what's the python之模块
正则表达式
首先,我们引入了正则表达式的知识。所谓正则表达式,就是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式本身和python没有什么关系,就是匹配字符串内容的一种规则。这里给了一个非常好用的在线测试工具http://tool.chinaz.com/regex/
谈到正则,就只和字符串相关了。着眼于正则的时候,输入的每一个字都是一个字符串。如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的,直接就可以匹配上。在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
字符组 : 形式为——[字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[ ]表示字符分为很多类,比如数字、字母、标点等等。假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。可以用[0123456789]表达,也可以用[0-9],后者只能从小指到大,即不可以用[9-0]的形式。
|
以下是正则表达式中的所有字符及其用法:
| 元字符 | 匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W |
匹配非字母或数字或下划线或汉字,即除\w能匹配的类型以外的所有类型 |
| \D |
匹配非数字,即除\d能匹配的类型以外的所有类型 |
| \S |
匹配非空白符,即除\s能匹配的类型以外的所有类型 |
| a|b |
匹配字符a或字符b |
| () |
匹配括号内的表达式,也表示一个组 |
| [...] |
匹配字符组中的字符 |
| [^...] |
匹配除了字符组中字符的所有字符,即与[]相反 |
|
. ^ $的用法简介
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 海. | 海燕海东西海娇 |
海燕 海东 海娇 |
匹配所有"海."的字符 |
| ^海. | 海燕海东西海娇 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海东西海娇 | 海娇 | 只匹配结尾的"海.$" |
* + ? { }的用法简介
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符,贪婪匹配 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符,贪婪匹配 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符,贪婪匹配 |
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符,贪婪匹配
|
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李杰 李莲 李二 |
惰性匹配 |
字符集[][^]的用法简介
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李[杰莲英二棍子]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配一个不是"和"的字符任意次 |
| [\d] | 456bdha3 |
4 |
表示匹配任意一个数字,匹配到4个结果 |
| [\d]+ | 456bdha3 |
456 |
表示匹配任意个数字,匹配到2个结果 |
分组 ()与 或 |[^]的用法简介
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
|
转义符 \的用法简介
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成'\\d',那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r'\d'这个概念,此时的正则是r'\\d'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \d | \d | False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配 |
| \\d | \d | True |
转义\之后变成\\,即可匹配 |
| "\\\\d" | '\\d' | True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\d' | r'\d' | True |
在字符串之前加r,让整个字符串不转义 |
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' |
<script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
注:在后面加上?后即转为非贪婪匹配模式,所有匹配长度都取最短
附:非贪婪模式的一个用法—— .*?x 就是取前面任意长度的字符,直到一个x出现
re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match('a', 'abc').group() # 同search,不过仅在字符串开始处进行匹配,如果开始没有匹配到就报错
print(ret)
#结果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)#('evaHegonHyuanH', 3)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果即3
print(next(ret).group()) #查看第二个结果即4
print([i.group() for i in ret]) #查看剩余的结果,以列表的形式打印,即['7', '8', '4']
注意:findall和split的优先级查询:
#1 findall的优先级查询:
import re ret = re.findall('www.(sogo|baidu).com', 'www.baidu.com')
print(ret) # ['baidu'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:sogo|baidu).com', 'www.baidu.com')
print(ret) # ['www.baidu.com'] #2 split的优先级查询
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
下面举几个练习的栗子,需要了解,为了变得更牛逼出去更好的装逼最好还是掌握:
1、匹配标签
import re
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
#还可以在分组中利用?<name>的形式给分组起名字
#获取的匹配结果可以直接用group('名字')拿到对应的值
print(ret.group('tag_name')) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
#如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group(1))
print(ret.group()) #结果 :<h1>hello</h1>
2、匹配整数
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '2', '60', '40', '35', '5', '4', '3'] ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '-2', '60', '', '5', '-4', '3'] ret.remove("")
print(ret) #['1', '-2', '60', '5', '-4', '3'] ret=re.findall(r'(-?\d+\.\d*)|-?\d+','1-2*(60+(-40.35/5)-(-4*3))')
print(ret)#['', '', '', '-40.35', '', '', ''] ret=re.findall(r'-?\d+\.\d*|-?\d+','1-2*(60+(-40.35/5)-(-4*3))')
print(ret)#['1', '-2', '60', '-40.35', '5', '-4', '3']
3、数字匹配
1、 匹配一段文本中的每行的邮箱
http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、
一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整数
4、爬虫练习
import requests import re
import json def getPage(url): response=requests.get(url)
return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num
response_html=getPage(url)
ret=parsePage(response_html)
print(ret)
f=open("move_info7","a",encoding="utf8") for obj in ret:
print(obj)
data=json.dumps(obj,ensure_ascii=False)
f.write(data+"\n") if __name__ == '__main__':
count=0
for i in range(10):
main(count)
count+=25
关于正则的知识目前就到这里,下面要说有关模块的知识
what's the 是模块?
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用。
模块的导入应该在程序的起始位置。格式为import +模块名
首先我们学了re模块,re模块与正则表达式息息相关,关于re模块的使用,在上文正则表达式中就有提及,即findall、search和match的使用方法,这里不做赘述。
然后我们来看看关于collection模块。
collection模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
下面我们来详细介绍一下这5种数据类型:
namedtuple:主要用在坐标上表示,如表示一个点或者一个圆
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(1, 2)
p.x
p.y #表示圆
#namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque:
因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
print(q)#['y', 'a', 'b', 'c', 'x']
注:deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict:使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。如果要保持Key的顺序,可以用OrderedDict
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])# dict的Key是无序的
print(d)#{'a': 1, 'c': 3, 'b': 2} od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])# OrderedDict的Key是有序的
print(od)#OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注:OrderedDict的Key会按照插入的顺序排列,不是按照Key本身排序
defaultdict:使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict
from collections import defaultdict
dd=defaultdict(lambda :'N/A')#即key不存在时返回设置的默认值
dd['k1']='abc'
print(dd['k1'])#abc
print(dd['k2])#N/A
拿defaultdict举个小栗子:
#有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
#即: {'k1': 大于66 , 'k2': 小于66} #利用字典的解决方式:
l= [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
for value in l:
if value>66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value] #利用defaultdict的解决方法:
from collections import defaultdict l= [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in l:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
Counter:Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。
c = Counter('abcdeabcdabcaba')
print c
#Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
时间模块
在Python中,通常有这三种方式来表示时间:时间戳(timestamp)、元组(struct_time)、格式化的时间字符串(Format String)
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String):表现形式为 ‘1999-12-06’,下文会详细介绍
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天和是否是夏令时)
注:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 61 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周日) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
import time
#时间戳
print(time.time())#1502179789.9325476
#时间字符串,%都有对应的意思
print(time.strftime('%Y-%m-%d %X'))#2017-08-08 16:09:49
#时间元祖
print(time.localtime())#time.struct_time(tm_year=2017, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=9, tm_sec=49, tm_wday=1, tm_yday=220, tm_isdst=0)
有关于时间字符串中的格式化符号,具体如下:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身 python中时间日期格式化符号:
几种格式之间的转换方式如下图:
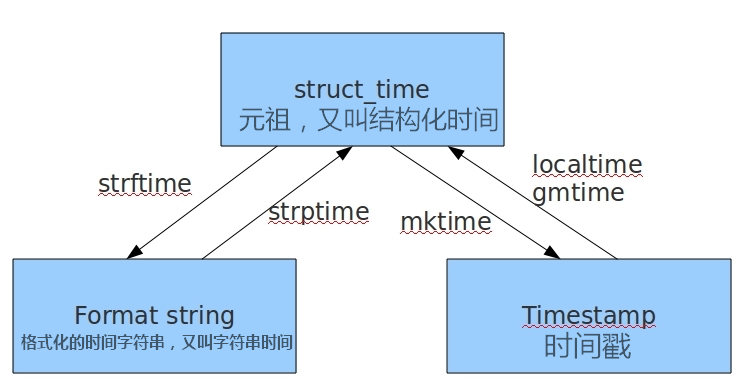
具体方法如下:
#时间戳转化为结构化时间(元祖)-->time.gmtime() time.localtime()
print(time.gmtime())#UTC时间,即格林尼治时间,与英国伦敦当地时间一致
print(time.localtime())#当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
#如果括号内有参数,则输出的是参数所代表的时间
print(time.gmtime(1500000000))#time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
print(time.localtime(1500000000))#time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间(元祖)转化为时间戳-->time.mktime(结构化的时间)
print(time.mktime(time.localtime()))#1502180872.0 #结构化时间(元祖)转换为字符串时间(格式化)-->time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则现实当前时间
print(time.strftime('%Y-%m-%d %X'))#2017-08-08 16:30:16
print(time.strftime("%Y-%m-%d %X",time.localtime(1500000000)))#2017-07-14 10:40:00 #字符串时间(格式化)转化为结构化时间(元祖)-->time.strptime(时间字符串,字符串对应格式)
print(time.strptime("2017-03-16","%Y-%m-%d"))#time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
print(time.strptime("07/24/2017","%m/%d/%Y"))#time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
另外还有一种特别的转换方式,如下图:

具体方法如下:
#结构化时间(元祖)转化为%a %b %d %H:%M:%S %Y串-->time.asctime(结构化时间),如果不传参数,直接返回当前时间的格式化串
print(time.asctime())#Tue Aug 8 16:47:55 2017
print(time.asctime(time.localtime(1500000000)))#Tue Aug 8 16:47:55 2017 #%a %d %d %H:%M:%S %Y串转化为结构化时间-->time.ctime(时间戳),如果不传参数,直接返回当前时间的格式化串
print(time.ctime())#Tue Aug 8 16:49:54 2017
print(time.ctime(1500000000))#Fri Jul 14 10:40:00 2017
random模块
random模块的作用就是随机,可随机生成整数、小数、字母,主要的应用方式是生成验证码。
import random
print(random.random())#随机生成0-1之间的小数
print(random.uniform(1,3))#随机生成1-3之间的小数
#
# 生成四个随机整数:
l = []
l.append(str(random.randint(0,9)))
l.append(str(random.randint(0,9)))
l.append(str(random.randint(0,9)))
l.append(str(random.randint(0,9)))
print(''.join(l))#随机四个数,如4041
print(l)#随机四个数组成的列表,如['4', '0', '4', '1'] print(random.randint(1000,9999))#随机生成1000-9999之间的整数,也可以视为给了四个随机整数的一种方法
print(random.randrange(1,7,2))#也可以使用步距 ret = random.choice([1,2,'b',4,'a',6])
print(ret)#随机从列表的元素中取出一个
ret = random.sample([1,2,'b',4,'a',6],3)
print(ret)#随机从列表的元素中取出三个 l = list(range(100))
random.shuffle(l)#随机打乱l中的顺序,
print(l)
random模块的一个重要应用场景是生成验证码,下面举一个栗子:
#写一个验证码,首先要有数字,其次要有字母,一共4位,可以重复
new_num_l = list(map(str,range(10))) #['0','1'...'9']
# alph_l = [] #用来存字母
# for i in range(65,91):#查询ascii码得到英文字母A-Z对应的数字为65-90
# alph = chr(i)
# alph_l.append(alph) #['A'..'Z']
alph_l = [chr(i) for i in range(65,91)] #列表推导式
new_num_l.extend(alph_l)
Alph_l = [chr(i) for i in range(97,124)]
new_num_l.extend(Alph_l)
# ret_l = [] #存生成的随机数字或字母
# for i in range(4):
# ret_l.append(random.choice(new_num_l))
ret_l = [random.choice(new_num_l) for i in range(4)]
#ret_l中有4个元素
# ret = random.sample(new_num_l,4)
print(''.join(ret_l)) #高级方法:
def myrandom():
new_num_l = list(map(str,range(10)))
alph_l = [chr(i) for i in range(65,91)] #列表推导式
Alph_l = [chr(i) for i in range(97,124)]
new_num_l.extend(alph_l)
new_num_l.extend(Alph_l)
ret_l = [random.choice(new_num_l) for i in range(4)]
return ''.join(ret_l)
print(myrandom())
os模块
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
所有关于os模块的方法
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。
>>> os.path.normcase('c:/windows\\system32\\')
'c:\\windows\\system32\\' 规范化路径,如..和/
>>> os.path.normpath('c://windows\\System32\\../Temp/')
'c:\\windows\\Temp' >>> a='/Users/jieli/test1/\\\a1/\\\\aa.py/../..'
>>> print(os.path.normpath(a))
/Users/jieli/test1
os路径处理
#方式一:推荐使用
import os
#具体应用
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一级
os.pardir,
os.pardir
))
sys.path.insert(0,possible_topdir) #方式二:不推荐使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys模块
sys模块是与python解释器交互的一个接口
sys.argv # 命令行参数List,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解释程序的版本信息
sys.maxint # 最大的Int值
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform # 返回操作系统平台名称
序列化模块
将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
- 字符串str——通过反序列化——数据结构
- 数据结构——通过序列化——字符串str
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?
现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。
但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。
你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢?
没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串,
但是你要怎么把一个字符串转换成字典呢?
聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。
eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
BUT!强大的函数有代价。安全性是其最大的缺点。
想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
而使用eval就要担这个风险。
所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
注意事项
序列化的目的
Json模块是序列化模块的一种,提供了四个功能:dumps、dump、loads、load,下面是具体功能:
#dumps和loads的用法
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}] #dump和load的用法
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close() f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
pickle模块也是序列化的一种,它与json极其相似,甚至说比json还要厉害。
json是用于字符串 和 python数据类型间进行转换,pickle是用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表... 还可以把python中任意的数据类型序列化)
注:这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。如果我们将一个字典或者列表序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了。所以,如果你序列化的内容是列表或者字典,非常推荐使用json模块。但如果出于某种原因你不得不序列化其他的数据类型,而未来还会用python对这个数据进行反序列化的话,那么就可以使用pickle。
这里对pickle模块的用法进行说明:
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic)
print(dic2) #字典 import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close() f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time.tm_year)
shelve模块
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
import shelve
f = shelve.open('shelve_file')
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close() import shelve
f1 = shelve.open('shelve_file')
existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing)
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
import shelve
f = shelve.open('shelve_file', flag='r')
existing = f['key']
f.close()
print(existing)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
import shelve
f1 = shelve.open('shelve_file')
print(f1['key'])
f1['key']['new_value'] = 'this was not here before'
f1.close() f2 = shelve.open('shelve_file', writeback=True)
print(f2['key'])
f2['key']['new_value'] = 'this was not here before'
f2.close()
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
hashlib模块
hashlib模块的功能是提供了常见的摘要算法,如MD5,SHA1,SHA256,SHA512等等
那么,什么是摘要算法呢?摘要算法就是可以把任意长度的数据转换为固定长度的字符串(通常用16进制的字符串表示)。摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过,也可以用来加密文件。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
这里以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib obj = hashlib.md5()
obj.update('what is your name?')
print md5.hexdigest() 计算结果如下:
d26a53750bc40b38b65a520292f69306 #如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
obj= hashlib.md5()
obj.update('hello,my name is jack')
obj.update('what is your name')
obj.update('nice to meet you')
obj.update('goodbye')
print md5.hexdigest()
#其结果与将所有的话合成一句话后调用摘要算法的结果完全一样
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1()
sha1.update('you motherfuker ')
sha1.update('oh shit,get out of here!')
print sha1.hexdigest()
摘要算法的一大应用就是将文件进行加密。
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中。如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5。
但是如果你的口令设置的过于简单比如‘123’,‘abc’之类的,攻击者可以实现算出这些值的摘要,然后来进行比对,一旦有用户的口令简单到被黑客猜中了,就会收到攻击。所以这就是为什么都推荐大家将密码设置的相对复杂的原因,诸如123、888、生日之类的尽量避免。
当然啦,为了保护这些脑回路简单的用户的安全,网站的程序员在编码时也会对考虑到这些问题并采取相应的措施。一般是通过对原始口令加一个复杂字符串来实现,俗称“加盐”。
import hashlib sha1 = hashlib.sha1(‘i am the salt’)#在初始位置加个东西,每个人的口令都会加上这一串,从而起到复杂化的作用,俗称‘加盐’
sha1.update('you motherfuker ')
sha1.update('oh shit,get out of here!')
print sha1.hexdigest()
经过加盐处理的MD5口令,只要‘盐’不被黑客知道,即使用户输入简单口令,就很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
注:摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
来看一个好多软件的常见文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
接下来我们用python生成一个这样的文档
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '',
'Compression': 'yes',
'CompressionLevel': '',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'','ForwardX11':'no'}
with open('example.ini', 'w') as configfile:
config.write(configfile)
查找文件
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read('example.ini')
print(config.sections()) # ['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print('bitbucket.org' in config) # True
print(config['bitbucket.org']["user"]) # hg
print(config['DEFAULT']['Compression']) #yes
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org>
for key in config['bitbucket.org']: # 注意,有default会默认default的键
print(key)
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
增删改操作
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('yuan')
config.remove_section('bitbucket.org')
config.remove_option('topsecret.server.com',"forwardx11")
config.set('topsecret.server.com','k1','')
config.set('yuan','k2','')
config.write(open('new2.ini', "w"))
what's the python之模块的更多相关文章
- Python标准模块--threading
1 模块简介 threading模块在Python1.5.2中首次引入,是低级thread模块的一个增强版.threading模块让线程使用起来更加容易,允许程序同一时间运行多个操作. 不过请注意,P ...
- Python的模块引用和查找路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于“模块”这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译型的语言,比如C#中 ...
- Python Logging模块的简单使用
前言 日志是非常重要的,最近有接触到这个,所以系统的看一下Python这个模块的用法.本文即为Logging模块的用法简介,主要参考文章为Python官方文档,链接见参考列表. 另外,Python的H ...
- Python标准模块--logging
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- python基础-模块
一.模块介绍 ...
- python 安装模块
python安装模块的方法很多,在此仅介绍一种,不需要安装其他附带的pip等,python安装完之后,配置环境变量,我由于中英文分号原因,环境变量始终没能配置成功汗. 1:下载模块的压缩文件解压到任意 ...
- python Queue模块
先看一个很简单的例子 #coding:utf8 import Queue #queue是队列的意思 q=Queue.Queue(maxsize=10) #创建一个queue对象 for i in ra ...
- python logging模块可能会令人困惑的地方
python logging模块主要是python提供的通用日志系统,使用的方法其实挺简单的,这块就不多介绍.下面主要会讲到在使用python logging模块的时候,涉及到多个python文件的调 ...
- Python引用模块和查找模块路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于"模块"这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译 ...
- Python Paramiko模块与MySQL数据库操作
Paramiko模块批量管理:通过调用ssh协议进行远程机器的批量命令执行. 要使用paramiko模块那就必须先安装这个第三方模块,仅需要在本地上安装相应的软件(python以及PyCrypto), ...
随机推荐
- android 中文api
http://www.embeddedlinux.org.cn/androidapi/
- [Python] 动态函数调用(通过函数名)
2018-04-09 update 利用python中的内置函数 eval() ,函数说明: def eval(*args, **kwargs): # real signature unknown & ...
- SpringBoot自定义错误页面,SpringBoot 404、500错误提示页面
SpringBoot自定义错误页面,SpringBoot 404.500错误提示页面 SpringBoot 4xx.html.5xx.html错误提示页面 ====================== ...
- 【GIS】Vue、Leaflet、highlightmarker、bouncemarker
感谢: https://github.com/brandonxiang/leaflet.marker.highlight https://github.com/maximeh/leaflet.boun ...
- Elasticsearch 学习之携程机票ElasticSearch集群运维驯服记(强烈推荐)
转自: https://mp.weixin.qq.com/s/wmSTyIGCVhItVNPHcH7nsA 一.整体架构 为什么采用ES作为搜索引擎呢?在做任何事情的时候,不要一上来就急着了解怎么做这 ...
- [原]NTP时间服务器简单设置
====server edit /etc/ntp.conf 添加 server 127.127.1.0 fudge 127.127.1.0 stratum 1 fudge 127.127.1.0 ...
- 使用Python往手机发送短信(基于twilio模块)
官网是https://www.twilio.com twilio的一句话介绍——提供SDK帮你连接世界上所有人,你可以很方便的调用他们提供的接口来给指定手机发短信,打电话. 首先在twilio的官网注 ...
- POJ 3635 - Full Tank? - [最短路变形][手写二叉堆优化Dijkstra][配对堆优化Dijkstra]
题目链接:http://poj.org/problem?id=3635 题意题解等均参考:POJ 3635 - Full Tank? - [最短路变形][优先队列优化Dijkstra]. 一些口胡: ...
- [No0000159]C# 7 中的模范和实践
关键点 遵循 .NET Framework 设计指南,时至今日,仍像十年前首次出版一样适用. API 设计至关重要,设计不当的API大大增加错误,同时降低可重用性. 始终保持"成功之道&qu ...
- React组件中的key
React组件中的key 一.key的作用 react中的key属性,它是一个特殊的属性,它是出现不是给开发者用的(例如你为一个组件设置key之后不能获取组件的这个key props),而是给reac ...