5.Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理。
1.URLError
首先解释下URLError可能产生的原因:
- 网络无连接,即本机无法上网
- 连接不到特定的服务器
- 服务器不存在
在代码中,我们需要用try-except语句来包围并捕获相应的异常。下面是一个例子,先感受下它的风骚
request = urllib2.Request('http://www.xxx.xom')
try:
urllib2.urlopen(request)
except urllib2.URLError,e:
print e.reason
我们利用了 urlopen方法访问了一个不存在的网址,运行结果如下:
[Errno 11001] getaddrinfo failed
它说明了错误代号是11004,错误原因是 getaddrinfo failed
2.HTTPError
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字”状态码”。举个例子,假如response是一个”重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。
其他不能处理的,urlopen会产生一个HTTPError,对应相应的状态吗,HTTP状态码表示HTTP协议所返回的响应的状态。下面将状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
HTTPError实例产生后会有一个code属性,这就是是服务器发送的相关错误号。
因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
下面我们写一个例子来感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这是它的父类URLError的属性。
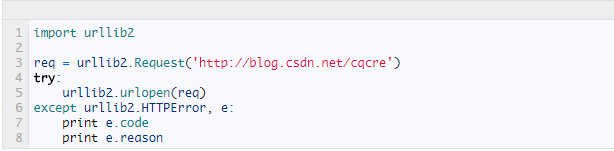
运行之后的结果是:
403
Forbidden
错误代号是403,错误原因是Forbidden,说明服务器禁止访问。
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以这么改写
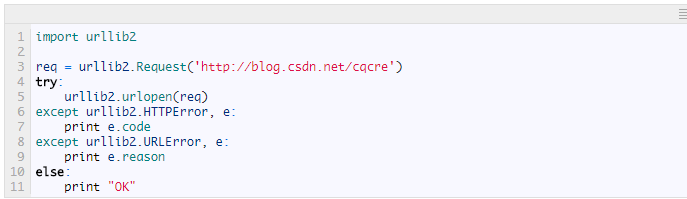
如果捕获到了HTTPError,则输出code,不会再处理URLError异常。如果发生的不是HTTPError,则会去捕获URLError异常,输出错误原因。
另外还可以加入 hasattr属性提前对属性进行判断,代码改写如下
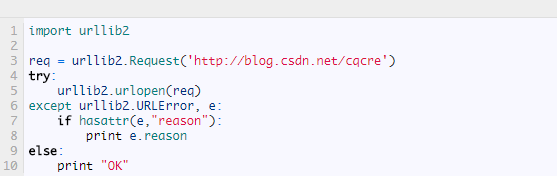
首先对异常的属性进行判断,以免出现属性输出报错的现象。
以上,就是对URLError和HTTPError的相关介绍,以及相应的错误处理办法,小伙伴们加油!
5.Python爬虫入门五之URLError异常处理的更多相关文章
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- Python爬虫教程——入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- 爬虫入门五 gooseeker
title: 爬虫入门五 gooseeker date: 2020-03-16 16:00:00 categories: python tags: crawler gooseeker是一个简单的爬虫软 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
随机推荐
- VueJs大全;vee-validate(一个验证vue插件), bootstrap-vue, axios简介。
Vue.js大全(包括依赖,插件,好的指导文章等!)
- Tensor RT使用记录
Tensor RT的介绍在此不做赘述. 自己在服务器上本打算装Tensor RT来着,不过过程很艰辛,最后发现服务器的cudnn版本偏低了,还需要升级cudnn的版本.故,在自己的电脑上了装了下Ten ...
- php字段转义
addslashes() 函数返回在预定义的字符前添加反斜杠的字符串. 预定义字符是:在以下符号前加/ 单引号(') 双引号(") 反斜杠(\) NULL parse_str($str,$a ...
- Remove Duplicate Letters(Java 递归与非递归)
题目介绍: Given a string which contains only lowercase letters, remove duplicate letters so that every l ...
- Ubuntu深度学习环境搭建 tensorflow+pytorch
目前电脑配置:Ubuntu 16.04 + GTX1080显卡 配置深度学习环境,利用清华源安装一个miniconda环境是非常好的选择.尤其是今天发现conda install -c menpo o ...
- Wannafly挑战赛23B游戏
https://www.nowcoder.com/acm/contest/161/B 题意:两个人van游戏,n堆石子,每次只能取这堆石子数目的因子个数,没得取的人输,问第一个人的必胜策略有多少种 题 ...
- rsync+inotify
一.rsync 1.1rsync是啥 相当于cp.scp.rm等工具,但优于这些工具,主要用在数据备份 1.2.rsync安装 yum -y install rsync --update 客户端删除文 ...
- 把url链接转换成二维码的工具类
import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import java.io ...
- Spring + Mybatis项目实现数据库读写分离
主要思路:通过实现AbstractRoutingDataSource类来动态管理数据源,利用面向切面思维,每一次进入service方法前,选择数据源. 1.首先pom.xml中添加aspect依赖 & ...
- python中类的概念
在Python中,所有数据类型都可以视为对象,也可以自定义对象.自定义的对象即面向对象中的类(Class)的概念. class Student(object): def __init__(self, ...