tf.trainable_variables() and tf.all_variables()
cross entropy
交叉熵,tensorflow 对 cross entropy 进行了集成:
1. 二分类和多分类公式集成,共用一个 API;
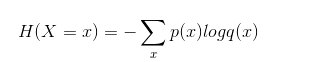
p(x) 真实标签,q(x) 预测概率;
2. 把 sigmoid 、softmax 等集成到 cross entropy 中;
正常情况下,神经网络最后的输出需要通过 softmax 转换成概率,然后再套用公式计算交叉熵,tf 的集成 API 直接输入神经网络的输出即可
tf.nn.softmax_cross_entropy_with_logits
集成了 softmax 和 cross entropy 的 API
def softmax_cross_entropy_with_logits(
_sentinel=None, # pylint: disable=invalid-name
labels=None,
logits=None,
dim=-1,
name=None,
axis=None)
示例
#our NN's output
logits = tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
#step1:do softmax
y = tf.nn.softmax(logits) #true label
y_= tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]]) #step2:do cross_entropy
cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #do cross_entropy just one step
cross_entropy2 = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_)) # dont forget tf.reduce_sum()!! with tf.Session() as sess:
softmax_value=sess.run(y)
c_e = sess.run(cross_entropy)
c_e2 = sess.run(cross_entropy2)
print(softmax_value)
print(c_e) # 1.222818
print(c_e2) # 1.2228179
可以看到手动计算 和 API 计算的结果是一样的
tf.nn.sparse_softmax_cross_entropy_with_logits
API 参数同上;
sparse,稀疏编码,把类别进行稀疏编码,如共 3 个类别,样本属于第 2 个,则需要编码为 [0,1,0]; 【对实际 label 的 sparse】
集成了 稀疏编码、softmax 和交叉熵;
# our NN's output
logits = tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]]) # true label
# 注意这里标签必须是浮点数,不然在后面计算tf.multiply时就会因为类型不匹配tf_log的float32数据类型而出错
y_= tf.constant([[0,0,1.0],[0,0,1.0],[0,0,1.0]]) # 这个是稀疏的标签 # 手算交叉熵
y = tf.nn.softmax(logits)
tf_log = tf.log(y)
pixel_wise_mult = tf.multiply(y_,tf_log)
cross_entropy = -tf.reduce_sum(pixel_wise_mult) #将标签稠密化
dense_y = tf.argmax(y_,1) # [2 2 2]
cross_entropy2_step1 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=dense_y,logits=logits)
cross_entropy2_step2 = tf.reduce_sum(cross_entropy2_step1) with tf.Session() as sess:
cross_entropy_value=sess.run(cross_entropy)
sparse_cross_entropy2_step2_value=sess.run([cross_entropy2_step2])
print(sess.run(dense_y)) # [2 2 2]
print("step4:cross_entropy result=\n%s\n"%(cross_entropy_value)) # 1.222818
print("Function(tf.reduce_sum) result=\n%s\n"%(sparse_cross_entropy2_step2_value)) # 1.2228179
tf.nn.sigmoid_cross_entropy_with_logits
API 参数同上;
这个 API 适用于 一个样本有多个 label 的情况,如在目标检测中,一张图像上可能有 猫,可能有狗,输出的 label 可能为 [0,1,1,0];
它的本质不是多分类,而是多个二分类;
def sigmoid(x):
return 1.0/(1+np.exp(-x)) labels = np.array([[1.,0.,0.],[0.,1.,0.],[0.,0.,1.]])
logits = np.array([[11.,8.,7.],[10.,14.,3.],[1.,2.,4.]])
y_pred = sigmoid(logits)
prob_error1 = -labels * np.log(y_pred) - (1 - labels) * np.log(1 - y_pred) labels1 = np.array([[0.,1.,0.],[1.,1.,0.],[0.,0.,1.]]) # 不一定只属于一个类别
logits1 = np.array([[1.,8.,7.],[10.,14.,3.],[1.,2.,4.]])
y_pred1 = sigmoid(logits1)
prob_error11 = -labels1 * np.log(y_pred1) - (1 - labels1) * np.log(1 - y_pred1) with tf.Session() as sess:
print(prob_error1)
# [[1.67015613e-05 8.00033541e+00 7.00091147e+00]
# [1.00000454e+01 8.31528373e-07 3.04858735e+00]
# [1.31326169e+00 2.12692801e+00 1.81499279e-02]]
print(sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=labels,logits=logits)))
# [[1.67015613e-05 8.00033541e+00 7.00091147e+00]
# [1.00000454e+01 8.31528373e-07 3.04858735e+00]
# [1.31326169e+00 2.12692801e+00 1.81499279e-02]]
print(prob_error11)
# [[1.31326169e+00 3.35406373e-04 7.00091147e+00]
# [4.53988992e-05 8.31528373e-07 3.04858735e+00]
# [1.31326169e+00 2.12692801e+00 1.81499279e-02]]
print(sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=labels1,logits=logits1)))
### 同上
tf.nn.weighted_cross_entropy_with_logits
它是 sigmoid_cross_entropy_with_logits 的扩展
def weighted_cross_entropy_with_logits(labels=None,
logits=None,
pos_weight=None,
name=None,
targets=None):
"""Computes a weighted cross entropy. labels * -log(sigmoid(logits)) * pos_weight +
(1 - labels) * -log(1 - sigmoid(logits)) pos_weight: A coefficient to use on the positive examples
"""
tf.losses.softmax_cross_entropy
增加了一个权重,当权重为 1 时,等价于 tf.nn.softmax_cross_entropy_with_logits
#our NN's output
logits = tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
#step1:do softmax
y = tf.nn.softmax(logits) #true label
y_= tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]]) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_))
# tf.losses.softmax_cross_entropy(y_, logits, weights=1.)
tf.losses.softmax_cross_entropy(y_, logits, weights=0.5) with tf.Session() as sess:
print(sess.run(loss)) # 0.40760598
print(sess.run(tf.losses.get_total_loss())) # 0.40760598 weights=1 时想等, weights=0.5 时为 0.20380299
均方差
tensorflow 其实没有提供这个 API,自己实现也很方便
y = tf.constant([0.9, 2.1, 2.8])
y_pred = tf.constant([1, 2, 3], dtype=tf.float32)
err1 = tf.reduce_sum(tf.square(y - y_pred)) / 3
err2 = tf.reduce_mean(tf.square(y - y_pred)) sess = tf.Session()
print(sess.run(err1)) # 0.020000001
print(sess.run(err2)) # 0.020000001
参考资料:
https://blog.csdn.net/marsjhao/article/details/72630147
https://blog.csdn.net/weixin_42561002/article/details/87802096 tf.losses.softmax_cross_entropy()及相邻函数中weights参数的设置
tf.trainable_variables() and tf.all_variables()的更多相关文章
- tf.trainable_variables和tf.all_variables的对比
tf.trainable_variables返回的是可以用来训练的变量列表 tf.all_variables返回的是所有变量的列表
- tf.trainable_variables()
https://blog.csdn.net/shwan_ma/article/details/78879620 一般来说,打印tensorflow变量的函数有两个:tf.trainable_varia ...
- tf.variable和tf.get_Variable以及tf.name_scope和tf.variable_scope的区别
在训练深度网络时,为了减少需要训练参数的个数(比如具有simase结构的LSTM模型).或是多机多卡并行化训练大数据大模型(比如数据并行化)等情况时,往往需要共享变量.另外一方面是当一个深度学习模型变 ...
- 【TensorFlow基础】tf.add 和 tf.nn.bias_add 的区别
1. tf.add(x, y, name) Args: x: A `Tensor`. Must be one of the following types: `bfloat16`, `half`, ...
- TensorFlow 辨异 —— tf.placeholder 与 tf.Variable
https://blog.csdn.net/lanchunhui/article/details/61712830 https://www.cnblogs.com/silence-tommy/p/70 ...
- TF.VARIABLE、TF.GET_VARIABLE、TF.VARIABLE_SCOPE以及TF.NAME_SCOPE关系
1. tf.Variable与tf.get_variable tensorflow提供了通过变量名称来创建或者获取一个变量的机制.通过这个机制,在不同的函数中可以直接通过变量的名字来使用变量,而不需要 ...
- tensorflow笔记4:函数:tf.assign()、tf.assign_add()、tf.identity()、tf.control_dependencies()
函数原型: tf.assign(ref, value, validate_shape=None, use_locking=None, name=None) Defined in tensorflo ...
- 理解 tf.Variable、tf.get_variable以及范围命名方法tf.variable_scope、tf.name_scope
tensorflow提供了通过变量名称来创建或者获取一个变量的机制.通过这个机制,在不同的函数中可以直接通过变量的名字来使用变量,而不需要将变量通过参数的形式到处传递. 1. tf.Variable( ...
- TF:利用TF的train.Saver将训练好的variables(W、b)保存到指定的index、meda文件—Jason niu
import tensorflow as tf import numpy as np W = tf.Variable([[2,1,8],[1,2,5]], dtype=tf.float32, name ...
随机推荐
- 微信小程序 使用环信聊天工具
当时做微信小程序环信的时候,没有遇到太多的问题,因为找到了一个例子,有兴趣的朋友可以把这个包下载下来看一下,写的超级的号,使用起来也特别简单,appkey需要自己配置,从环信官网https://con ...
- laravel安装Excel安装不上
1.生明版本号 composer require maatwebsite/excel 2.1我的PHP是7.0安装Excel得2.1 2.在composer.json中加入 "maatweb ...
- 【洛谷p1932】A+B A-B A*B A/B A%B Problem
(emmmm) 这道题成功让我见识到了Dev撤回的高端大气上档(dàng)次. A+B A-B A*B A/B A%B Problem[传送门](真是个优秀的高精) 算法:::::::(模板题弄这么费 ...
- selenium 简单粗暴的定位方法
- unitest discover 模板实例
说明:测试用例和主函数分开存放
- LCS(最长公共子序列)问题
例题见挑战程序设计竞赛P56 解释:子序列是从原序列中按顺序(可以跳着)抽取出来的,序列是不连续的,这是其和子串最大的区别: 我们可以定义dp数组为dp[i][j],表示的是s1-si和t1-ti对应 ...
- HDU - 4780费用流
题意:M台机器要生产n个糖果,糖果i的生产区间在(si, ti),花费是k(pi-si),pi是实际开始生产的时间机器,j从初始化到生产糖果i所需的时间Cij,花费是Dij,任意机器从生产糖果i到生产 ...
- Python 向列表中添加元素
向列表中添加元素 1.append tabulation1.append('紫霞') ['大圣', '天蓬', '卷帘', '紫霞', '紫霞', '青霞'] 2.insert tabulation1 ...
- 第一阶段——站立会议总结DAY07
未做,有一些作业比较赶,所以,先搁置了它.
- pip安装kolla-ansible时报错Cannot install 'PyYAML'的解决方法
pip install kolla-ansible --ignore-installed PyYAML