
select * from table1 where datediff(mm,'2009-8-12 13:17:50', date)>0 select * from table1 select ...
- 内存Zone中的pageset成员分析
1: struct per_cpu_pageset __percpu *pageset; 首先,分析一个函数,__free_pages,这个函数是Buddy System提供的API接口函数,用于翻译 ...