Scrapy学习篇(六)之Selector选择器
当我们取得了网页的response之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,python从网页中提取数据的包很多,常用的有下面的几个:
- BeautifulSoup
它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但是速度上有所欠缺。 - lxml
是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
你可以在scrapy中使用任意你熟悉的网页数据提取工具,但是,scrapy本身也为我们提供了一套提取数据的机制,我们称之为选择器(seletors),他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。下面我们来了解scrapy选择器。
使用选择器
scrapy中调用选择器的方法非常的简单,下面我们从实例中进行学习。
我们还是以博客园首页的信息作为例子,演示使用选择器抓取数据,下图是首页的html信息,我们下面就是抓取标题,链接,阅读数,评论数。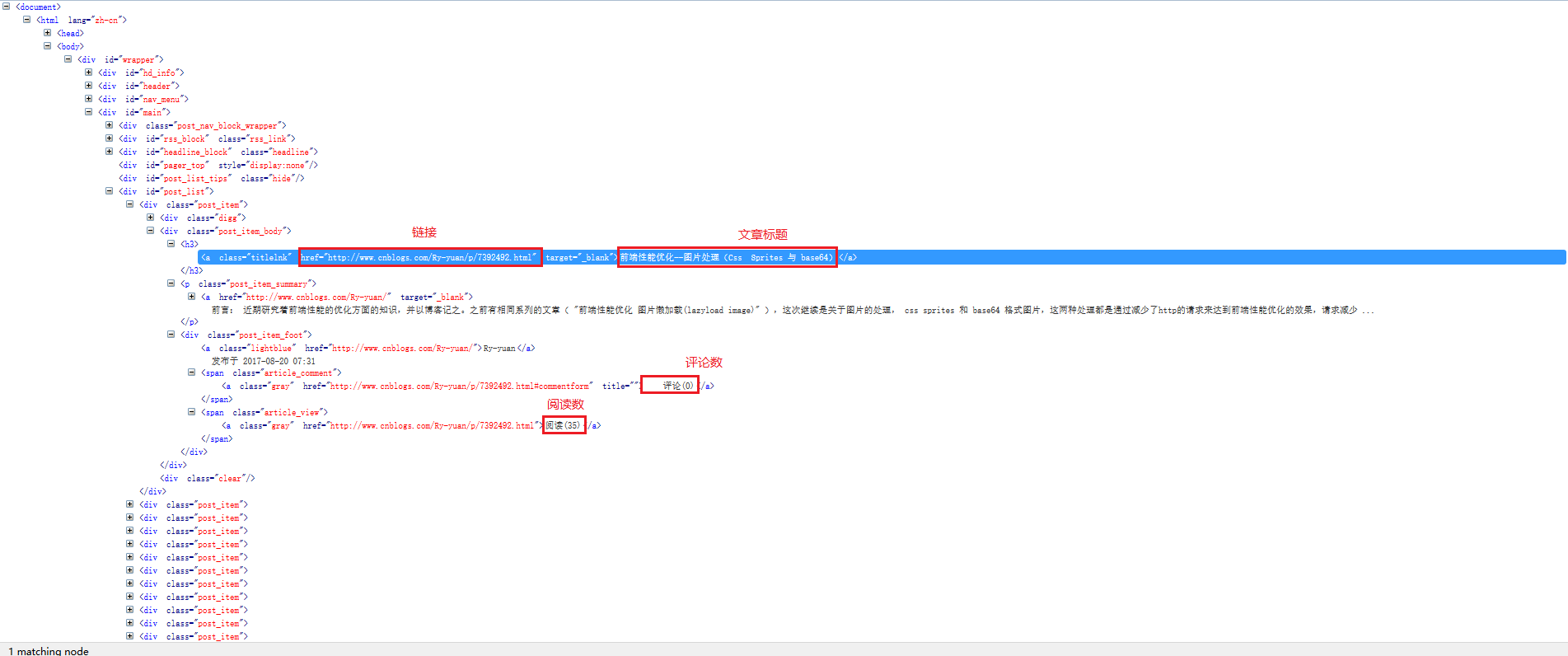
import scrapy
from scrapy.selector import Selector
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
selector = Selector(response=response)
title = selector.xpath('//a[@class="titlelnk"]/text()').extract()
link = selector.xpath('//a[@class="titlelnk"]/@href').extract()
read = selector.xpath('//span[@class="article_comment"]/a/text()').extract()
comment = selector.xpath('//span[@class="article_view"]/a/text()').extract()
print('这是title:',title)
print('这是链接:', link)
print('这是阅读数', read)
print('这是评论数', comment)选择器的使用可以分为下面的三步:
- 导入选择器
from scrapy.selector import Selector - 创建选择器实例
selector = Selector(response=response) - 使用选择器
selector.xpath()或者selector.css()
当然你可以使用xpath或者css中的任意一种或者组合使用,怎么方便怎么来,至于xpath和css语法,你可以去额外学习,仔细观察,你会发现每个选择器最后都有一个extract(),你可以尝试去掉这个看一下,区别在于,当你没有使用extract()的时候,提取出来的内容依然具有选择器属性,简而言之,你可以继续使用里面的内容进行提取下级内容,而当你使用了extract()之后,提取出来的内容就会变成字符串格式了。我们进行多级提取的时候,这会很有用。值得注意的是,选择器提取出来的内容是放在列表里面的,即使没有内容,那也是一个空列表,下面我们运行这个爬虫,你会发现内容已经被提取出来了。
事实上,我们可以完全不用那么麻烦,因为scrapy为我们提供了选择器的简易用法,当我们需要选择器的时候,只要一步就可以了,如下:
import scrapy
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
title = response.xpath('//a[@class="titlelnk"]/text()').extract()
link = response.xpath('//a[@class="titlelnk"]/@href').extract()
read = response.xpath('//span[@class="article_comment"]/a/text()').extract()
comment = response.xpath('//span[@class="article_view"]/a/text()').extract()
print('这是title:', title)
print('这是链接:', link)
print('这是阅读数', read)
print('这是评论数', comment)可以看到,我们直接使用response.xpath()就可以了,并没有导入什么,实例化什么,可以说非常方便了,当然直接response.css()一样可以。
拓展
scrapy为我们提供的选择器还有一些其他的特点,这里我们简单的列举
- extract()
>>> response.xpath('//title/text()') [<Selector (text) xpath=//title/text()>] >>> response.css('title::text') [<Selector (text) xpath=//title/text()>]
前面已经提到了,.xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表,就是说,你依然可以使用里面的元素进行向下提取,因为它还是一个选择器,为了提取真实的原文数据,我们需要调用 .extract() - extract_first()
如果想要提取到第一个匹配到的元素, 可以调用response.xpath('//span[@class="article_view"]/a/text()').extract_first()这样我们就拿到了第一个匹配的数据,当然,我们之前提到了选择器返回的数据是一个列表,那么你当然可以使用response.xpath('//span[@class="article_view"]/a/text()').extract()[0]拿到第一个匹配的数据,这和response.xpath('//span[@class="article_view"]/a/text()')[0].extract()效果是一样的,值得注意的是,如果是空列表,这两种方法的区别就出现了,extract_first()会返回None,而后面的那种方法,就会因列表为空而报错。
除此之外,我们还可以为extract_first()设置默认值,当空列表时,就会返回一个我们设置的值,比如:extract_first(default='not-found')。
结合正则表达式
你会发现,之前我们匹配的阅读数,评论数都会有汉字在里面,如果我们只想提取里面的数字呢,这个时候就可以使用正则表达式和选择器配合来实现,比如下面:
import scrapy
class Cnblog_Spider(scrapy.Spider):
name = "cnblog"
allowed_domains = ["cnblogs.com"]
start_urls = [
'https://www.cnblogs.com/',
]
def parse(self, response):
read = response.xpath(
'//span[@class="article_comment"]/a/text()').re('\d+')
comment = response.xpath(
'//span[@class="article_view"]/a/text()').re('\d+')
print('这是阅读数', read)
print('这是评论数', comment)运行一下,可以看到,效果就出来了。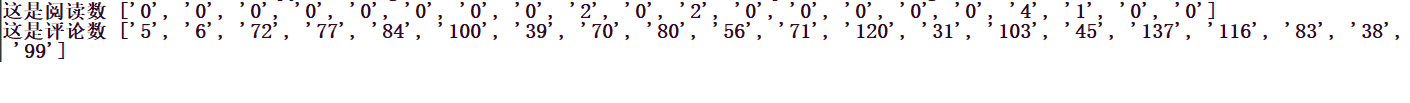
Scrapy学习篇(六)之Selector选择器的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy学习篇(五)之Spiders
Spiders Spider类定义了如何爬取某个网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item).简而言之,Spider就是你定义爬取的动作及分析某个网 ...
- Scrapy学习篇(四)之数据存储
上一篇中,我们简单的实现了toscrapy网页信息的爬取,并存储到mongo,本篇文章信息看看数据的存储.这一篇主要是实现信息的存储,我们以将信息保存到文件和mongo数据库为例,学习数据的存储,依然 ...
- Scrapy学习篇(十二)之设置随机IP代理(IPProxy)
当我们需要大量的爬取网站信息时,除了切换User-Agent之外,另外一个重要的方式就是设置IP代理,以防止我们的爬虫被拒绝,下面我们就来演示scrapy如何设置随机IPProxy. 设置随机IPPr ...
- Scrapy学习篇(十一)之设置随机User-Agent
大多数情况下,网站都会根据我们的请求头信息来区分你是不是一个爬虫程序,如果一旦识别出这是一个爬虫程序,很容易就会拒绝我们的请求,因此我们需要给我们的爬虫手动添加请求头信息,来模拟浏览器的行为,但是当我 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- Scrapy学习篇(一)之框架
概览 在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解.下面是scr ...
- Scrapy学习篇(十三)之scrapy-splash
之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来. 但是,像比如一些购物网站,他们的商品信息都是js加载出来的,并且会有ajax异步加载.像这样的情况,直接使用scrap ...
随机推荐
- 【HDOJ1531】【差分约束+添加超级源点】
http://acm.hdu.edu.cn/showproblem.php?pid=1531 King Time Limit: 2000/1000 MS (Java/Others) Memory ...
- doc 常用命令
★ 查看java环境变量 echo %JAVA_HOME% echo %PATH% echo %CLASSPATH%
- 下面的程序段创建了BufferedReader类的对象in,以便读取本机c盘my文件夹下的文件1.txt。File构造函数中正确的路径和文件名的表示是( )。
下面的程序段创建了BufferedReader类的对象in,以便读取本机c盘my文件夹下的文件1.txt.File构造函数中正确的路径和文件名的表示是( ). ./表示当前项目的路径../表示当 ...
- Go Example--方法
package main import "fmt" //定义结构体 type rect struct { width,height int } //定义结构体指针的方法 func ...
- nginx unit nodejs 模块试用(续)
最新(应该是18 年了)nginx unit 发布了新的版本,对于nodejs 的支持有很大的改进,上次测试过,问题还是 比较多,这次使用新版本在测试下对于nodejs 的支持,以及以前block ...
- 记一次接口504 Gateway Time-out原因及解决方法
今天在刷新公司项目页面时发现有个板块一直刷新不出数据,最后发现接口报错(504 Gateway Time-out) 通过查看代码发现有个sql语句,如下,特别慢 select `vdc1`, ...
- 项目中更新pip 问题。更新后还是老版本
(venv) E:\renyuwang\venv\Scripts>python -m pip install --upgrade pipRequirement already up-to-dat ...
- Unity Blog 学习
The Profiler window https://unity3d.com/cn/learn/tutorials/temas/performance-optimization/profiler-w ...
- PowerDesigner学习 ---- 系列文章
一.PowerDesigner概述(系统分析与建模) 二.项目和框架矩阵 三.企业架构模型 四.业务处理模型 五.概念数据模型(CDM生成LDM,PDM和OOM) 六.物理数据模型(PDM逆向工程) ...
- 我 支持 使用 async await
这篇文章原来的 标题 是 <我 反对 使用 async await>, 但经过后来的一些研究, 发现 async await 是 良性 的, 所以 我把 标题 改成了 <我 支持 使 ...