spark自定义分区器实现
在spark中,框架默认使用的事hashPartitioner分区器进行对rdd分区,但是实际生产中,往往使用spark自带的分区器会产生数据倾斜等原因,这个时候就需要我们自定义分区,按照我们指定的字段进行分区。具体的流程步骤如下:
1、创建一个自定义的分区类,并继承Partitioner,注意这个partitioner是spark的partitioner
2、重写partitioner中的方法
override def numPartitions: Int = ???
override def getPartition(key: Any): Int = ??? 代码实现:
测试数据集:
cookieid,createtime,pv
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
指定按照第一个字段进行分区
步骤1:
package _core.sourceCodeLearning.partitioner import org.apache.spark.Partitioner
import scala.collection.mutable.HashMap /**
* Author Mr. Guo
* Create 2019/6/23 - 12:19
*/
class UDFPartitioner(args: Array[String]) extends Partitioner { private val partitionMap: HashMap[String, Int] = new HashMap[String, Int]()
var parId = 0
for (arg <- args) {
if (!partitionMap.contains(arg)) {
partitionMap(arg) = parId
parId += 1
}
} override def numPartitions: Int = partitionMap.valuesIterator.length override def getPartition(key: Any): Int = {
val keys: String = key.asInstanceOf[String]
val sub = keys
partitionMap(sub)
}
}
步骤2:
主类测试:
package _core.sourceCodeLearning.partitioner
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.sql.SparkSession
/**
* Author Mr. Guo
* Create 2019/6/23 - 12:21
*/
object UDFPartitionerMain {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val ssc = SparkSession
.builder()
.config(conf)
.getOrCreate()
val sc = ssc.sparkContext
sc.setLogLevel("WARN")
val rdd = ssc.sparkContext.textFile("file:///E:\\TestFile\\analyfuncdata.txt")
val transform = rdd.filter(_.split(",").length == 3).map(x => {
val arr = x.split(",")
(arr(0), (arr(1), arr(2)))
})
val keys: Array[String] = transform.map(_._1).collect()
val partiion = transform.partitionBy(new UDFPartitioner(keys))
partiion.foreachPartition(iter => {
println(s"**********分区号:${TaskContext.getPartitionId()}***************")
iter.foreach(r => {
println(s"分区:${TaskContext.getPartitionId()}###" + r._1 + "\t" + r._2 + "::" + r._2._1)
})
})
ssc.stop()
}
}
运行结果:
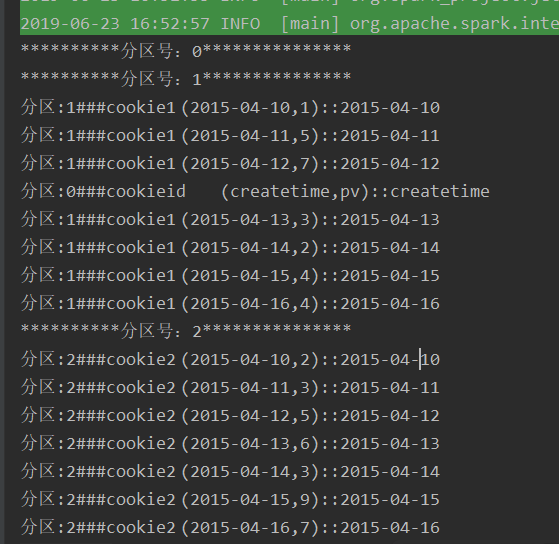
这样就是按照第一个字段进行了分区,当然在分区器的中,对于key是可以根据自己的需求随意的处理,比如添加随机数等等
spark自定义分区器实现的更多相关文章
- Spark自定义分区(Partitioner)
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略,这两种分区策略在很多情况下都适合我们的场景.但是有些情况下,Spark内部不能符合咱们的需求 ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- kafka 自定义分区器
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.a ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- RDD(六)——分区器
RDD的分区器 Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数.RDD中每条数据经过Shuffle过 ...
- 聊聊Spark的分区、并行度 —— 前奏篇
通过之前的文章[Spark RDD详解],大家应该了解到Spark会通过DAG将一个Spark job中用到的所有RDD划分为不同的stage,每个stage内部都会有很多子任务处理数据,而每个sta ...
- 玩转Kafka的生产者——分区器与多线程
上篇文章学习kafka的基本安装和基础概念,本文主要是学习kafka的常用API.其中包括生产者和消费者, 多线程生产者,多线程消费者,自定义分区等,当然还包括一些避坑指南. 首发于个人网站:链接地址 ...
- kafka producer partitions分区器(七)
消息在经过拦截器.序列化后,就需要确定它发往哪个分区,如果在ProducerRecord中指定了partition字段,那么就不再需要partitioner分区器进行分区了,如果没有指定,那么会根据k ...
- Kafka的接口回调 +自定义分区、拦截器
一.接口回调+自定义分区 1.接口回调:在使用消费者的send方法时添加Callback回调 producer.send(new ProducerRecord<String, String> ...
随机推荐
- spring3+structs2整合hibernate4时报org.springframework.beans.factory.BeanCreationException: Could not autowire method: public void sy.dao.impl.UserDaoImpl.setSessionFactory(org.hibernate.SessionFactory);
今天在spring3+structs2整合hibernate4时报如下错误,一直找不到原因: org.springframework.beans.factory.BeanCreationExcepti ...
- 使用androidstudio时遇到的一些小错误
1 路径名字中不能有汉字 报如下错误:Error:(1, 0) Your project path contains non-ASCII characters. This will most lik ...
- Samba服务的安装
Samba的安装 1.准备环境 Centos7 [root@localhost ~]# systemctl stop firewalld [root@localhost ~]# setenforce ...
- netstat 指令
netstat 指令将所有的网络端口监听情况进行罗列 语法 netstat -tuln 几个常见的服务端口 例 通过grep 查看端口来获得上面的服务是否开启,并给予提示 1 #!/bin/bas ...
- Centos6安装破解JIRA7.3.8
jira是Atlassian公司出品的项目与事务跟踪工具,被广泛应用于缺陷跟踪(bug管理).客户服务.需求收集.流程审批.任务跟踪.项目跟踪和敏捷管理等工作领域. 好了言归正传: 安装jira之前我 ...
- NDK笔记(二)-在Android Studio中使用ndk-build(转)
前面一篇我们接触了CMake,这一篇写写关于ndk-build的使用过程.刚刚用到,想到哪儿写哪儿. 环境背景 Android开发IDE版本:AndroidStudio 2.2以上版本(目前已经升级到 ...
- 使用 @Log4j2 log.error() 打印异常日志
public static void main(String[] args) { int a = 10; try { int i = 1/0; } catch (Exception e) { Syst ...
- 合并vector里的内容,输出一个string
string merge_vector(vector<string> dp_scpe_all) { //合并vector里的内容 string new_dp_scpe; ; m < ...
- (转)OpenFire源码学习之二:Mina基础知识
转:http://blog.csdn.net/huwenfeng_2011/article/details/43413009 Mina概述 Apache MINA(Multipurpose Infra ...
- MFC的回调函数
MFC中应该有两类回调函数:一类是源自C的传统回调函数,此类回调函数若非定义为全局函数,而定义在类中的话,要添加static约束,常见的有EnumXXX():一类是消息响应函数,通过成员函数指针实 ...