【转】AUC(Area Under roc Curve )计算及其与ROC的关系
让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准。这样的标准其实有很多,例如:大约10年前在machine learning文献中一统天下的标准:分类精度;在信息检索(IR)领域中常用的recall和precision,等等。其实,度量反应了人们对” 好”的分类结果的追求,同一时期的不同的度量反映了人们对什么是”好”这个最根本问题的不同认识,而不同时期流行的度量则反映了人们认识事物的深度的变 化。近年来,随着machine learning的相关技术从实验室走向实际应用,一些实际的问题对度量标准提出了新的需求。特别的,现实中样本在不同类别上的不均衡分布(class distribution imbalance problem)。使得accuracy这样的传统的度量标准不能恰当的反应分类器的performance。举个例子:测试样本中有A类样本90个,B 类样本10个。分类器C1把所有的测试样本都分成了A类,分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。则C1的分类精度为 90%,C2的分类精度为75%。但是,显然C2更有用些。另外,在一些分类问题中犯不同的错误代价是不同的(cost sensitive learning)。这样,默认0.5为分类阈值的传统做法也显得不恰当了。
为了解决上述问题,人们从医疗分析领域引入了一种新的分类模型performance评判方法——ROC分析。ROC分析本身就是一个很丰富的内容,有兴趣的读者可以自行Google。由于我自己对ROC分析的内容了解还不深刻,所以这里只做些简单的概念性的介绍。
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。因为(0, 0)和(1, 1)连线形成的ROC曲线实际上代表的是一个随机分类器。如果很不幸,你得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。虽然,用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。好了,到此为止,所有的 前续介绍部分结束,下面进入本篇帖子的主题:AUC的计算方法总结。
一、假正例和假负例
分类器的正确率和召回率
前几天在无觅上看到有人分享了一篇 数据不平衡时分类器性能评价之ROC曲线分析, 把这个问题已经讲差不多了, 我这复述一下.
先说混淆矩阵 (confusion matrix). 混淆矩阵是评估分类器可信度的一个基本工具, 设实际的所有正样本为 P (real-Positive), 负样本为 N (real-Negative), 分类器分到的正样本标为 pre-Positive', 负样本标为 pre-Negetive', 则可以用下面的混淆矩阵表示所有情况:
| real-positive | real-negative
pre-positive' | TP (true positive) | FP (false positive)
pre-negative' | FN (false negative) | TN (true negative)
通过这个矩阵, 可以得到很多评估指标:
FP rate = FP / N
TP rate = TP / P
Accuracy = (TP + TN) / (P + N) # 一般称之为准确性或正确性
Precision = TP / (TP + FP) # 另一些领域的准确性或正确性, 经常需要看上下文来判断
Recall = TP / P # 一般称之为召回率
F-score = Precision * Recall
假正例(False Positive):预测为1,实际为0的样本
假负例(False Negative):预测为0,实际为1的样本
实际预测中,那些真正例(True Positive)和真负例(True Negative)都不会造成损失(cost)。
那么,我们假设一个假正例的损失是LFP,一个假负例的损失是LFN。
我们可以得到一个损失矩阵:
| y^=1 | y^=0 | |
| y=1 | 0 | LFN |
| y=0 | LFP | 0 |
其中,y是真实值,y^是预测值。
那么,我们可以得到一个样本的后验期望损失:
 这里 p(y=1|x)是x为正样本的概率 * x被误判为负样本的概率 也就是 样本的期望损失。
这里 p(y=1|x)是x为正样本的概率 * x被误判为负样本的概率 也就是 样本的期望损失。
 同理可得 ,
同理可得 ,
当 的时候,我们会预测结果为y^1=1,此时 (当正样本被误判为负样本的概率大于负样本被误判为正样本的概率时),也就是预测结果中大部分为负样本,
的时候,我们会预测结果为y^1=1,此时 (当正样本被误判为负样本的概率大于负样本被误判为正样本的概率时),也就是预测结果中大部分为负样本,

假设, ,那么我们可以得到决策规则:
,那么我们可以得到决策规则:

其中, ,也就是我们的决策边界。
,也就是我们的决策边界。
例如,c=1时,我们对假正例和假负例同等对待,则可以得到我们的决策边界0.5。
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。
真阳性率=真阳性人数÷标准阳性人数,即: 真阳性率=a÷(a+c)
假阳性率=假阳性人数÷标准阴性人数,即: 假阳性率=b÷(b+d)
|
标准
|
合计
|
|||
|
阳性(+)
|
阴性(-)
|
|||
|
某筛检
方法
|
阳性(+)
|
a
|
b
|
a+b
|
|
阴性(-)
|
c
|
d
|
c+d
|
|
|
合 计
|
a+c
|
b+d
|
N
|
|
(b:筛选为阳性,而标准分类为阴性的例数;d:阴性一致例数)
最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test是等价的。这个等价关系的证明留在下篇帖子中给出。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这 和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去正类样本的score为最 小的那M个值的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
AUC=((所有的正例位置相加)-M*(M+1))/(M*N)
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
---------------------------------------------------------------华丽的分割线(还是这篇博文写的明白)---------------------------------------------------------------------
大家在将统计学习方法用于实际应用时,不免会遇到各类间数据不太平衡的情况。比如垃圾邮件的识别、稀有病情的诊断、诈骗电话识别、情感分析等等情况。导致数据不平衡的原因有很多,有可能是因为不恰当的采样方法,也可能真实的数据分布就是如此;然而真实的数据分布在大多数情况下我们是无从得知的,于是我们只好认为我们所取得的样本是“真实”的,再从中进行学习。那么针对数据不平衡有很多研究点,最近稍微调研了一下,这也算是一个比较老的Topic了。2000 AAAI/2003 ICML先后有两次Workshop对此进行讨论,之后似乎研究的人就比较少了。
本文主要关注的是在类间数据不平衡的情况下,如何评价分类器的性能?至于这个问题本身的更详细分析,只要在google scholar中搜索“Learning from Imbalance data”就会看一堆资料了,我也看了一些,但是不细致,最近实在是很忙。
在AAAI(2000) Workshop上,有两个问题最受关注。
1:在类不平衡(class imbalances)的情况下,如何评价学习算法的性能?
2:类不平衡与代价敏感学习(cost-sensitive Learning)的关系。
今天稍微研究了一下第一个问题。既然要评价,那么也就默认了一个前提假设:类样本不平衡是符合实际数据分布的(训练集和测试集同分布)。要评价一个二元分类器的性能,人们自然而然地想到Accuracy。而对于不平衡数据,这是否合适?看一个简单的例子:假设这个世界上有99.9%的人不患癌症,0.01%的人身患癌症。于是我们想设计一个分类器,来判断一个病人是否身患癌症。那么在已有先验知识的情况下,我只需要认为所有病人都不患癌症,那么分类器至少能达到99.9%的分类准确率。显然,这个分类器一点儿价值也没有。同理,对于n:1(n比较大)的类样本分布,只需要认为所有样本都属于n那一类,准确率就可以达到非常高,可是没有任何意义和参考价值。所以,Accuracy的衡量标准在这里是不合适的。
ROC分析为这个问题提供了一个比Accuracy更为准确的度量方式:)
先简单看一下混淆矩阵(confusion matrix)。混淆矩阵是评估分类器可信度的一个基本工具。以二元分类器为研究对象,下面的混淆矩阵显示了一个分类器可能遇到的所有情况:
| positive | negative | |
| positive’ | TP (true positive) | FP (false positive) |
| negative’ | FN (false negative) | TN (true negative) |
其中列对应于样本实际的类别,行对应于样本被预测的类别。这四个基本指标可以衍生出多个分类器指标:
1:FP rate = FP / N;N为负样本数
2:TP rate = TP / P;P为正样本数
3:Accuracy = (TP + TN) / (P + N);//我们一般用的
4:Precision = TP / (TP + FP)
5:Recall = TP / P
6:F-score = Precision * Recall
其中Accuracy是我们最经常使用的,在某些领域,Precision/Recall也很频繁。
以上这些都属于静态的评价指标,如前所述,当正负样本不平衡时存在严重的问题。
于是,ROC曲线和AUC(曲线包围面积)应运而生。
ROC曲线描述的是混淆矩阵中FPR(FP rate)和TPR两个量之间的相对变化关系。如果二元分类器给出的是对正样本的一个分类概率,那么通过设定不同的阈值,可以得到不同的混淆矩阵,而每个混淆矩阵都对应于ROC曲线上的一个点。将这些点描绘出来可以得到一条平滑的曲线,这时,我们可以用曲线所包围的面积,即AUC,来评估该二元分类器的可信度。这就是ROC分析,说完啦。看一幅来自Wikipedia的图:
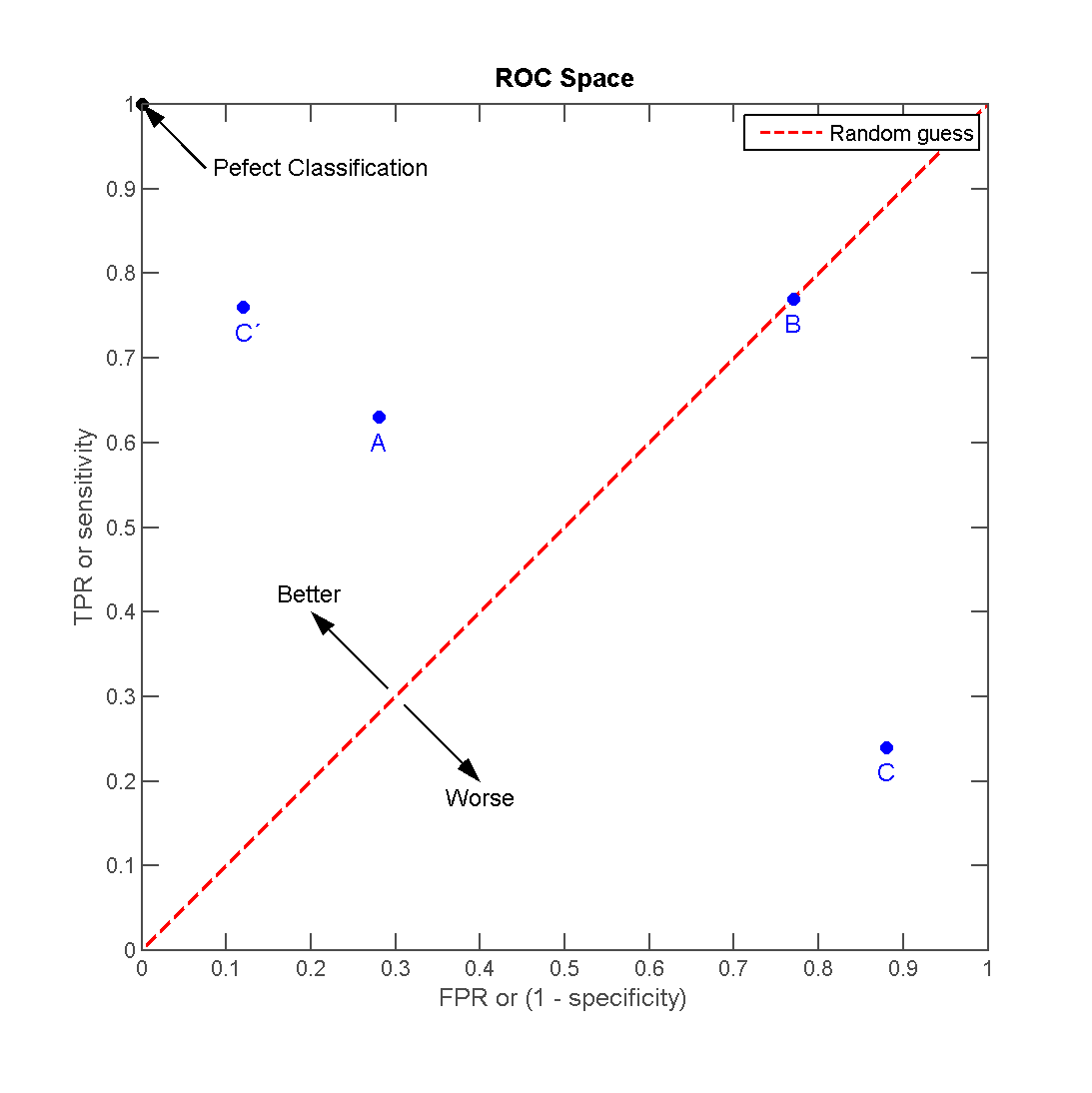
横轴为FPR,纵轴为TPR。如果混淆矩阵表示的点(FPR,TPR)处在中间那根红线上,则表示该分类器没有区分能力。以前面的n:1为例,如果分类器简单地把所有样本分至n这一类,则正好处在右上角,即(1, 1)。再试想一下数据平衡1:1的情况,当分类器处于红线上时,容易计算出Accuracy为50%,对于二元分类器而言,没有什么比准确率低于50%更丢人的事情了……
所以,点若处在左上角部分,则说明分类器性能不错,若不幸在右下角,那么这个分类器无疑是一坨。。
我们根据不同的阈值得到了ROC曲线之后:
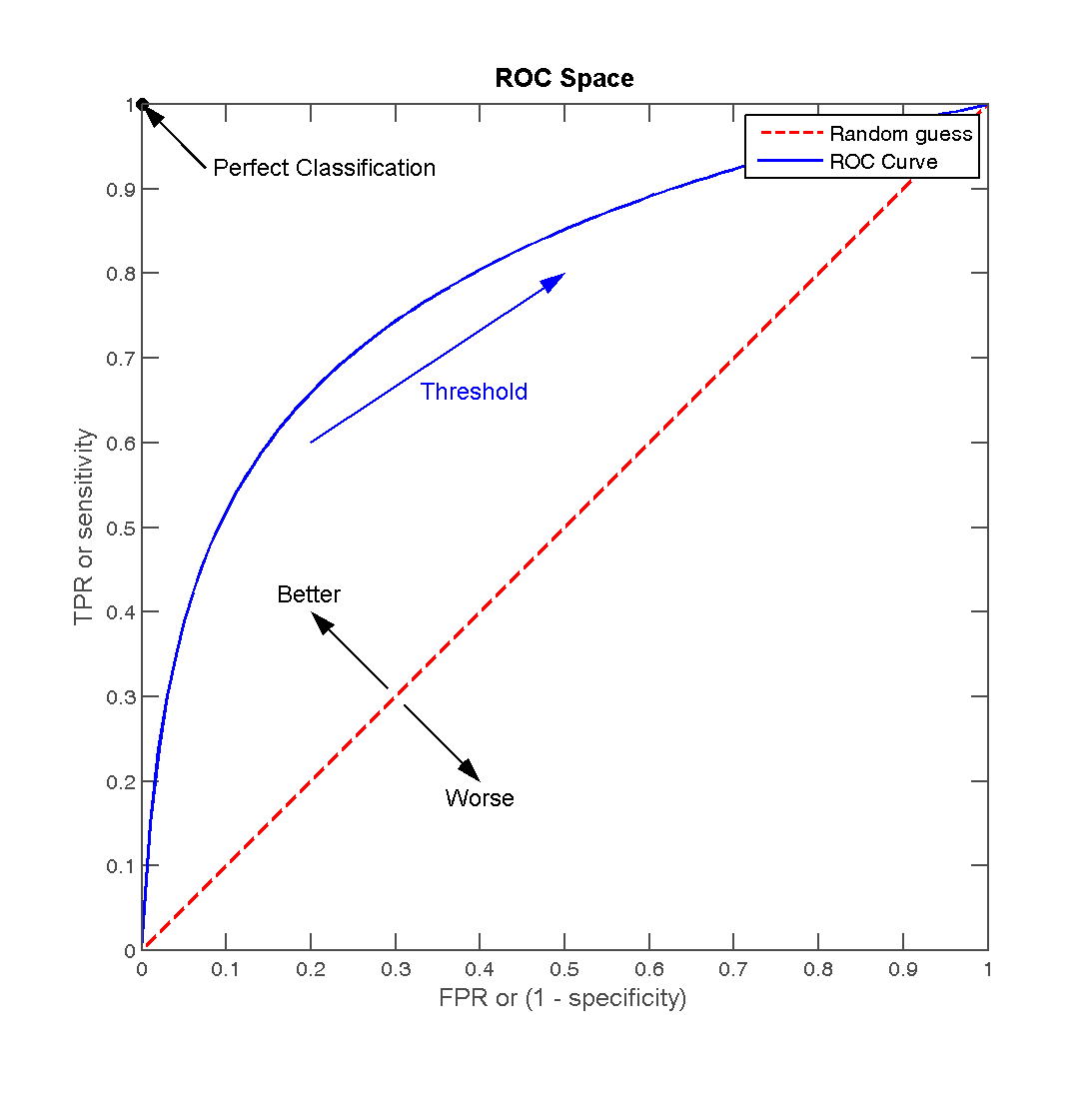
可以通过计算该曲线所包围的面积(AUC)来衡量分类器的可信度。面积越大,则可信度越高。不过面积可不好计算,因为我们得到的都是离散点。对此有兴趣的话,可以参考下这篇文章(ICML 2006)
The Relationship Between Precision-Recall and ROC Curves
这篇文章附着一个计算AUC的Java工具包:http://mark.goadrich.com/programs/AUC/
一般认为,对于一个诊断实验,AUC在0.5~0.7之间时,诊断价值较低;在0.7~0.9之间,诊断价值中等;在0.9以上时诊断价值较高。这是医学诊断上的经验了,对于其他领域的分类器如何,还需要在实践中摸索。
【转】AUC(Area Under roc Curve )计算及其与ROC的关系的更多相关文章
- AUC(Area Under roc Curve )计算及其与ROC的关系
转载: http://blog.csdn.net/chjjunking/article/details/5933105 让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准.这样的标准其实有 ...
- Area Under roc Curve(AUC)
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- AUC(Area Under roc Curve)学习笔记
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- 机器学习-TensorFlow应用之classification和ROC curve
概述 前面几节讲的是linear regression的内容,这里咱们再讲一个非常常用的一种模型那就是classification,classification顾名思义就是分类的意思,在实际的情况是非 ...
- ROCR包中ROC曲线计算是取大于cutoff还是大于等于cutoff
找到对应的代码如下 .compute.unnormalized.roc.curve function (predictions, labels) { pos.label <- levels(la ...
- hadoop计算二度人脉关系推荐好友
https://www.jianshu.com/p/8707cd015ba1 问题描述: 以下是qq好友关系,进行好友推荐,比如:老王和二狗是好友 , 二狗和春子以及花朵是好友,那么老王和花朵 或者老 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- 为什么CTR预估使用AUC来评估模型?
ctr预估简单的解释就是预测用户的点击item的概率.为什么一个回归的问题需要使用分类的方法来评估,这真是一个好问题,尝试从下面几个关键问题去回答. 1.ctr预估是特殊的回归问题 ctr预估的目标函 ...
随机推荐
- POJ 1679The Unique MST
Description Given a connected undirected graph, tell if its minimum spanning tree is unique. Definit ...
- php中括号定义数组
php5.3及之前的版本是不支持中括号定义数组的.5.4之后支持. 错误信息是,不识别“[”
- 在linux里如何建立一个快捷方式,连接到另一个目录
用软链接 用法:ln -s 源目录 目标快捷方式, 比如你要在/etc下面建立一个叫LXBC553的快捷方式,指向/home/LXBC,那就是 ln -s /home/LXBC /etc/LXBC ...
- Python学习之路4☞条件和循环
一.if语句 1.1 功能 计算机又被称作电脑,意指计算机可以像人脑一样,根据周围环境条件(即expession)的变化做出不同的反应(即执行代码) if语句就是来控制计算机实现这一功能 1.2 语法 ...
- hdu5131 贪心
#include<stdio.h> #include<string.h> #include<algorithm> #include<string> #i ...
- DRP 2016-06-30 16:36 314人阅读 评论(21) 收藏
学习drp有一段时间了,其实从很久以前,再提高班的学习就已经不是单纯的学习,学习总是伴随着项目.这就使得我们的学习不可能全天的,大把大把时间的学习只出现在第一和第二年,所以,各自珍惜吧. DRP(Di ...
- MaxCompute 项目子账号做权限管理
场景: 一个企业使用多款阿里云产品,MaxCompute是其中一个产品,用的是同个主账号,主账号不是由使用MaxCompute的大数据同学管理, 大数据同学使用的是子账号.大数据同学日常需要给Max ...
- axios细节之绑定到原型和axios的defaults的配置属性
把axios绑定到原型 vue开发者一套很好用的实践,一般来说,实践如果能够让大部分人都接受,会逐渐成为一个默认的标准. // 把axios配置到原型上 Vue.prototype.$axios = ...
- ADO.NET_02
一.说明 这个例子是小白跟着学习代码记录,模拟用户登陆功能,并可以查询所有学生信息. 二.代码 共4个文件,如下 App.config <?xml version="1.0" ...
- 关于使用JavaMail发送邮件抛出java.lang.NoSuchMethodError: com.sun.mail.util.TraceInputStream.<init>(Ljava异常的解决方法
我们在使用JavaMail时有可能会如下异常: Exception in thread "main" java.lang.NoSuchMethodError: com.sun.ma ...