Pytorch 之 backward
首先看这个自动求导的参数:
- grad_variables:形状与variable一致,对于
y.backward(),grad_variables相当于链式法则dz/dx=dz/dy × dy/dx 中的 dz/dy。grad_variables也可以是tensor或序列。 - retain_graph:反向传播需要缓存一些中间结果,反向传播之后,这些缓存就被清空,可通过指定这个参数不清空缓存,用来多次反向传播。
- create_graph:对反向传播过程再次构建计算图,可通过
backward of backward实现求高阶导数。
注意variables 和 grad_variables 都可以是 sequence。对于scalar(标量,一维向量)来说可以不用填写grad_variables参数,若填写的话就相当于系数。若variables非标量则必须填写grad_variables参数。下面结合参考示例来解释一下这个参数怎么用。
先说一下自己总结的一个通式,适用于所有形式:
 对于此式,x的梯度x.grad为
对于此式,x的梯度x.grad为 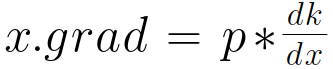
1.scalar标量
注意参数requires_grad=True让其成为一个叶子节点,具有求导功能。

手动求导结果:

代码实现:
import torch as t
from torch.autograd import Variable as v a = v(t.FloatTensor([2, 3]), requires_grad=True) # 注意这里为一维,标量
b = a + 3
c = b * b * 3
out = c.mean()
out.backward(retain_graph=True) # 这里可以不带参数,默认值为‘1’,由于下面我们还要求导,故加上retain_graph=True选项
结果:
a.grad
Out[184]:
Variable containing:
15
18
[torch.FloatTensor of size 1x2]
结果与手动计算一样
backward带参数呢?此时的参数为系数
将梯度置零:
a.grad.data.zero_()
再次求导验证输入参数仅作为系数:
n.backward(torch.Tensor([[2,3]]), retain_graph=True)
结果:(2和3应该分别作为系数相乘)
a.grad
Out[196]:
Variable containing:
30
54
[torch.FloatTensor of size 1x2]
验证了我们的想法。
2.张量
import torch
from torch.autograd import Variable as V m = V(torch.FloatTensor([[2, 3]]), requires_grad=True) # 注意这里有两层括号,非标量
n = V(torch.zeros(1, 2))
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3
求导 :(此时的[[1, 1]]为系数,仅仅作为简单乘法的系数),注意 retain_graph=True,下面我们还要求导,故置为True。
n.backward(torch.Tensor([[1,1]]), retain_graph=True)
结果:
m.grad
Out[184]:
Variable containing:
4 27
[torch.FloatTensor of size 1x2]
将梯度置零:
m.grad.data.zero_()
再次求导验证输入参数仅作为系数:
n.backward(torch.Tensor([[2,3]]))
结果:4,27 × 2,3 =8,81 验证了系数这一说法
m.grad
Out[196]:
Variable containing:
8 81
[torch.FloatTensor of size 1x2]
注意backward参数,由于是非标量,不填写参数将会报错。
3. 另一种重要情形
之前我们求导都相当于是loss对于x的求导,没有接触中间过程。然而对于下面的链式法则我们知道如果知道中间的导数结果,也可以直接计算对于输入的导数。而grad_variables参数在某种意义上就是中间结果。即上面都是z.backward()之类,那么考虑y.backward(b) 或 y.backward(x)是什么意思呢?
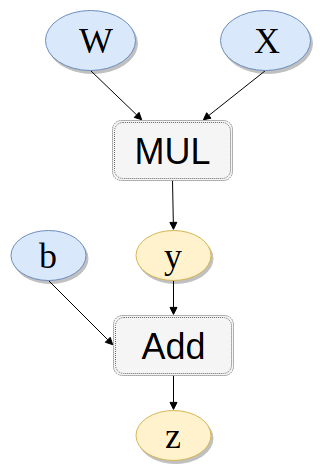
下面给出一个例子解释清楚:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(3), requires_grad=True)
y = Variable(torch.randn(3), requires_grad=True)
z = Variable(torch.randn(3), requires_grad=True)
print(x)
print(y)
print(z) t = x + y
l = t.dot(z)
结果:
# x
Variable containing:
0.9168
1.3483
0.4293
[torch.FloatTensor of size 3] # y
Variable containing:
0.4982
0.7672
1.5884
[torch.FloatTensor of size 3] # z
Variable containing:
0.1352
-0.4037
-0.2425
[torch.FloatTensor of size 3]
在调用 backward 之前,可以先手动求一下导数,应该是:
当我们打印x.grad和y.grad时都是 x.grad = y.grad = z。 当我们打印z.grad 时为 z.grad = t = x + y。这里都没有问题。重要的来了:
先置零:
x.grad.data.zero_()
y.grad.data.zero_()
z.grad.data.zero_()
看看下面这个情况:
t.backward(z)
print(x.grad)
print(y.grad)
print(z.grad)
此时的结果为:
x和y的导数仍然与上面一样为z。而z的导数为0。解释:
t.backward(z): 若求x.grad: z * dt/dx 即为dl/dt × dt/dx=z
若求y.grad: z * dt/dy 即为dl/dt × dt/dy=z
若求z.grad: z * dt/dz 即为dl/dt × dt/dz = z×0 = 0
再验证一下我们的想法:
清零后看看下面这种情况:
t.backward(x)
print(x.grad)
print(y.grad)
print(z.grad)
x和y的导数仍然相等为x。而z的导数为0。解释:
t.backward(x): 若求x.grad: x * dt/dx 即为x × 1 = x
若求y.grad: x * dt/dy 即为x × 1 = x
若求z.grad: x * dt/dz 即为x × 0 = 0
验证成功。
另:k.backward(p)接受的参数p必须要和k的大小一样。这一点也可以从通式看出来。
参考:
PyTorch 的 backward 为什么有一个 grad_variables 参数?
PyTorch 中文网
PyTorch中的backward [转]
Calculus on Computational Graphs: Backpropagation
Pytorch 之 backward的更多相关文章
- ARTS-S pytorch中backward函数的gradient参数作用
导数偏导数的数学定义 参考资料1和2中对导数偏导数的定义都非常明确.导数和偏导数都是函数对自变量而言.从数学定义上讲,求导或者求偏导只有函数对自变量,其余任何情况都是错的.但是很多机器学习的资料和开源 ...
- Pytorch autograd,backward详解
平常都是无脑使用backward,每次看到别人的代码里使用诸如autograd.grad这种方法的时候就有点抵触,今天花了点时间了解了一下原理,写下笔记以供以后参考.以下笔记基于Pytorch1.0 ...
- pytorch autograd backward函数中 retain_graph参数的作用,简单例子分析,以及create_graph参数的作用
retain_graph参数的作用 官方定义: retain_graph (bool, optional) – If False, the graph used to compute the grad ...
- pytorch的backward
在学习的过程中遇见了一个问题,就是当使用backward()反向传播时传入参数的问题: net.zero_grad() #所有参数的梯度清零 output.backward(Variable(t.on ...
- Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析
backward函数 官方定义: torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph ...
- 关于Pytorch中autograd和backward的一些笔记
参考自<Pytorch autograd,backward详解>: 1 Tensor Pytorch中所有的计算其实都可以回归到Tensor上,所以有必要重新认识一下Tensor. 如果我 ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-2-autograd
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 torch.autograd就是为了方 ...
- 深度学习框架PyTorch一书的学习-第一/二章
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 pytorch的设计遵循tensor- ...
- TensorFlow2.0初体验
TF2.0默认为动态图,即eager模式.意味着TF能像Pytorch一样不用在session中才能输出中间参数值了,那么动态图和静态图毕竟是有区别的,tf2.0也会有写法上的变化.不过值得吐槽的是, ...
随机推荐
- 使用netty编写IM通信界面
前驱知识 WebSocket 维基百科: WebSocket是一种在单个TCP连接上进行全双工通信的协议.WebSocket通信协议于2011年被IETF定为标准RFC 6455,并由RFC7936补 ...
- Java NIO -- 阻塞和非阻塞
传统的 IO 流都是阻塞式的.也就是说,当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务.因此,在完成网络通信进行 IO操作 ...
- 面试 -- fragment生命周期
Android 3.0 (Api 11)引入: Fragment具有重用,易适配(平板和手机之间的)优点: 依赖Activity,生命周期受到Activity的生命周期影响: fragment生命周期 ...
- 11:SSM框架下各个层的解释说明
具体见网址:http://blog.csdn.net/lutianfeiml/article/details/51864160
- html中空格字符实体整理
摘要 浏览器总是会截短 HTML 页面中的空格.如果您在文本中写 10 个空格,在显示该页面之前,浏览器会删除它们中的 9 个.如需在页面中增加空格的数量,您需要使用 字符实体. 本篇就单介绍空格的字 ...
- 预测氨基酸替换的致病性及分子机制:MutPred工具的使用
MutPred的功能是预测氨基酸替换后的致病性及其分子机制,旧版本见链接:http://mutpred1.mutdb.org/ 新版本更新为MutPred2,见网站链接:http://mutpred2 ...
- 常用nginx rewrite重定向-跳转实例:
1,将www.myweb.com/connect 跳转到connect.myweb.com rewrite ^/connect$ http://connect.myweb.com permanent; ...
- nginx设置反向代理后端jenklins,页面上的js css文件无法加载
转载 2017年06月14日 22:36:59 8485 问题现象: nginx配置反向代理后,网页可以正常访问,但是页面上的js css文件无法加载,页面样式乱了. (1)nginx配置如下: (2 ...
- Tomcat的配置文件详解
Tomcat的配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Tomcat的配置文件 Tomcat的配置文件默认存放在$CATALINA_HOME/conf目录中, ...
- VUE2.0 饿了吗视频学习笔记(七-终):compute,循环,flex,display:table
一.star组件使用到了computed属性 computed相当于属性的一个实时计算,当对象的某个值改变的时候,会进行实时计算. computed: { starType() { return 's ...