[No0000FD]C# 正则表达式
正则表达式 是一种匹配输入文本的模式。.Net 框架提供了允许这种匹配的正则表达式引擎。模式由一个或多个字符、运算符和结构组成。
定义正则表达式
下面列出了用于定义正则表达式的各种类别的字符、运算符和结构。
- 字符转义
- 字符类
- 定位点
- 分组构造
- 限定符
- 反向引用构造
- 备用构造
- 替换
- 杂项构造
字符转义
正则表达式中的反斜杠字符(\)指示其后跟的字符是特殊字符,或应按原义解释该字符。
|
转义字符表达式 |
描述,注释 |
模式,提取表达式 |
匹配,要提取的文本与提取结果 |
|
\a |
与报警 (bell) 符 \u0007 匹配。 |
\a |
"Warning!" + '\u0007' 中的 "\u0007" |
|
\b |
在字符类中,与退格键 \u0008 匹配。 |
[\b]{3,} |
"\b\b\b\b" 中的 "\b\b\b\b" |
|
\t |
与制表符 \u0009 匹配。 |
(\w+)\t |
"Name\tAddr\t" 中的 "Name\t" 和 "Addr\t" |
|
\r |
与回车符 \u000D 匹配。(\r 与换行符 \n 不是等效的。) |
\r\n(\w+) |
"\r\nHello\nWorld." 中的 "\r\nHello" |
|
\v |
与垂直制表符 \u000B 匹配。 |
[\v]{2,} |
"\v\v\v" 中的 "\v\v\v" |
|
\f |
与换页符 \u000C 匹配。 |
[\f]{2,} |
"\f\f\f" 中的 "\f\f\f" |
|
\n |
与换行符 \u000A 匹配。 |
\r\n(\w+) |
"\r\nHello\nWorld." 中的 "\r\nHello" |
|
\e |
与转义符 \u001B 匹配。 |
\e |
"\x001B" 中的 "\x001B" |
|
\ nnn |
使用八进制表示形式指定一个字符(nnn 由二到三位数字组成)。 |
\w\040\w |
"a bc d" 中的 "a b" 和 "c d" |
|
\x nn |
使用十六进制表示形式指定字符(nn 恰好由两位数字组成)。 |
\w\x20\w |
"a bc d" 中的 "a b" 和 "c d" |
|
\c X \c x |
匹配 X 或 x 指定的 ASCII 控件字符,其中 X 或 x 是控件字符的字母。 |
\cC |
"\x0003" 中的 "\x0003" (Ctrl-C) |
|
\u nnnn |
使用十六进制表示形式匹配一个 Unicode 字符(由 nnnn 表示的四位数)。 |
\w\u0020\w |
"a bc d" 中的 "a b" 和 "c d" |
|
\ |
在后面带有不识别的转义字符时,与该字符匹配。 |
\d+[\+-x\*]\d+ |
"(2+2) * 3*9" 中的 "2+2" 和 "3*9" |
static void Main(string[] args)
{
Console.WriteLine(@"\a:");
Console.WriteLine(Regex.IsMatch("Warning!" + '\u0007', @"\a"));
foreach (var match in Regex.Matches("Warning!" + '\u0007', @"\a"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\b:");
Console.WriteLine(Regex.IsMatch("\b\b\b\b", @"[\b]{3,}"));
foreach (var match in Regex.Matches("\b\b\b\b", @"[\b]{3,}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\t:");
Console.WriteLine(Regex.IsMatch("Name\tAddr\t", @"(\w+)\t"));
foreach (var match in Regex.Matches("Name\tAddr\t", @"(\w+)\t"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\r:");
Console.WriteLine(Regex.IsMatch("\r\nHello\nWorld.", @"\r\n(\w+)"));
foreach (var match in Regex.Matches("\r\nHello\nWorld.", @"\r\n(\w+)"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\v:");
Console.WriteLine(Regex.IsMatch("\v\v\v", @"[\v]{2,}"));
foreach (var match in Regex.Matches("\v\v\v", @"[\v]{2,}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\f:");
Console.WriteLine(Regex.IsMatch("\f\f\f", @"[\f]{2,}"));
foreach (var match in Regex.Matches("\f\f\f", @"[\f]{2,}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\n:");
Console.WriteLine(Regex.IsMatch("\r\nHello\nWorld.", @"\r\n(\w+)"));
foreach (var match in Regex.Matches("\r\nHello\nWorld.", @"\r\n(\w+)"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\e:");
Console.WriteLine(Regex.IsMatch("\x001B", @"\e"));
foreach (var match in Regex.Matches("\x001B", @"\e"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\ nnn:");
Console.WriteLine(Regex.IsMatch("a bc d", @"\w\040\w"));
foreach (var match in Regex.Matches("a bc d", @"\w\040\w"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\x nn:" );
Console.WriteLine(Regex.IsMatch("a bc d", @"\w\x20\w"));
foreach (var match in Regex.Matches("a bc d", @"\w\x20\w"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\c X \c x:");
Console.WriteLine(Regex.IsMatch("\x0003", @"\cC"));
foreach (var match in Regex.Matches("\x0003", @"\cC"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\u nnnn:" );
Console.WriteLine(Regex.IsMatch("a bc d", @"\w\u0020\w"));
foreach (var match in Regex.Matches("a bc d", @"\w\u0020\w"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\:");
Console.WriteLine(Regex.IsMatch("(2+2) * 3*9", @"\d+[\+-x\*]\d+"));
foreach (var match in Regex.Matches("(2+2) * 3*9", @"\d+[\+-x\*]\d+"))
{
Console.WriteLine(match);
}
Console.ReadKey();
}
\a:
True \b:
True \t:
True
Name
Addr
\r:
True Hello
\v:
True \f:
True \n:
True Hello
\e:
True \ nnn:
True
a b
c d
\x nn:
True
a b
c d
\c X \c x:
True \u nnnn:
True
a b
c d
\:
True
+
*
字符类
字符类与一组字符中的任何一个字符匹配。(通则:一般情况下\x与\X的关系是\X一般表示非的含义)。
|
字符类表达式 |
描述,注释 |
模式,提取表达式 |
匹配,要提取的文本与提取结果 |
|
[character_group] |
匹配 character_group 中的任何单个字符。 默认情况下,匹配区分大小写。 |
[mn] |
"mat" 中的 "m","moon" 中的 "m" 和 "n" |
|
[^character_group] |
非:与不在 character_group 中的任何单个字符匹配。 默认情况下,character_group 中的字符区分大小写。 |
[^aei] |
"avail" 中的 "v" 和 "l" |
|
[ first - last ] |
字符范围:与从 first 到 last 的范围中的任何单个字符匹配。 |
[a-eM-N0-9] |
Name!@#$1 中的 N,a,e,1 |
|
. |
通配符:与除 \n 之外的任何单个字符匹配。 若要匹配原意句点字符(. 或 \u002E),您必须在该字符前面加上转义符 (\.)。 |
a.e |
"have" 中的 "ave", "mate" 中的 "ate" |
|
\p{ name } |
与 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配。 |
\p{Lu} |
"City Lights" 中的 "C" 和 "L" |
|
\P{ name } |
与不在 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配。 |
\P{Lu} |
"City" 中的 "i"、 "t" 和 "y" |
|
\w |
与任何单词字符匹配。 |
\w |
"Room#1" 中的 "R"、 "o"、 "m" 和 "1" |
|
\W |
与任何非单词字符匹配。 |
\W |
"Room#1" 中的 "#" |
|
\s |
与任何空白字符匹配。 |
\w\s |
"ID A1.3" 中的 "D " |
|
\S |
与任何非空白字符匹配。 |
\s\S |
"int __ctr" 中的 " _" |
|
\d |
与任何十进制数字匹配。 |
\d |
"4 = IV" 中的 "4" |
|
\D |
匹配不是十进制数的任意字符。 |
\D |
"4 = IV" 中的 " "、 "="、 " "、 "I" 和 "V" |
Unicode 通用类
|
Unicode 通用类 |
说明 |
|
Lu |
字母,大写 |
|
Ll |
字母,小写 |
|
Lt |
字母,词首字母大写 |
|
Lm |
字母,修饰符 |
|
Lo |
字母,其他 |
|
Mn |
标记,非间距 |
|
Mc |
标记,间距组合 |
|
Me |
标记,封闭 |
|
Nd |
数字,十进制数 |
|
Nl |
数字,字母 |
|
No |
数字,其他 |
|
Pc |
标点,连接符 |
|
Pd |
标点,短划线 |
|
Ps |
标点,开始 |
|
Pe |
标点,结束 |
|
Pi |
标点,前引号(根据用途可能表现为类似 Ps 或 Pe) |
|
Pf |
标点,后引号(根据用途可能表现为类似 Ps 或 Pe) |
|
Po |
标点,其他 |
|
Sm |
符号,数学 |
|
Sc |
符号,货币 |
|
Sk |
符号,修饰符 |
|
So |
符号,其他 |
|
Zs |
分隔符,空白 |
|
Zl |
分隔符,行 |
|
Zp |
分隔符,段落 |
|
Cc |
其他,控制 |
|
Cf |
其他,格式 |
|
Cs |
其他,代理项 |
|
Co |
其他,私用 |
|
Cn |
其他,未赋值(不存在任何字符具有此属性) |
static void Main(string[] args)
{
Console.WriteLine(@"[character_group]:");
Console.WriteLine(Regex.IsMatch("mat," + "moon", @"[mn]"));
foreach (var match in Regex.Matches("mat," + "moon", @"[mn]"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"[^character_group]:");
Console.WriteLine(Regex.IsMatch("avail", @"[^aei]"));
foreach (var match in Regex.Matches("avail", @"[^aei]"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"[ first - last ]:");
Console.WriteLine(Regex.IsMatch("Name!@#$1", @"[a-eM-N0-9]"));
foreach (var match in Regex.Matches("Name!@#$1", @"[a-eM-N0-9]"))
{
Console.WriteLine(match);
}
Console.WriteLine(@".:");
Console.WriteLine(Regex.IsMatch("have,"+ "mate", @"a.e"));
foreach (var match in Regex.Matches("have," + "mate", @"a.e"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\p{ name }");
Console.WriteLine(Regex.IsMatch("City Lights", @"\p{Lu}"));
foreach (var match in Regex.Matches("City Lights", @"\p{Lu}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\P{ name }:");
Console.WriteLine(Regex.IsMatch("City", @"\P{Lu}"));
foreach (var match in Regex.Matches("City", @"\P{Lu}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\w:");
Console.WriteLine(Regex.IsMatch("Room#1", @"\w"));
foreach (var match in Regex.Matches("Room#1", @"\w"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\W:");
Console.WriteLine(Regex.IsMatch("Room#1", @"\W"));
foreach (var match in Regex.Matches("Room#1", @"\W"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\s:");
Console.WriteLine(Regex.IsMatch("ID A1.3", @"\w\s"));
foreach (var match in Regex.Matches("ID A1.3", @"\w\s"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\S:");
Console.WriteLine(Regex.IsMatch("int __ctr", @"\s\S"));
foreach (var match in Regex.Matches("int __ctr", @"\s\S"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\d:");
Console.WriteLine(Regex.IsMatch("4 = IV", @"\d"));
foreach (var match in Regex.Matches("4 = IV", @"\d"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\D:");
Console.WriteLine(Regex.IsMatch("4 = IV", @"\D"));
foreach (var match in Regex.Matches("4 = IV", @"\D"))
{
Console.WriteLine(match);
}
Console.ReadKey();
}
[character_group]:
True
m
m
n
[^character_group]:
True
v
l
[ first - last ]:
True
N
a
e .:
True
ave
ate
\p{ name }
True
C
L
\P{ name }:
True
i
t
y
\w:
True
R
o
o
m \W:
True
#
\s:
True
D
\S:
True
_
\d:
True \D:
True = I
V
定位点
定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用字符。
|
断言表达式 |
描述,注释 |
模式,提取表达式 |
匹配,要提取的文本与提取结果 |
|
^ |
匹配必须从字符串或一行的开头开始。 |
^\d{3} |
"567-777-" 中的 "567" |
|
$ |
匹配必须出现在字符串的末尾或出现在行或字符串末尾的 \n 之前。 |
-\d{4}$ |
"8-12-2012" 中的 "-2012" |
|
\A |
匹配必须出现在字符串的开头。 |
\A\w{4} |
"Code-007-" 中的 "Code" |
|
\Z |
匹配必须出现在字符串的末尾或出现在字符串末尾的 \n 之前。 |
-\d{3}\Z |
"Bond-901-007" 中的 "-007" |
|
\z |
匹配必须出现在字符串的末尾。 |
-\d{3}\z |
"-901-333" 中的 "-333" |
|
\G |
匹配必须出现在上一个匹配结束的地方。 |
\G\(\d\) |
"(1)(3)(5)[7](9)" 中的 "(1)"、 "(3)" 和 "(5)" |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置。 |
er\b |
匹配"never"中的"er",但不能匹配"verb"中的"er"。 |
|
\B |
匹配非单词边界。 |
er\B |
匹配"verb"中的"er",但不能匹配"never"中的"er"。 |
Console.WriteLine(@"^:");
Console.WriteLine(Regex.IsMatch("567-777-", @"^\d{3}"));
foreach (var match in Regex.Matches("567-777-", @"^\d{3}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"$:");
Console.WriteLine(Regex.IsMatch("8-12-2012", @"-\d{4}$"));
foreach (var match in Regex.Matches("8-12-2012", @"-\d{4}$"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\A:");
Console.WriteLine(Regex.IsMatch("Code-007-", @"\A\w{4}"));
foreach (var match in Regex.Matches("Code-007-", @"\A\w{4}"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\Z:");
Console.WriteLine(Regex.IsMatch("Bond-901-007", @"-\d{3}\Z"));
foreach (var match in Regex.Matches("Bond-901-007", @"-\d{3}\Z"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\z");
Console.WriteLine(Regex.IsMatch("-901-333", @"-\d{3}\z"));
foreach (var match in Regex.Matches("-901-333", @"-\d{3}\z"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\G:");
Console.WriteLine(Regex.IsMatch("(1)(3)(5)[7](9)", @"\G\(\d\)"));
foreach (var match in Regex.Matches("(1)(3)(5)[7](9)", @"\G\(\d\)"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\b:");
Console.WriteLine(Regex.IsMatch("never,"+ "verb", @"er\b"));
foreach (var match in Regex.Matches("never," + "verb", @"er\b"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"\B:");
Console.WriteLine(Regex.IsMatch("verb,"+ "never", @"er\B"));
foreach (var match in Regex.Matches("erb," + "nevegr", @"\ber"))
{
Console.WriteLine(match);
}
^:
True $:
True
-
\A:
True
Code
\Z:
True
-
\z
True
-
\G:
True
()
()
()
\b:
True
er
\B:
True
er
分组构造
分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。(组群,或成为子样式)
|
分组构造表达式 |
描述,注释 |
模式,提取表达式 |
匹配,要提取的文本与提取结果 |
|
(subexpression) |
捕获匹配的子表达式并将其分配到一个从零开始的序号中。 |
(\w)\1 |
"deep" 中的 "ee",(\0表示整个表达式) |
|
(?< name >subexpression) |
将匹配的子表达式捕获到一个命名组中。 |
(?<double>\w)\k<double> |
"deep" 中的 "ee",(\K表示反向引用后面分组捕获的内容) |
|
(?< name1 -name2 >subexpression) |
定义平衡组定义。 |
(((?'Open'\()[^\(\)]*)+((?'Close-Open'\))[^\(\)]*)+)*(?(Open)(?!))$ |
"3+2^((1-3)*(3-1))" 中的 "((1-3)*(3-1))" ( (?(Open)(?!))顺序否定环视,保证堆栈中Open捕获组计数是否为0,也就是“(”和“)”是配对出现的 $ |
|
(?: subexpression) |
定义非捕获组。 |
Write(?:Line)? |
"Console.WriteLine()" 中的 "WriteLine",匹配subexpression,但不捕获匹配结果。 |
|
(?imnsx-imnsx:subexpression) |
应用或禁用 subexpression 中指定的选项。 |
A\d{2}(?i:\w+)\b |
"A12xl A12XL a12xl" 中的 "A12xl" 和 "A12XL" i: IgnoreCase 使用不区分大小写的匹配。 有关更多信息,请参见不区分大小写的匹配。 |
|
(?= subexpression) |
零宽度正预测先行断言。 |
\w+(?=\.) |
"He is. The dog ran. The sun is out." 中的 "is"、 "ran" 和 "out"(.结尾的单词) “(?=\.)”表示零宽空间后面是“.” |
|
(?! subexpression) |
零宽度负预测先行断言。 |
\b(?!un)\w+\b |
"unsure sure unity used" 中的 "sure" 和 "used"(非un开头的单词) \b先限定字符串边界 “(?!un)”表示零宽空间后面不是“un” |
|
(?< =subexpression) |
零宽度正回顾后发断言。 |
(?<=19)\d{2}\b |
"1851 1999 1950 1905 2003" 中的 "99"、"50"和 "05"(19开头的年份后两位) “(?<=19)”表示零宽空间前面是“19” |
|
(?< ! subexpression) |
零宽度负回顾后发断言。 |
(?<!^|\s)end\w+\b |
"end sends endure lender" 中的 "ends" 和 "ender" “(?<!^|\s)”表示领款空间前面不是“^字符串开头”或“\s任意空白字符” |
|
(?> subexpression) |
非回溯(也称为"贪婪")子表达式。 |
[13579](?>A+B+) |
"1ABB 3ABBC 5AB 5AC" 中的 "1ABB"、 "3ABB" 和 "5AB" “(?>A+B+)”表示尽可能多的匹配“A+B+” |
Console.WriteLine(@"(subexpression):");
Console.WriteLine(Regex.IsMatch("deep", @"(\w)\1"));
foreach (var match in Regex.Matches("deep", @"(\w)\1"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?<name>subexpression):");
Console.WriteLine(Regex.IsMatch("deep", @"(?<double>\w)\k<double>"));
foreach (var match in Regex.Matches("deep", @"(?<double>\w)\k<double>"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?< name1 -name2 >subexpression):");
Console.WriteLine(Regex.IsMatch("3+2^((1-3)*(3-1))", @"(((?'Open'\()[^\(\)]*)+((?'Close-Open'\))[^\(\)]*)+)*(?(Open)(?!))$"));
foreach (var match in Regex.Matches("3+2^((1-3)*(3-1))", @"(((?<Open>\()[^\(\)]*)+((?<-Open>\))[^\(\)]*)+)*(?(Open)(?!))$"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?: subexpression):");
Console.WriteLine(Regex.IsMatch("Console.WriteLine()", @"Write(?:Line)?"));
foreach (var match in Regex.Matches("Console.WriteLine()", @"Write(?:Line)?"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?imnsx-imnsx:subexpression)");
Console.WriteLine(Regex.IsMatch("A12xl A12XL a12xl", @"A\d{2}(?i:\w+)\b"));
foreach (var match in Regex.Matches("A12xl A12XL a12xl", @"A\d{2}(?i:\w+)\b"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?= subexpression):");
Console.WriteLine(Regex.IsMatch("He is. The dog ran. The sun is out.", @"\w+(?=\.)"));
foreach (var match in Regex.Matches("He is. The dog ran. The sun is out.", @"\w+(?=\.)"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?! subexpression):");
Console.WriteLine(Regex.IsMatch("unsure sure unity used", @"\b(?!un)\w+\b"));
foreach (var match in Regex.Matches("unsure sure unity used", @"\b(?!un)\w+\b"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?<=subexpression):");
Console.WriteLine(Regex.IsMatch("1851 1999 1950 1905 2003", @"(?<=19)\d{2}\b"));
foreach (var match in Regex.Matches("1851 1999 1950 1905 2003", @"(?<=19)\d{2}\b"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?<! subexpression):");
Console.WriteLine(Regex.IsMatch("end sends endure lender", @"(?<!\w)\w{2}\b"));
foreach (var match in Regex.Matches("end sends endure lender", @"(?<!\w)\w{2}\b"))
{
Console.WriteLine(match);
}
Console.WriteLine(@"(?> subexpression):");
Console.WriteLine(Regex.IsMatch("1ABB 3ABBC 5AB 5AC", @"[13579](?>A+B+)"));
foreach (var match in Regex.Matches("1ABB 3ABBC 5AB 5AC", @"[13579](?>A+B+)"))
{
Console.WriteLine(match);
}
相符子样式
(subexpression) - (Matched Subexpressions, 相符子样式)
在样式中, 以圆括号圈住的部份就是一个子样式 (Subexpressions), 也称为一个群组 (Group)。有时候我们并非刻意去捕抓这个群组, 但是因为使用圆括号圈住, 使得它也算做一个群组, 所以可以在 Match.Groups[n] 里面找到。例如样式 "(AB | CD)", 写成这样是因为语法如此, 而不是因为我们刻意要捕捉这个群组。但是它仍然算是一个群组。如果你不想在 Groups 中看到这个群组, 那么可以使用下面提到的「不予获取的群组」, 或者改用「具名相符子样式」。
若使用 Match.Groups[n] 来列出捕捉到的群组, 它的编号顺序会以从左到右的左括号做为基准。例如, 假设我们以 "(((((.+).+).+).+).+)" 这个样式来检测 "ABCDE" 这个受测字符串的话, 找到的群组会像以下的样子:
- Groups[0]: ABCDE
- Groups[1]: ABCDE
- Groups[2]: ABCD
- Groups[3]: ABC
- Groups[4]: AB
- Groups[5]: A
在这五个群组中, Groups[0] 一律会列出整个相符的字符串。但是从 Groups[1] 开始, 捕捉到的就是 "(((((.+).+).+).+).+)" 这个相符子样式(从左边算来第一个左括号), Groups[2] 就是 "((((.+).+).+).+)" (从左边算来第二个左括号)... 依此类推。
example:“((.+)(.+))((.+)((.+)(.+))) ”匹配 "ABCDE":
- Groups[0]: ABCDE
- Groups[1]: AB
- Groups[2]: A
- Groups[3]: B
- Groups[4]: CDE
- Groups[5]: C
- Groups[6]: DE
- Groups[7]: D
- Groups[8]: E
捕获组,其实有两层含义:
1.捕获()中定义的字符,捕获到内容就按组对待;
2.捕获到内容为空字符(区别没有捕获到),则捕获匹配的零宽空间;
对称群组定义
(?<name1-name2>subexpression) - (Balancing Group Definitions, 对称群组定义)
如果前面已定义过 name2, 那么这里可以获取出 name2 到 name1 中间的文字, 然后将它命名为 name1。如果你在式子中并未定义 name2 则会出现错误。例如输入的受测字符串为
<input id="ID" name="NAME" type="BUTTON" />
把 Regex 样式定义为 (?<Quote>\")[^"]+(?<Text-Quote>\")
那么我们就能撷取出 ID, NAME 与 BUTTON 三个符合 Text 群组的字。至于 Quote 群组, 虽然我们有定义它, 也有找到, 但并不会出现在结果中。换句话说, 这个范例中的 Quote 群组变成一个暂用的群组; 它只是被用来得到 Text 群组而已。
请注意, 本功能大概只有 .NET 有支持, 其它多数 Regex 引擎 (Ruby, Python, Java, JavaScript, Perl, Delphi 等等) 都不支持。所以本功能用处并不大。
不予获取的群组
(?:subexpression) - (Noncapturing Groups, 不予获取的群组)
这个功能很单纯, 只是让括号括住的部份不列入 Group 而已。个人认为本功能如同鸡肋, 用得上的机会根本少之又少。不过由于 MSDN 对本功能的解释过于简单, 范例也举得不好, 所以恐怕会令许多人感觉困惑。再此简述一下:原本我们在 Regex 的 Pattern 中, 凡是使用括号括住的部份, 都会列入 Group 里面, 之后我们就可以使用 Group[i] 逐个取出。然而, 如果你把一个括住的部份加上 ?: 符号, 那么这个括住的部份就不会列入 Group[i]。
例如我们有一个 Pattern 如下:
(a(b*))+
如果 Match 的话, 你可以使用 Group[0], Group[1] 和 Group[2] 取出三个符合的群组。然而, 如果你把以上的式子改写为:
(a(?:b*))+
那么你只能取到 Group[0] 和 Group[1], 就不会有 Group[2] 了。
或许你会认为上述的例子也可以写成 (ab*)+ 即可, 结果会是一样的。不过你总会踫上远比 b* 还要复杂的群组, 使得你不得不使用括号把它给括住; 如果你又不想列入 Group[i] 的时候, 就可以使用这一招。就像在这个范例, 你也可以把式子改成:
(?:a(?:b*))+
那么就只有 Group[0] 存在, 其它都没有了。当然, 对我个人而言是几乎用不上这个功能的, 因为我习惯采用 Named Matched Subexpressions (也就是采用 ?<Name> 这种标注方法), 所以除了测试之外, 根本不会去列举 Group[i], 这就是为什么本功能对我如同鸡肋的原因了。
群组选项
(?imnsx-imnsx:subexpression) - (Group Options, 群组选项)
我们在建立 Regex 对象时可以指定其选项, 但我们也可以在 Pattern 里的某个群组中强制开启或关闭这些选项, 方法是透过 ?imnsx-imnsx 前置标注来达成。其语法如下
?X-Y
这里 X 指的是要开启的功能, 而跟在减号后面的 Y 则是要关闭的功能。这里 X 跟 Y 可以代表数个不同的字符:
- i - 不区分大小写 (case-insensitive matching, 预设为开启)
- m - 多行 (multi-line):
设定多行模式后, ^ 与 $ 可以适用于每行的行首与行末 (但别期望它会认得 <br /> 或 <p> 这种 HTML 标记) - n – 获取明确命名的群组 (Explicit Capture):
凡是非以 ?<Name> 标注的群组将不予获取, 也不列入 Group 集合 - s - 单行 (single line):
与多行相反; 不再将 \n 字符视为字与字的间隔符号 - x - 略过 Pattern 中的空格符 (ignore pattern
whitespace, 预设为不略过):
原本 pattern 中的空格符等同于 \s, 如果开启此选项则, 那么你就必须明确的使用 \s 来代表空格符(当然, 你也不能期望它认得
这种标示)。不过我个人建议你忘记
Regex 有提供这种功能。你最好在该使用 \s 或 \t
的地方乖乖的使用 \s 或 \t, 否则最后可能会以混乱收场。
这些代表字符可以写在一起, 像 ?mx 或 ?mx-is 等等。
假设受测字符串为 "AB AC A D", 如果 pattern 为 "(a.)", 那么在预设情况下会检测不到任何东西, 但改成 "(?i:a.) 则会找到 "AB", "AC" 和 "A "。如果 pattern 是 "(?i:a .)" (注意这里在 a 跟句点中间夹了一个空白), 则可以找到 "A D", 但如果改成 "(?ix:a .)" 则可以找到 "AB", "AC" 与 "A "; 但如果改成 "(?i-x: a .)", 那么又只能找到 "A D"。
不过, 请留意不同的语言的群组选项有不同的实作方式, 例如 JavaScript 根本不支持这种群组。但是对于有支持的语言(.Net, Java, PHP, Ruby 等等), 总体而言差异并不大。
另外还有一个值得特别注意之处。如果你使用 RegexOptions 来设定样式的选项, 那么它对整个样式都有效。但是如果你使用这里介绍的 inline 群组选项的话, 该群组出现的位置会影响样式的比对结果。例如, 如果你把 (?i) 写在样式的最前面, 那么整个样式都不区大小写.但是如果你把它写在样式的中间, 那么它会从那个位置开始生效, 在它之前并不受影响.
非回溯子样式
(?> subexpression ) - (Nonbacktracking Subexpressions, 非回溯子样式, 也称为穷尽 (Greedy) 子样式)
先看这里所谓的「回溯」是什么意思。基本上, .Net 机制在解析样式时, 它并不是一条路直挺挺走到底, 而是会视情况分解成树状路径; 当走过一个节点之后, 会回到前一个分支, 再走另一个分岔路径, 直到整颗树都巡览过一遍为止。像这种会回头走另一条路径的行为, 就称为「回溯」(backtracking)。
现在假设我们有一个受测字符串为 "001 2223 4444 55556", 我们先使用一个平常的 pattern 如下:
(\w)\1+(\w\b)
其用意是检出开头以一个以上的迭字方式出现 (即开头的 "(\w)\1+" ), 后面再跟着另一个字符结尾 (即随后的 "(\w\b)" ) 的字符串。根据以上样式, 我们可以检出 "001"、"2223"、"4444" 和 "55556", 亦即受测字符串中的所有子字符串都全部被检出。这里我们可能会对 "4444" 产生疑义, 为什么它也可以被检测出来? 其实基准样式, "4444" 可以被拆成 "444" + "4", 所以它会被检出。但是, 如果我们把 pattern 改成非回溯子样式:
(?>(\w)\1+)(\w\b)
那么我们就只会检出 "001"、"2223" 和 "55556" 而已, 其中的 "4444" 不会被检出。为什么? 因为我们在样式的前半段 (即 "(?>(\w)\1+)") 已经指明它为非回溯子样式, 而一旦被指定为非回溯子样式, .Net 只会直接采用最多的匹配数量来评估一次而已 (即 "4444",贪婪匹配,最大匹配), 而不会再把 "4444" 拆成 "44" + "44"、"444" + "4" 和 "4444" 来评估三次。在这里, "4444" 虽然符合 (?>(\w)\1+) 这个子样式, 但是这串字的后面并未再跟着任何字符以符合后面的 (\w\b) 子样式, 所以最后就被评估为 No Match。相对的, 其它像 "001"、"2223" 和 "55556" 却可以完全符合, 所以被评估为 Match。
所以如果我们刚好想要检测出 aab, aaab 这种出现规则的字符串, 而排除 aaaa 这种字符串的话, 非回溯子样式就是最佳选择了。
边界检测群组
以下会列出几个专做「边界检测」(assertion, 又称断字、断言) 的群组。这几个群组都是所谓「环顾」(Look Around) 群组, 意思就是做边界检查用的, 而不是用来获取出什么信息。所以我们可以看到这些群组的名称多半都有「无宽度」(Zero-Width零宽) 这个字眼, 它们通常也不会被列入 matched groups 里。
所谓的「边界检测」, 意思是专门用来检查边界的条件, 例如, 我们可以使用 \A 来检查整个字符串的起始位置, 用 ^ 检查一行的起始位置, 用 $ 来检查一行的结束位置, 用 \b 来检查字的边界条件, 诸如此类。但是如果边界条件不是什么文字边界、行首、行末等等, 而是比较复杂的文字, 那么我们就可以使用这些边界检测群组。
值得注意的是, 并不是所有语言都支持所有的边界检测群组, 例如 Ruby 在 1.8 以前并不支持。JavaScript 也不全部支持。幸好 .Net 是完全支持的。Ruby 2.0,和 .Net 基本一致。所以下述范例的用法和结果在 .Net 中应该是完全相同的。
所谓的零宽,就是指没有宽度的字符,即字符与字符之间的空间。如检测“end sends endure lender”字符与字符之间的空间:

无宽度右合子样式
(?=subexpression) - (Zero-Width Positive Lookahead Assertions, 无宽度右合子样式,零宽断言,正预测先行断言)
此功能在中文 MSDN 翻译中称为「无宽度右合样判断式」。你可能一开始看不懂这个翻译, 但这个描述实际上是正确的。所有环顾群组的主要功能是用来做边界的检查, 而不是用在获取(这就是为什么这几个群组被称为「无宽度」)。在这种群组的左边, 一定会跟着真正要获取的样式(如果没有, 也不会发生错误, 只是使用 Group[i] 取不到任何结果而已; 你仍然能使用 IsMatch 取得检测成不成功的信息, 但是这么做是没有意义的 - 除非是运用在另一种应用的方法, 下面会再提到)。
Regex 的比对绝大多数都是从左往右进行的。所以如果我们一次就比对到最右边之处, 那不就是把比对的动作「提前」进行了吗? 所以所谓右合子样式名称中的 "Lookahead" 这个字就是这样来的。同时, 这也就是为什么我们称之为「右合」的由来。此外, 稍后我们会谈到 "Lookbehind" 和「左合」, 也是基于同样的道理。
现在以范例来介绍无宽度右合子样式。如果受测字符串是 "ab22 cd33 eeff", 而 pattern 是 "(\b[a-zA-Z]+)(?=\d+\b)" (用意是找出所有以英文字母开头, 以数字结尾的字, 但只取英文字符的部份), 那么我们可以获取出 "ab" 和 "cd" (分别在两个 Match 中)。换句话说, "ab22" 和 "cd33" 虽然都符合整个 pattern, 但右合样式(对应 "22" 与 "33")本身并不会被取出来。
关于右合样式还有另一种应用的方法, 刚好和上述写法相反, 是把右合样式写在左边。例如, 我们若使用 "\d{9,}" 作为 pattern, 我们会获取出所有九位数以上的电话号码。但如果我们只想获取所有以 02 开头的电话, 怎么办? 当然我们可以把 pattern 改成 "02\d{7,}" 即可; 但我们也可以使用右合样式来做过滤, 亦即改成 "(?=02\d*)(\d{10})"。若采用后面的样式, 那么程序一开始便检查字符串中有没有符合 "(02\d{10})" 样式的子字符串, 若有, 再从中获取出这个子字符串。
无宽度右合样式实在是一种很好用的工具; 虽然可能有人会坚持一定要去修改要获取的 pattern, 但我却宁可保持原始的获取样式不变, 而是把右合样式一个一个迭加上去。例如在上例中, 我们使用 "(?=02\d*)(\d{7,})" 就可以滤出台北的电话, 但如果我要滤出台北跟高雄的电话, 怎么办? 很简单, 加上去就好了:
"( (?=02\d*) | (?=07\d*) ) (\d{7,})" <- 式子里面的空白是不必要的, 只是为了容易看而已
换句话说, 你可以使用 "( zwpla1 | zwpla2 ) (pattern)" 这种写法达到「或」的效果。至于个中巧妙就端看你怎么搭配使用了。
不过, 请注意 不管你把断言放在左边或是右边, 请把它放在最左边或最右边(亦即最左边或最右边的群组)。如果你偏偏把它放在中间, 像是 "(\w*)\s*(?=ABC)\s*(\w*)", 那么这个原本不应该被捕捉到的群组可能又会被捕捉到。请务必了解, 第一种用法(放在右边)与第二种用法(放在左边)使用在不同情境之下, 使用的样式普遍上不同。所以除非你知道你在做什么, 否则我建议你不要把无宽度右合子样式放在两个整个样式的中间(以下的无宽度左合子样式也是一样)。
无宽度右不合子样式
(?!subexpression) - (Zero-Width Negative Lookahead Assertions, 无宽度右不合子样式,负向零宽断言,负预测先行断言)
刚好和上一个功能相反; 所以中文 MSDN 翻译成「无宽度右不合样判断式」, 意思是只有当此样式不符合时, 才会继续比对它右边的其它样式。至于用法和右合样式一模一样, 我就不再特别说明了。在上一个范例中, 如果我们想找出「台北以外」的电话号码, 那么就是这个功能可以办到的。
无宽度左合子样式
(?<=subexpression) - (Zero-Width Positive Lookbehind Assertions, 无宽度左合子样式,正回顾后发断言)
此功能在中文翻译中称为「无宽度左合样判断式」, 和「无宽度右合样判断式」使用方式类似, 只是两者位于不同边。例如, 如果有一个受测字符串是 "1998 1999 2000 2001 2002 2009 0212345678", 我们要把里面符合公元年度样式的子字符串挑出来, 但我们只要公元 2000 (含)以后的, 而且我们只取百位数以下的两个数字, 这时候我们就可以采用左合样式:
(?<=\b2)\d(?<ShortenYear>\d\d)\b
顺利取出 "00", "01", "02" 与 "09"。在此例中, (?<=\b2) 代表位于左侧、以 2 开头的一个字符, 而蓝色的 \d(?<ShortenYear>\d\d)\b 则代表三个数字字符结尾的字符(如 "001", 但只取右边两个字符 "01")。
跟右合样式一样, 左合样式也有一种另类的用法, 也就是把它当作一个单纯的检验式, 只不过这次它是放到右边。现在假设有一个受测字符串是 "8 AM 11 AM 1 PM 3 PM", 我们原本可以使用 (\b(?<Hour>\d{1,2})\s*(AM|PM)\b) 取出 "8 AM"、"11 AM"、"1 PM" 和 "3 PM", 但如果我们只想取下午的时间, 那么我们就可以在它的右边加上一个左合样式:
(\b\d{1,2}\s*(AM|PM)\b)(?<=PM\b)
(\b(?<Hour>\d{1,2})\s*(AM|PM)\b)(?<=\b\d{1,2}\s*PM\b) #.NET中可以用不固定长度
如此, 我们就可以只取出 "1 PM" 和 "3 PM" 了。
无宽度左不合子样式
(?<!subexpression) - (Zero-Width Negative Lookbehind Assertions, 无宽度左不合子样式,负向零宽断言,负回顾后发断言)
中文 MSDN 翻译为「无宽度左不合样判断式」, 和上一个功能恰恰相反。如果借用上面的那个例子 (受测字符串为 "1998 1999 2000 2001 2002 2009 0212345678"), 我们可以使用以下的 pattern:
(?<!2)\d(?<ShortenYear>\d\d)\b(?<=\b\d{4}\b)
(?<!2\d)\d\d\b(?<=\b\d{4}\b)
取出开头不为 2 且符合四位数字格式的二位数年份: "98"、"99"。请注意我们在样式最右边加上了一个左合判断式 (蓝色部份) 以检查是否为四位数的数字。如果你在式子中使用了左不合判断式, 那么你只能如上例般采用左合判断式来做预先检查, 而不能采用放在左边的右合判断式 (请参考上面对于 ?= 及 ?<= 两种判断式的说明); 这是值得特别注意之处。
在某些语言中 (例如 Ruby) 左合和左不合子群组都不允许使用变动长度的量词 (例如 + * {1,2}等等), 换句话说, 这些语言的左合和左不合子群组中只能使用固定长度的样式 (但是右合和右不合子群组倒是可以)。例如 "(?<=a*)" 这种样式会引发编译程序错误。把这个范例中的样式里的 (?<=a*) 中的星号拿掉, 就能正确执行了。所幸在 .Net 中并无这种限制。
应用时机与场合
了解上述四种边界检测群组之后, 如果你还不知道这四种检测群组可以应用在什么场合里, 那么我可以举一个例子。基本上, 我们可以这样用:
(不)符合左边的样式 + 真正要获取的信息 + (不)符合右边的样式
HTML 和 XML 标签刚好很适合用来做示范。一个正规的 HTML 标签就是一个 "<" 加上几个字, 再加上 ">"。例如 "<b>"。用白话来说, 我们就可以检测「左边必须是 <」, 以及「右边必须是 >」。以边界检测群组来做, 就是把 (?<=<) 放在式子的最左边, 把 (?=>) 放在式子的最右边。完整的式子如下:
(?<=<)\s?(?<OpenTag>[^ >]+)\s?(?<Content>[^\/>]*)(?<SelfClose>\/)?(?=>)
范例:
测试目标:
HTML Open Tag
<input a="a" > <input b = "b" c='c'/> <input> <>
Pattern:
(?<=<)\s?(?<OpenTag>[^ >]+)\s?(?<Content>[^\/>]*)(?<SelfClose>\/)?(?=>)

结果:
HTML Open Tag
<input a="a" > <input b = "b" c='c'/> <input> <>

在这个范例中, 我们可以一次取出 Open Tag、卷标内所有属性, 以及 Self-Closing 字符。检查取得的 Self-Closing 字符是否为 "/", 就可以判断这个 HTML 标签是否为 Self-closed。此外, 把取出的 Content 字符串拿去分析, 就可以取得各个属性。
不过, 凭良心说, 这个范例并非最好的范例。它只是容易示范而已。为什么它不是最好的范例? 因为你可以把 (?<=<) 简单地以 "<" 取代、把 (?=>) 简单地以 ">" 取代, 结果相同。两者的差别只是使用 "<" 和 ">" 的话, 会让 Matched Groups[0] 连同 "<" 和 ">" 都一起取到而已。
限定符
限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项。 限定符包括下表中列出的语言元素。
|
限定符 |
描述 |
模式 |
匹配 |
|
* |
匹配上一个元素零次或多次。 |
\d*\.\d |
".0"、 "19.9"、 "219.9" 此匹配会尽量多的匹配 |
|
+ |
匹配上一个元素一次或多次。 |
"be+" |
"been" 中的 "bee", "bent" 中的 "be" |
|
? |
匹配上一个元素零次或一次。 |
"rai?n" |
"ran"、 "rain" |
|
{ n } |
匹配上一个元素恰好 n 次。 |
",\d{3}" |
"1,043.6" 中的 ",043", "9,876,543,210" 中的 ",876"、 ",543" 和 ",210" |
|
{ n ,} |
匹配上一个元素至少 n 次。 |
"\d{2,}" |
"166"、 "29"、 "1930" |
|
{ n , m } |
匹配上一个元素至少 n 次,但不多于 m 次。 |
"\d{3,5}" |
"166", "17668", "193024" 中的 "19302" |
|
*? |
匹配上一个元素零次或多次,但次数尽可能少。 |
\d*?\.\d |
".0"、 "19.9"、 "219.9" |
|
+? |
匹配上一个元素一次或多次,但次数尽可能少。 |
"be+?" |
"been" 中的 "be", "bent" 中的 "be" |
|
?? |
匹配上一个元素零次或一次,但次数尽可能少。 |
"rai??n" |
"ran"、 "rain" |
|
{ n }? |
匹配前导元素恰好 n 次。 |
",\d{3}?" |
"1,043.6" 中的 ",043", "9,876,543,210" 中的 ",876"、 ",543" 和 ",210" |
|
{ n ,}? |
匹配上一个元素至少 n 次,但次数尽可能少。 |
"\d{2,}?" |
"166"、 "29" 和 "1930" |
|
{ n , m }? |
匹配上一个元素的次数介于 n 和 m 之间,但次数尽可能少。 |
"\d{3,5}?" |
"166", "17668", "193024" 中的 "193" 和 "024" |
反向引用构造
反向引用允许在同一正则表达式中随后标识以前匹配的子表达式。
|
反向引用构造 |
描述 |
模式 |
匹配 |
|
\ number |
反向引用。 匹配编号子表达式的值。 |
(\w)\1 |
"seek" 中的 "ee" 整个字符串用“\0”匹配 |
|
\k< name > |
命名反向引用。 匹配命名表达式的值。 |
(?< char>\w)\k< char> |
"seek" 中的 "ee" |
备用构造
备用构造用于修改正则表达式以启用 either/or 匹配。
|
备用构造 |
描述 |
模式 |
匹配 |
|
| |
匹配以竖线 (|) 字符分隔的任何一个元素。 |
th(e|is|at) |
"this is the day. " 中的 "the" 和 "this" |
|
(?( expression )yes | no ) |
如果正则表达式模式由 expression 匹配指定,则匹配yes;否则匹配可选的 no 部分。 expression 被解释为零宽度断言。 |
(?(A)A\d{2}\b|\b\d{3}\b) |
"A10 C103 910" 中的 "A10" 和 "910" 把(A)当作零宽正向先行断言,如果在这个位置能匹配, 匹配A\d{2}\b 否则 匹配\b\d{3}\b |
|
(?( name )yes | no ) |
如果 name 或已命名或已编号的捕获组具有匹配,则匹配 yes;否则匹配可选的 no。 |
(?<quoted>")?(?(quoted).+?"|\S+\s) |
"Dogs.jpg "Yiska playing.jpg"" 中的 Dogs.jpg 和 "Yiska playing.jpg" “(?<quoted>")”表示零宽空间后是“"”的分组 “(?<quoted>")?”表示匹配上述0次或1次的零宽空间 (?(quoted).+?"|\S+\s)表示,从左向右依次看"Dogs.jpg "Yiska playing.jpg"", 从"Dogs.jpg "开始直到""Yiska playing.jpg""前, “(?<quoted>")?”均未捕获到任何元素(零宽空间不算元素) 所以匹配“\S+\s”,即“Dogs.jpg ” 在看到""Yiska playing.jpg""时,“(?<quoted>")?”捕获到元素“"” 因此从“Yiska playing.jpg"”开始匹配“.+?"”,加上前面捕获的“"”,即""Yiska playing.jpg""。 |
Console.WriteLine(@"(?( name )yes | no ):");
foreach (var match in Regex.Matches("Dogs.jpg \"Yiska playing.jpg\"", "(?<quoted>\")?(?(quoted).+?\"|\\S+\\s)"))
{
Console.WriteLine($"{{{match}}}");
}
(?( name )yes | no ):
{Dogs.jpg }
{"Yiska playing.jpg"}
同样,考虑
Console.WriteLine(@"(?( name )yes | no ):");
foreach (var match in Regex.Matches("Dogs.jpg \"Yiska playing.jpg\"", "(?<quoted>\")?(?(quoted).+?|\\S+\\s)"))
{
Console.WriteLine($"{{{match}}}");
}
(?( name )yes | no ):
{Dogs.jpg }
{"Y}
{iska }
注意:上述所有捕获组中,部分正则引擎不支持非固定长度捕获表达式,即含有“*?{m,n}”等非固定长度匹配式,上述结果均在.NET下运行。
替换
替换是替换模式中使用的正则表达式。
|
字符 |
描述 |
模式 |
替换模式 |
输入字符串 |
结果字符串 |
|
$number |
替换按组 number 匹配的子字符串。 |
\b(\w+)(\s)(\w+)\b |
$3$2$1 |
"one two" |
"two one" |
|
${name} |
替换按命名组 name 匹配的子字符串。 |
\b(?< word1>\w+)(\s)(?< word2>\w+)\b |
${word2} ${word1} |
"one two" |
"two one" |
|
$$ |
替换字符"$"。 |
\b(\d+)\s?USD |
$$$1 |
"103 USD" |
"$103" |
|
$& |
替换整个匹配项的一个副本。 |
(\$*(\d*(\.+\d+)?){1}) |
**$& |
"$1.30" |
"**$1.30**" 见下图 |
|
$` |
替换匹配前的输入字符串的所有文本。 |
B+ |
$` |
"AABBCC" |
"AAAACC" $`匹配BB前的所有字符,即AA,然后BB就被替换成了AA |
|
$' |
替换匹配后的输入字符串的所有文本。 |
B+ |
$' |
"AABBCC" |
"AACCCC" $'匹配BB后的所有字符,即CC,然后BB就被替换成了CC |
|
$+ |
替换最后捕获的组。 |
B+(C+) |
$+ |
"AABBCCDD" |
AACCDD $+匹配CC,所以BBCC被替换成了CC |
|
$_ |
替换整个输入字符串。 |
B+ |
$_ |
"AABBCC" |
"AAAABBCCCC" $_匹配AABBCC,所以BB被替换成了AABBCC |
用“(\$*(\d*(\.+\d+)?){1})”匹配“$1.30”
匹配结果:


1.尝试从“ $ 1 . 3 0 ”的第一个“零宽位”开始匹配“(\$*(\d*(\.+\d+)?){1})”: “$ 1 . 3 0 ”匹配。(\$*(\d*(\.+\d+)?){1}中{1}指(\d*(\.+\d+)?)只出现一次,即最小匹配)
2.尝试从“ $ 1 . 3 0 ”的第二个“零宽位”开始匹配“(\$*(\d*(\.+\d+)?){1})”:由于$(结尾)符合\$*(\$*(\d*(\.+\d+)?){1}中\$匹配0次\d*匹配0次(\.+\d+)?匹配0次,),所以“ $”(结尾)中的零宽空间被捕获,但"$”(结尾)未被捕获。
Console.WriteLine(@"$number:");
Console.WriteLine(Regex.Replace("one two", @"\b(\w+)(\s)(\w+)\b", @"$3$2$1")); Console.WriteLine(@"${name}:");
Console.WriteLine(Regex.Replace("one two", @"\b(?<word1>\w+)(\s)(?<word2>\w+)\b", @"${word2} ${word1}")); Console.WriteLine(@"$$:");
Console.WriteLine(Regex.Replace("103 USD", @"\b(\d+)\s?USD", @"$$$1")); Console.WriteLine(@"$&:");
Console.WriteLine(Regex.Replace("$1.30", @"(\$*(\d*(\.+\d+)?){1})", @"**$&")); Console.WriteLine(@"$`:");
Console.WriteLine(Regex.Replace("AABBCC", @"B+", @"$`")); Console.WriteLine(@"$':");
Console.WriteLine(Regex.Replace("AABBCC", @"B+", @"$'")); Console.WriteLine(@"$+:");
Console.WriteLine(Regex.Replace("AABBCCDD", @"B+(C+)", @"$+")); Console.WriteLine(@"$_:");
Console.WriteLine(Regex.Replace("AABBCC", @"B+", @"$_"));
$number:
two one
${name}:
two one
$$:
$
$&:
**$1.30**
$`:
AAAACC
$':
AACCCC
$+:
AACCDD
$_:
AAAABBCCCC
杂项构造
|
构造 |
描述 |
实例 |
|
(?imnsx-imnsx) |
在模式中间对诸如不区分大小写这样的选项进行设置或禁用。 |
\bA(?i)b\w+\b 匹配 "ABA Able Act" 中的 "ABA" 和 "Able" |
|
(?#注释) |
内联注释。该注释在第一个右括号处终止。 |
\bA(?#匹配以A开头的单词)\w+\b |
|
# [行尾] |
该注释以非转义的 # 开头,并继续到行的结尾。 |
(?x)\bA\w+\b#匹配以 A 开头的单词 |
Regex 类
Regex 类用于表示一个正则表达式。
|
序号 |
方法 & 描述 |
|
1 |
public bool IsMatch( string input ) |
|
指示 Regex 构造函数中指定的正则表达式是否在指定的输入字符串中找到匹配项。 |
|
|
2 |
public bool IsMatch( string input, int startat ) |
|
指示 Regex 构造函数中指定的正则表达式是否在指定的输入字符串中找到匹配项,从字符串中指定的开始位置开始。 |
|
|
3 |
public static bool IsMatch( string input, string pattern ) |
|
指示指定的正则表达式是否在指定的输入字符串中找到匹配项。 |
|
|
4 |
public MatchCollection Matches( string input ) |
|
在指定的输入字符串中搜索正则表达式的所有匹配项。 |
|
|
5 |
public string Replace( string input, string replacement ) |
|
在指定的输入字符串中,把所有匹配正则表达式模式的所有匹配的字符串替换为指定的替换字符串。 |
|
|
6 |
public string[] Split( string input ) |
|
把输入字符串分割为子字符串数组,根据在 Regex 构造函数中指定的正则表达式模式定义的位置进行分割。 |
浅谈正则表达式解析过程 / 效率优化
前言
编写高性能的正则表达式,有如下几条规则,这几条规则是本人总结出来的:
1、使用正确的边界匹配器(^、$、\b、\B等)
2、使用具体的元字符、字符类(\d、\w、\s等)
3、使用正确的量词(+、*、?、{n,m})
4、使用非捕获组、原子组
5、注意量词的嵌套
其实正则表达式的很多优化技巧都是围绕着“减少回溯”这样一个原则进行优化的。
至于什么是“回溯”,笔者就不在这里重复了,以下通过具体的例子理解这样的过程。
示例
一、以下是一则匹配电子邮件地址的正则表达式:
先一步步的解析:
1、^\w+:表示必须以字符开始, 且是一个或者多个;
2、([\.-]?\w+)*中的“[\.-]?”表示匹配“.”或者“-”,零次或者一次;
3、([\.-]?\w+)*中的“\w+”则表示匹配一个或者多个的字符;
4、([\.-]?\w+)*整个则表示匹配.xxx、-xxx或者xxx这样的字符,且零次或者多次;
5、第1-4步,则匹配sunny或者sunny.yang这样的字符;
6、“@”则是具体元,匹配具体的@;
7、 \w+:则表示匹配的一个或者多个的字符,因为email不可能这样嘛:sunny@.gmail.com;
8、 ([\.-]?\w+)*:则跟第2-4步一样,匹配.163、-lib、.gd这样的字符,且零次或者多次;
9、 (\.\w{2,3})+$:则匹配.com、.cc这样结尾的域名,且因为\w{2,3}限定了长度必须为2-3位,所以不能匹配.c、.n这样的字符。
乍看这样一个解析过程没问题,逻辑正确,但其实暗藏很多问题,看看以下的一个匹配图,backtrack则表示回溯(使用RegexBuddy可以很清晰的看到这过程)

整个成功的匹配过程经历了55步,我们先分析下整个匹配过程:
1、图中的第1和2步,匹配^\w+,匹配成功,匹配了“admin”;
2、图中第3步,匹配[\.-]?,当然由于不存在“.”和“-”,因此没匹配上具体的字符,但又由于“?”的限定,可以匹配零或者一次,因此这个子表达式匹配成功,虽然没匹配上具体的字符。
3、图中第4步,匹配\w+,由于“+”限定一个或者多个以上字符,但后续已经没[a-zA-Z0-9]可以匹配了,因此产生回溯,回溯到上次匹配成功的位置,也就admin;
4、图中第5步,因为上一步产生了回溯,所以“[\.-]?\w+”匹配了零次,由于([\.-]?\w+)*中限定零次或者多次,因此也匹配成功,也没匹配上具体的字符;
以下步骤,匹配该过程:
5、图中第6步,匹配了“@” ,第7步匹配了“\w+”,即匹配了“open”;
6、图中第8-13步,匹配“([\.-]?\w+)*” ,匹配了“-lib”、“.com”,匹配“.com”可能与我们期望不相符,我们期望这子表达式匹配的是www.xx.gd.cn中的“.gd”;
7、图中第7-10步,匹配了open-lib,第7-13步则匹配了open-lib.com;
8、因为“([\.-]?\w+)*”中的量词是“*”,则继续重复这个过程;
9、 图中第14步,匹配“([\.-]?\w+)*”中的“[\.-]?”,因为此时指针已经位于@open-lib.com之后了,但由于量词“?”,因此也匹配成功,但没匹配上字符,也没字符可匹配;
10、 图中第15步,匹配“([\.-]?\w+)*”中的“\w+”,此时指针仍位于字符串末尾,没任何字符能匹配,所以匹配失败,产生回溯,回到上次成功的位置,即图中的第13步,继续下个表达式的匹配;
11、 图中第16步,匹配(\.\w{2,3})+中的“\.”,由于没有任何字符能匹配,匹配失败,进行回溯;
12、图中第17步 ,(\.\w{2,3})+中量词“+”,表示该表达式必须匹配一次或者多次,由于上一步匹配失败了,所以匹配零次,但不符合一次或者多次的限定,因此继续回溯;
13、由于上一步匹配失败,需要进行回溯,因此表达式没有更多的分支了,只能将指针回退一个字符,回溯上次成功的位置,即([\.-]?\w+)*中\w+的位置(这是上次产生分支的位置);
14、图中剩下的步骤,就重复着匹配([\.-]?\w+)*,回退字符,匹配(\.\w{2,3})+这样的过程,直到匹配成功。
二、以下看看另外一则同样匹配邮件地址的正则表达式:
这个正则跟上面的看起来貌似差不多,不过细看还是有区别的,也先一步步来解析:
1、^\w+:表示必须以字符开始, 且是一个或者多个(这一步与上面的一样);
2、 ([-\.]\w+)*中的“[-\.]”表示匹配“-”或者“.”;
3、 ([-\.]\w+)*中的“\w+”则表示匹配一个或者多个的字符;
5、第1-4步,则匹配sunny或者sunny.yang这样的字符;
6、“@”则是具体元,匹配具体的“@”;
7、 \w+:则表示匹配的一个或者多个的字符,因为email不可能这样嘛:sunny@.gmail.com;
8、([-\.]\w+)*:则跟第2-4步一样,匹配.163、-lib、.gd这样的字符,且零次或者多次;
9、“\.”则是具体元,匹配“.”;
10、\w+:则匹配一个或者多个字符;
11、([-\.]\w+)*:则匹配“.com”、“-lib”、“.c”这样的字符,且可以零次或者多次;
12、$ :则表示结尾
乍看这个正则的步骤过程貌似比上一则长,其实不然,同时这个正则也存在着问题,先看看匹配图,同样backtrack表示回溯:
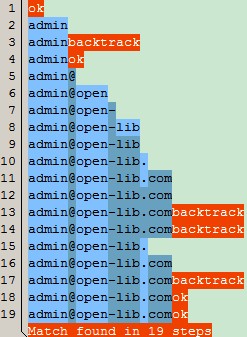
对的,你没看错,整个正确的匹配过程用了19步,对比前面的55步,简直天与地的差别。,我们继续分析下匹配过程:
1、图中的第1和2步,匹配^\w+,匹配成功,匹配了“admin”;
2、图中第3步,匹配[-\.],当然由于不存在“.”和“-”,因此没匹配上具体的字符,也没具体的量词允许匹配零次,所以不用继续往下匹配了,因此直接产生了回溯;
3、图中第4步,因为上一步产生了回溯,所以“[-\.]\w+”匹配了零次,由于([-\.]\w+)*中限定零次或者多次,因此也匹配成功,也没匹配上具体的字符;
以下步骤,匹配该过程:
4、图中第6步\w+,匹配了open;
5、图中第7-12步匹配([-\.]\w+)*,匹配了“-lib”和“.com”;
6、因为“([-\.]\w+)*”中的量词是“*”,则继续重复这个过程;
7、图第13步,匹配([-\.]\w+)* ,因为此时指针已经位于@open-lib.com之后了,也没具体的量词允许匹配零次,因此匹配失败,回溯到上次成功的位置;
8、图第14步,匹配 ([-\.]\w+)*$中的“[-\.]”,此时指针仍位于字符串末尾,没任何字符能匹配,所以匹配失败,产生回溯,回到上次成功且还没尝试过的位置,即图中的第9步;
9、经过上面的回溯,指针已经位于@open-lib之后的位置了;
10、图第15步匹配了“.”,第16步\w+则匹配了“com” ;
11、图第17步匹配([-\.]\w+)*,由于此时指针又位于字符串末尾,因此[-\.]部分没匹配上任何字符,因此产生回溯;
12、图第18步,由于 ([-\.]\w+)*的量词是“*”,表示匹配零次或多次,虽然子表达式[-\.]匹配失败,所以整个表达式匹配了零次,也是匹配成功;
13、最后一步第19步,“$”表示末尾匹配,因为此时指针位于字符串末尾,故符合,因此也匹配成功。
分析
整个匹配过程关键优化地方,还是回溯,两个示例表达式看起来相近,匹配过程也部分类似,但两个例子的效率却如此大的分别,现在来分析一下造成回溯的原因。
对比下两个表达式不同的部分:
^\w+([\.-]\w+)*@\w+([\.-]\w+)*\.\w+([-\.]\w+)*$
[No0000FD]C# 正则表达式的更多相关文章
- JS正则表达式常用总结
正则表达式的创建 JS正则表达式的创建有两种方式: new RegExp() 和 直接字面量. //使用RegExp对象创建 var regObj = new RegExp("(^\\s+) ...
- Python高手之路【五】python基础之正则表达式
下图列出了Python支持的正则表达式元字符和语法: 字符点:匹配任意一个字符 import re st = 'python' result = re.findall('p.t',st) print( ...
- C# 正则表达式大全
文章导读 正则表达式的本质是使用一系列特殊字符模式,来表示某一类字符串.正则表达式无疑是处理文本最有力的工具,而.NET提供的Regex类实现了验证正则表达式的方法.Regex 类表示不可变(只读)的 ...
- C#基础篇 - 正则表达式入门
1.基本概念 正则表达式(Regular Expression)就是用事先定义好的一些特定字符(元字符)或普通字符.及这些字符的组合,组成一个“规则字符串”,这个“规则字符串”用来判断我们给定的字符串 ...
- JavaScript正则表达式,你真的知道?
一.前言 粗浅的编写正则表达式,是造成性能瓶颈的主要原因.如下: var reg1 = /(A+A+)+B/; var reg2 = /AA+B/; 上述两个正则表达式,匹配效果是一样的,但是,效率就 ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- 【JS基础】正则表达式
正则表达式的() [] {}有不同的意思. () 是为了提取匹配的字符串.表达式中有几个()就有几个相应的匹配字符串. (\s*)表示连续空格的字符串. []是定义匹配的字符范围.比如 [a-zA-Z ...
- JavaScript 正则表达式语法
定义 JavaScript定义正则表达式有两种方法. 1.RegExp构造函数 var pattern = new RegExp("[bc]at","i"); ...
- [jquery]jquery正则表达式验证(手机号、身份证号、中文名称)
数字判断方法:isNaN()函数 test()方法 判断字符串中是否匹配到正则表达式内容,返回的是boolean值 ( true / false ) // 验证中文名称 function isChin ...
随机推荐
- 12C -- ORA-12850: 无法在所有指定实例上分配从属进程: 需要 2, 已分配 1
使用客户端连接到oracle 12.2.0.1 rac数据库,报以下错误信息: ORA-12850: 无法在所有指定实例上分配从属进程: 需要 2, 已分配 1 因为没有mos账号,只好谷歌一下了.找 ...
- 译:1. RabbitMQ Java Client 之 "Hello World"
这些教程介绍了使用RabbitMQ创建消息传递应用程序的基础知识.您需要安装RabbitMQ服务器才能完成教程 1. 打造第一个Hello World 程序 RabbitMQ是一个消息代理:它接受和转 ...
- Atitit 类库冲突 解决方案
Atitit 类库冲突 解决方案 表现情况,找到不某些方法 类等,一个情况是真的找不到,一个情况是加载了错误的jar,导致正确的jar无法加载.. 1.1. 查找现在ide正在使用的jar1 1.2. ...
- rocketmq 源码
https://github.com/YunaiV/incubator-rocketmq
- 截图工具(window 10 和Mac OSX)
Win10上截图 1.使用系统截图工具 所有程序中可以看到 通过win+R,打开运行,输入"SnippingTool" 文件位于: C:\Windows\System32\Sn ...
- PaaS 应用引擎
这里主要是梳理一下应用引擎(XXXX App Engine),它一般被归类到PaaS领域.应用引擎即提供了各种编程语言开发的应用所需的一整套运行环境:它开箱即用,你只需部署应用的代码即可,无需前期的环 ...
- 提一下InfoQ
昨天在微信读书中整理了一个"架构师"清单,把InfoQ中文社区这两年发布的电子书整理到了一起,分享给了团队成员. 如果你去研究InfoQ中文社区,就会发现其中一个人与之因缘际会的相 ...
- Caltech数据使用详情
Caltech官网: http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/ 以Caltech测试集为例(大概是4095个图片 ...
- 学习Mysql过程中拓展的其他技术栈:Docker入门介绍
一.Docker的介绍和安装 1. Docker是什么 百度百科的介绍: Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linu ...
- mac air 2012 mid 使用bootcamp 安装windows
一切都按正常顺序进行,到开始安装时,遇到错误: "提示windows无法安装到这个磁盘.选中的磁盘具有MBR分区表" 解决方法: 重新进入mac系统,使用bootcamp从头开始, ...