Theano教程:Python的内存管理
在写大型程序时候的一大挑战是如何保证最少的内存使用率。但是在Python中的内存管理是比较简单的。Python显示分配内存,使用引用计数系统管理对象,当指向某一个对象的引用数变为 0 的时候,该对象所占的内存就会被释放。理论上听起来很不错,也很简单,但是在实践中,我们需要知道一些Python内存管理的知识从而让程序在运行过程中能够更加高效地使用内存。其中一个方面我们需要知道的是基本的Python对象所占空间的大小,另一方面我们需要知道的是Python在内部到底是如何管理内存的。
基本对象
一个 int 对象占多大空间呢? C/C++程序员会说它是由具体的机器决定的,可能是32为或者64位,因此它最多占8个字节(一个字节8位)。那么在Python中也是如此吗?
下面写一个函数来揭示出对象占多大的空间(某些情况下需要递归,比如某一个对象类型不是基本的数据类型):
import sys
def show_sizeof(x, level=0):
print "\t" * level, x.__class__, sys.getsizeof(x), x
if hasattr(x, '__iter__'):
if hasattr(x, 'items'):
for xx in x.items():
show_sizeof(xx, level + 1)
else:
for xx in x:
show_sizeof(xx, level + 1)
我们可以用下面的函数调用来观察不同的基本数据类型所占空间大小:
show_sizeof(None)
show_sizeof(3)
show_sizeof(2**63)
show_sizeof(102947298469128649161972364837164)
show_sizeof(918659326943756134897561304875610348756384756193485761304875613948576297485698417)
在64-bit系统和2.7.8 Python上运行的结果:
<type 'NoneType'> 16 None
<type 'int'> 24 3
<type 'long'> 36 9223372036854775808
<type 'long'> 40 102947298469128649161972364837164
<type 'long'> 60 918659326943756134897561304875610348756384756193485761304875613948576297485698417
可以看到None占了16个字节,int 占了24个字节,是64为系统中C的int64_t 的 3 倍,而且是能够被机器识别的整型。长整型(无限制的精确度)用来表示出了大于263 - 1的整数,所占空间最小为36个字节。而且这个所占空间大小会随着算法中整数的大小线性增长。
Python的float是特定实现的,看上去类似于C中double,但是Python中的 float 不会在数据超过8个字节时终止表示:
show_sizeof(3.14159265358979323846264338327950288)
在64为系统输出:
<type 'float'> 24 3.14159265359
可以看到又是C中double类型所占空间(8字节)的3倍.
那么对于字符串呢?
show_sizeof("")
show_sizeof("My hovercraft is full of eels")
在64位系统输出:
<type 'str'> 33
<type 'str'> 62 My hovercraft is full of eels
空字符串占33字节,随着字符串内容增加,所占空间线性增长。
下面测试常用的tuple,list 和 dictionary所占空间大小(均为在64为系统下的输入结果):
show_sizeof([])
show_sizeof([4, "toaster", 230.1])
输出:
<type 'list'> 64 []
<type 'list'> 88 [4, 'toaster', 230.1]
空list占64个字节,而64位系统中的C++ std::list() 只占16个字节,达到了4倍。
对于tuple呢?dictionary?:
show_sizeof({})
show_sizeof({'a':213, 'b':2131})
输出:
<type 'dict'> 272 {}
<type 'dict'> 272 {'a': 213, 'b': 2131}
<type 'tuple'> 64 ('a', 213)
<type 'str'> 34 a
<type 'int'> 24 213
<type 'tuple'> 64 ('b', 2131)
<type 'str'> 34 b
<type 'int'> 24 2131
可以看出,对于字典中的每一个 key/value 对,占64字节,但是注意('a', 213)所占空间是64字节,而 'a' 所占空间是34字节,213 占空间是24字节,所以留出64 -(34+24) = 6字节给key/value本身;另外,我们看到整个字典占272字节,而不是64+64 = 128字节。字典本身是被设计成一个搜索效率高的数据结构,所以会用到必要的额外的空间。如果字典内部采用的是某种树结构,必须考虑到包含每一个值的节点和指向孩子节点的两个指针的空间消耗;如果字典内部采用哈希表实现,我们必须保证有足够的空闲空间从而保证性能。
字典与C++std::map结构对等,而C++的map在创建(空map)时占48个字节, C++空字符串占 8 个字节,整数占4个字节。
观察到了这么多现象,到底是怎么回事?看上去一个空字符串占8个字节还是占37个字节似乎改变不了什么。如果不扩展数据大小,确实如此。我们必须关心的是我们创建多少个对象会到达程序所使用的内存的限制。在实践应用中,这个问题很棘手。要想设计出一个管理内存的好策略,不但需要关心对象所占内存的大小,还需要所创建对象的数量以及这些对象的创建顺序,事实证明这对于Python很重要。一个关键元素就是理解Python是如何在内部分配内存的,也正是下面即将讨论的.
内部内存管理
为了加速内存分配(和重复使用),Python对小型对象使用列表来管理。每个列表包含的对象所占空间大小都很相近:如一个列表包含的对象均占1到8个字节,另一个列表包含的对象均占9到16个字节等。当需要创建一个小型对象时,要么重复使用列表中空闲块,要么分配一块新空间。
事实上,即使一个对象的空间被free了,它做占据的内存空间也不会被返回给Python的全局内存池,而是仅仅被标记为free然后加入到空闲列表。过期的(被消亡)对象的位置空间会在一个新的差不多大小的对象被创建时,进行重复使用,如果没有过期的对象释放的空间存在,那么就直接新分配空间。
如果小型对象的所占内存从未被释放,那么列表所占内存空间就会一直增大,那么内存慢慢就会被这些大量的小型对象占据。
因此,我们应该努力只分配空间给那些有必要的对象,在循环中只创建少量的对象,尽量使用生成器语法。
事实上,列表占据空间的自由增长似乎并不算是一个问题,因为列表所包含的空间仍然允许Python程序进入和使用。但是从操作系统的视角来看,程序所占内存的大小会超过系统分配给Python的总内存的大小。
为了证明上面所述,使用memory_profiler(依赖于 python-psutil包)来证明:
import copy
import memory_profiler #这里加上@profile是来监视具体函数function的内存使用情况
@profile
def function():
x = list(range(1000000)) # allocate a big list
y = copy.deepcopy(x)
del x
return y if __name__ == "__main__":
function()
在Ubuntu上运行:

程序创建了包含1,000,000个int值(1,000,000*12 bytes = ~11.4MB),建立一个对list的引用变量x(1,000,000 * 8 bytes =~ 3.8MB), 总内存使用量大约为15.2MB.然后copy.deepcopy 进行深度拷贝操作和建立新的引用变量y,同样需要占用内存大约15.2MB,所以第8行的内存使用量增加了15.367MB. 注意第 9 行,del x, 内存使用量仅仅减少了3.824MB,这表明del操作只是释放了指向 list 引用变量的内存空间,而不是list中的整数所占内存空间,这些整数值保留在堆中,导致内存占用多了将近11.4MB.
在这个例子中分配了总共大约15.309 + 15.367 - 3.82 = ~26.8MB, 而我们存储一个list只需要大约11.4MB的内存,超出了1倍多! 所以,在编程中的也许我们不注意的地方,就会导致内存占用增长很快!
pickle
pickle是一种标准的把Python对象序列化到文件和以及从文件解序列化出来的方式。它的内存足迹(memory footprint)是什么? 它创建了额外的数据副本还是用一种更加聪明的方式?考虑:
import memory_profiler
import pickle
import random def random_string():
return "".join([chr(64 + random.randint(0, 25)) for _ in xrange(20)]) @profile
def create_file():
x = [(random.random(),
random_string(),
random.randint(0, 2 ** 64))
for _ in xrange(1000000)] pickle.dump(x, open('machin.pkl', 'w')) @profile
def load_file():
y = pickle.load(open('machin.pkl', 'r'))
return y if __name__=="__main__":
create_file()
#load_file()
这个程序用来生成一些pickle 数据和读取pickle 数据(pickle数据的读取在这里注释了,首先没用让读取函数运行),使用memory_profiler,生成pickle数据过程中使用了大量内存:

再看看pickle数据的读取(把上面程序中第23行注释掉,把24行的注释去掉):
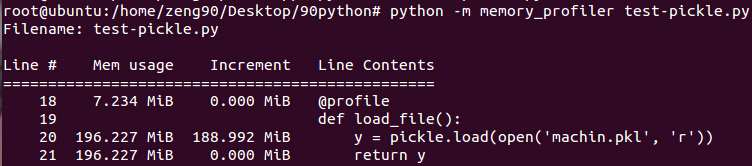
所以,pickle是非常消耗内存的做法,从上面的图看出,在数据的创建时,大约使用127MB内存,而一个pickle.dump操作就要额外使用差不多与数据相当的内存空间(117MB).
在unpickle操作中(即反序列化操作,从pkl中读取数据),看上去效率还好点,虽然确实占用了比原始数据(127MB)大的内存空间(188MB),但是还没到达有超1倍的程度。
总之,涉及pickle的操作应该在对内存容量要求较高的程序中尽量避免。那么,有没有可以替代的选择呢?我们知道pickle保存了数据结构的结构,即将数据原封不动保存起来(不仅仅保存数据,还要保存数据的结构信息),所以我们才能在需要的时候,将数据从pickle文件中恢复出来。但是,并不是所有时候都需要这样用pickle保存,就像上面例子中的list,完全可以用一个基于文本的文件格式按顺序保存里面的元素,没必要用pickle来保存:
import memory_profiler
import random
import pickle def random_string():
return "".join([chr(64 + random.randint(0, 25)) for _ in xrange(20)]) @profile
def create_file():
x = [(random.random(),
random_string(),
random.randint(0, 2 ** 64))
for _ in xrange(1000000) ]
# 这里使用文本来保存数据而不是pickle
f = open('machin.flat', 'w')
for xx in x:
print >>f, xx
f.close() @profile
def load_file():
y = []
f = open('machin.flat', 'r')
for line in f:
y.append(eval(line))
f.close()
return y if __name__== "__main__":
create_file()
#load_file()
建立文件时,内存足迹:
 与上面pickle保存数据对比,可以发现,通过文本保存文件值占用几乎可以忽略的内存。
与上面pickle保存数据对比,可以发现,通过文本保存文件值占用几乎可以忽略的内存。
下面再来看看数据的读取时,内存足迹变化(将30行的代码注释,将31行的注释符去掉):

原始数据127MB,读取时占用内存139MB,和原始数据很接近,多出来的约10MB内存空间是分配给循环中产生的临时变量。
这个例子可以启示我们在处理数据的时候不要首先全部读取数据,然后再处理数据,而是每次读取几项,处理完这几项,释放这几项的空间,然后再读取几项处理,以此类推,这样,之前分配过的内存空间就可以重复使用。比如读取数据到一个Numpy的array中,我们可以先创建一个空array,然后逐行读取数据,逐行填入array,这样大约只需要和数据大小差不多的内存空间。如果使用pickle, 至少要分配2倍于数据大小的内存空间:一次是pickle在load时分配占用,一次是创建存储数据的array.
总结
Python 设计的目标根本上就不同于 C 语言设计的目标。后者是以更加复杂和显示的编程为代价让程序员能够更好地控制程序要做的事,而前者设计的目的是让代码更加迅速并且尽量隐藏细节。尽管听起来不错,但是在生产环境中,忽略执行效率会栽大跟头,所以在Python代码设计过程中,知道哪些代码执行的效率很低,从而尽量避免这种低效率编写对于生产环境来说很重要!
Theano教程:Python的内存管理的更多相关文章
- Objective-C 基础教程第九章,内存管理
目录 Object-C 基础教程第九章,内存管理 前言: 对象生命周期 引用计数 RetainCount1项目例子 对象所有权 访问方法中的保留和释放 自动释放 所有对象放入池中 自动释放池的销毁时间 ...
- python学习笔记10(Python的内存管理)
用这张图激励一下自己,身边也就只有一位全栈数据工程师!!! 32. Python的内存管理 1. 对象的内存使用 对于整型和短字符串对象,一般内存中只有一个存储,多次引用.其他的长字符串和其他对象 ...
- python的内存管理机制
先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲 (1)垃圾回收 (2)引用计数 (3)内存池机制 一.垃圾回收: python不像C++,Java等语言一样,他们可以不用事先声明变量 ...
- day21(1)---python的内存管理
垃圾回收机制: 不能被程序访问到的数据,就称之为垃圾. 引用计数:引用计数是用来记录值的内存地址被记录的次数的 每一次对值地址的引用都可以使得该值的引用计数+1 每一次对值地址的释放都可以使得该值的引 ...
- python的内存管理与垃圾回收机制学习
一.python内存申请: 1.python的内存管理分为六层:最底的两层有OS控制.第三层是调用C的malloc和free等进行内存控制.第四层第五层是python的内存池.最上层使我们接触的直接对 ...
- python的内存管理机制(zz)
本文转载自:http://www.cnblogs.com/CBDoctor/p/3781078.html 先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲 (1)垃圾回收 (2)引用计 ...
- Python的内存管理、命名规则、3个特性讲解
理解变量: 变:现实世界中的状态是会发生改变的 量:衡量/记录现实世界中的状态,让计算机能够像人一样去识别世间万物(例如:一个人的身高.体重等这些信息) 为什么要变量: 程序执行的本质就是一系列状态的 ...
- Python深入06 Python的内存管理
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 语言的内存管理是语言设计的一个重要方面.它是决定语言性能的重要因素.无论是C语言的 ...
- 【转】python的内存管理机制
http://developer.51cto.com/art/201007/213585.htm 内存管理,对于Python这样的动态语言,是至关重要的一部分,它在很大程度上甚至决定了Python的执 ...
随机推荐
- 类加载过程&对象的创建过程
类加载过程 1.JVM发现要使用一个类,首先要到方法区中找:如果找到了,就直接使用,如果没有找到,才会去找这个类的class文件,然后加载: (在找class文件时,是根据classpath配置的地址 ...
- Codeforces Round #420 (Div. 2) A,B,C
A. Okabe and Future Gadget Laboratory time limit per test 2 seconds memory limit per test 256 megaby ...
- hdu 2845 Beans(最大不连续子序列和)
Problem Description Bean-eating is an interesting game, everyone owns an M*N matrix, which is filled ...
- 移动端利用-webkit-box水平垂直居中
首先,必须要在父元素上用display:-webkit-box. 一.box的属性: 1.box-orient 用于父元素,用来确定父容器里子容器的排列方式,是水平还是垂直. horizontal在水 ...
- 【LOJ#10002】喷水装置
题目大意:给定一段区间 [l,r] ,N 条线段,求至少用多少条线段能够覆盖整个区间,不能覆盖输出-1. 题解:每次在起点小于当前位置的线段集合中选择有端点最大的位置作为下一个位置,并更新答案,如果当 ...
- 【模板】Treap
Treap,又称树堆,是一种通过堆性质来维持BST平衡的数据结构.具体体现在对于树上每一个点来说,既有BST维护的值,又有一个堆维护的随机生成的值.维护平衡性的办法是根据堆维护的值的相对大小关系进行左 ...
- 如何在通用权限管理系统中集成log4net日志功能
开发人员都知道,在系统运行中要记录各种日志,自己写一个日志功能,无论是在效率还是功能扩展上来说都不是很好,目前大多用的是第三方的日志系统,其中一个非常有名,用的最多的就是log4net.下面是关于这个 ...
- java 线程栈 & java.lang.StackOverflowError
网上搜索了一下,关于java的线程栈: JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K. JVM的内存,被划分了很多的区域: (来源:http://www.iteye.com/ ...
- BellmanFord 最短路
时间复杂度:O(VE) 最多循环V次,每次循环对每一条边(共E条边)判断是否可以进行松弛操作 最多V次:一个点的最短路,最多包含V-1个点(不包含该点), 如d1->d2->d3-> ...
- 有意思的undefined columns selected,源于read.table和read.csv
输入以下语法时: read.table(site_file,header=T)->data data<-data[which(data[,5]=="ADD"),] 出现 ...