【Hive学习之一】Hive简介
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
apache-hive-3.1.1
一、简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类sql语句的查询功能;
Hive使用Hql作为查询接口,使用HDFS存储,使用mapreduce计算;Hive的本质是将Hql转化为mapreduce;让非java编程者对hdfs的数据做mapreduce操作
Hive: 数据仓库。与关系型数据库区别:
①数据库可以用在Online的应用中,Hive主要进行离线的大数据分析;
②数据库的查询语句为SQL,Hive的查询语句为HQL;
③数据库数据存储在LocalFS,Hive的数据存储在HDFS;
④Hive执行MapReduce,MySQL执行Executor;
⑤Hive没有索引;
⑥Hive延迟性高;
⑦Hive可扩展性高;
⑧Hive数据规模大;
二、架构
Hive的架构
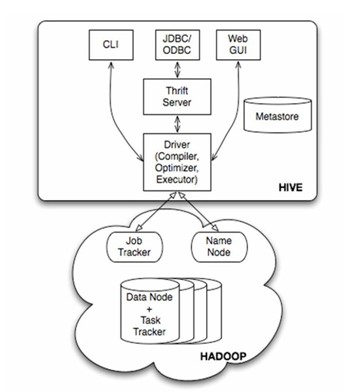
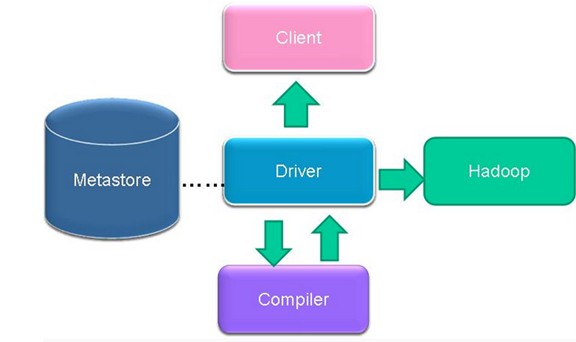
(1)用户接口主要有三个:Hive命令行模式(CLI),最常用模式;Hive Client(如JavaApi方式),对外提供RPC服务 ; Hive Web Interface(HWI):浏览器方式。
(2)Hive运行时将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
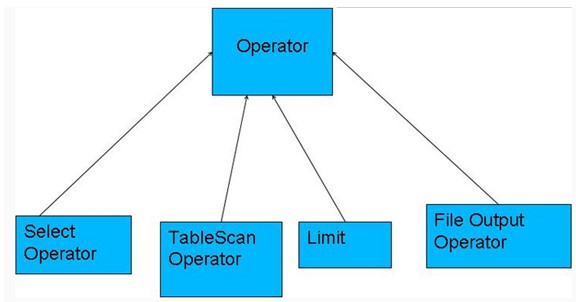
Operator操作符
编译器将一个Hive SQL转换操作符;
操作符是Hive的最小的处理单元;
每个操作符代表HDFS的一个操作或者一道MapReduce作业;
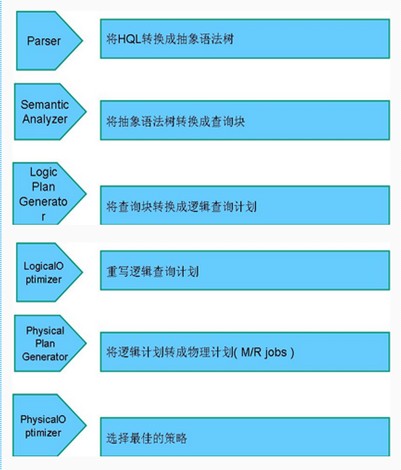
ANTLR词法语法分析工具解析hql
三、搭建
划分的维度:对关系型数据库的访问和管理来划分的
1、local模式:此模式连接到一个In-memory的数据库Derby,一般用于Unit Test。因为在内存不易维护,建议不用。
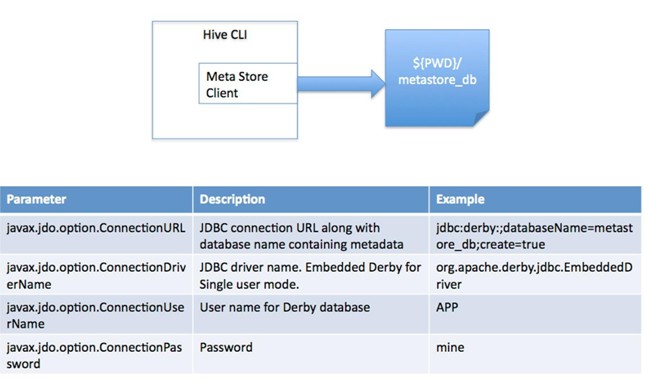
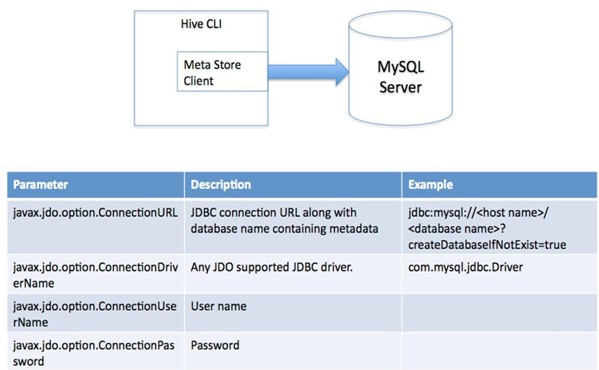
2、单用户模式:通过网络连接到一个数据库中,是最经常使用到的模式;
步骤一:安装mysql
参考:搭建Linux-java web运行环境之二:安装mysql
步骤二:解压apache-hive-3.1.1-bin.tar.gz 并设置环境变量
[root@PCS102 src]# tar -xf apache-hive-3.1.1-bin.tar.gz -C /usr/local
步骤三:修改配置
[root@PCS102 conf]# cd /usr/local/apache-hive-3.1.-bin/conf && ll
total
-rw-r--r--. root root Apr beeline-log4j2.properties.template
-rw-r--r--. root root Oct : hive-default.xml.template
-rw-r--r--. root root Apr hive-env.sh.template
-rw-r--r--. root root Apr hive-exec-log4j2.properties.template
-rw-r--r--. root root Oct : hive-log4j2.properties.template
-rw-r--r--. root root Apr ivysettings.xml
-rw-r--r--. root root Oct : llap-cli-log4j2.properties.template
-rw-r--r--. root root Oct : llap-daemon-log4j2.properties.template
-rw-r--r--. root root Apr parquet-logging.properties
#复制配置文件
[root@PCS102 conf]# cp hive-default.xml.template hive-site.xml
#修改配置hive-site.xml
<!--hive数据上传到HDFS中的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/root/hive_remote/warehouse</value>
</property>
<!--hive是否本地模式-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--hive连接mysql地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://PCS101/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<!--hive连接mysql驱动类-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--hive连接mysql用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--hive连接mysql 密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>
</property> :.,$-1d 删除当前行到倒数第二行
步骤四:拷贝mysql驱动包mysql-connector-java-5.1.32-bin
/usr/local/apache-hive-3.1.1-bin/lib
步骤五:初始化数据库 第一次启动之前需要hive元数据库初始化
[root@PCS102 bin]# /usr/local/apache-hive-3.1.-bin/bin/schematool -dbType mysql -initSchema
未初始化 会报错:
hive> create table test01(id int,age int);
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
步骤六:启动 默认进入命令行
[root@PCS102 bin]# /usr/local/apache-hive-3.1.1-bin/bin/hive
which: no hbase in (/usr/local/jdk1..0_65/bin:/home/cluster/subversion-1.10./bin:/home/cluster/apache-storm-0.9./bin:/usr/local/hadoop-3.1./bin:/usr/local/hadoop-3.1./sbin:/usr/local/apache-hive-3.1.-bin/bin:/usr/local/jdk1..0_80/bin:/home/cluster/subversion-1.10./bin:/home/cluster/apache-storm-0.9./bin:/usr/local/hadoop-3.1./bin:/usr/local/hadoop-3.1./sbin:/usr/local/jdk1..0_80/bin:/home/cluster/subversion-1.10./bin:/home/cluster/apache-storm-0.9./bin:/usr/local/hadoop-3.1./bin:/usr/local/hadoop-3.1./sbin:/usr/local/jdk1..0_80/bin:/home/cluster/subversion-1.10./bin:/home/cluster/apache-storm-0.9./bin:/usr/local/sbin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/openssh/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/apache-hive-3.1.-bin/lib/log4j-slf4j-impl-2.10..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.1./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = e08b6258-e2eb-40af-ba98-87abcb2d1728 Logging initialized using configuration in jar:file:/usr/local/apache-hive-3.1.-bin/lib/hive-common-3.1..jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive .X releases.
hive> create table test01(id int,age int);
OK
Time taken: 1.168 seconds
hive> desc test01;
OK
id int
age int
Time taken: 0.181 seconds, Fetched: row(s)
hive> insert into test01 values(1,23);
Query ID = root_20190125164516_aa852f47-a9b0-4c59--efb557965a5b
Total jobs =
Launching Job out of
Number of reduce tasks determined at compile time:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1548397153910_0001, Tracking URL = http://PCS102:8088/proxy/application_1548397153910_0001/
Kill Command = /usr/local/hadoop-3.1./bin/mapred job -kill job_1548397153910_0001
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 4.96 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 8.01 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1548397153910_0001
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is filtered out by condition resolver.
Moving data to directory hdfs://PCS102:9820/root/hive_remote/warehouse/test01/.hive-staging_hive_2019-01-25_16-45-16_011_1396999443961154869-1/-ext-10000
Loading data to table default.test01
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 8.01 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
Time taken: 23.714 seconds
hive>
查看HDFS:
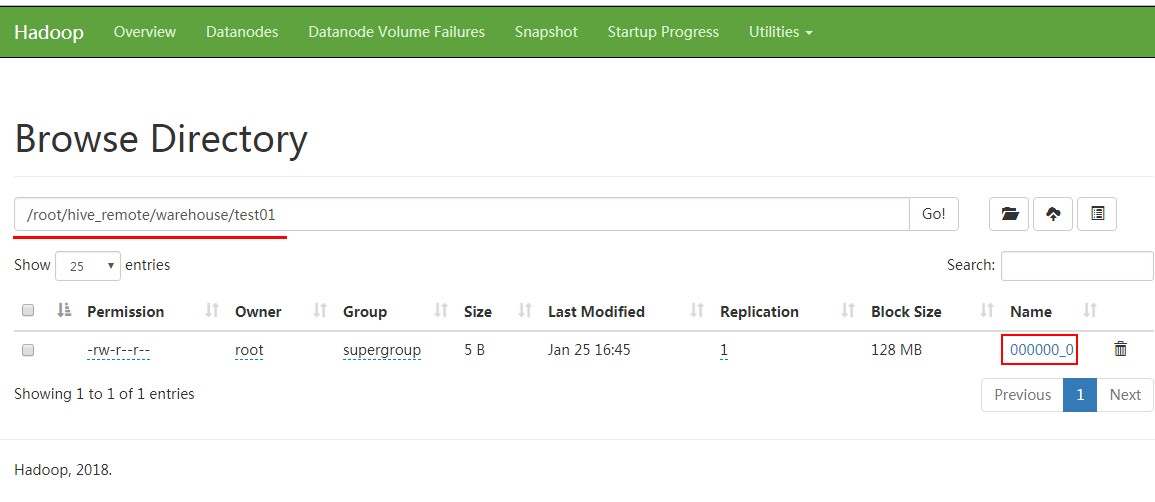
[root@PCS102 bin]# hdfs dfs -cat /root/hive_remote/warehouse/test01/*
123
查看插入数据MR:
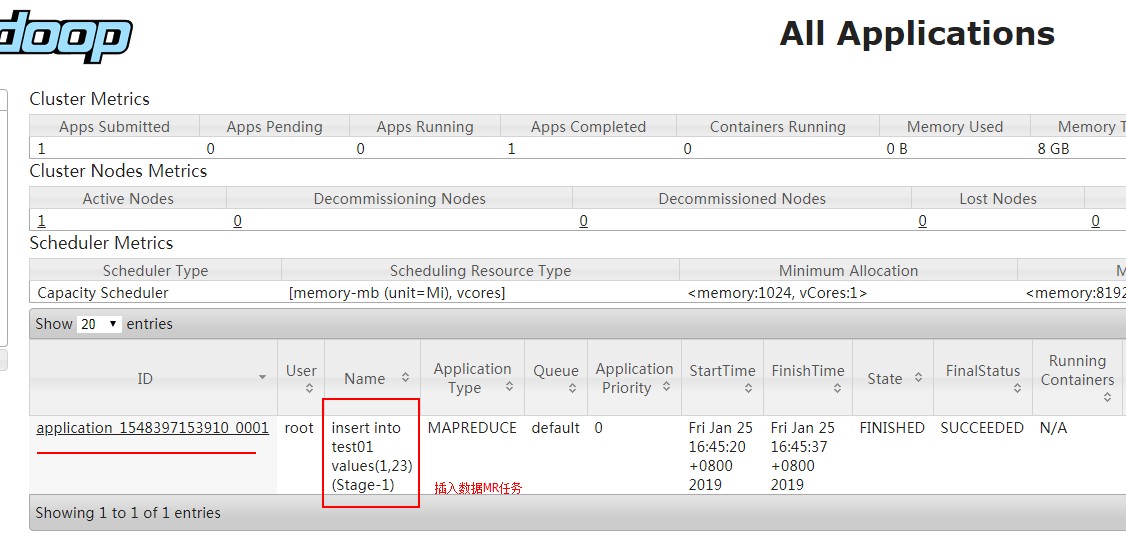
查看mysql:
字段:

表:

步骤七:退出
hive>exit;
或者
hive>quit;
3、远程服务器模式/多用户模式:用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库;
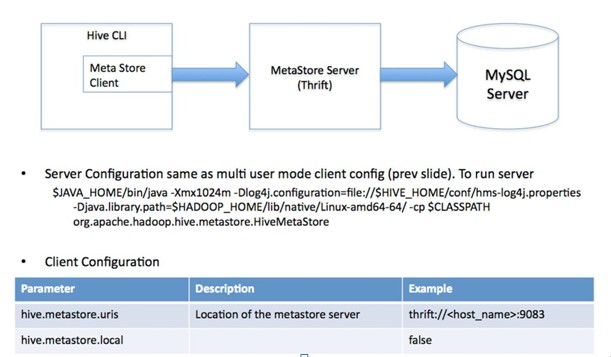
服务端需要启动metastore服务
[root@PCS102 conf]# nohup hive --service metastore &
[root@PCS102 conf]# jps
24657 RunJar
Jps
NameNode
NodeManager
DataNode
JobHistoryServer
RunJar
ResourceManager
SecondaryNameNode
1、服务端和客户端在同一个节点:
PCS101:mysql服务端
PCS102:hive服务端和客户端
PCS102 配置文件:hive-site.xml
<configuration>
<!--hive数据上传到HDFS中的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/root/hive_remote/warehouse</value>
</property>
<!--hive是否本地模式-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--hive连接mysql地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://PCS101/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<!--hive连接mysql驱动类-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--hive连接mysql用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--hive连接mysql 密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--hive meta store client地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://PCS102:9083</value>
</property>
</configuration>
2、服务端和客户端在不同节点(客户端 服务端都要依赖hadoop)
PCS101:mysql服务端
PCS102:hive服务端
PCS103:hive客户端
PCS102:hive服务端配置文件:hive-site.xml
<configuration>
<!--hive数据上传到HDFS中的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/root/hive_remote/warehouse</value>
</property>
<!--hive连接mysql地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://PCS101/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<!--hive连接mysql驱动类-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--hive连接mysql用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--hive连接mysql 密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
PCS103:hive客户端配置文件:hive-site.xml
<configuration>
<!--hive数据上传到HDFS中的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/root/hive_remote/warehouse</value>
</property>
<!--hive是否本地模式-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--hive meta store client地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://PCS102:9083</value>
</property>
</configuration>
问题:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib 下jar包jline-0.9.94.jar 比较老导致 将hive下jline拷贝到hadoop下就可以了
[root@node101 bin]# schematool -dbType mysql -initSchema
// :: WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist
Metastore connection URL: jdbc:mysql://node102/hive_remote?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 1.2.
Initialization script hive-schema-1.2..mysql.sql
[ERROR] Terminal initialization failed; falling back to unsupported
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
at jline.TerminalFactory.create(TerminalFactory.java:)
at jline.TerminalFactory.get(TerminalFactory.java:)
at org.apache.hive.beeline.BeeLineOpts.<init>(BeeLineOpts.java:)
at org.apache.hive.beeline.BeeLine.<init>(BeeLine.java:)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:) Exception in thread "main" java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
at org.apache.hive.beeline.BeeLineOpts.<init>(BeeLineOpts.java:)
at org.apache.hive.beeline.BeeLine.<init>(BeeLine.java:)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:)
【Hive学习之一】Hive简介的更多相关文章
- hive学习(二) hive操作
hive ddl 操作官方手册https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL hive dml 操作官方手 ...
- hive学习(四) hive的函数
1.内置运算符 1.1关系运算符 运算符 类型 说明 A = B 所有原始类型 如果A与B相等,返回TRUE,否则返回FALSE A == B 无 失败,因为无效的语法. SQL使用”=”,不使用”= ...
- hive学习(三) hive的分区
1.Hive 分区partition 必须在表定义时指定对应的partition字段 a.单分区建表语句: create table day_table (id int, content string ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive学习:Hive连接JOIN用例详解
1 准备数据: 1.1 t_1 01 张三 02 李四 03 王五 04 马六 05 小七 06 二狗 1.2 t_2 01 11 03 33 04 44 06 66 07 77 08 88 1.3 ...
- hive学习
大数据的仓库Hive学习 10期-崔晓光 2016-06-20 大数据 hadoop 10原文链接 我们接着之前学习的大数据来学习.之前说到了NoSql的HBase数据库以及Hadoop中 ...
- Hive学习路线图(转)
Hadoophivehqlroadmap学习路线图 1 Comment Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig ...
- 【转】Hive学习路线图
原文博客出自于:http://blog.fens.me/hadoop-hive-roadmap/ 感谢! Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Ha ...
- Hive学习路线图--张丹老师
前言 Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作 ...
- Hive学习 系列博客
原 Hive作业优化 原 Hive学习六:HIVE日志分析(用户画像) 原 Hive学习五--日志案例分析 原 Hive学习三 原 Hive学习二 原 Hive学习一 博客来源,https://blo ...
随机推荐
- Python开发【笔记】:asyncio 定时器
asyncio 定时器 实现: import asyncio class Timer: def __init__(self, timeout, callback): self._timeout = t ...
- Java如何编写Servlet程序
一:Servlet Servlet是Java服务器端编程,不同于一般的Java应用程序,Servlet程序是运行在服务器上的,服务器有很多种,Tomcat只是其中一种. 例子: 在Eclipse中新建 ...
- es组合多个条件进行查询
GET /test_index/_search{ "query": { "bool": { "must": { "match&qu ...
- 1-3-编译Linux内核
1-3-编译Linux内核 1.将Linux源码包拷贝到共享文件夹. 2.进入共享文件夹. 3.解压,命令#tar xvfj Kernel_3.0.8_TQ210_for_Linux_v2.2.tar ...
- Java 基础 常用API (System类,Math类,Arrays, BigInteger,)
基本类型包装类 基本类型包装类概述 在实际程序使用中,程序界面上用户输入的数据都是以字符串类型进行存储的.而程序开发中,我们需要把字符串数据,根据需求转换成指定的基本数据类型,如年龄需要转换成int类 ...
- Linux用户群组权限恢复
/etc/passwd:该文件用于存放用户详细信息:例如 root:x:0:0:root:/root:/bin/bash 用户id 0:就表示root用户 bin下的bash:表示可以登入操作系统 s ...
- tf中计算图 执行流程学习【转载】
转自:https://blog.csdn.net/dcrmg/article/details/79028003 https://blog.csdn.net/qian99/article/details ...
- pycharm tips
批量更改变量名,就在该变量名上shift+f6 ../data 两个点,就是上一级目录,一个点就是当前目录 unhashable type: 'list' 使用set进行去重 a = [1,2,2,3 ...
- Apache服务安全加固
一.账号设置 以专门的用户帐号和用户组运行 Apache 服务. 根据需要,为 Apache 服务创建用户及用户组.如果没有设置用户和组,则新建用户,并在 Apache 配置文件中进行指定. 创建 A ...
- Kotlin 型变 + 星号投影(扯蛋)
Kotlin中的型变: 1. in,顾名思义,就是只能作为传入参数的参数类型 2.out, ..............,就是只能作为返回类型参数的参数类型 星号投影: 我们引用官网的吧-- For ...