flink基本原理
一、简介
开源流式处理系统在不断地发展,从一开始只关注低延迟指标到现在兼顾延迟、吞吐与结果准确性,在发展过程中解决了很多问题,编程API的易用性也在不断地提高。本文介绍一下 Flink 中的核心概念,这些概念是学习与使用 Flink 十分重要的基础知识,在后续开发 Flink 程序过程中将会帮助开发人员更好地理解 Flink 内部的行为和机制。
这里引用一张图来对常用的实时计算框架做个对比:

Flink 是有状态的和容错的,可以在维护一次应用程序状态的同时无缝地从故障中恢复。它支持大规模计算能力,能够在数千个节点上并发运行。它具有很好的吞吐量和延迟特性。同时,Flink 提供了多种灵活的窗口函数。Flink 在流式计算里属于真正意义上的单条处理,每一条数据都触发计算,而不是像 Spark 一样的 Mini Batch 作为流式处理的妥协。Flink的容错机制较为轻量,对吞吐量影响较小,而且拥有图和调度上的一些优化,使得 Flink 可以达到很高的吞吐量。而 Strom 的容错机制需要对每条数据进行ack,因此其吞吐量瓶颈也是备受诟病。
二、工作原理
Flink基本工作原理如下图:
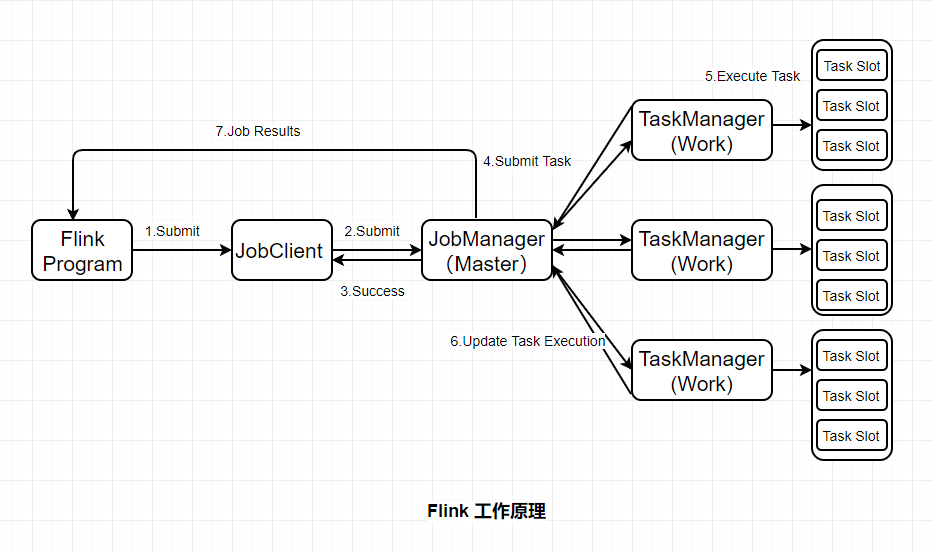
JobClient:负责接收程序,解析和优化程序的执行计划,然后提交执行计划到JobManager。这里执行的程序优化是将相邻的Operator融合,形成Operator Chain,Operator的融合可以减少task的数量,提高TaskManager的资源利用率。
JobManagers:负责申请资源,协调以及控制整个job的执行过程,具体包括,调度任务、处理checkpoint、容错等等。
TaskManager:TaskManager运行在不同节点上的JVM进程,负责接收并执行JobManager发送的task,并且与JobManager通信,反馈任务状态信息,如果说JobManager是master的话,那么TaskManager就是worker用于执行任务。每个TaskManager像是一个容器,包含一个或者多个Slot。
Slot:Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManager的内存,值得注意的是,Slot仅划分内存,不涉及CPU的划分,即CPU是共享使用。每个Slot可以运行多个task。Slot的个数就代表了一个程序的最高并行度。
Task:Task是在operators的subtask进行链化之后形成的,具体Flink job中有多少task和operator的并行度和链化的策略有关。
SubTask:因为Flink是分布式部署的,程序中的每个算子,在实际执行中被分隔为一个或者多个subtask,运算符子任务(subtask)的数量是该特定运算符的并行度。数据流在算子之间流动,就对应到SubTask之间的数据传输。Flink允许同一个job中来自不同task的subtask可以共享同一个slot。每个slot可以执行一个并行的pipeline。可以将pipeline看作是多个subtask的组成的。
三、核心概念
1、Time(时间语义)
Flink 中的 Time 分为三种:事件时间、达到时间与处理时间。
1)事件时间:是事件真实发生的时间。
2)达到时间:是系统接收到事件的时间,即服务端接收到事件的时间。
3)处理时间:是系统开始处理到达事件的时间。
在某些场景下,处理时间等于达到时间。因为处理时间没有乱序的问题,所以服务端做基于处理时间的计算是比较简单的,无迟到与乱序数据。
Flink 中只需要通过 env 环境变量即可设置Time:
//创建环境上下文
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置在当前程序中使用 ProcessingTime
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
2、Window(窗口)
窗口本质就是将无限数据集沿着时间(或者数量)的边界切分成有限数据集。
1)Time Window:基于时间的,分为Tumbling Window(无数据重叠)和Sliding Window(有数据重叠) 。
2)Count Window:基于数量的,分为Tumbling Window(无数据重叠)和Sliding Window(有数据重叠)。
3)Session Window:基于会话的,一个session window关闭通常是由于一段时间没有收到元素。
4)Global Window:全局窗口。
在实际操作中,window又分为两大类型的窗口:Keyed Window 和 Non-keyed Window,两种类型的窗口操作API有细微的差别。
3、Trigger
1)自定义触发器
触发器决定了窗口何时会被触发计算,Flink 中开发人员需要在 window 类型的操作之后才能调用 trigger 方法传入触发器定义。Flink 中的触发器定义需要继承并实现 Trigger 接口,该接口有以下方法:
- onElement(): 每个被添加到窗口中的元素都会被调用
- onEventTime(): 当事件时间定时器触发时会被调用,比如watermark到达
- onProcessingTime(): 当处理时间定时器触发时会被调用,比如时间周期触发
- onMerge(): 当两个窗口合并时两个窗口的触发器状态将会被调动并合并
- clear(): 执行需要清除相关窗口的事件
以上方法会返回决定如何触发执行的 TriggerResult:
- CONTINUE: 什么都不做
- FIRE: 触发计算
- PURGE: 清除窗口中的数据
- FIRE_AND_PURGE: 触发计算后清除窗口中的数据
2)预定义触发器
如果开发人员未指定触发器,则 Flink 会自动根据场景使用默认的预定义好的触发器。在基于事件时间的窗口中使用 EventTimeTrigger,该触发器会在watermark通过窗口边界后立即触发(即watermark出现关闭改窗口时)。在全局窗口(GlobalWindow)中使用 NeverTrigger,该触发器永远不会触发,所以在使用全局窗口时用户需要自定义触发器。
4、State
Managed State 是由flink runtime管理来管理的,自动存储、自动恢复,在内存管理上有优化机制。且Managed State 支持常见的多种数据结构,如value、list、map等,在大多数业务场景中都有适用之处。总体来说是对开发人员来说是比较友好的,因此 Managed State 是 Flink 中最常用的状态。Managed State 又分为 Keyed State 和 Operator State 两种。
Raw State 由用户自己管理,需要序列化,只能使用字节数组的数据结构。Raw State 的使用和维度都比 Managed State 要复杂,建议在自定义的Operator场景中酌情使用。
5、状态存储
Flink中状态的实现有三种:MemoryState、FsState、RocksDBState。三种状态存储方式与使用场景各不相同,详细介绍如下:
1)MemoryStateBackend
构造函数:MemoryStateBackend(int maxStateSize, boolean asyncSnapshot)
存储方式:State存储于各个 TaskManager内存中,Checkpoint存储于 JobManager内存
容量限制:单个State最大5M、maxStateSize<=akka.framesize(10M)、总大小不超过JobManager内存
使用场景:无状态或者JobManager挂掉不影响的测试环境等,不建议在生产环境使用
2)FsStateBackend
构造函数:FsStateBackend(URI checkpointUri, boolean asyncSnapshot)
存储方式:State存储于 TaskManager内存,Checkpoint存储于 外部文件系统(本次磁盘 or HDFS)
容量限制:State总量不超过TaskManager内存、Checkpoint总大小不超过外部存储空间
使用场景:常规使用状态的作业,分钟级的窗口聚合等,可在生产环境使用
3)RocksDBStateBackend
构造函数:RocksDBStateBackend(URI checkpointUri, boolean enableincrementCheckpoint)
存储方式:State存储于 TaskManager上的kv数据库(内存+磁盘),Checkpoint存储于 外部文件系统(本次磁盘 or HDFS)
容量限制:State总量不超过TaskManager内存+磁盘、单key最大2g、Checkpoint总大小不超过外部存储空间
使用场景:超大状态的作业,天级的窗口聚合等,对读写性能要求不高的场景,可在生产环境使用
根据业务场景需要用户选择最合适的 StateBackend ,代码中只需在相应的 env 环境中设置即可:
// flink 上下文环境变量
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置状态后端为 FsStateBackend,数据存储到 hdfs /tmp/flink/checkpoint/test 中
env.setStateBackend(new FsStateBackend("hdfs://ns1/tmp/flink/checkpoint/test", false))
6、Checkpoint
Checkpoint 是分布式全域一致的,数据会被写入hdfs等共享存储中。且其产生是异步的,在不中断、不影响运算的前提下产生。
用户只需在相应的 env 环境中设置即可:
// 1000毫秒进行一次 Checkpoint 操作
env.enableCheckpointing(1000)
// 模式为准确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 两次 Checkpoint 之间最少间隔 500毫秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 过程超时时间为 60000毫秒,即1分钟视为超时失败
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许1个Checkpoint的操作在执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
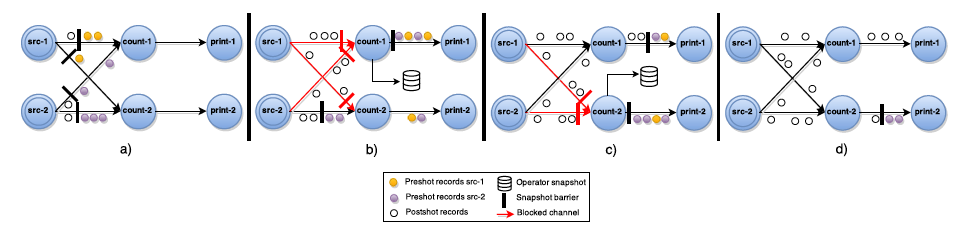
Asynchronous Barrier Snapshots(ABS)
这个算法基本上是Chandy-Lamport算法的变体,针对DAG(有向无环图)的ABS算法执行流程如下所示:
- Barrier周期性的被注入到所有的Source中,Source节点看到Barrier后,会立即记录自己的状态,然后将Barrier发送到Transformation Operator。
- 当Transformation Operator从某个input channel收到Barrier后,它会立刻Block住这条通道,直到所有的input channel都收到Barrier,此时该Operator就会记录自身状态,并向自己的所有output channel广播Barrier。
- Sink接受Barrier的操作流程与Transformation Oper一样。当所有的Barrier都到达Sink之后,并且所有的Sink也完成了Checkpoint,这一轮Snapshot就完成了。
下面这个图展示了一个ABS算法的执行过程:
7、Watermark
Flink 程序并 不能自动提取数据源中哪个字段/标识为数据的事件时间,从而也就无法自己定义 Watermark 。
开发人员需要通过 Flink 提供的 API 来 提取和定义 Timestamp/Watermark,可以在 数据源或者数据流中 定义。
1)自定义数据源设置 Timestamp/Watermark
自定义的数据源类需要继承并实现 SourceFunction[T] 接口,其中 run 方法是定义数据生产的地方:
//自定义的数据源为自定义类型MyType
class MySource extends SourceFunction[MyType]{
//重写run方法,定义数据生产的逻辑
override def run(ctx: SourceContext[MyType]): Unit = {
while (/* condition */) {
val next: MyType = getNext()
//设置timestamp从MyType的哪个字段获取(eventTimestamp)
ctx.collectWithTimestamp(next, next.eventTimestamp) if (next.hasWatermarkTime) {
//设置watermark从MyType的那个方法获取(getWatermarkTime)
ctx.emitWatermark(new Watermark(next.getWatermarkTime))
}
}
}
}
2)在数据流中设置 Timestamp/Watermark
在数据流中,可以设置 stream 的 Timestamp Assigner ,该 Assigner 将会接收一个 stream,并生产一个带 Timestamp和Watermark 的新 stream。
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks())
8、广播状态(Broadcast State)
和 Spark 中的广播变量一样,Flink 也支持在各个节点中各存一份小数据集,所在的计算节点实例可在本地内存中直接读取被广播的数据,可以避免Shuffle提高并行效率。
广播状态(Broadcast State)的引入是为了支持一些来自一个流的数据需要广播到所有下游任务的情况,它存储在本地,用于处理其他流上的所有传入元素。
// key the shapes by color
KeyedStream<Item, Color> colorPartitionedStream = shapeStream.keyBy(new KeySelector<Shape, Color>(){...}); // a map descriptor to store the name of the rule (string) and the rule itself.
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>("RulesBroadcastState",BasicTypeInfo.STRING_TYPE_INFO, TypeInformation.of(new TypeHint<Rule>() {})); // broadcast the rules and create the broadcast state
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor); DataStream<Match> output = colorPartitionedStream.connect(ruleBroadcastStream).process(new KeyedBroadcastProcessFunction<Color, Item, Rule, String>(){...});
9、Operator Chain
Flink作业中,可以指定相关的chain将相关性非常强的转换操作(operator)绑定在一起,使得上下游的Task在同一个Pipeline中执行,避免因为数据在网络或者线程之间传输导致的开销。
一般情况下Flink在Map类型的操作中默认开启 Operator Chain 以提高整体性能,开发人员也可以根据需要创建或者禁止 Operator Chain 对任务进行细粒度的链条控制。
//创建 chain
dataStream.filter(...).map(...).startNewChain().map(...)
//禁止 chain
dataStream.map(...).disableChaining()
创建的链条只对当前的操作符和之后的操作符有效,不不影响其他操作,如上代码只针对两个map操作进行链条绑定,对前面的filter操作无效,如果需要可以在filter和map之间使用 startNewChain方法即可。
10、Side Output
除了从DataStream操作的结果中获取主数据流之外,Flink还可以产生任意数量额外的侧输出(Side Output)结果流。侧输出结果流的数据类型不需要与主数据流的类型一致,不同侧输出流的类型也可以不同。当要拆分数据流时(通常必须复制流),从每个流过滤出不想拥有的数据时Side Output将非常有用。
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// 将数据发送到常规输出中
out.collect(value);
// 将数据发送到侧输出中
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
参考:
https://zhuanlan.zhihu.com/p/93507000
https://ci.apache.org/projects/flink/flink-docs-release-1.9/
https://www.jianshu.com/p/8d6569361999
flink基本原理的更多相关文章
- flink 基本原理
state状态操作 https://ci.apache.org/projects/flink/flink-docs-release-1.8/concepts/programming-model.htm ...
- flink入门(一)——基本原理与应用场景
一.简介 1.简介 flink是一个开源的分布式流处理框架 优势:高性能处理.高度灵活window操作.有状态计算的Exactly-once等 详情简介,参考官网:https://flink.apac ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- 带你认识FusionInsight Flink:既能批处理,又能流处理
摘要:本文主要介绍了FusionInsight Flink组件的基本原理.Flink任务提交的常见问题.以及最佳实践FAQ. 本文分享自华为云社区<FusionInsight HD Flink组 ...
- Ognl表达式基本原理和使用方法
Ognl表达式基本原理和使用方法 1.Ognl表达式语言 1.1.概述 OGNL表达式 OGNL是Object Graphic Navigation Language(对象图导航语言)的缩写,他是一个 ...
- Android自定义控件之基本原理
前言: 在日常的Android开发中会经常和控件打交道,有时Android提供的控件未必能满足业务的需求,这个时候就需要我们实现自定义一些控件,今天先大致了解一下自定义控件的要求和实现的基本原理. 自 ...
- HMM基本原理及其实现(隐马尔科夫模型)
HMM(隐马尔科夫模型)基本原理及其实现 HMM基本原理 Markov链:如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程.马尔可夫链是时间和状态 ...
随机推荐
- PHP 7.4 新语法:箭头函数
短闭包,也叫做箭头函数,是一种用 php 编写的短函数.当向函数中传递闭包时,这个功能是非常有用的,比如使用 array_map 或是 array_filter 函数时. 译者注:PHP7.4 计划于 ...
- Jquery才可以使用 this 指定当前DOM
Jquery才可以使用 this 指定当前DOM jquery获取并设置它的元素 <div class="shop-item" style="line-height ...
- deepin MySQL 安装以及编码格式的修改utf-8
deepin MySQL 安装以及编码格式的修改utf-8: 1.sudo apt-get install mysql-server mysql-client 2.sudo mysql -u root ...
- ubuntu 18 怎样对Windows进行远程桌面控制
ubuntu 18 怎样对Windows进行远程桌面控制: 1. 先安装一个redesktop 工具(sudo apt-get install redesktop) 2. 在通过 redesktop ...
- [学习笔记] 在Eclipse中使用Hibernate,并创建第一个工程
在Eclipse中使用Hibernate 安装 Hibernate Tools 插件 https://tools.jboss.org/downloads/ Add the following URL ...
- ffmpeg-3.1.4居然也有这么坑的bug
近日自己用下载的ffmpeg-3.1.4代码自己编译来用,没想到会碰到这么一下低级坑.我用自己的编译出来的库总是会在用rtsp上传视频时崩掉,起初我还以为自己编译的x264出问题,因为我是绕开使用pk ...
- [转发]CSR8670的DFU功能
本文源自:https://blog.csdn.net/wzz4420381/article/details/52371409 作者:RyomaWang 申明:为了保持原作者内容,这里不进行任何修改,后 ...
- 【故障公告】docker swarm 集群问题造成新版博客后台故障
非常抱歉,今天下午 16:55~17:05 左右,由于 docker swarm 集群的突发不稳定问题造成新版博客后台(目前处于灰度发布阶段)无法正常使用,由此给您带来麻烦,请您谅解. 出故障期时,新 ...
- ubuntu 16.04安装并启动openssh
对于没有图形界面的linux系统,一般都会用到远程连接控制,,因此新安装的linux系统,在配好网络后,首先要安装的就是远程连接工具,ssh是常用的方法. ps -ef |grep ssh //查看 ...
- 🔥《手把手教你》系列基础篇之3-python+ selenium-驱动浏览器和元素定位大法(详细)
1. 简介 上一篇中,只是简单地一带而过的说了一些驱动浏览器,这一篇继续说说驱动浏览器,然后再说一说元素定位的方法. 完成环境的安装并测试之后,我们对Selenium有了一定的了解了,接下来我们继续驱 ...