数据库SQLserver(课本)
一、SQL server的部署
1、数据库的基本概念
- 数据库通常是一个由行和列组成的二维表
- 数据表中的行通常叫做记录或元祖
- 数据表中的列通常叫做字段或属性
2、主键和外键
- 主键:定义主键可以保证数据的完整性
- 外键:一个关系数据库通常包含多个表,通过外键,可以将这些表连接
3、数据库的完整性
- 实体完整性规则:主键不为空
- 域完整性规则:指定某一数据对某一个列是否有效或确定是否允许空值
- 引用完整性规则:如果两个表互相关联,那么引用完整规则要求不允许引用不存在的元祖
- 用户定义完整性规则:针对某一数据的约束条件
4、安装:可看:https://www.cnblogs.com/-xuan/p/9998103.html
5、启动数据库
- 服务(win + R,services.msc,)-->右击SQL server(MSSQLSERVER),开启
- SQL server配置管理器(安装完成后点击桌面左下角,选择Microsoft SQL server 2016中打开),SQL服务-->SQL server(MSSQLSERVER)
- 使用SSMS启动或者停止
6、注册服务器(方便日后管理):打开SSMS连接后,右击实例,注册即可
7、在SQL server中,数据库分为两种
- 系统数据库:
- master 数据库:记录系统级别的信息
- model 数据库:用作实力上创建所有数据库的模板
- msdb数据库:用于SQL server代理计划警报和作业
- tempdb数据库:表示一个数据空间,用于保存临时的对象或中间结果集,SQL server每次启动数据库tempdb都会重新创建
- 用户数据库:
二、数据库和表的管理
1、文件类型
- 主数据文件:包括文件的启动信息,每个数据库都有且只有一个主数据文件,扩展名为*.mdf
- 次要(辅助)数据文件:可以白数据库内动保存到其他计算机或磁盘,扩展名为*.ndf
- 日志文件:最低必须有一个,可以很多,数据误删除可以使用日志文件进行恢复,扩展名为*.ldf
- 文件流:储存非结构化数据,如图片、音频、视频等二进制文件; 数据流主要将SQL server数据库引擎和NTFS集成在一起。
2、数据文件:数据文件由若干个64kb大小的区(Extend)组成,每个区由8个8kb的连续页(Page)组成
3、扩展数据库:可以通过右击数据库——>点击属性——>文件 进行数据库的扩展
4、收缩数据库:分为手动收缩和自动收缩
- 手动收缩分为:收缩数据库和收缩文件
- 收缩数据库:右击数据库——>任务——>收缩——>数据库,对整个数据库进行收缩
- 收缩文件:右击数据库——>任务——>收缩——>文件,对某个文件收缩
- 自动收缩:可以通过右击数据库——>点击属性——>选项——>自动收缩 改为True
5、分离数据库和附加:用于数据库的迁移
6、数据类型
Character 字符串:
| 数据类型 | 描述 | 存储 |
|---|---|---|
| char(n) | 固定长度的字符串。最多 8,000 个字符。 | n |
| varchar(n) | 可变长度的字符串。最多 8,000 个字符。 | |
| varchar(max) | 可变长度的字符串。最多 1,073,741,824 个字符。 | |
| text | 可变长度的字符串。最多 2GB 字符数据。 |
Unicode 字符串:
| 数据类型 | 描述 | 存储 |
|---|---|---|
| nchar(n) | 固定长度的 Unicode 数据。最多 4,000 个字符。 | |
| nvarchar(n) | 可变长度的 Unicode 数据。最多 4,000 个字符。 | |
| nvarchar(max) | 可变长度的 Unicode 数据。最多 536,870,912 个字符。 | |
| ntext | 可变长度的 Unicode 数据。最多 2GB 字符数据。 |
Binary 类型:
| 数据类型 | 描述 | 存储 |
|---|---|---|
| bit | 允许 0、1 或 NULL | |
| binary(n) | 固定长度的二进制数据。最多 8,000 字节。 | |
| varbinary(n) | 可变长度的二进制数据。最多 8,000 字节。 | |
| varbinary(max) | 可变长度的二进制数据。最多 2GB 字节。 | |
| image | 可变长度的二进制数据。最多 2GB。 |
Number 类型:
| 数据类型 | 描述 | 存储 |
|---|---|---|
| tinyint | 允许从 0 到 255 的所有数字。 | 1 字节 |
| smallint | 允许从 -32,768 到 32,767 的所有数字。 | 2 字节 |
| int | 允许从 -2,147,483,648 到 2,147,483,647 的所有数字。 | 4 字节 |
| bigint | 允许介于 -9,223,372,036,854,775,808 和 9,223,372,036,854,775,807 之间的所有数字。 | 8 字节 |
| decimal(p,s) |
固定精度和比例的数字。允许从 -10^38 +1 到 10^38 -1 之间的数字。 p 参数指示可以存储的最大位数(小数点左侧和右侧)。p 必须是 1 到 38 之间的值。默认是 18。 s 参数指示小数点右侧存储的最大位数。s 必须是 0 到 p 之间的值。默认是 0。 |
5-17 字节 |
| numeric(p,s) |
固定精度和比例的数字。允许从 -10^38 +1 到 10^38 -1 之间的数字。 p 参数指示可以存储的最大位数(小数点左侧和右侧)。p 必须是 1 到 38 之间的值。默认是 18。 s 参数指示小数点右侧存储的最大位数。s 必须是 0 到 p 之间的值。默认是 0。 |
5-17 字节 |
| smallmoney | 介于 -214,748.3648 和 214,748.3647 之间的货币数据。 | 4 字节 |
| money | 介于 -922,337,203,685,477.5808 和 922,337,203,685,477.5807 之间的货币数据。 | 8 字节 |
| float(n) | 从 -1.79E + 308 到 1.79E + 308 的浮动精度数字数据。 参数 n 指示该字段保存 4 字节还是 8 字节。float(24) 保存 4 字节,而 float(53) 保存 8 字节。n 的默认值是 53。 | 4 或 8 字节 |
| real | 从 -3.40E + 38 到 3.40E + 38 的浮动精度数字数据。 | 4 字节 |
Date 类型:
| 数据类型 | 描述 | 存储 |
|---|---|---|
| datetime | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 3.33 毫秒。 | 8 bytes |
| datetime2 | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 100 纳秒。 | 6-8 bytes |
| smalldatetime | 从 1900 年 1 月 1 日 到 2079 年 6 月 6 日,精度为 1 分钟。 | 4 bytes |
| date | 仅存储日期。从 0001 年 1 月 1 日 到 9999 年 12 月 31 日。 | 3 bytes |
| time | 仅存储时间。精度为 100 纳秒。 | 3-5 bytes |
| datetimeoffset | 与 datetime2 相同,外加时区偏移。 | 8-10 bytes |
| timestamp | 存储唯一的数字,每当创建或修改某行时,该数字会更新。timestamp 基于内部时钟,不对应真实时间。每个表只能有一个 timestamp 变量。 |
7、默认值:如果没有指定数据,则使用默认值
8、标识列的三个特点及指定的三个内容
- 三个特点
- 列的数据类型为不带小数的数值类型
- 该列有一定顺序产生,不允许为空
- 列值不重复,具有标识表中每行的内容,每个表只能有一个
- 三个内容
- 类型:必须是数值类型,当选择decimal和numeric时,小数位必须为0
- 种子:第一行的值,默认为1
- 递增量:相邻两个表示值之间的增量
9、T-SQL语句管理
- 创建表
CREATE TABLE 表名(
第一列 数据类型()
第二列 数据类型()
...
) 可以指定以下内容
identity(1,1) 标识列,种子为1,递增值为1
not null 制定该列不能为空
primary key 指定主键
check(条件) 对该列做约束创建表
- 修改表
-- 添加列
ALTER TABLE 表名
ADD 列名 数据类型() -- 修改列的数据类型
ALTER TABLE 表名
ALTER COLUNM 列名 数据大小() -- 删除列
ALTER TABLE 表名
DROP COLUMN 列名 --删除表 DROP TABLE 表名添加列,修改列,删除列,删除表
三、T-SQL查询语句
1、插入数据、更新数据、删除数据
-- 插入
insert into 表名 [列名] values(要插入的值列表) 例:
insert into class_table(姓名,年龄,职务) values ('杨过','','运维工程师') //向class_table表中插入姓名:杨过,年龄:18,职务:运维工程师 --更新(修改)数据
update 表名 set 列名 = 更新值 where 条件 例:
update class_table 年龄 = 10 where 姓名 = '杨过' //更改class_table 中 姓名是:杨过 的年龄为10, 可以不指定where,则将所有人年龄更改为10 --删除数据
delete from 表名 where 条件 例:
delete from class_table where 姓名 = '杨过' //删除姓名是杨过的哪一行,如果不指定where则删除整个表,纪录日志 删除表
truncate table class_table //删除表,不记录日志,标识列重置
插入、更新、删除
2、查询语句select
- 语法结构
select select_list
[into new_table_name]
from table_name
[wherer search_conditions]
[group by group_by_expression] [having search_confitions]
[orwer by order_expression [ ASC | DESC] ]语法结构
- 比较运算符
--等于、大于、小于什么的就没写 between 指定一个范围,包含边界 例:between 10 and 20 从10到20的数,包含10和20 is【not】 null 搜索空值扩非空值 like 模糊查询,与字符串进行模式匹配 in 是否在数据范围里边
比较运算符
- 通配符
'_' 任意单个字符
'%' 任意个任意长度的字符
[] 括号范围所指定的一个字符
[^] 不在括号内的任意一个字符 and 两边同时为True,返回True
or 两边一遍为True则返回True
not 真返回假,假返回真 顺序:() > not > and > or通配符 和 逻辑运算符
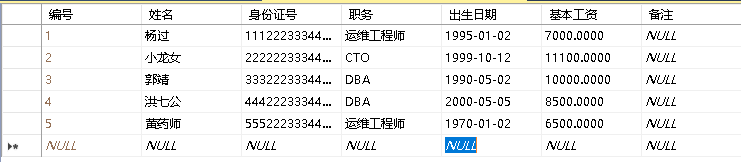
- 查询举例,由于后边都是查询举例,所以就写到一起了,表:

可以先执行以下命令创建词表:
--创建表
CREATE TABLE class_table(
编号 decimal(100,0) identity(1)
姓名 nvarchar(50) not null,
身份证号 char(18) primary key not null,
姓名 nvarchar(50) not null,
姓名 nvarchar(50) not null,
) -- 插入
insert into class_table (姓名,身份证号,职务,出生日期,基本工资)
values('杨过','','运维工程师','1995/01/02',8500),
('小龙女','','CTO','1999/10/12',11100),
('郭靖','','DBA','1990/05/02',10000),
('洪七公','','DBA','2000/05/05',8500),
('黄药师','','运维工程师','1995/01/02',8500)创建上图表
--1、显示表中所有信息
select * from class_table -- 2、查询特定列
select 姓名,职务
from class_table --3、查询特定行
--①查询职务是运维工程师的行的所有信息
select * from class_table
where 职务='运维工程师' --②查询工资在8500 到 10000的员工信息
select * from class_table
where 基本工资 between 8500 and 10000 --③查询工资高于8000 小于 10000的员工
select * from class_table
where 基本工资 > 8000 and 基本工资 < 10000 --④更新黄药师和杨过的工资分别为6500、7000
update class_table set 基本工资 = 6500 where 姓名 = '黄药师'
update class_table set 基本工资 = 7000 where 姓名 = '杨过' --⑤查询表中工资为6500,8500,11100的员工所有信息
select * from class_table where 基本工资 in (6500,8500,11100) --⑥查询表中身份证号以11或22开头的员公所有信息
select * from class_table where 身份证号 like '11%' or 身份证号 like '22%' -- ⑦查询表中姓杨的运维工程师
select * from class_table where 姓名 like '杨%' and 职务 = '运维工程师' --⑧ 查询表中备注为空的员工所有信息
select * from class_table where 备注 is null --4、限制返回的行数
select top n 显示的列 from 表名 --n为返回的行数 --①查询前3行数据
select top 3 * from class_table --5、改变查询后显示的列的名字
select 原名字 as 显示的名字 from 表名
--①显示名字和身份证号,姓名用‘name’表示,身份证用‘idcard’表示
--第一种方式
select 姓名 as name,身份证号 as idcard from class_table
--第二种方式,可以去掉as
select 姓名 name,身份证号 idcard from class_table
--第三种方式,可以用等号赋值
select name=姓名,idcard=身份证号 from class_table --6、排序
select 要显示的列 from 表名 order by 根据什么排序 asc(升序) | desc(降序) --①按照工资进行升序
select * from class_table order by 基本工资 asc --7、查询时重复的只显示一个
select distinct 显示列 from 表名 --①查询表中都有哪些职务
select distinct 职务 from class_table --8、使用select生成新表
select 要添加新表的列 into 新表的名字 ftom 表名
--①将工资大于8000的姓名,职务添加到新表new_table中
select 姓名,职务
into new_table
from class_table
where 基本工资 > 8000
--执行之后会出现一个新表,可以右击,编辑查看前二百行进行查看
--②使用insert查询插入
insert into new_table(姓名,职务) --new_table必须存在才可以使用insert插入
select 姓名,职务
from class_table
where 基本工资 > 8000 --③使用union关键字进行连续插入
insert new_table
select '老大','出去打工' union
select '老二','干活' union
select '老三','照顾老四' union
select '老四','玩'查询举例
第三章实验:
实验案例一:先创建表
create table products(
编号 decimal(10,0) identity(1,1) primary key not null,
名称 nvarchar(10) not null,
种类 nvarchar(10) not null,
成本 money not null,
出厂日期 date not null,
)
创建表
- 方法一
-- 方法一
insert into products(名称,种类,成本,出厂日期)
values ('西瓜','水果',4.1000,'2018/05/06'),
('芹菜','蔬菜',1.0000,'2017/04/01'),
('番茄','蔬菜',2.9000,'2017/05/09'),
('黄瓜','蔬菜',2.2000,'2017/05/05'),
('香蕉','水果',6.1000,'2017/05/23'),
('核桃','坚果',28.1000,'2017/06/02'),
('开心果','坚果',38.1000,'2017/06/21'),
('蓝莓','水果',50.1000,'2017/05/15')方法一
- 可以使用:truncate table products 删除表中的数据,然后使用方法二创建
-- 方法二 insert into products(名称,种类,成本,出厂日期)
select '西瓜','水果',4.1000,'2018/05/06' union
select '芹菜','蔬菜',1.0000,'2017/04/01' union
select '番茄','蔬菜',2.9000,'2017/05/09' union
select '黄瓜','蔬菜',2.2000,'2017/05/05' union
select '香蕉','水果',6.1000,'2017/05/23' union
select '核桃','坚果',28.1000,'2017/06/02' union
select '开心果','坚果',38.1000,'2017/06/21' union
select '蓝莓','水果',50.1000,'2017/05/15'方法二
--验证结果:select * from products
实验案例二:
--1、查看成本低于10的水果价格
select * from products
where 成本 < 10 and 种类 = '水果' --2、将所有蔬菜成本上调一元
update products set 成本 = 成本 + 1
where 种类='蔬菜' --3、查询成本大于3元小于40元的产品信息,并按照成高到低排序
select * from products
where 成本 between 3 and 40
order by 成本 desc --4、查询成本最高的5个产品 select top 5 * from products
order by 成本 DESC --5、查询都有哪些产品种类
select distinct 种类 from products --6、将products中水果的名称、种类、和出厂日期信息插入新表products_new中。
select 名称,种类,出厂日期
into products_new from products
where 种类='水果'
实验案例二
四、T-SQL高级查询
1、以下为函数部分,使用的表为
- 系统函数
--①CONVERT():数据类型转换
select convert(varchar(5),12345) --将数字转换为字符类型 --②CAST():数据类型转换
select cast('2017-05-05' as datetime) --字符串转换为日期时间型 --③CURRENT_USER():返回当前数据库的用户名
select CURRENT_USER --返回的dbo是每个数据库的默认用户,具有所有者的权限 --④ DATELENGTH():返回表达式的字节数
select DATALENGTH('1234五') --一个数字一个字节,一个汉字2个字节,所以会返回6 --⑤HOST_NAME():返回当前计算机明
select HOST_NAME() --⑥SYSTEM_USER:返回登录SQL server的用户名
select SYSTEM_USER --⑦给定用户的ID 返回数据库的用户名,后边的数字不指定默认为1
select USER_NAME(1)系统函数
- 字符串函数
--①CHARINDEX:查找一个字符串在另一个字符串的位置
select CHARINDEX('bdqn','www.bdqn.com') --查找‘bdqn’在‘www.bdqn.com’中的位置,返回5 --②LEN:返回括号内字符串长度
select LEN(123456789) --③UPPER:将字符所有小写字母变为大写,返回改变后的内容
select UPPER('abcd123') --④LOWER:将所有大写字母变为小写,返回改变后的内容
select LOWER('ABCD123') --⑤LTRIM:清除左边的空格,返回清除后的内容
select LTRIM(' 左边 ') --⑥RTRIM:清除右边的空格,返回清除后的内容
select RTRIM(' 右边 ') --⑦RIGHT:从字符右边返回指定数目的字符
select RIGHT('ABCDEFG',3) --返回EFG --⑧LEFT:返回字符左边的指定字符
select LEFT('ABCDEFG',3) --返回ABC --⑨REPLACR:替换字符
select REPLACE('ABCABCABCABC','B','A') --将字母B替换为A并返回 --⑩STUFF:从指定位开始,删除指定的字符,并在此处添加
select STUFF('ABCDEFG',2,3,'我的世界') --从第二个字符开始,删除三个字符,并在此处添加‘我的世界’ --3、字符串拼接
select '运维工程师'+姓名+'的基本工资是:'+CAST(基本工资 as varchar(10)) + '元'
from class_table
where 职务='运维工程师'字符串函数
- 日期函数
--①GETDATE():获取当前系统日期时间
select GETDATE() --②DATEADD():可以用于修改日期,指定添加的年(YY)月(MM)日(DD)
select DATEADD(YY,4,'2000-01-01') --在年上添加4,返回2004-01-01
select DATEADD(MM,4,'2000-01-01') --在月上添加4,返回2000-05-01
select DATEADD(DD,4,'2000-01-01') --在日上添加4,返回2000-01-05 --③DATEDIFF():比较两个日期的差
select DATEDIFF(YY,'2000-01-01','2018-01-01') --计算从2000-01-01到2018-01-01过了多少年
select DATEDIFF(MM,'2000-01-01','2018-01-01') --计算从2000-01-01到2018-01-01过了多少月
select DATEDIFF(DD,'2000-01-01','2018-01-01') --计算从2000-01-01到2018-01-01过了多少天 --④DATENAME():显示指定日期中的特定部分字符串
select DATENAME(YY,'2000-01-01') --显示年
select DATENAME(MM,'2000-10-01') --显示月
select DATENAME(DD,'2000-01-10') --显示日
select DATENAME(DW,'2018-11-23') --显示星期 --⑤DATEPART:显示日期中指定日期的整数形式
select DATEPART(YY,'2018-11-22') --显示年的整数形式
select DATEPART(MONTH,'2018-11-22') --显示月的整数形式
select DATEPART(DD,'2018-11-22') --显示日的整数形式 --日期函数举例
--①显示十天后的日期和时间
select DATEADD(dd,10,GETDATE()) --②显示所有人的姓名和年龄
select 姓名,DATEDIFF(yy,出生日期,GETDATE()) as 年龄 from class_table --③显示表中90后员工的姓名和出生年份
select 姓名,DATEPART(YY,出生日期) as 出生年份
from class_table
where 出生日期 between '1990-01-01' and '1999-12-31'日期函数
- 聚合函数
--sum
select sum(基本工资) as 总工资 from class_table --计算出所有人工资的总和 --avg
select avg(基本工资) as 平均工资 from class_table --计算出所有员工的平均工资 --max
select max(基本工资) as 最高工资 from class_table --计算出所有员工的最高工资 --min
select min(基本工资) as 最低工资 from class_table --计算出所有员工的最低工资 --count
select count(姓名) as 所有员工个数 from class_table --计算公司有多少员工 --例子:
--计算出表中90后的员工人数
select count(出生日期) as '90后人数'
from class_table
where 出生日期 between '1990-01-01' and '1999-12-31'聚合函数
- 分组查询:顺序为where —>group by —> having
--案例1:查询表中每个职务的平均信息
select 职务,avg(基本工资) as 平均工资 from class_table
group by 职务 --案例二:查询平均工资小于10000的职务
select 职务,avg(基本工资) as 平均工资
from class_table
group by 职务
having avg(基本工资) < 10000 --案例三:计算平均工资小于一万的职务,前提是郭靖不在计算之内
select 职务,avg(基本工资) as 平均工资
from class_table
where 姓名 <> '郭靖'
group by 职务
having avg(基本工资) < 10000分组查询
- 数学函数
--①ABS():取绝对值
select ABS(-46) --②CEILING:取大于等于的整数,然后返回
select CEILING(46.4) --③FLOOR:取小于等于的整数,然后返回
select floor(46.4) --④POWER:求幂数
select power(5,2) --算出5的2次方 --⑤ROUND:四舍五入,第二个数是指定精数
select ROUND(45.123,1) --⑥SIGN:正数返回1,0返回0,负数返回-1
select sign(-6) --⑦SQRT:取浮点数的平方根
select SQRT(9) --案例1:查询所有人的平均工资,并取整
select ceiling(avg(基本工资)) as 平均工资
from class_table数学函数
- 综合案例
查询未满三十岁的员工生日和年龄,并计算出距离30岁生日的天数,最后用字符串拼接 select '员工' + 姓名+'的生日是:'+convert( varchar(10),出生日期,111) + ',现在的年龄是'+cast(datediff(YY,出生日期,GETDATE()) as varchar(10))+',距离三十岁生日还有:'+cast(DATEDIFF(dd,出生日期,GETDATE())as varchar(10))+'天'
from class_table
where DATEDIFF(YY,出生日期,GETDATE()) < 30综合案例
2、表连接:使用的表为课后实验案例中创建的表
--1、内连接(inner join):最常用的链接方式
--第一种
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products,sales
where products.名称 = sales.名称 --第二种
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products inner join sales on products.名称 = sales.名称 --2、外链接
--①:左外链接
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products left join sales on products.名称 = sales.名称
--②:右外链接
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products right join sales on products.名称 = sales.名称
--③:完整外链接
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products full join sales on products.名称 = sales.名称
表连接
3、课后实验:
- 实验案例一
--实验案例一
--创建表
create table products(
编号 decimal(10,0) identity(1,1) primary key not null,
名称 nvarchar(10) not null,
种类 nvarchar(10) not null,
成本 money not null,
出厂日期 date not null,
) insert into products(名称,种类,成本,出厂日期)
values ('西瓜','水果',4.1000,'2018/05/06'),
('芹菜','蔬菜',1.0000,'2017/04/01'),
('番茄','蔬菜',2.9000,'2017/05/09'),
('黄瓜','蔬菜',2.2000,'2017/05/05'),
('香蕉','水果',6.1000,'2017/05/23'),
('核桃','坚果',28.1000,'2017/03/03'),
('开心果','坚果',38.1000,'2017/02/22'),
('蓝莓','水果',50.1000,'2017/05/11') --1、查询出厂日期晚于2017年4月的水果信息
select * from products
where 种类 = '水果' and 出厂日期 >= '2017-04-01' --2、分组查询所有水果、蔬菜、坚果的总成本
select 种类,
sum(成本) as 总成本
from products
group by 种类 --3、查询所有水果的名称和出厂日期,一待定格式拼接字符串,如‘西瓜的出厂日期是:2017/05/06’
select 种类+'的出厂日期是:'+replace(cast(出厂日期 as varchar(10)),'-','/')
from products
where 种类 = '水果' --4、查询所有蔬菜的平均成本
select avg(成本) as 平均成本
from products
where 种类='蔬菜'
group by 种类实验案例一
- 实验案例二
--实验案例2
--创建表
create table products
(
编号 decimal(10,0) identity(1,1) primary key not null,
名称 nvarchar(10) not null,
种类 nvarchar(10) not null,
成本 money not null,
出厂日期 date not null,
) insert into products(名称,种类,成本,出厂日期)
values ('西瓜','水果',4.1000,'2018/05/06'),
('芹菜','蔬菜',1.0000,'2017/04/01'),
('番茄','蔬菜',2.9000,'2017/05/09'),
('黄瓜','蔬菜',2.2000,'2017/05/05'),
('香蕉','水果',6.1000,'2017/05/23'),
('核桃','坚果',28.1000,'2017/03/03'),
('开心果','坚果',38.1000,'2017/02/22'),
('蓝莓','水果',50.1000,'2017/05/11') create table sales
(
名称 nvarchar(10) not null,
销售地点 nvarchar(10) not null,
销售价格 money not null
) insert into sales
values
('苹果','河北',5),
('香蕉','湖南',6.2),
('番茄','北京',3.15),
('黄瓜','湖北',2.45),
('芹菜','河北',1.11),
('草莓','北京',10),
('哈密瓜','北京',8.98),
('蓝莓','上海',59.9),
('核桃','海南',35.8) --
--第一种
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products,sales
where products.名称 = sales.名称 --第二种
select products.名称,products.种类,products.成本,sales.销售地点,sales.销售价格
from products inner join sales on products.名称 = sales.名称 --
--第一种
select products.名称,products.种类,products.成本,sales.销售价格
from products,sales
where products.名称 = sales.名称 and sales.销售地点 = '海南'
--第二种
select products.名称,products.种类,products.成本,sales.销售价格
from products inner join sales on products.名称 = sales.名称 and sales.销售地点 = '海南' --
--第一种
select products.名称,products.种类,products.成本,sales.销售价格
from products,sales
where products.名称 = sales.名称 and sales.销售地点 = '北京' and products.种类 = '蔬菜'
--第二种
select products.名称,products.种类,products.成本,sales.销售价格
from products inner join sales on products.名称 = sales.名称 and sales.销售地点 = '北京' and products.种类 = '蔬菜'实验案例二
- 实验案例一
五、查询优化 和 事物处理
1、索引
- 唯一索引:唯一索引不允许两行具有相同索引值
- 主键索引:主键索引要求住建中的每个值是唯一的,一个表的主键就是这个表的主键索引
- 聚集索引:一个表只能有一个,,表中的各行的物理顺序与键值的逻辑(索引)顺序相同
- 非聚集索引:可以有多个,通过索引找到记录的存放位置
- 复合索引:和创建主键一样,可以将多个列组合,作为索引,这种索引称为逻辑索引
- 全文索引:全文索引是一种特殊类型的基于标记的功能性索引,由SQL server中全文引擎服务创建和维护
2、创建索引:在表的设计,右击创建索引
使用索引查找:
select * from 表名
with (index = 索引名)
where 条件
使用索引查找
3、视图
- 常用操作
- 筛选表中的行
- 防止未经允许的用户访问敏感资源
- 将做个物理表数据抽象为一个逻辑表
- 好处
- 对最终用户的好处
①结果更容易理解
②获得数据更容易 - 对开发人员的好处
①限制数据检索更容易
②维护应用程序方便
- 对最终用户的好处
- 创建视图
打开数据库节点,然后右击数据库,新建视图,选择物理表 可以手动修改下方自动生成的SQL语句
4、存储过程
- 存储过程的优点
- 模块化的程序设计:一次创建,后期可以任意使用
- 执行速度快,效率高
- 减少网络流量:在网络中不需要传输过多代码
- 具有良好的安全性:避免了攻击者非法截取SQL 代码获得数据的可能性
- 存储过程分类
- 系统存储过程
exec sp_databases //列出服务器上所有数据库信息
exec sp_renamedb 'myband' ,'bank' 修改数据库名称 use bdqn //指定bdqn数据库
go
exec sp_tables //当前数据库中可查询对象的列表
exec sp_columns xueyuan //查看学员表中的信息
exec sp_help xueyuan //查看学员表中的所有信息
exec sp_helpconstraint xueyuan //查看的约束
exec sp_helptext view_1 //查看视图的语句文本
exec sp_stored_procedures //返回当前数据库的存储过程列表常用的系统存储过程
exec xp_cmdshell 'mkdir C:\bank',no_output //创建文件夹,不输出 --注意
xp_cmashell为了安全,默认没有启用,可以使用以下命令创建
exec sp_configure 'show advanced options', 1 //显示高级配置信息
go
reconfigure //从新配置
go
exec sp_configure 'xp_cmdshell',1 //打开xp_cmdshell选项
go
reconfigure //重新配置
go常用的扩展存储过程
- 用户自定义存储过程
create procedure 存储过程名
as
SQL 语句 drop procedure创建、删除存储过程
查询虚拟化课程的平均分 --检查是否存在存储过程
use bdqn
go
if exists(select * from 系统表(sysobjects)) where name='存储过程名(后边用demo表示)'
drop procedure demo
go
-- 创建存储过程
create procedure demo
as
declare @subject int --定义一个整数变量 --给变量赋值
select @subject = kecheng.课程ID from 表名
inner join chengji on cehngji.课程ID = kecheng.课程ID
where 课程名='虚拟化' declare @avg decimal(18,2) --生命一个小数变量,用于保存平均分
select @avg = AVG(学员成绩)
from cehngji where 课程ID=@subject print '平均分:'+convert(varchar(5),@avg) 调用 exec demo创建实例
5、触发器
- 触发器分为三种
- insert触发器:当向表中表中插入数据,自动执行触发器定义的SQL语句
- update触发器:更新表中某列、多列时,自动执行触发器定义的SQL语句
- delect触发器:当删除表中数据时,自动执行触发器定义的SQL语句
- 触发器作用
- 强化约束
- 跟踪变化
- 级联运行
- 创建触发器
create trigger 名称
on 表名
[with encryption] //防止触发器作为SQL server 复制的一部分发布
for {[delete,insert,update]} //指定触发器执行了什么后触发
as SQL语句创建触发器
课后作业:
- 创建表
create table xueyuan
(
学员ID int primary key not null,
学员姓名 nvarchar(50) not null,
电话 decimal(11,0) not null,
出生日期 date not null
) create table chengji
(
学员ID int not null,
课程ID int not null,
考试成绩 int not null,
考试日期 date not null
) create table kecheng
(
课程ID int primary key not null,
课程名 nvarchar(50) not null
) insert into xueyuan
select 1,'老大',110,'2000/01/01' union
select 2,'老二',120,'2001/01/01' union
select 3,'老三',130,'2002/01/01' union
select 4,'老四',140,'2003/01/01' union
select 5,'老五',150,'2004/01/01' union
select 6,'老六',160,'2005/01/01' union
select 7,'老七',170,'2006/01/01' union
select 8,'老八',180,'2007/01/01' insert into kecheng
select 1, 'Java' union
select 2,'HTML' union
select 3,'python' insert into chengji
select 1,1,60,'2000/01/01' union
select 2,2,55,'2005/01/01' union
select 3,2,70,'2006/01/01' union
select 4,1,92,'2000/01/01' union
select 5,3,80,'2007/01/01' union
select 6,3,49,'2002/01/01' union
select 7,2,95,'2006/01/01' union
select 8,1,88,'2018/01/01'创建表
create trigger demo
on kecheng
for update
as
print '禁止操作,请联系DBA'
ROLLBACK TRANSACTION //回滚操作
go --执行上边触发器后,当向kecheng表中更新数据,将会被拒绝触发器实例
6、事务
- 事务是作为单个逻辑工作单元执行的一系列操作,一个逻辑单元必须有以下四个属性
- 原子性
- 一致性
- 隔离性
- 持久性
- 执行事务
begin TRANSTACTION --开始事务
commit TRANSACTION --提交事务
ROLLBACK --回滚事务 - 应用实例
select customername,currentomonry as 转账事务前余额 from bank
go
begin TRANSACTION --开始事务
declare @errorSum int --声明变量,用于保存错误号的和
set @errorSum = 0 --初始化变量
--张三转账1000元给李四
uodate bank set currenmonry = curentmonry - 1000
where customername = '张三'
set @errorSum = @errorXum + @@ERROR --累计是否有错误
uodate bank set currenmonry = curentmonry + 1000
where customername = '李四'
set @errorSum = @errorXum + @@ERROR --累计是否有错误 select customername,curentomoney as 转账事物过程中的余额
from bank if @errorSum <>0 --如果有错误
begin
print '交易失败,回滚事务'
ROLLBANK TRANSACTION
end
else
begin
print '交易成功,提交事务,保存硬盘,永久保存'
COMMIT TRANSACTION
end
go应用实例
- 实验案例一
select xueyuan.学员姓名,kecheng.课程ID,chengji.考试日期,chengji.考试成绩 as 学员成绩
from chengji with (index=成绩) inner join kecheng on chengji.课程ID=kecheng.课程ID
inner join xueyuan on chengji.学员ID=xueyuan.学员ID
where chengji.考试成绩 between 80 and 90实验案例一
- 实验案例二
SELECT dbo.kecheng.课程ID, dbo.kecheng.课程名, AVG(dbo.chengji.考试成绩) AS 平均成绩
FROM dbo.chengji INNER JOIN
dbo.kecheng ON dbo.chengji.课程ID = dbo.kecheng.课程ID INNER JOIN
dbo.xueyuan ON dbo.chengji.学员ID = dbo.xueyuan.学员ID
GROUP BY dbo.kecheng.课程ID, dbo.kecheng.课程名实验案例二
- 实验案例三
create trigger xueyuan_no_update
on xueyuan
for update
as
print '禁止修改'
rollback transaction
go实验案例三
--实验案例三测试
update xueyuan set 学员姓名='李四' where xueyuan.学员姓名='老四' - 实验案例四
use school
go
--exec sp_databases
--exec sp_tables
--exec sp_helpconstraint xueyuan
--exec sp_helpindex chengji
--exec sp_stored_procedures
--exec sp_helptext xueyuan_no_update 从go后边,一行一小题实验案例四
六、权限管理与数据恢复
1、权限设置
- SQL Server的4个安全机制
- 客户机的安全机制
- 服务器的安全机制
- 数据库的安全机制
- 数据对象的安全机制
- SQL Server的两种验证方式:右击实例 —— 属性 —— 安全性 设置使用的验证方式
- Windows身份验证
- SQL Server 和 Windows 身份验证 混合模式
- 登录账号设置:右击实例 —— 安全性 —— 登录名 右击登录名,新建登录名
- 服务器级别权限设置:实例 —— 安全性 —— 登录名 右击某个用户 —— 服务器角色设置权限
固定服务器角色
说 明
sysadmin
执行SQL Server中的任何动作
serveradmin
配置服务器设置
setupadmin
安装复制和管理扩展过程
securityadmin
管理登录和CREATE DATABASE的权限以及阅读审计
processadmin
管理SQL Server进程
dbcreator
创建和修改数据库
diskadmin
管理磁盘文件
- 新建数据库用户:数据库 —— bdqn —— 安全性 —— 右击用户,新建用户,打开数据库用户 —— 新建
- 内置数据库用户:dbo,每个数据库的默认用户,不能删除或修改,具有所有者权限,默认dbo映射了db_OWNER数据库的角色成员,而db_OWNER具有对数据库的全部管理权限
- guest是来宾用户:不能删除或修改,不映射任何用户。没有任何权限,处于禁用状态
- 数据库角色及权限
固定数据库角色
说 明
db_owner
可以执行数据库中技术所有动作的用户
db_accessadmin
可以添加、删除用户的用户
db_datareader
可以查看所有数据库中用户表内数据的用户
db_datawriter
可以添加、修改或删除所有数据库中用户表内数据的用户
db_ddladmin
可以在数据库中执行所有DDL操作的用户
db_securityadmin
可以管理数据库中与安全权限有关所有动作的用户
db_backoperator
可以备份数据库的用户(并可以发布DBCC和CHECKPOINT语句,这两个语句一般在备份前都会被执行)
db_denydatareader
不能看到数据库中任何数据的用户
db_denydatawriter
不能改变数据库中任何数据的用户
固定的数据库还有一个public的角色,该角色用来捕获数据库中用户的所有默认权限,该角色不能被删除
- 数据库级别设置权限步骤
- 第一种:SQL server实例 —— 安全性 —— 登录名 ,右击某个用户,然后属性 —— 用户映射 在’登录属性’窗口下方选择数据库角色成员即可
- 第二种:bdqn —— 安全性 —— 角色,右击数据库角色,在弹出的菜单中选择‘新建数据库角色’,打开‘数据库角色-新建‘,选择常规页中新建;新建后可以右击有户名设置权限
- 对象级别权限设置
为表授权:直接右击表 —— 属性 —— 权限 可以点击搜索添加数据库用户
也可以对数据库和存储过程授权,直接右击数据库或者存储过程即可
2、SQL server备份和还原
- 造成数据丢失的主要原因
①程序错误
②人为错误
③计算机失败
④磁盘失败
⑤灾难和偷窃 - 备份类型
- 完整备份:完整备份整个数据库、部分事务日志、数据库的结构和文件结构备份
- 差异备份:指对上一次完整备份之后的所有更改的数据做备份,备份过程能识别出数据库中那一部分吧被修改了,并只对这一部分备份
- 事务日志备份:在执行至少一次完整备份后,才可以备份事务日志,事务日志备份记录了数据库的所有改变
- 恢复模式
- 简单恢复模式:在简单恢复模式下,不活动的日志将被删除,所以不支持事务日志备份
- 完整恢复模式:可以保证数据能够恢复到发生故障时的状态,除了发生错误的那一刹那的事务
- 大容量日志恢复模式:恢复的数据太多,会导致数据库性能很低,可以采用大容量日志恢复
- 更改恢复模式:右击bdqn数据库 —— 属性 —— 选项 在恢复模式可以设置
数据库SQLserver(课本)的更多相关文章
- sql 2000 无法连接远程数据库 sqlserver不存在或访问被拒绝、不能打开到主机的连接,在端口1433:连接失败等 解决方案
问题: sql 2000 无法连接远程数据库 sqlserver不存在或访问被拒绝 telnet 127.0.0.1 1433 提示:不能打开到主机的连接,在端口1433:连接失败 解决方案: ...
- C#------EntityFramework实体加载数据库SQLServer(MySQL)
一.SQLServer数据库创建表Company,包含ID,CName,IsEnabled三列 二.(1)VS新建一个DXApplication工程,名为CompanyManageSystem (2) ...
- 小觑数据库(SqlServer)查询语句执行过程
近年来,越来越多的NoSql产品不断的以技术革命的者的身份跳出来:“你看哥是多么的快,你们关型型数据库真是战五渣阿”.是的,高性能的场景下NoSql真的很出彩.而我们关系型数据库只能在墙角哭泣&quo ...
- 【转载】C#常用数据库Sqlserver通过SQL语句查询数据库以及表的大小
在Sqlserver数据库中,一般我们查看数据库的大小可以通过查找到数据库文件来查看,但如果要查找数据表Table的大小的话,则不可通过此方法,在Sqlserver数据库中,提供了相应的SQL语句来查 ...
- 【转载】C#常用数据库Sqlserver中DATEPART() 函数
在Sqlserver数据库中,DATEPART() 函数用于返回日期/时间的单独部分,比如年.月.日.小时.分钟等等.DatePart()函数的语法为: DATEPART(datepart,date) ...
- Java程序操作数据库SQLserver详解
数据库基本操作:增删改查(CRUD) crud介绍(增.删.改.查操作) CRUD是指在做计算处理时的增加(Create).查询(Retrieve)(重新得到数据).更新(Update)和删除(Del ...
- 数据库——SQL-SERVER练习(6) 数据库安全性
一.实验准备 (1)运行SQL-SERVER服务管理器, 启动服务(2)运行查询分析器, 以DBA身份登录数据库服务器: 用户名sa, 密码123456(3)打开CREATE-TABLE ...
- 数据库——SQL-SERVER练习(2)连接与子查询
一.实验准备 1.复制实验要求文件及“CREATE-TABLES.SQL”文件, 粘贴到本地机桌面. 2.启动SQL-SERVER服务. 3. 运行查询分析器, 点击菜单<文件>/< ...
- 数据库——SQL-SERVER练习(1)连接与子查询
一.实验准备 1.复制实验要求文件及“CREATE-TABLES.SQL”文件, 粘贴到本地机桌面. 2.启动SQL-SERVER服务. 3. 运行查询分析器, 点击菜单<文件>/< ...
随机推荐
- sha0dow0socks
秋水的一键安装脚本 #!/usr/bin/env bash PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bi ...
- P3899 [湖南集训]谈笑风生
题目链接 https://www.lydsy.com/JudgeOnline/problem.php?id=3653 https://www.luogu.org/problemnew/show/P38 ...
- Hyper
https://github.com/zeit/hyper https://gist.github.com/coco-napky/404220405435b3d0373e37ec43e54a23 Ho ...
- Trim Galore用法及参数考量
Trim Galore是一个非常流行的用于「去接头序列」的软件,用于处理高通量测序得到的原始数据.通常我们从测序公司拿到数据后,第一步就是评估数据的质量以及对raw data去接头处理.公司拿来的数据 ...
- tomcat使用spring-loaded实现应用热部署
springloaded官方说明: Spring Loaded is a JVM agent for reloading class file changes whilst a JVM is runn ...
- HDU 3507 Print Article(斜率优化)
显然的斜率优化模型 但是单调队列维护斜率单调性的时候出现了莫名的锅orz 代码 #include <cstdio> #include <algorithm> #include ...
- IE10 解决input file 同一文件不触发onchange事件
if (window.ActiveXObject) { var reg = /10\.0/; var str = navigator.userAgent; if (reg.test(str)) { v ...
- (zhuan) awesome-object-proposals
awesome-object-proposals A curated list of object proposals resources for object detection. This ...
- (转载)C# winform 在一个窗体中如何设置另一个窗体的TextBox的值
方法1:修改控件的访问修饰符.(不建议使用此法) public System.Windows.Forms.TextBox textBox1; 在调用时就能直接访问 Form1 frm = new Fo ...
- Codeforces 808G Anthem of Berland(KMP+基础DP)
题意 给定一个字符串 \(s\) ,一个字符串 \(t\) ,其中 \(s\) 包含小写字母和 "?" ,\(t\) 只包含小写字母,现在把 \(s\) 中的问号替换成任意的小写字 ...