python爬虫 ----文章爬虫(合理处理字符串中的\n\t\r........)
import urllib.request
import re
import time num=input("输入日期(20150101000):") def openpage(url):
html=urllib.request.urlopen(url) page=html.read().decode('gb2312') return page def getpassage(page):
passage = re.findall(r'<p class="MsoNormal" align="left">([\s\S]*)</FONT>',str(page)) passage1=re.sub("</?\w+[^>]*>", "", str(passage)) passage2=passage1.replace('\\r', '\r').replace('\\n', ' \n').replace('\\t','\t').replace(']','').replace('[','').replace(' ',' ') print(passage2) with open(load,'a',encoding='utf-8') as f:
f.write("-----------------------------"+"日期"+str(date)+"---------------------------------\n"+passage2+"----------------------------------------------------\n") for i in range(1,32):
date=int(num)+int(i)
print(date)
load="C:/Users/home/Desktop/新建文本文档.txt"
url=("http://www.hbuas.edu.cn/news/xyxw/news_"+str(date)+".htm")
try: page=openpage(url) getpassage(page) print("第"+str(i)+"号有文章,----已下载")
except:
print("第"+str(i)+"号无文章。")
time.sleep(2)
写了一个爬学校新闻网的爬虫,
主要涉及 re正则 urllib.request 文件的写入
在爬取文章时通常会返回很多影响美感的代码
如下:
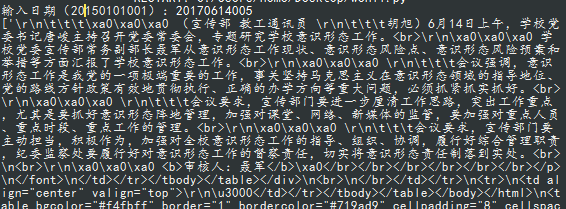
优化:
两次正则
passage = re.findall(r'<p align="left">([\s\S]*)</FONT>',str(page)) #第一次匹配字段
passage1=re.sub("</?\w+[^>]*>", "", str(passage)) # 第二次去掉html标签
替换
passage2=passage1.replace('\\r', '\r').replace('\\n', ' \n').replace('\\t','\t').replace(']','').replace('[','').replace(' ',' ')
效果如下:
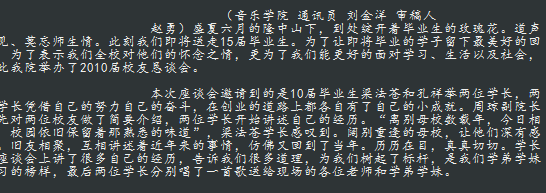
over!
python爬虫 ----文章爬虫(合理处理字符串中的\n\t\r........)的更多相关文章
- python经典算法题:求字符串中最长的回文子串
题目 给定一个字符串 s,找到 s 中最长的回文子串.你可以假设 s 的最大长度为 1000. 示例 1: 输入: "babad" 输出: "bab" 注意: ...
- python 实现查找某个字符在字符串中出现次数,并以字典形式输出
把字符串'aenabsascd'中的字符出现的次数统计出来,并以字典形式输出 方法一: def count_str(str): dic={} for i in str: dic[i]=str.coun ...
- python处理dict转json,字符串中存在空格问题,导致url编码时,存在多余字符
在进行urlencode转换请求的参数时,一直多出一个空格,导致请求参数不正确,多了一个空格,解决方法一种是将dict中key-value键值对的value直接定义为字符串,另一种是value仍然为字 ...
- PYTHON 写函数,计算传入字符串中【数字、字母、空格、以及其他的个数】
def func1(s): al_num = 0 spance_num = 0 digit_num = 0 others_num = 0 for i in s: if i.isdigit(): # i ...
- Python:用正则表达式,提取字符串中的所有中文
import re def clean(line): pattern = re.compile(u'[^\u4e00-\u9fa5]') #中文的范围为\u4e00-\u9fa5 line = re. ...
- Linux c字符串中不可打印字符转换成16进制
本文由 www.169it.com 搜集整理 如果一个C字符串中同时包含可打印和不可打印的字符,如果想将这个字符串写入文件,同时方便打开文件查看或者在控制台中打印出来不会出现乱码,那么可以将字符串中的 ...
- Python基础笔记系列七:字符串定义和访问
本系列教程供个人学习笔记使用,如果您要浏览可能需要其它编程语言基础(如C语言),why?因为我写得烂啊,只有我自己看得懂!! 字符串定义和访问 1.字符串基础 a.字符串可以用单引号.双引号.三引号( ...
- 利用Python编写网络爬虫下载文章
#coding: utf-8 #title..href... str0='blabla<a title="<论电影的七个元素>——关于我对电影的一些看法以及<后会无期 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
随机推荐
- 2018/09/17《涂抹MySQL》【性能优化及诊断】学习笔记(七)
读 第十三章<MySQL的性能优化与诊断> 总结 一说性能优化,整个人都像被打了鸡血一样
- python 随机模块常用命令
import randomprint(random.random()) #用于生成一个0到1之间的随机浮点数print(random.uniform(1,3))# 用于生成一个指定范围内的随机浮点数p ...
- mysql数据库的备份和还原
mysql数据库的备份命令:mysqldump -u root -p 要备份的现有数据库名 > 备份后的sql文件名.sql,例如: mysqldump -u root -p heal ...
- ActiveMQ整合spring、同步索引库
1. Activemq整合spring 1.1. 使用方法 第一步:引用相关的jar包. <dependency> <groupId>org.springframework ...
- 关于hover的一个问题记录
问题描述: 页面显示: 当鼠标移动到其中一个文件夹上面的时候,显示如下: 显示这样的效果的原理是:对于外层元素.collectionsbox添加hover之后,再去取里面的元素,比如说左上角的shar ...
- 关于XML文档的xmlns、xmlns:xsi和xsi:schemaLocation
https://yq.aliyun.com/articles/40353 ************************************* 摘要: 相信很多人和我一样,在编写Spring或者 ...
- IAM:亚马逊访问权限控制
IAM的策略.用户->服务器(仓库.业务体) IAM:亚马逊访问权限控制(AWS Identity and Access Management )IAM使您能够安全地控制用户对 AWS 服务和资 ...
- lsof 命令
[root@localhost ~]# lsof COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME init root cwd DIR , / in ...
- css垂直居中怎么设置?文字上下居中和图片垂直居中
css 居中分css垂直居中和css水平居中,水平居中平时比较常用,这里我们主要讲css上下居中的问题.垂直居中又分为css文字上下居中和css图片垂直居中,下面我们就分别来介绍一下. css文字上下 ...
- SQL存储过程分页
CREATE PROC ZDY_FY(@Pages INT, @pageRow INT) --@Pages第几页 @pageRow每页显示几行 AS BEGIN DECLARE @starNum IN ...