Callable,阻塞队列,线程池问题
一.说说Java创建多线程的方法
1. 通过继承Thread类实现run方法
2. 通过实现Runnable接口
3. 通过实现Callable接口
4. 通过线程池获取
二. 可以写一个Callable的案例吗?如何调用Callable接口
/*是一个带返回值的多线程类,如果需要有线程返回的结果,就需要使用此类*/
class MyThread implements Callable<Integer> { @Override
public Integer call() {
return 1000;
}
}
public static void main(String[] args) throws Exception{
/*Thread 构造方法传入 Runnable , FutureTask 构造方法传入 Callable ,
FutureTask 继承于 RunnableFuture 继承于 Runnable
所以 Thread通过传入FutureTask即Runnable的实现类来启动Callable线程,
透传思想,传接口,不传具体的实现类,可以保证灵活性,(适配器模式)
*/
FutureTask<Integer> ft = new FutureTask(new MyThread());// 一个是main线程,一个是t1线程
new Thread(ft,"t1").start();
int res1 = 1000;
// 获取t1线程中的返回值,建议放在最后
// 如果没有计算完成就取值,会导致整个程序阻塞,直到t1执行完成
int res2 = ft.get();
//自旋锁,如果t1线程没有计算完成,就等待
while (!ft.isDone()){
}
System.out.println(Thread.currentThread().getName() + "\t"+(res1+res2));
}
三. 请你谈谈对阻塞队列的理解,为什么要是用阻塞队列,它有哪些具体的实现,各有什么特点?
在多线程的环境下,所谓阻塞,在某些情况下会挂起线程,一旦条件满足,被挂起的线程又被唤醒.我们不需要关心
什么时候需要阻塞线程,什么时候需要唤醒线程,一切都有BlockingQueue自动调度实现
它有7个实现类
* 1.ArrayBlockingQueue 由数组构成的有序阻塞队列
* 2.LinkedBlockingQueue 由链表构成的有序阻塞队列
* 3.PriorityBlockingQueue 支持优先级排序的无界阻塞队列
* 4.DelayQueue 使用优先级队列的延迟无阻塞队列
* 5.SynchronousQueue 不存储元素的阻塞队列,也即单元素队列
* 6.LinkedTransferQueue 由链表组成的无界阻塞队列
* 7.LinkedBlockingQueue 由链表构成的双向阻塞队列
1,2,5用的最多
BlockingQueue的使用方法
1.会抛出异常
public static void show01(int n){
/*队列中的数据错误,会抛出异常*/
/*add 队列满了,再继续插入会抛出java.lang.IllegalStateException: Queue full异常*/
/*remove 从队列中移除一个元素,并返回该元素,如果队列为空,就抛出java.util.NoSuchElementException异常*/
/*element 返回队列的首个元素,如果队列为空,抛出java.util.NoSuchElementException异常*/
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(n);
System.out.println(blockingQueue.add("a"));
System.out.println(blockingQueue.add("b"));
System.out.println(blockingQueue.add("c"));
// System.out.println(blockingQueue.add("x"));
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
//System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.element());//
}
2.不会抛出异常
public static void show02(int n){
/*队列数据错误,不会抛出异常*/
/*offer 添加元素,如果队列满了,再继续插入元素,会返回false*/
/*poll 获取元素,如果队列为空,再继续获取元素,会返回null*/
/*peek 获取队列的首元素,如果队列为空,返回null*/
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(n);
System.out.println(blockingQueue.offer("a"));
System.out.println(blockingQueue.offer("b"));
System.out.println(blockingQueue.offer("c"));
// System.out.println(blockingQueue.offer("x"));
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.peek());
}
3.队列阻塞
public static void show03(int n){
/*队列数据异常,不会抛出异常,没有返回值*/
/*put 如果队列已满,在插入元素,队列会阻塞*/
/*take 如果队列为空,在获取元素,队列会阻塞*/
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(n);
try {
blockingQueue.put("a");
blockingQueue.put("b");
blockingQueue.put("c");
// blockingQueue.put("x");
System.out.println("-------------------");
blockingQueue.take();
blockingQueue.take();
blockingQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
4.队列超时 (实际用的较多)
public static void show04(int n){
/*队列数据异常,不会抛出异常,返回true/false值*/
/*offer 传入值,等待时间,等待单位,往队列中存放元素,当队列中的元素已满,继续等待,如果超过给定时间,那么就会丢弃元素*/
/*poll 等待时间,等待单位,从队列中获取元素,当队列中的元素为空,继续等待,如果超过给定时间,那么就不会获取*/
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(n);
try {
System.out.println(blockingQueue.offer("a", 2L, TimeUnit.SECONDS));
System.out.println(blockingQueue.offer("b", 2L, TimeUnit.SECONDS));
System.out.println(blockingQueue.offer("c", 2L, TimeUnit.SECONDS));
System.out.println(blockingQueue.offer("x", 2L, TimeUnit.SECONDS));
blockingQueue.poll(2L,TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
show01(3); // 异常
show02(3); // 没有异常
show03(3); // 阻塞
show04(3); // 超时等待
}
四.请你谈谈对线程池的理解,为什么要使用线程池,如何使用线程池?
介绍:线程池的主要是控制运行的线程的数量,如果处理过程中将任务加入队列,然后在线程创建的时候启动这些任务.如果线程数量超过了最大数量的线程将排队等候,等待其他的线程执行完毕,再从队列中取出任务来执行.
优点:
1.降低资源消耗,通过复用已创建的线程降低线程创建和销毁造成的消耗
2.提高响应速度,当任务达到时,任务可以不需要等待线程创建就可以立刻执行
3.提高线程的可管理性,线程属于稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性
使用线程池可以进行统一的分配,调优和监控
一句话总结:线程复用,控制最大并发数,管理线程
public static void show01(ExecutorService es){
// 创建1个线程池,里面有5个固定的线程
/*1. 创建一个定长的线程池,可控制线程的最大并发数,超出的线程会在队列中等待
* 2. newFixedThreadPool创建的线程池corePoolSize和maxPoolSize的值事相等的,使用的是LinkedBlockingQueue
* */
es = Executors.newFixedThreadPool(5);
try{
// 有10个任务等待被执行
for (int i = 1; i <= 10; i++) {
es.execute(()->{
System.out.println(Thread.currentThread().getName() +"\t 执行任务");
});
}
}catch (Exception e){
e.getStackTrace();
}finally {
es.shutdown();//关闭线程池
}
}
public static void show02(ExecutorService es){
// 创建1个线程池,里面有1个固定的线程
/*
* 1.创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有的任务按照指定的顺序执行
* 2.newSingleThreadExecutor将corePoolSize和maxPoolSize的值都设置为1,使用的是LinkedBlockingQueue
* */
es = Executors.newSingleThreadExecutor();
try{
for (int i = 1; i <= 10; i++) {
es.execute(()->{
System.out.println(Thread.currentThread().getName() +"\t 执行任务");
});
}
}catch (Exception e){
e.getStackTrace();
}finally {
es.shutdown();//关闭线程池
}
}
public static void show03(ExecutorService es){
// 创建1个线程池,里面无固定个线程
/*
* 1.创建一个可缓存的线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则创建新线程
* 2.newCachedThreadPool将corePoolSize的值设置为0,maxPoolSize的值设置为Integer.MAX_VALUE,使用
* 的是synchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程
*
* */
es = Executors.newCachedThreadPool();
try{
for (int i = 1; i <= 10; i++) {
es.execute(()->{
System.out.println(Thread.currentThread().getName() +"\t 执行任务");
});
}
}catch (Exception e){
e.getStackTrace();
}finally {
es.shutdown();//关闭线程池
}
}
public static void main(String[] args) {
ExecutorService es = null;
show01(es);
show02(es);
show03(es);
}
五. 请你谈一谈线程池的七大/五大参数分别代表什么意思
int corePoolSize 线程池中常驻核心线程数
* 1.在创建了线程池后,当有请求任务来了之后,就会安排线程池中的线程去执行请求的任务,类似于银行当值的窗口
* 2.当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中
int maximumPoolSize 线程池同时能够容纳同时执行的最大线程数,此值必须大于等于1
long keepAliveTime 多余的空闲线程的存活时间
* 当前线程池数量超过corePoolSize时,空闲时间达到keepAliveTime值时,多余线程会被销毁直到只剩下corePoolSize个线程为止
* 默认情况下,只有当线程池中的线程数大于corePoolSize时候keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize
*
TimeUnit unit keepAliveTime的单位
BlockingQueue<Runnable> workQueue 任务队列,被提交但尚未被执行的任务
ThreadFactory threadFactory 表示生成线程池中工作线程的线程工厂,用于创建线程,一般用默认的值即可
RejectedExecutionHandler handler 拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数(maximumPoolSize)如何来拒绝请求执行的Runnable策略
六.请你谈一谈线程池的底层工作原理
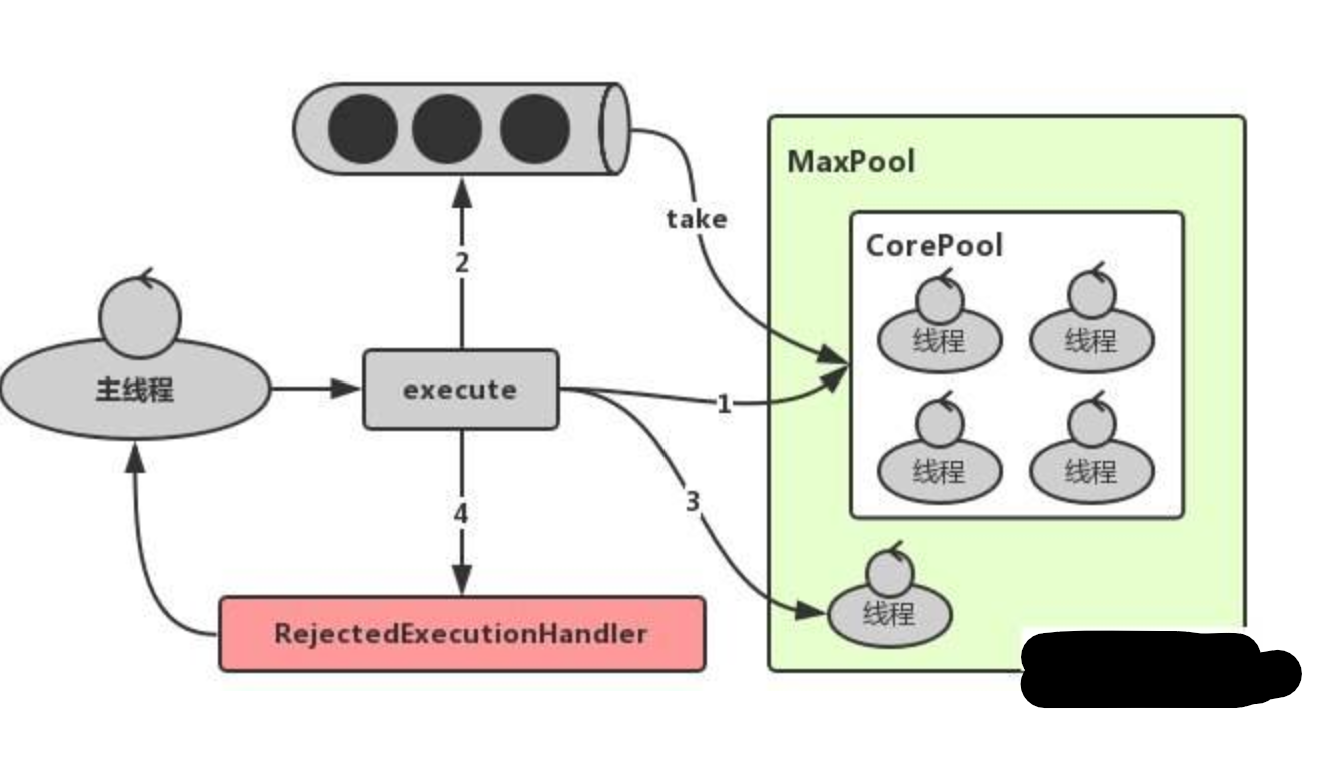
1.在创建了线程池后,等待提交过来的任务请求
2.当调用execute方法添加一个任务请求时,线程池会做出如下判断:
2.1 如果正在运行的线程数量小于corePoolSize,那么会马上创建这个线程并执行这个任务
2.2 如果此时正在运行的线程数量大于或等于corePoolSize,那么会将这个这个任务放进阻塞队列中等待
2.3 如果此时阻塞队列满了且正在运行的线程数量小于maximumPoolSize,那么会创建非核心线程来立即执行这些任务
2.4 如果此时阻塞队列满了且正在运行的线程数大于或等于maximumPoolSize.那么线程池会启用饱和拒绝策略来拒绝新的请求
3.当一个线程完成任务时,会从阻塞队列中取出下一个任务来执行
4.此时当一个线程空闲并超过一定的时间keepAliveTime,此时线程池会判断,如果当前运行的线程数量大于corePoolSize,那么这些线程将会被终止.
所以线程池的所有任务完成后,最终会收缩到corePoolSize的大小.
举列子:银行办理业务,周六招商银行,一共有5个柜面,只开放了2个柜台办理业务,此时2就代表corePoolSize,5个柜台代表了maximumPoolSize,只有2个员工在干活,
其他的3个柜台都是空闲的当有人来进去办业务,如果来的人少于2人可以立即办理业务,无需等待,当来了5个人办理业务,前面的1,2号没有办完,此时3,4,5号就
会进入候客区等待.也就是线程池中的阻塞队列中等待被执行.如果此时来银行办理业务的任实在太多,来了7,8,9,候客区也满了(BlockingQueue满了),此时银行
行长就会开放剩余的柜台来处理业务(非核心线程打开,此时线程数达到最大值),打电话给另外3个柜员来加班,此时柜台全部开放,也满足不了新的客户需求,那么
最后银行行长就会暂时关闭这个网点(拒绝策略拒绝新的请求),先来办理行内的业务.当解决了一个任务时,就会叫下一个号来办理业务(从阻塞队列中获取待
解决的任务).如果过了一个小时(keepAliveTime保留活跃时间),银行的流量下降了,此时,加班的3个人可以先回去(本来也不该他们上班),银行重新回归到初始状
态.(这么说,小伙伴们懂了吗~)
七. 请你谈一谈线程池的拒绝策略
此时线程池中的阻塞队列已经被塞满,再也放不进新的任务,同时线程数也达到了maximumPoolSize,无法为新的请求服务,此时JDK有4种拒绝策略
1.AbortPolicy(默认) 直接抛出RejectedExecutionException异常阻止系统正常运行
2.CallersRunsPolicy "调用者模式"一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量
3.DiscardOldestPolicy 抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
4.DiscardPolicy 直接丢弃任务,不予处理也不抛出异常.如果允许任务丢失,这是最好的一种方案
那此时可以说下在工作中用了哪一种线程池?(此处有坑)
JDK提供的线程池一律不能说,标准答案: 根据业务的需要,自定义ThreadPoolExectuor来创建线程池.
public static void show04(ExecutorService es){
// 核心线程数为2,最大线程数为5,非核心线程的最大运行时间是1秒
// 阻塞队列中一共有3个等待的任务,使用默认的线程生成策略,同时开启
// 调用者模式的拒绝策略
es = new ThreadPoolExecutor(
2,5,1L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
try{
for (int i = 1; i <= 10; i++) { // 开启10个请求,最大线程数量是8,
es.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t办理业务");
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
es.shutdown();
}
}
运行结果:
AbortPolicy,直接抛出异常

CallersRunsPolicy 不会抛出异常,返回给方法的调用者,也就是main线程
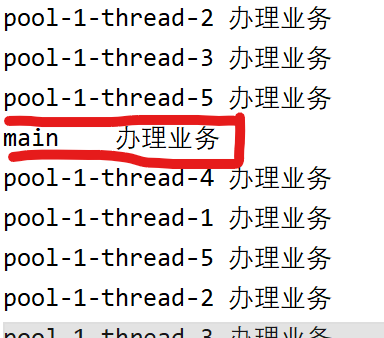
DiscardOldestPolicy 抛弃队列中等待最久的任务

DiscardPolicy 直接抛弃队列中多余的任务,如果业务允许,此拒绝策略效率最高

八. 请你谈一谈,如何在实际的生产业务中确定线程池中参数的配置
此时要根据实际做的系统进行分类
1.CPU密集型
/*指的是该任务需要大量的运算,没有阻塞,CPU一直全速运行,CPU密集任务只有真正的多核心CPU才能得到加速(通过多线程)而在单核CPU上
无论开几个模拟多线程的任务都不可能得到加速,因为CPU的运算能力有限.
1.CPU密集型的任务尽可能少配线程数量
2.公式:线程数 = CPU核心数 + 1个线程的线程池(8核就开启8个线程,12核开启12个线程,尽量减少切换)
3.System.out.println(Runtime.getRuntime().availableProcessors());//查看CPU的核心数*/
2.I/O密集型
/* 1.I/O密集型并不是在一直执行任务,应该配置尽可能多的线程,线程数 = CPU核心数 * 2
2.I/O密集型即该任务需要大量的I/O操作,业务系统中大量的阻塞(从数据库,缓存获取数据,修改数据...)
所以在I/O密集型的场景中,使用多线程可以大大加速程序运行,即使在单核CPU上,这种加速也可以利用了被浪费掉的阻塞时间
因为大部分线程都会阻塞,需要配置大量的线程数
线程数 = CPU核心数 / 1-阻塞系数 阻塞系数在0.8~0.9之间
(例如 8核心CPU 8 / 1 - 0.9 = 80,如果是I/O密集型的操作,需要配置80个线程数)
*/
Callable,阻塞队列,线程池问题的更多相关文章
- 第45天学习打卡(Set 不安全 Map不安全 Callable 常用的辅助类 读写锁 阻塞队列 线程池)
Set不安全 package com.kuang.unsafe; import java.util.*; import java.util.concurrent.CopyOnWriteArray ...
- SpringBoot普通消息队列线程池配置
1 package com.liuhuan.study.config; 2 3 import com.google.common.util.concurrent.ThreadFactoryBuilde ...
- Day037--Python--线程的其他方法,GIL, 线程事件,队列,线程池,协程
1. 线程的一些其他方法 threading.current_thread() # 线程对象 threading.current_thread().getName() # 线程名称 threadi ...
- python 线程(其他方法,队列,线程池,协程 greenlet模块 gevent模块)
1.线程的其他方法 from threading import Thread,current_thread import time import threading def f1(n): time.s ...
- day34 GIL锁 线程队列 线程池
一.Gil锁(Global Interpreter Lock) python全局解释器锁,有了这个锁的存在,python解释器在同一时间内只能让一个进程中的一个线程去执行,这样python的多线程就无 ...
- python并发编程之线程剩余内容(线程队列,线程池)及协程
1. 线程的其他方法 import threading import time from threading import Thread,current_thread def f1(n): time. ...
- Python 线程----线程方法,线程事件,线程队列,线程池,GIL锁,协程,Greenlet
主要内容: 线程的一些其他方法 线程事件 线程队列 线程池 GIL锁 协程 Greenlet Gevent 一. 线程(threading)的一些其他方法 from threading import ...
- python全栈开发 * 线程队列 线程池 协程 * 180731
一.线程队列 队列:1.Queue 先进先出 自带锁 数据安全 from queue import Queue from multiprocessing import Queue (IPC队列)2.L ...
- day 34 线程队列 线程池 协程 Greenlet \Gevent 模块
1 线程的其他方法 threading.current_thread().getName() 查询当前线程对象的名字 threading.current_thread().ident ...
随机推荐
- Python学习之路6☞函数,递归,内置函数
一python中的函数 函数是逻辑结构化和过程化的一种编程方法. python中函数定义方法: def test(x): "The function definitions" x+ ...
- AtCoder Beginner Contest 075 C Bridge(割边)
求割边个数.Tarjan的板子.. #include <bits/stdc++.h> using namespace std; const int MAXN = 55; const int ...
- C# Dapper 基本使用 增删改查事务
来源:https://blog.csdn.net/Tomato2313/article/details/78880969 using DapperTest.Models; using System.C ...
- SpringMVC参数校验,包括JavaBean和基本类型的校验
该示例项目使用SpringBoot,添加web和aop依赖. SpringMVC最常用的校验是对一个javaBean的校验,默认使用hibernate-validator校验框架.而网上对校验单个参数 ...
- 为你的 SuperSocket 启用动态语言
步骤如下: 1.添加 DLR (dynamic language runtime) 配置片段; Section 定义: <section name="microsoft.scripti ...
- elasticsearch-倒排索引原理
倒排索引 Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索.一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表. 例如,假设我们有两个 ...
- log4js的简单配置
js记录日志工具log4js,参数请参考官网文档https://log4js-node.github.io/log4js-node/index.html const log4js = require( ...
- H3C 帧中继显示与调试
- Bi-LSTM-CRF for Sequence Labeling
做了一段时间的Sequence Labeling的工作,发现在NER任务上面,很多论文都采用LSTM-CRFs的结构.CRF在最后一层应用进来可以考虑到概率最大的最优label路径,可以提高指标. 一 ...
- Python--day43--连表查询(重要)